目录
八、文件系统
8.1 磁盘
8.1.1 磁盘的物理结构
8.1.2 磁盘的存储结构
8.1.3 磁盘的逻辑结构
8.2 inode
九、软硬链接
9.1 软链接
9.2 硬链接
9.3 当前路径(.)和上级路径(..)
十、文件的三个时间
八、文件系统
上面的内容谈论的都是一个被打开文件,那没有被打开的文件呢?接下来就要谈论。磁盘上有大量没有被打开的文件,也需要操作系统进行静态管理,方便我们随时打开。未打开的文件就被文件系统进行管理
8.1 磁盘
学习文件系统之前要简单了解一下磁盘,这样方便理解文件系统
8.1.1 磁盘的物理结构
磁盘是一种永久性存储介质,在计算机中,磁盘是唯一的机械设备,与磁盘相对应的就是内存,内存是掉电易失存储介质。 在企业中,磁盘依旧是储存的主流

每个磁盘片有两面,两个盘面都可以用于储存数据,存储的数据都是二进制的,每一个盘面都有一个磁头,并且磁头与盘面是没有接触的,如上图的左图
8.1.2 磁盘的存储结构
如上图的中间图片和右边图片
- 磁道(Tracker):磁盘表面被分为许多同心圆,每个同心圆称为一个磁道,每个磁道都有自己的编号
- 柱面(Cylinder):多个磁盘的同一个磁道重叠起来叫做磁柱
- 磁面(Head):一个盘面,每个盘面都有自己的编号
- 扇区(Sector):磁道的一个扇形区,每个扇区都有自己的编号
- 磁头数 == 盘面数,并且磁头是共进退
- 磁道等价于磁道,所以:磁头,柱面,扇区 == 磁头,磁道,扇区
磁盘的基本读写单位是扇区,扇区大小一般是 512字节(512byte)
每个盘片被分为若干个同心圆,每一个同心圆就是一个磁道,而每个磁道被划分为若干个扇区,每个扇区的大小都是 512字节
如何定位一个扇区(如何找到指定的扇区)?
首先找到属于这个扇区的磁道(柱面),再找到这个扇区的盘面,然后在磁道(柱面)上进行定位这个扇区
注:机械硬盘的寻址的工作方式:磁头不断摆动(定位磁道和盘面),盘片不断旋转(定位到特定的扇区)( 磁道— 盘面 — 扇区)
通过 柱面Cylinder —— 磁头Head —— 扇区Sector 进行寻址,这种寻址方法为 CHS寻址
8.1.3 磁盘的逻辑结构
把磁盘类比磁带,可以把磁盘盘片想象成线性结构,当磁带被卷起来时,其就像磁盘一样是圆形的,但当我们把磁带拉直后,其就是线性的,磁盘也可以这样进行类比

把一个磁道“拉直”了,其就变成了一条直线,依此类推,可以把每一个盘面上的每一条磁道都“拉直”相连

我们就可以从逻辑上把磁盘看成一个数组 sector_arr[n],以一个扇区大小为数组一个元素的大小。所以对磁盘数据的修改,就可以抽象成对数组的增删查改
认为磁盘是线性结构,所以要访问某一个扇区,就是直接定位数组的下标,这种寻址方式称为 LBA寻址(logic block address)
操作系统内部使用的是 LAB寻址,LAB方式寻址和 CHS方式寻址可以相互转化
为什么 OS 要对磁盘逻辑抽象使用 LAB寻址,为什么不使用 CHS寻址?
- 为了便于管理磁盘
- 不想让 OS 的代码和硬件强耦合
虽然磁盘的访问基本单位是 512字节,但是依旧很小、OS 内的文件文件系统定制的多个扇区的读取:1KB,2KB,4KB为基本单位,Linux 一般采用 4KB 作为基本单位,4KB 也就是8个扇区
哪怕是只读取、只修改 1字节,也必须将 4KB 加载到内存,进行读取或修改
为什么采用 4KB 作为 IO 的基本单位?
局部性原理,再加上内存也是被划分为 4KB 大小的空间为基本单位,对应磁盘也划分 4KB 为基本单位,可以提高 IO 效率
8.2 inode
磁盘空间很大,管理成本高,磁盘采用分治思想,比如管理我们的国家,一个国家分成许多个省份,省再分成许多个市,市又分成许多个区...,这就是分而治之的思想,这也是我们的电脑为什么有 C/D/F...盘了
计算机为了更好的管理磁盘,会对磁盘进行分区。而对于每一个分区来说,分区的头部会包括一个启动块(Boot Block),对于该分区的其余区域文件系统将其划分为一个个的块组(Block Group)
比如,磁盘有500GB,分到合适就不再进行分区了
 注意: 启动块的大小是确定的,而块组的大小是由格式化的时候确定的,并且不可以更改,每个分区的大小由 OS 决定
注意: 启动块的大小是确定的,而块组的大小是由格式化的时候确定的,并且不可以更改,每个分区的大小由 OS 决定

