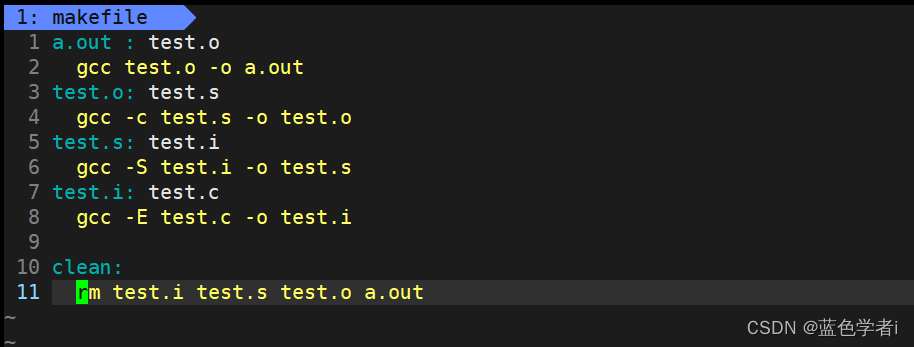
总结:计算机中字符串比较大小的规则
- 一·背景:
- 二·Unicode编码表:字符越靠后,对应的十进制值越大
- 三·单个字符之间比较规则:
- 四·案例演示:单个字符与单个字符之间比较大小
- 1.前提:汉字“一”与汉字“万”,进行大小比较。
- 2.两个汉字所在编码表的位置:汉字一在汉字万的前面7位处,如下图所示
- 3.使用计算机字符相减计算两个字符的相距的位数:完全满足单个字符之间比较规则
- 4.Character包装类的底层compare方法源码,本质也是将两个字符的十进制值进行相减,然后返回两个值的差;从而再进行判断两个字符的大小或者字符排序
- 五·两个字符串之间比较规则:
- 六·案例演示:两个字符串之间进行比较大小
- 1.两个字符所在编码表的位置:字符0在字符1的前面1位处,如下图所示
- 2.使用计算机字符串比较结果:
一·背景:
1.网上很多教程都说的不完整,不明确,因此本人自己总结了一下
2.大家都知道,字符串比较的基本规则是按照字典顺序比较,但这个字典指的是什么呢?是新华字典还是英文字典?那如果是其他特殊字符又该如何比较大小呢?
二·Unicode编码表:字符越靠后,对应的十进制值越大
查看Unicode编码表工具网站:
http://www.hipenpal.com/tool/characters_to_unicode_charts_in_simplified_chinese.php?unicode=118
三·单个字符之间比较规则:
