Prometheus中的promQL语句:
Prometheus提供的一种promQL语法,用来处理接口数据,然后方便用户对数据进行处理加工,它是Prometheus专门提供的一个函数表达式语言,可以实时的查询和聚合时间序列的数据,通过HTTPApi的方式提供给外部使用,
PromQL主要分为下面的几种类型数据:
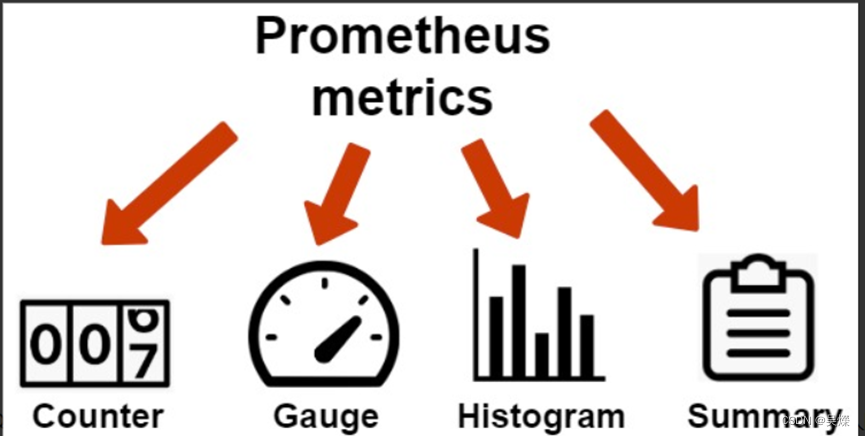
这里面的类型对应前面提到的metrics类型:
Counter: 只增不减的计数器:
像在Prometheus中统计一些cpu,http_reques_total的数据,都是一直在增加的数据,
Gauge: 可增可减的仪表盘:
这种方式更侧重于表示当前系统的一个状态,通过获取实时数据进行展示, 常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
Histogram和Summary: 都是用来分析数据的分布情况
Histogram与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。不同在于Histogram指标直接反应了在不同区间内样本的个数,区间通过标签len进行定义。
同时对于Histogram的指标,我们还可以通过histogram_quantile()函数计算出其值的分位数.
不同在于Histogram是在服务器端进行计算的分位数,而Summary的则是在客户端进行的计算,.
简单的几个示例:
过去5分钟的平均增长速率:
rate(http_requests_total[5m])
计算某个指标数据和.
Sum(my_metric_name)
Sum(http_requests_total[5m])
计算load5分钟,负载在两个小时内的差异:
delta(node_load5{instance="localhost:9100",job="node"}[2h])
当然,其中的数据来源,都是通过Prometheus中有的监控项目和采集到的数据,也可以加上不同标签进行过滤标识.
还有很多的语法和使用情况:
参考: Prometheus-基础系列-(四)-PromQL语句实践-1 - 知乎 (zhihu.com)
Prometheus的时序数据库
在使用Prometheus的时候,一般都没有安装其他专门用来存储采集数据的数据库.因为Prometheus自带有一种数据库.它是将采集到的样本以时间为序列的方式进行保存到本地内存中,然后定时通过分块的方式存储到磁盘中,但本地存储一般会保存15天,之后就会删除,那么需要永久保存就需要修改参数:” “storage.tsdb.retention.time=10000d”;延长时间.
时序数据库
首先看看什么是时序数据库. PrometheusTSDB、InfluxDB都是时序数据库.
因为Prometheus采集数据都是通过以时间节点来进行数据采集和标识,那么就需要将时间和当前时间的数据对应起来,一般都是通过(key,value)的形式记性存储.
每个数据点也就是由时间戳和值构成的元组.
identifier->(t0,v0),(t1,v1),(t2,v2)...
Prometheus TSDB的数据模型:
<metric name>{<labelname>=<label value>, ...}
例如Prometheus中的具体示例:
requests_total{method="POST",handler="/messages"}
其中一个时间序列是一组时间上严格单调递增的数据点序列,它可以通过metric来寻址,
Prometheus TSDB的存储原理
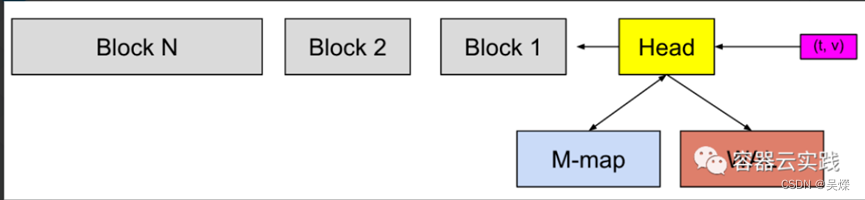
这个图就是存储的大致流程,其中t,v,就是采集的键值对数据,Head块是TSDB的内存块,所以数据进入后先放入到内存中,这里为了防止主机异常后数据丢失,所以还有一个预写机制,先做了一次预写日志(WAL)存储,并将这个数据在内存中保存一段时间,方便查询.