每个组块都有着相同的组成结构,每个组块都由超级块(Super Block)、块组描述符表(Group Descriptor Table)、块位图(Block Bitmap)、inode位图(inode Bitmap)、inode表(inode Table)以及数据表(Data Block)组成

- Block Group:文件系统会根据分区的大小划分为数个Block Group,而每个Block Group都有着相同的结构组成
- 超级块(Super Block):存放整个文件系统本身的结构信息。记录的信息主要有:bolck 和 inode 的总量,未使用的block和inode 的数量,一个 block 和 inode 的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block 的信息被破坏,可以说整个文件系统结构就被破坏了
- GDT(Group Descriptor Table):块组描述表,描述块组属性信息
- 块位图(Block Bitmap):Block Bitmap 中记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用
- inode位图(inode Bitmap):每个 bit 表示一个 inode 是否空闲可用
- i节点表(inode Table):存放文件属性,如文件大小,所有者,最近修改时间,每个文件的 inode等
- 数据区(Data Blocks):存放文件内容
注意:
- 超级块(Super Block)是每个分组都有一个,假设这个组的超级块出异常了,被操作系统检测到了,OS 就会把其他组的超级块拷贝到出异常的超级块,这个异常的分组就可以正常工作了,因为每一个分组都有一个相同的超级块
- 磁盘的格式化本质上就是重新写入文件系统,比如 Windows 下的磁盘分区 C/D/E...盘,假设对E盘格式化就是对该分区重新写入文件系统
在前面说过,文件 = 内容 + 属性。在 Linux 下,文件的内容和属性是分开存储的,文件属性里面有一个重要的东西:inode,inode 是固定大小的,一般是 128字节,也有 256字节的。Linux 下的 inode 一般是 128字节,每一个文件都有一个 inode。
inode 几乎包含了文件的所有的属性,文件名除外,文件名并不在 inode 中存储
文件的内容在 数据区(Data Blocks)存储
inode 为了区分彼此,所以每一个 inode 都有一个ID
查看文件的 inode
//显示文件的inode
ls -i
i节点表(inode Table)保存了分组内部所有可用的 inode(包括已经使用 + 未使用的) ,inode Table 在分组的时候已经固定了大小
数据区(Data Blocks)保存的是分组内部所有文件是数据块,以 4KB 为单位储存
inode位图(inode Bitmap)中记录的是每个 bit 表示一个 inode 是否空闲可用,位图中的比特位的位置和当前文件对应的 inode 的位置是一一对应的
块位图(Block Bitmap)中记录着 Data Block 中哪个数据块已经被占用,哪个数据块没有被占用,位图中的比特位的位置和当前 data block对应的数据块位置也是一一对应的
GDT(Group Descriptor Table)是块组描述表,对应分组的宏观属性
查找一个文件是统一使用 inode 编号进行查找的
如何理解创建一个文件?
- 通过 inode位图结构,找到一个空闲的 inode
- 在 inode Table 当中找到对应的 inode,并将文件的属性信息填充进 inode 中
- 将该文件的文件名和 inode 添加到目录文件的数据块中
如何理解对文件写入信息?
- 通过文件的 inode 编号找到对应的 inode 所在的位置
- 通过 inode 找到存储该文件内容的数据块,并将数据写入数据块
- 若不存在数据块或申请的数据块已被写满,则通过 Block Bitmap 找到一个空闲的块,并在数据区当中找到对应的空闲块,再将数据写入数据块,最后还需要建立数据块和 inode 的对应关系
- 注:一个文件的数据块是通过一个数组维护的,这个数组大小一般是15,前12个数据块用于存储文件的内容,剩余的三个元素分别是一级索引、二级索引和三级索引,后三个元素并不存储文件的内容。当该文件使用数据块的个数超过12个时,会使用这三个索引进行数据块扩充,不用担心数据块不够使用
如何理解目录?
- 一个目录下,文件名是没有重复,并且一个文件肯定是在一个特定的目录下
- 并且一个目录也算一个文件,也有自己的 inode(存的是目录的大小、权限、链接数、拥有者、所属组等)
- 目录也有自己的内容,目录的数据块中存储的就是该目录下的 文件名 以及对应文件的 inode,所以到这里我们也就知道了文件名存在哪里
如何理解删除一个文件?
- 在目录的 data block,用户提供的文件名,以文件名作为找到对应的 inode,在 inode Bitmap中把对应的比特位置中由1置0
- 然后再把 Block Bitmap 中把文件对应的数据块把它由1置0
- 最后在目录的data block中,删除inode和文件名的映射关系
- 所以,删除文件并不是真的把文件彻底删除了,也就是说被删除的文件在特定的条件下可以被恢复
为什么拷贝文件的时候很慢,而删除文件的时候很快?
- 因为拷贝文件需要先创建文件,然后再对该文件进行写入操作
- 该过程需要先申请 inode 并填入文件的属性信息,之后还需要再申请数据块,最后才能进行文件内容的数据拷贝,
- 而删除文件就是上面所说的
- 因此拷贝文件是很慢的,而删除文件是很快
九、软硬链接
9.1 软链接
什么是软连接?
- 软链接又叫做符号链接,软链接文件相对于原文件来说是一个独立的文件,该文件有自己的 inode 编号,但是该文件只包含了原文件的路径名,所以软链接文件的大小要比源文件小得多
- 软链接就类似于Windows操作系统当中的快捷方式
创建一个文件的软连接:
ln -s 文件名 软链接文件名比如:

