文章目录
- 决策树
- 学习过程
- 预测过程
- 如何划分
- 信息熵
- 信息增益
- 增益率
- 基尼指数
- 泛化能力关键:剪枝
- 预剪枝
- 后剪枝
- 比较
- 缺失值处理:样本赋权,权重划分
决策树
决策树基于“树”结构进行决策
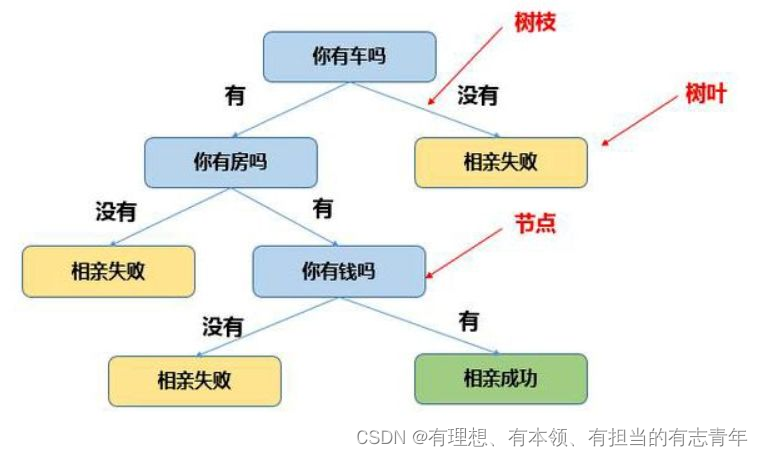
- 每个内部节点对应于某个属性上的测试
- 每个分支对应于该属性的某个取值
- 每个叶节点对应于一个预测结果
学习过程
根据训练数据,确定每个节点的划分属性
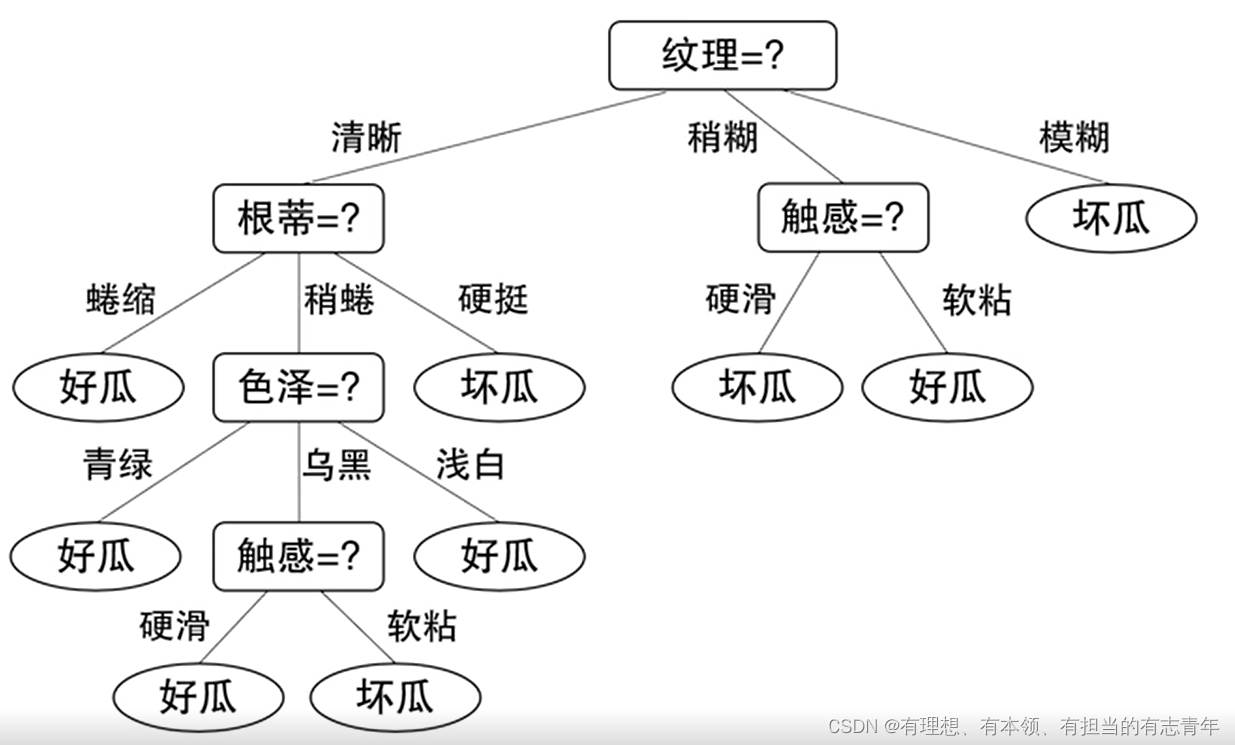
划分停止条件
- 当前节点包含的样本属于同一类别,无需划分
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
- 当前节点包含的样本集合为空,不能划分
预测过程
新样本从根节点开始,根据节点属性一步一步往下走,直到叶节点为最终预测结果
如何划分
信息熵
描述当前样本纯度,信息熵越小,纯度越高