然后刷新到磁盘中并进行内存的一个映射(M-map),当这些内存映射的块或内存中的块到达某个时间后,就会进行持久化存储到磁盘block中去.
在head中还存在着数据截断:
Head中样本的一个声明周期的流程:
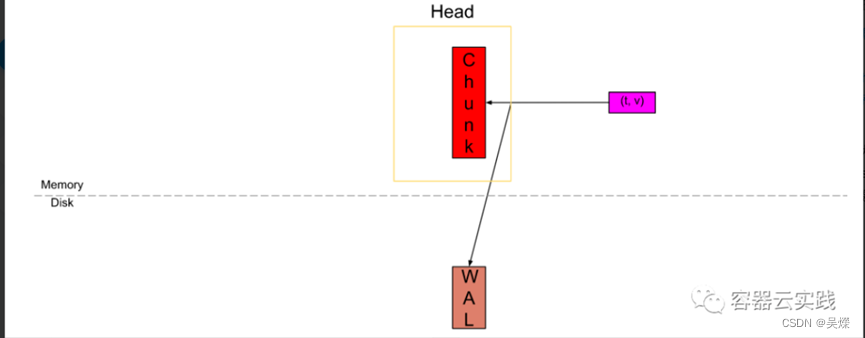
首先采集到数据后,来到head中存在active chunk中,这是唯一可以主动写入数据的地方,同时进行一次预写日志.
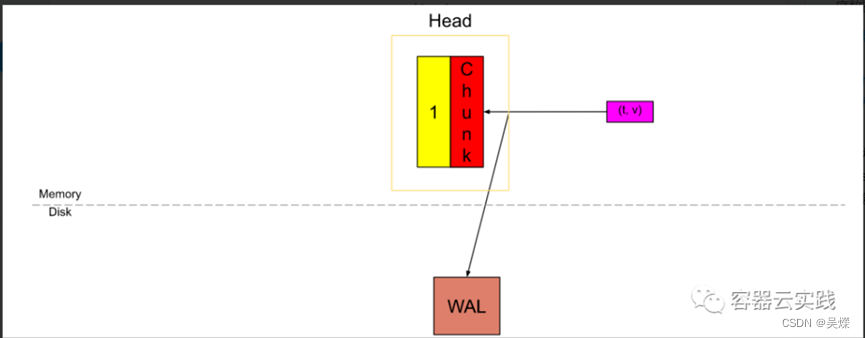
一旦active的空间被填满之后就需要进行数据截断,
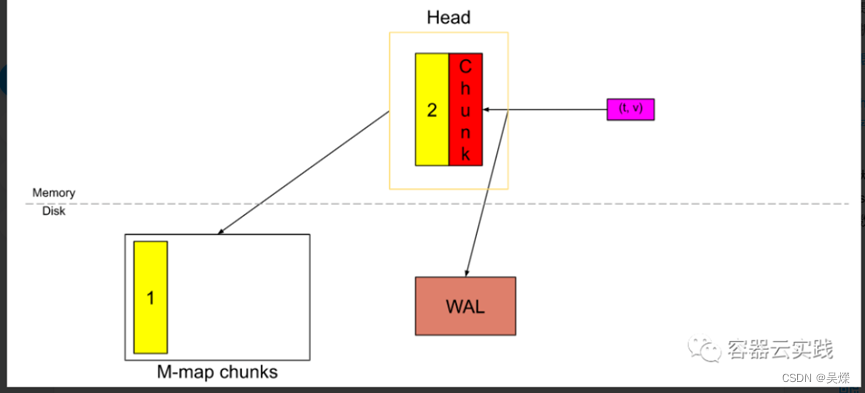
那么就将截断数据进行内存映射后,写入到磁盘中,继续循环这个过程,
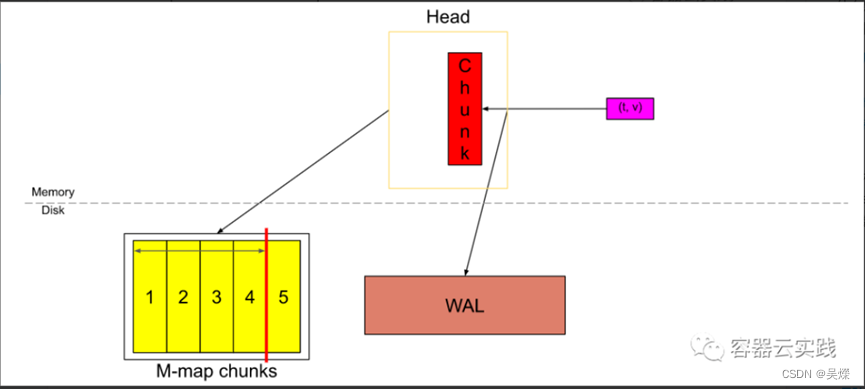
当数据变多,其中内存映射也只会去加载最新的,最被频繁使用的数据,此时TSDB就会将不常用数据刷新到磁盘bolck中,.
