cpp 多线程:内存模型(std::memory_order)
文章目录
- cpp 多线程:内存模型(std::memory_order)
- 概念
- 内存模型基础
- 原子操作间的关系
- Synchronized-with
- Happens-before
- std::memory_order
- Relaxed ordering
- Release-Consume ordering
- Release-Acquire ordering
- Sequentially-consistent ordering
- 总结

概念
在 cpp11 标准原子库中(std::atomic),大多数函数都接受一个参数:std::memory_order:
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
复制代码
std::memory_order被称为内存排序约束。它们中的每一个都有其预期目的。std::memory_order 指定内存访问,包括常规的非原子内存访问,如何围绕原子操作排序。在没有任何制约的多处理器系统上,多个线程同时读或写数个变量时,一个线程能观测到变量值更改的顺序不同于另一个线程写它们的顺序。其实,更改的顺序甚至能在多个读取线程间相异。一些类似的效果还能在单处理器系统上出现,因为内存模型允许编译器变换。
cpp原子库中所有原子操作的默认行为是序列一致的顺序(memory_order_seq_cst, 见后述讨论)。该默认行为可能有损性能,不过也可以传递给线程对原子操作额外的 std::memory_order 参数,以指定附加制约,在原子性外,编译器和处理器还必须强制该操作。
看到这里,不了解内存模型,原子操作等概念的可能不是特别明白上面这段解释,下面我们先来详细介绍这些基础概念。
内存模型基础
- 我们都知道为了避免 race condition,线程就要规定代码语句(语句块)的执行顺序。通常我们都是使用 mutex 加锁,后一线程必须等待前一线程解锁才能继续执行。第二种方式是使用原子操作来避免竞争访问同一内存位置。
- 所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直执行到结束,在执行完毕之前不会被任何其它任务或事件中断。原子操作是不可分割的操作,要么做了要么没做,不存在做一半的状态。如果读取对象值的加载操作是原子的,那么对象上的所有修改操作也是原子的,读取的要么是初始值,要么是某个修改完成后的存储值。因此,原子操作不存在修改过程中值被其他线程看到的情况,也就避免了竞争风险。
- 每个对象从初始化开始都有一个修改顺序,这个顺序由来自所有线程对该对象的写操作组成。通常这个顺序在运行时会变动,但在任何给定的程序执行中,系统中所有线程都必须遵循此顺序
- 如果对象不是原子类型,就要通过同步来保证线程遵循每个变量的修改顺序。如果一个变量对于不同线程表现出不同的值序列,就会导致数据竞争和未定义行为。使用原子操作就可以把同步的责任抛给编译器
- 内存模型,准确来说应该是多线程内存模型,也叫动态内存模型,多个线程对同一个对象同时读写时所做的约束,该模型理解起来要复杂一些,涉及了内存、Cache、CPU各个层次的交互,尤其是在多核系统中为了保证多线程环境下执行的正确性,需要对读写事件加以严格限制。std::memory_order就是用来做这事的,它实际上是程序员、编译器以及CPU之间的契约,遵守契约后大家各自优化,从而可能提高程序性能。 std::memory_order,它表示机器指令是以什么样的顺序被处理器执行的 ,一般现代的处理器不是逐条处理机器指令的。下面来简单举个例子说明一下(初始:x=y=0):
| 线程1 | 线程2 |
|---|---|
| ① x = 1; | ③ y=2; |
| ② r1 = y; | ④ r2 = x; |
假设编译器、CPU不对指令进行重排,也没有使用std::memory_order,且两个线程交织执行(假设以上四条语句都是原子操作)时共有4!/(2!*2!)=6种情况:
- ①②③④ -> r1=0,r2=1
- ③④①② -> r1=2,r2=0
- ①③④② -> r1=2,r2=1
- ①③②④ -> r1=2,r2=1
- ③①②④ -> r1=2,r2=1
- ③①④② -> r1=2,r2=1