信息增益
描述经过一次划分后获得的收益
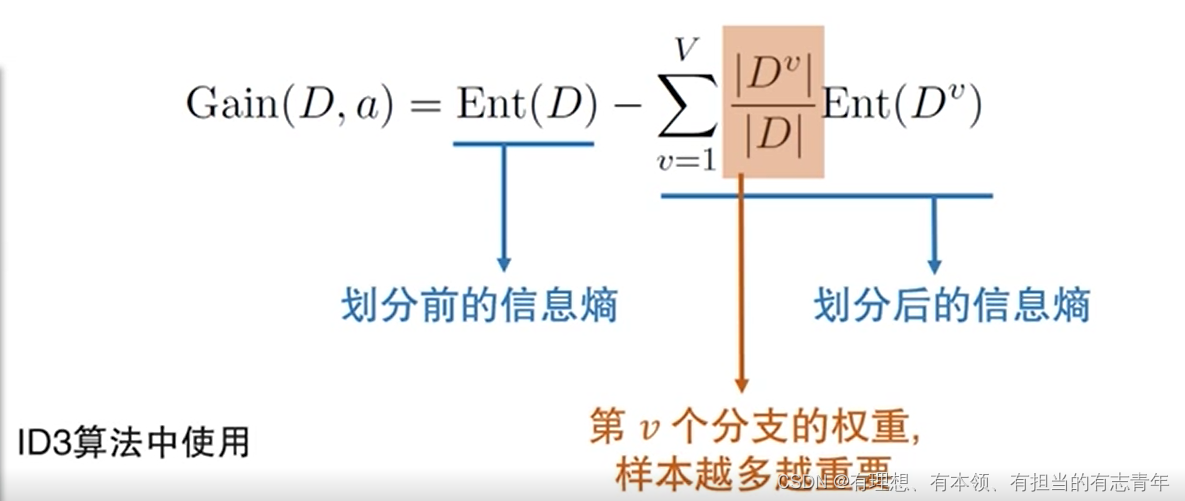
缺点:对于属性值多的属性有所偏好
增益率

过程:先从信息增益中找到高于平均水平的,再从中找到增益率高的
基尼指数
基尼指数越小,数据集纯度越高

泛化能力关键:剪枝
预剪枝
验证每个节点划分后前后精度变化,再决定要不要生成这个节点
后剪枝
先生成完整的决策树,再由下向上考虑每个节点前后精度变化
比较

缺失值处理:样本赋权,权重划分
- 计算无缺失值的信息增益
- 根据无缺失值的样本占总样本的比例赋予信息增益权重,找到最大的属性作为划分节点
- 含缺失值的样本,根据无缺失值的样本在三个分支上的比例进行划分