任何字符都是先获取字符在Unicode编码表中对应的十进制值,再将前一个字符的十进制值减去后一个字符的十进制值,最后会得到一个十进制数字;最后再根据这个返回的值去进行判断两个字符的大小或者进行字符排序(一般默认是Unicode编码表的字符排列顺序就是自然顺序或字典顺序,即字符越靠后,对应的十进制值越大)
注意:
(1)最后返回的数字表示:前一个字符相对于后一个字符在Unicode编码表中的位置关系。
(1-1)若前一个字符在后一个字符的前面则返回负数,且数字大小就是两个字符在Unicode编码表上相距的位数;
(1-2)若前一个字符在后一个字符的后面则返回正数,且数字大小就是两个字符在Unicode编码表上相距的位数;
(2)编码表里面包含各种英文、汉字、特殊字符等等
(3)大家口中常说的字符串比较是使用字典顺序,有时候也说是使用ASCII码表对应的值比较。先说结论,这两种说法是OK的但是不完整也不准确,且容易让初学者误解。这里的字典顺序并不是什么新华字典、英文字典等等,而是指的Unicode编码表;然而Unicode编码表是完全兼容ASCII表的,从ASCII编码表中获取英文字符对应的十进制值与从Unicode编码表中获取英文字符对应的十进制值是完全相等的,当然还有其他特殊字符等等也是如此;但是ASCII编码表由于是美国发明创建的,因此天生就不支持非英语国家的字符,尤其是没有中文字符。因此为了便于全球计算机互联互通,就得有个全球统一的字符集编码,这也就是大名鼎鼎的Unicode编码,也称“万国码”。但是其他字符集编码几乎没有被Unicode编码兼容,都需要进行相互转换才行。