从上面看,最终r1和r2的最终结果共有3种,r1= r2 = 0的情况不可能出现。但是当四条语句不是原子操作时。有一种可能是CPU的指令预处理单元看到‘线程1’的两条语句没有依赖性(不管哪条语句先执行,在两条指令语句完成后都会得到一样的结果),会先执行r1=y再执行x=1,或者两条指令同时执行,这就是CPU的多发射和乱序执行。对于线程2也一样。这样一来就有可能出来r1= r2= 0的结果。执行顺序可能就是:②④①③
另外一种r1= r2 = 0的情况是:线程1和线程线程2分别在不同的CPU核上执行,大家都知道CPU中是有Cache和RAM的,简单的理解一下程序的执行都是从RAM->Cache->CPU,执行完后CPU->Cache->RAM,有一种可能是当Core1和Core2都将x,y更新到L1 Cache中,而还未来得及更新到RAM时,两个线程都已经执行完了第二条语句,此时也会出现r1= r2= 0。
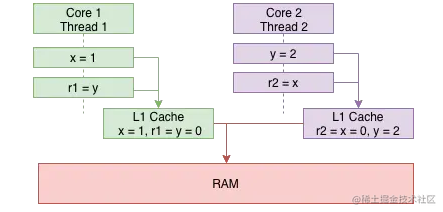
另外一个就是,从编译器层面也一样,为了获取更高的性能,它也可能会对语句进行执行顺序上的优化(类似CPU乱序)。
因此,在编译器优化+CPU乱序+缓存不一致的多重组合下,情况不止以上三种。但不管哪一种,都不是我们希望看到的。那么如何避免呢?最简单的,也是首选的,方案当然是std::mutex。因为使用mutex对比atomic更容易分析程序出现的各种错误,对于mutex的错误,大多数都是漏了加锁,或者加锁次序错乱等问题,但是如果使用atomic就比较难排查问题。那std::atomic是不是就没啥用呢,当然不是,当程序对代码执行效率要求很高,std::mutex不满足时,就需要std::atomic上场了,因为std::atomic主要是为了提高性能而生的。
现在的编译器基本都支持指令重排,上述的现象也只是理想情况下的执行情况,因为顺序一致性代价太大不利于程序的优化。但是有时候你需要对编译器的优化行为做出一定的约束,才能保证你的程序行为和你预期的执行结果保持一致,那么这个约束就是内存模型。 如果想要写出高性能的多线程程序必须理解内存模型,编译器会给你的程序做静态优化,CPU 为了提升性能也有动态乱序执行的行为。总之,实际编程中程序不会完全按照你原始代码的顺序来执行,因此内存模型就是程序员、编译器、CPU 之间的契约。编程、编译、执行都会在遵守这个契约的情况下进行,在这样的规则之上各自做自己的优化,从而提升程序的性能。
原子操作间的关系
多线程中要保证race-condition情况下的正确运行,mutex或者atomic限制是必要的,mutex我们前面的文章已经介绍过可以理解为就是synchronizes-with的关系,而atomic的限制有两种关系:synchronizes-with和happens-before的限制,确保在线程之间运行的顺序保证。
Synchronized-with
The synchronizes-with relationship is something that you can get only between operations on atomic types. Operations on a data structure (such as locking a mutex) might provide this relationship if the data structure contains atomic types and the operations on that data structure perform the appropriate atomic operations internally, but fundamentally it comes only from operations on atomic types. if thread A stores a value and thread B reads that value, there’s a synchronizes-with relationship between the store in thread A and the load in thread B.
从synchronizes-with的定义中我们可以看出,这种关系讲的就是线程之间的原子操作关系。
Happens-before
it specifies which operations see the effects of which other operations. if operation A on one thread inter-thread happens-before operation B on another thread, then A happens-before B.