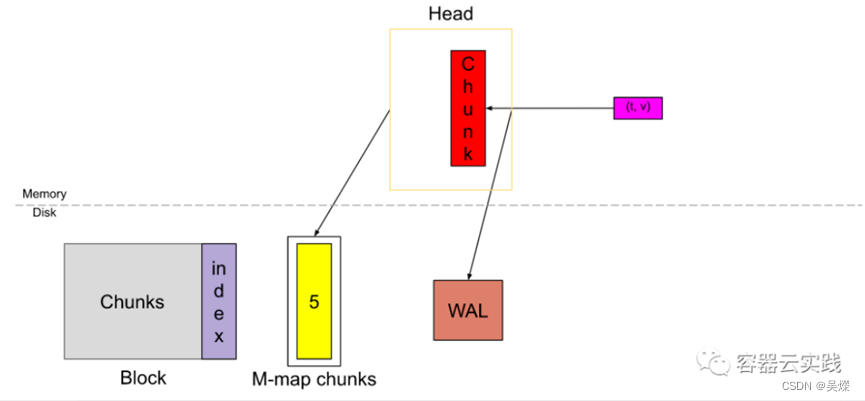
Block的持久化存储
Block的目录结构:
├── 01BKGTZQ1SYQJTR4PB43C8PD98 #block ID
│ ├── chunks # Block中的chunk文件
│ │ └── 000001
│ ├── tombstones # 数据删除记录文件
│ ├── index # 索引
│ └── meta.json # bolck元信息
磁盘上的block是固定时间范围内的chunk的集合,由他们自己的索引组成,其中包含 多个文件目录,对于每一个block上都有一个唯一的uid,id是可以进行排序的,当我们需要更新,修改bolck中的一些样本时,Prometheus TSDB只能重写整个block,生成新的id,如果要删除的情况下,Prometheus TSDB通过tombstones 实现了在不触及原始样本的情况下进行清理.
Tombstones 可以认为是一个删除标记,是block中唯一在写入数据后用于存储删除请求所创建的和修改的文件
Block合并:
在间隔多个定时时间后呢,就会产生大量的block块出现,那么就需要对这个多个block进行维护,
那么它进行合并的工作主要是将一个或多个现有块,写入一个新块,最后删除源块,并使用新的合并块后的block代替这些源块.
为什么需要对Block进行合并?
上面对tombstones介绍我们知道Prometheus在对数据的删除操作会记录在单独文件stombstone中,而数据仍保留在磁盘上。因此,当stombstone序列超过某些百分比时,需要从磁盘中删除该数据。
如果样本值波动较小,有大量重复的数据,那么对block合并,减少和节省磁盘空间,
当查询命中大于1个block时,必须合并每个块的结果,
如果有时间上重叠的block,查询他们还有对block之间的样本进行重复数据删除,合并后就不需要重复删除.
服务发现
Prometheus的自动发现是Prometheus自动对节点进行监控,与zabbix的自动发现和注册类似,,但Prometheus的自动发现方式较多,比如file_sd_confis基于文件自动发现,基于K8S自动发现,基于OpenStack的自动发现,基于consul自动发现等等.主要是用来解决云上资源的动态伸缩,
基于文件的自动发现配置:
File_sd_configs实现了文件级别的自动发现,使用文件自动发现功能后,Prometheus会定期检查配置文件是否有更新,如果有更新的话,就将新加入节点加入监控,服务端不同重启.
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
#自动发现配置
scrape_configs:
- job_name: 'prometheus'
file_sd_configs: #不再是static_configs了
- files: ['/usr/local/prometheus/sd_config/*.yml']
refresh_interval: 120s #加载文件的间隔时长
基于consul的自动发现配置:
Consul是一个服务器注册中心,主要用于容器化场景的自动发现,consul支持集群化配置,由多个代理节点组成的集群方式,代理节点分为server和client,所有的服务都可以进行注册,
区别:
在client是客户端模式,该模式下所有的注册到当前节点的服务会被转发到server,而且不会持久化这部分的服务信息,.