四·案例演示:单个字符与单个字符之间比较大小
1.前提:汉字“一”与汉字“万”,进行大小比较。
2.两个汉字所在编码表的位置:汉字一在汉字万的前面7位处,如下图所示
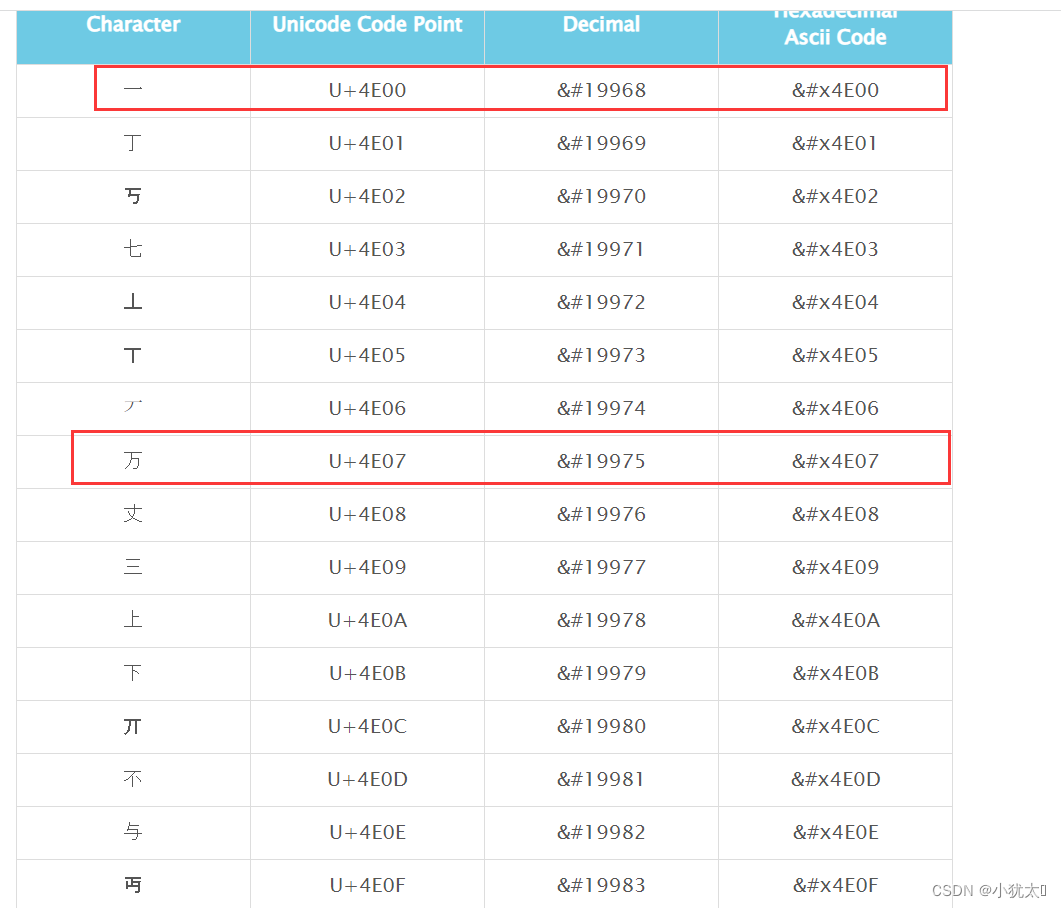
3.使用计算机字符相减计算两个字符的相距的位数:完全满足单个字符之间比较规则
4.Character包装类的底层compare方法源码,本质也是将两个字符的十进制值进行相减,然后返回两个值的差;从而再进行判断两个字符的大小或者字符排序

五·两个字符串之间比较规则:
从两个字符串的开头,依次分别获取两个字符串的单个字符,再依据单个字符之间的比较规则,判断哪个字符大,则哪个字符串大;若两者的单个字符相等,则依次分别再取下一位单个字符,再进行比较,直到分出结果。
注意:
(1)“一1”跟“一”比较,第一位单个字符肯定相等,都取第二位单个字符时,明显第二个字符串没有第二位字符了;这种情况下计算机会默认用0代替,然后拿去跟另一个字符比较,直到比较出结果
六·案例演示:两个字符串之间进行比较大小
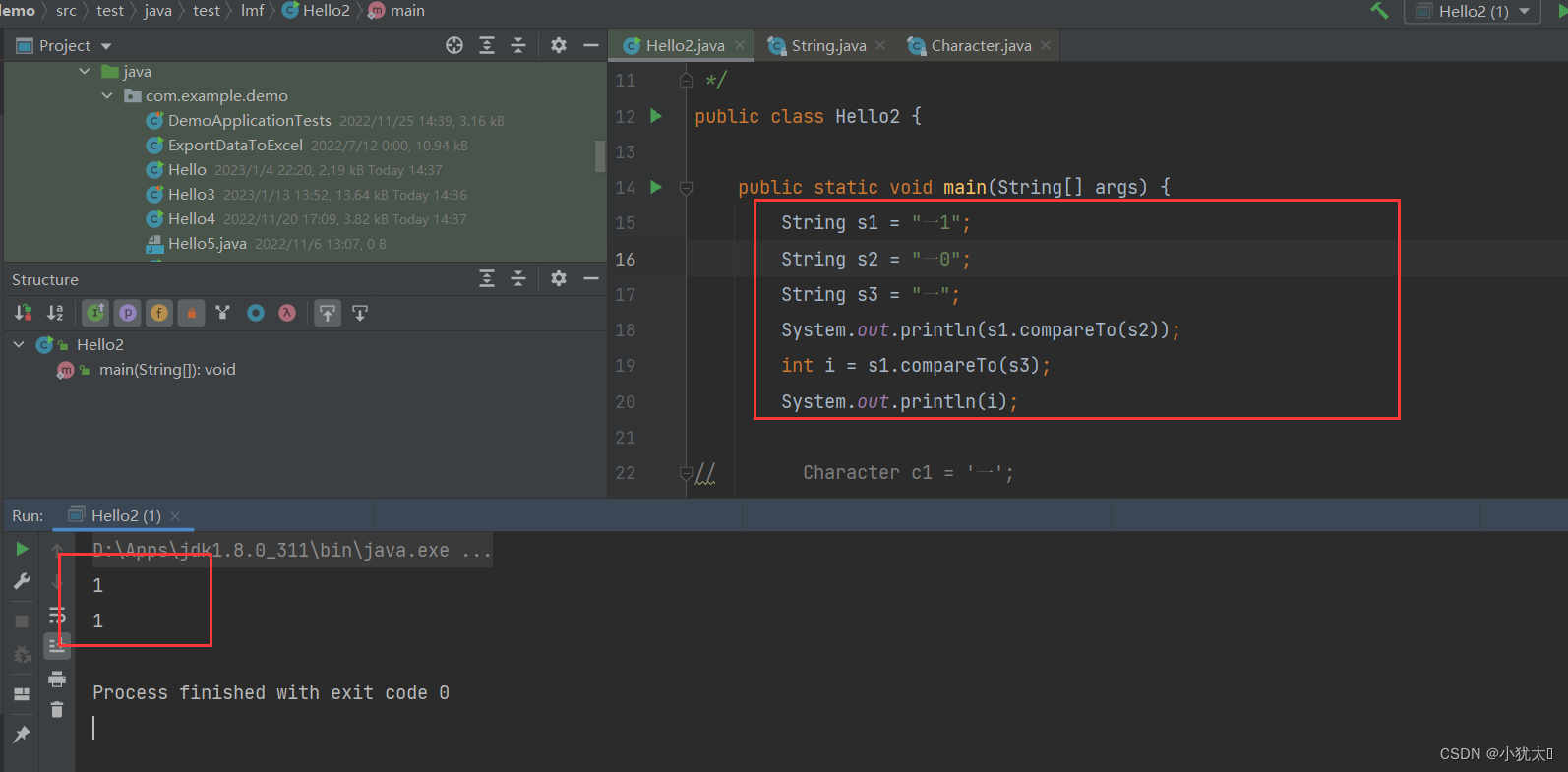
1.两个字符所在编码表的位置:字符0在字符1的前面1位处,如下图所示

2.使用计算机字符串比较结果:



![LeetCode[684]冗余连接](https://img-blog.csdnimg.cn/img_convert/c02bdcf7bcf2441196d3e09029eb0f3c.png)