这个概念可以分为单线程和多线程:
- 对于单线程之间的执行顺序当然是很直观的,如果一个操作 A 排列在另一个操作 B 之前,那么这个操作 A happens-before B,一般单线程叫A sequenced-before B。但如果多个操作发生在一条声明中(statement),那么通常他们是没有 happens-before 关系的,因为他们是未排序的。
- 对于多线程而言, 如果一个线程中的操作A先于另一个线程中的操作B, 那么 A happens-before B(一般多线程间操作叫A inter-thread happens-before B)。一般来说
inter-thread happens-before才是用来表示两个线程中两个操作被执行的先后顺序的一种描述。happens-before具有可传递性。如果Ahappens-beforeB,Bhappens-beforeC,则有Ahappens-beforeC;而且当store操作A与load操作B发生同步时,则Ahappens-beforeB; - Inter-thread happens-before 可以与 sequenced-before 关系结合:如果 A sequenced-before B, B inter-thread happens-before C, 那么 A inter-thread happens-before C. 这揭示了如果你在一个线程中对数据进行了一系列操作,那么你只需要一个 synchronized-with 关系, 即可使得数据对于另一个执行操作 C 的线程可见。
我们举个例子来简单说明一下这几种关系,看下面的程序,write_x_then_y()与read_y_then_x()运行在不同的thread:
atd::atomic<bool> x(false);
atd::atomic<bool> y(false);
void write_x_then_y()
{
x.store(true,std::memory_order_relaxed); // 1
y.store(true,std::memory_order_release); // 2
}
void read_y_then_x()
{
while(!y.load(std::memory_order_acquire)); // 3
if(x.load(std::memory_order_relaxed)){ // 4
// do something
}
}
复制代码
上面的例子中,x原子变量采用的是relaxed order, y原子变量采用的是acquire-release order
- 两个线程中的y原子存在synchronizes-with的关系,也就是语句②和③属于synchronizes-with关系,因为它们本身就是原子间的操作store和load。
- read_y_then_x的load与 write_x_then_y的y.store存在一种happens-before的关系,虽然relaxed并不保证happens-before关系,但是在同一线程里,release会保证在其之前的原子store操作都能被看见(语句①一定在语句②前完成), acquire能保证通线程中的后续的load都能读到最新指(语句③也一定在语句④前完成)。所以当y.load为true的时候,x肯定可以读到最新值(true)。所以即使这里x用的是relaxed操作,所以其也能达到acquire-release的作用。
std::memory_order
内存的顺序描述了计算机CPU获取内存的顺序,内存的排序可能静态也可能动态的发生:
- 静态内存排序:编译器期间,编译器对内存重排
- 动态内存排序:运行期间,CPU乱序执行
静态内存排序是为了提高代码的利用率和性能,编译器对代码进行了重新排序;同样为了优化性能CPU也会进行对指令进行重新排序、延缓执行、各种缓存等等,以便达到更好的执行效果。虽然经过排序确实会导致很多执行顺序和源码中不一致,但是你没有必要为这些事情感到棘手足无措。任何的内存排序都不会违背代码本身所要表达的意义,并且在单线程的情况下通常不会有任何的问题。 但是在多线程场景中,无锁的数据结构设计中,指令的乱序执行会造成无法预测的行为。所以我们通常引入内存栅栏这一概念来解决可能存在的并发问题。内存栅栏是一个令 CPU 或编译器在内存操作上限制内存操作顺序的指令,通常意味着在 barrier 之前的指令一定在 barrier 之后的指令之前执行。 在 C11/cpp11 中,引入了六种不同的 memory order,可以让程序员在并发编程中根据自己需求尽可能降低同步的粒度,以获得更好的程序性能。这六种 order 分别是:
typedef enum memory_order {
memory_order_relaxed, // 无同步或顺序限制,只保证当前操作原子性
memory_order_consume, // 标记读操作,依赖于该值的读写不能重排到此操作前
memory_order_acquire, // 标记读操作,之后的读写不能重排到此操作前
memory_order_release, // 标记写操作,之前的读写不能重排到此操作后
memory_order_acq_rel, // 仅标记读改写操作,读操作相当于 acquire,写操作相当于 release
memory_order_seq_cst // sequential consistency:顺序一致性,不允许重排,所有原子操作的默认选项
} memory_order;
复制代码
除非为操作指定一个特定的序列,否则原子类型操作的内存序列默认都是memory_order_seq_cst。上面的六个类型可以统分为三大内存模型:
- 顺序一致性:memory_order_seq_cst,这个是默认的内存序,我们上面也多次提到,顺序一致性不能很好的利用硬件的资源才有了其他的内存序,大家都知道,在多核情况下,每个CPU核都有自己的cache,一个变量可能被多个CPU核读到自己的cache中运算,顺序一致性要求每一个CPU核修改了变量就要与其他CPU核的cache进行同步,这样就牵扯到CPU核之间的通信。所以顺序一致会增加CPU之间通信逻辑,因此相对消耗更多指令。