而server模式,则是会持久化这些数据,到本地,
对于Prometheus来说,他就是会自动获取到consul里的数据进行监控,而这些数据就是其他注册到consul中的.
global: #这里的配置项可以单独配置在某个job中
scrape_interval: 15s #采集数据间隔,默认15秒
evaluation_interval: 15s 告警规则监测频率,比如已经设置了内存使用大于70%就告警的规则,这里就会每15秒执行一次告警规则
scrape_timeout:10s #采集超时时间
scrape_configs:
- job_name: 'prometheus-server'
metrics_path defaults to '/metrics'
scheme defaults to 'http'
static_configs:
- targets: ['localhost:9090']
- job_name: 'consul-redis'
metrics_path defaults to '/metrics'
scheme defaults to 'http'
consul_sd_configs:
- server: '192.168.1.100:8500' #指定consul服务的地址,会从这个地址拉取数据
tags:
- "redis" #拉取数据时根据不同的标签进行分组
refresh_interval: 1m
- job_name: 'consul-mysql'
metrics_path defaults to '/metrics'
scheme defaults to 'http'
consul_sd_configs:
- server: '192.168.1.100:8500'
tags:
- "mysql" #拉取数据时根据不同的标签进行分组
refresh_interval: 1m
Prometheus-operator
介绍Prometheus-operator
在前面我们介绍了Prometheus监控,,但如果是在K8S集群中部署Prometheus,那么当我们使用configmap方式注入Prometheus.yaml文件.然后在配置文件中进行这个targets的修改,来管理监控的实例.. 无论我们是使用挂载targets方式还是直接修改,,都需要在修改好配置之后将Prometheus的pod进行删除重建,才能读取到最新的一个配置,进行加载.
那么这种方式的更新维护效率很低下,使用监控的体验感也不好.
所以为了简化这些步骤, CoreOS率先引入了Operator的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator。
Prometheus Operator的工作原理
从概念上来讲operator就是针对管理特定应用程序的,在K8S接班的resource和controller的概念上,通过扩展K8Sapi的方式,帮助用户创建,配置管理这些有状态的应用程序.
架构图:
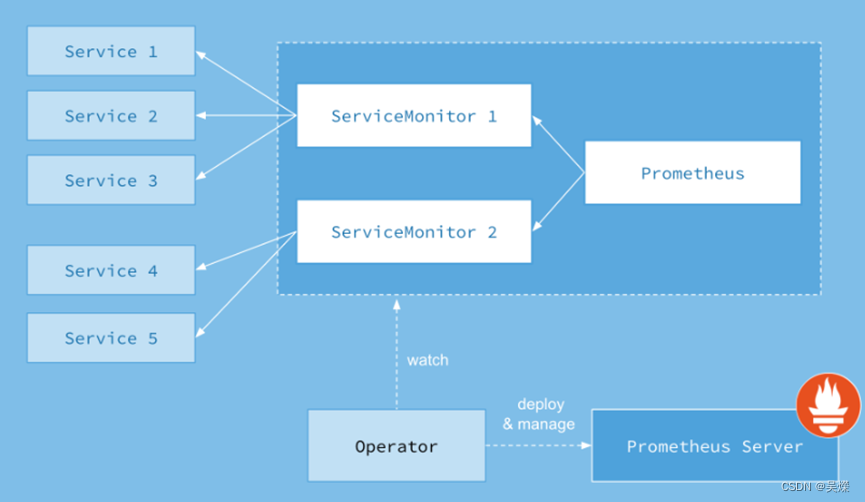
从这个图中可以很好的看出,它所拥有的几种资源类型,以及和SVC的之间的关系.
Prometheus的本职就是一组用户自定义的CRD资源以及controller的实现,Prometheusoperator负责监听到这些自定义资源的变化,并且根据这些资源的定义自动化的完成在Prometheus server自身以及配置的自动化管理工作.
Prometheus operator资源类型:
目前提供了4种资源类型:
Prometheus:声明创建和管理PrometheusServer的实例,通过statefulset方式创建server pod
ServiceMonitor: 负责声明式的管理监控配置,后端关联svc
PrometheusRule: 负责声明式的管理告警配置
Alertmanager:声明式的创建和管理Alertmanager实例。
就是在K8S集群中通过声明和使用这四种资源类型创建,相互关联来实现Prometheus的监控服务,同时可以很好的进行维护.
K8S集群中使用Prometheus-operator搭建监控服务
参考链接: 什么是Prometheus Operator · Prometheus中文技术文档