图中可以看出软链接文件的 inode 号与原文件的 inode 是不同的,并且软链接文件的大小比源文件的大小要小得多

从图中看出,软链接文件只是其原文件的一个标记,当删除了原文件后,软链接文件不能独立存在,虽然仍保留文件名,但却不能执行原文件该有的功能了

这个数字就是文件的硬链接数,给文件创建软连接后原文件的链接数没有发生变化
9.2 硬链接
硬链接的概念:
硬链接文件就是原文件的一个别名,一个文件有几个文件名,该文件的硬链接数就是几,并且 inode 编号与原文件一致
创建硬链接
ln 原文件名 硬链接文件名比如:

从图中我们可以看到,硬链接文件的 inode 与原文件的 inode 是相同的,并且硬链接文件的大小与源文件的大小也是相同的,特别注意的是,当创建了一个硬链接文件后,该硬链接文件和原文件的硬链接数都变成了2

与软连接不同的是,当硬链接的原文件被删除后,硬链接文件仍能正常执行,只是文件的硬链接数减少了一个,因为此时该文件的文件名少了一个
软硬链接的区别
- 软链接是一个独立的文件,有独立的 inode,而硬链接没有独立的 inode
- 软链接相当于快捷方式,硬链接本质没有创建文件,只是建立了一个文件名和已有的 inode 的映射关系,并写入当前目录
9.3 当前路径(.)和上级路径(..)
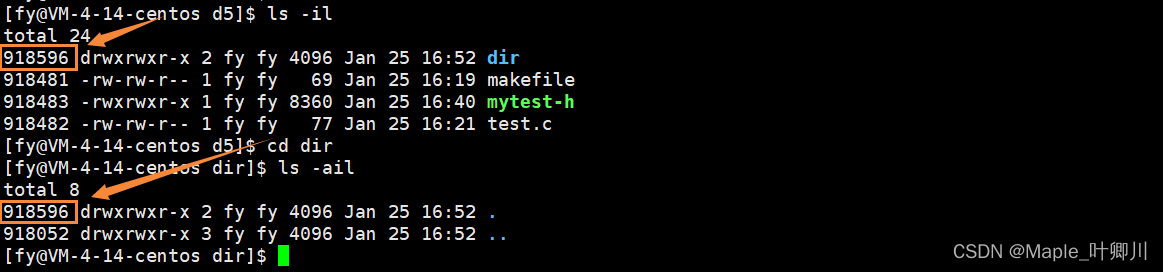
创建一个普通文件,该普通文件的硬链接数是1,因为此时该文件只有一个文件名。那为什么我们创建一个目录后,该目录的硬链接数是2 ??

因为每个目录创建后,该目录下默认会有两个隐含文件 . 和 ..,它们分别代表当前目录和上级目录,因此这里创建的目录有两个名字,一个是 dir 另一个就是该目录下的 .,并且也可以看到 dir 和该目录下的 . 的inode号是一样的
十、文件的三个时间
在Linux当中,可以使用命令 stat 来查看对应文件的信息
stat 文件名
这其中包含了文件的三个时间信息(AMC):
- Access: 文件最后被访问的时间
- Modify: 文件内容最后的修改时间
- Change: 文件属性最后的修改时间
----------------我是分割线---------------
文章到这里就结束了,下一篇即将更新


![LeetCode[1319]连通网络的操作次数](https://img-blog.csdnimg.cn/img_convert/66d200d112b34fb9a9c783f457a780aa.png)






![[Android开发基础1] 五大常用界面布局](https://img-blog.csdnimg.cn/ad67495df6264ba683fe4a2cf75bcc63.png)