- 获取-释放序:memory_order_consume, memory_order_acquire, memory_order_release和memory_order_acq_rel;acquire 和 release虽然并没有sequence consistency那样强的约束,但是比relaxed order约束要强一个等级,另外acquire 和 release也引入了synchronize的关系。同步是成对的,在执行释放的线程和执行获取的线程之间。释放操作与读取写入值的获取操作同步。这意味着不同的线程仍然可以看到不同的排序,但这些排序是受限的。
- 自由序:memory_order_relaxed,不保证任何的指令执行顺序
前面也提到了,内存序的出现,目的是提升相关操作的性能。但使用顺序一致序(默认内存序,相较于其他序列,它是最简单的)时,对于在通常情况来说其实就已经够用了。
Relaxed ordering
- 标记为 memory_order_relaxed 的原子操作不是同步操作,不强制要求并发内存的访问顺序,只保证原子性和修改顺序一致性;
- Relaxed ordering的限定范围是同线程,在同一线程内对同一原子变量的访问不可以被重排,仍保持happens-before关系,
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<int> x = 0;
std::atomic<int> y = 0;
void f() {
int i = y.load(std::memory_order_relaxed); // 1 happen before 2
x.store(i, std::memory_order_relaxed); // 2
}
void g() {
int j = x.load(std::memory_order_relaxed); // 3
y.store(42, std::memory_order_relaxed); // 4
}
int main() {
std::thread t1(f);
std::thread t2(g);
t1.join();
t2.join();
std::cout << x << " - " << y << std::endl;
// 可能执行顺序为 4123,结果 x == 42, y == 42
// 可能执行顺序为 1234,结果 x == 0, y == 42
}
复制代码
- Relaxed ordering 不允许循环依赖,下面例子由于使用relaxed,线程f和g之间的操作是没办法保证依赖关系的:
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<int> x = 0;
std::atomic<int> y = 0;
void f() {
std::cout << "1\n";
int i = y.load(std::memory_order_relaxed); // 1
std::cout << "2\n";
if (i == 42) {
x.store(i, std::memory_order_relaxed); // 2
}
}
void g() {
std::cout << "3\n";
int j = x.load(std::memory_order_relaxed); // 3
std::cout << "4\n";
if (j == 42) {
y.store(42, std::memory_order_relaxed); // 4
}
}
int main() {
std::thread t1(f);
std::thread t2(g);
t1.join();
t2.join();
std::cout << x << " - " << y << std::endl;
// 一般的顺序是1234
// 结果不允许为 x = 42, y = 42
// 因为要产生这个结果,1 依赖 4,4 依赖 3,3 依赖 2,2 依赖 1
}
复制代码
- Relaxed ordering一般适用于只要求原子操作,不需要其它同步保障的情况。典型使用场景是自增计数器,比如 std::shared_ptr 的引用计数器,它只要求原子性,不要求顺序和同步:
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::atomic<int> x = 0;
void f() {
for (int i = 0; i < 1000; ++i) {
x.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::vector<std::thread> v;
for (int i = 0; i < 10; ++i) {
v.emplace_back(f);
}
for (auto& x : v) {
x.join();
}
std::cout << x; // 一定是输出 10000
}
复制代码
Release-Consume ordering
- 对于标记为 memory_order_consume 原子变量 x 的读操作 R,当前线程中依赖于 x 的读写不允许重排到 R 之前,其他线程中对依赖于 x 的变量写操作对当前线程可见
- 如果线程 A 对一个原子变量x的写操作为 memory_order_release,线程 B 对同一原子变量的读操作为 memory_order_consume,带来的副作用是,线程 A 中所有 dependency-ordered-before 该写操作的其他写操作(non-atomic和relaxed atomic),在线程 B 的其他依赖于该变量的读操作中可见
- 典型使用场景是访问很少进行写操作的数据结构(比如路由表),以及以指针为中介的 publisher-subscriber 场景,即生产者发布一个指针给消费者访问信息,但生产者写入内存的其他内容不需要对消费者可见,这个场景的一个例子是 RCU(Read-Copy Update)。该顺序的规范正在修订中,并且暂时不鼓励使用 memory_order_consume
#include <atomic>
#include <cassert>
#include <thread>
std::atomic<int*> x;
int i;
void producer() {
int* p = new int(42);
i = 42;
x.store(p, std::memory_order_release);
}
void consumer() {
int* q;
while (!(q = x.load(std::memory_order_consume))) {
}
assert(*q == 42); // 一定不出错:*q 带有 x 的依赖
assert(i == 42); // 可能出错也可能不出错:i 不依赖于 x
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
}
复制代码
consume语义是一种弱的acquire,它只对关联变量进行约束,这个实际编程中基本不用,且在某些情况下会自动进化成acquire语义(比如当用consume语义修饰的load操作在if条件表达式中时)。另外,cpp17标准明确说明这个语义还未完善,建议直接使用acquire。
Release-Acquire ordering
- 在release之前的所有store操作绝不会重排到(不管是编译器对代码的重排还是CPU指令重排)此release对应的操作之后,也就是说如果release对应的store操作完成了,则cpp标准能够保证此release之前的所有store操作肯定已经先完成了,或者说可被感知了;
- 在acquire之后的所有load操作或者store操作绝对不会重排到此acquire对应的操作之前,也就是说只有当执行完此acquire对应的load操作之后,才会执行后续的读操作或者写操作。
我们看下面的例子,由于①使用 了 memory_order_release的写操作 ,②对同一原子变量x进行了memory_order_acquire 的读操作,所以当②的while读到q不为null退出后,则往下的两个assert一定不出错,因为②的while退出,说明①一定执行完了,release-acquire对同一原子的WR操作规定了,release前的操作必定先发生(下面的01和02必定先与①执行)。
#include <atomic>
#include <cassert>
#include <thread>
std::atomic<int*> x;
int i;
void producer() {
int* p = new int(42); // 01
i = 42; // 02
x.store(p, std::memory_order_release); // 1 happens-before 2(由于 2 的循环)
}
void consumer() {
int* q;
while (!(q = x.load(std::memory_order_acquire))) { // 2
}
assert(*q == 42); // 一定不出错
assert(i == 42); // 一定不出错
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
}
复制代码
对于标记为 memory_order_release 的写操作 W,有以下一些限制(作用)
- 当前线程中的其他读写操作不允许重排到W之后;
- 若其他线程 acquire 该原子变量,则当前线程所有 happens-before 的写操作在其他线程中可见;
- 若其他线程 consume 该原子变量,则当前线程所有 dependency-ordered-before W 的其他写操作在其他线程中可见;
- 对于标记为 memory_order_acq_rel 的读改写(read-modify-write)操作,相当于写操作是 memory_order_release,读操作是 memory_order_acquire,当前线程的读写不允许重排到这个写操作之前或之后,其他线程中 release 该原子变量的写操作在修改前可见,并且此修改对其他 acquire 该原子变量的线程可见
- Release-Acquire ordering 并不表示 total ordering
#include <atomic>
#include <thread>
std::atomic<bool> x = false;
std::atomic<bool> y = false;
std::atomic<int> z = 0;
void write_x() {
x.store(true, std::memory_order_release); // 1 happens-before 3(由于 3 的循环)
}
void write_y() {
y.store(true, std::memory_order_release); // 2 happens-before 5(由于 5 的循环)
}
void read_x_then_y() {
while (!x.load(std::memory_order_acquire)) { // 3 happens-before 4,因为3使用了acquire
}
if (y.load(std::memory_order_acquire)) { // 4
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire)) { // 5 happens-before 6,因为5使用了acquire
}
if (x.load(std::memory_order_acquire)) { // 6
++z;
}
}
int main() {
std::thread t1(write_x);
std::thread t2(write_y);
std::thread t3(read_x_then_y);
std::thread t4(read_y_then_x);
t1.join();
t2.join();
t3.join();
t4.join();
// z可能为0:134执行则y为false,256执行则x为false,但1,2之间没有顺序关系
}
复制代码
- 为了使两个写操作有序,将其放到一个线程里
#include <atomic>
#include <cassert>
#include <thread>
std::atomic<bool> x = false;
std::atomic<bool> y = false;
std::atomic<int> z = 0;
void write_x_then_y() {
x.store(true, std::memory_order_relaxed); // 1 happens-before 2,因为2使用了release
y.store(true, std::memory_order_release); // 2 happens-before 3(由于 3 的循环)
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire)) { // 3 happens-before 4,因为3使用了acquire
}
if (x.load(std::memory_order_relaxed)) { // 4
++z;
}
}
int main() {
std::thread t1(write_x_then_y);
std::thread t2(read_y_then_x);
t1.join();
t2.join();
assert(z.load() != 0); // 顺序一定为 1234,z一定不为 0
}
复制代码
- 利用 Release-Acquire ordering 可以传递同步,我们看下面的例子,最终实现1234这样的执行顺序,1 happens-before 2,3 happens-before 4,因为2:happens-before 3,所以1234顺序是必然的:
#include <atomic>
#include <cassert>
std::atomic<bool> x = false;
std::atomic<bool> y = false;
std::atomic<int> v[2];
void f() {
// v[0]、v[1] 的设置没有先后顺序,但都 happens-before 1,因为1使用了release
v[0].store(1, std::memory_order_relaxed);
v[1].store(2, std::memory_order_relaxed);
x.store(true, std::memory_order_release); // 1 happens-before 2(由于 2 的循环)
}
void g() {
while (!x.load(std::memory_order_acquire)) { // 2:happens-before 3,因为2使用了acquire
}
y.store(true, std::memory_order_release); // 3 happens-before 4(由于 4 的循环)
}
void h() {
while (!y.load(std::memory_order_acquire)) { // 4 happens-before v[0]、v[1] 的读取
}
assert(v[0].load(std::memory_order_relaxed) == 1);
assert(v[1].load(std::memory_order_relaxed) == 2);
}
复制代码
- 使用读改写操作(memory_order_acq_rel)可以将上面的两个标记合并为一个,也能得到一样的效果,看下面的例子,也是必然安装123顺序执行:
#include <atomic>
#include <cassert>
std::atomic<int> x = 0;
std::atomic<int> v[2];
void f() {
v[0].store(1, std::memory_order_relaxed);
v[1].store(2, std::memory_order_relaxed);
x.store(1, std::memory_order_release); // 1 happens-before 2(由于 2 的循环)
}
void g() {
int i = 1;
// 如果x当前的值等于i则将x改写为2,返回true,如果不等则让i=x,并返回false
while (!x.compare_exchange_strong(i, 2, std::memory_order_acq_rel)) { // 2 happens-before 3(由于 3 的循环)
// x 为 1 时,将 x 替换为 2,返回 true
// x 为 0 时,将 i 替换为 x,返回 false
i = 1; // 返回 false 时,x 未被替换,i 被替换为 0,因此将 i 重新设为 1,再继续while
}
}
void h() {
while (x.load(std::memory_order_acquire) < 2) { // 3
}
assert(v[0].load(std::memory_order_relaxed) == 1);
assert(v[1].load(std::memory_order_relaxed) == 2);
}
复制代码
Sequentially-consistent ordering
- memory_order_seq_cst 是所有原子操作的默认选项,可以省略不写。对于标记为 memory_order_seq_cst 的操作,大概行为就是对每一个变量都进行上面所说的Release-Acquire操作,读操作相当于 memory_order_acquire,写操作相当于 memory_order_release,读改写操作相当于 memory_order_acq_rel,此外还附加一个单独的 total ordering,即所有线程对同一操作看到的顺序也是相同的。这是最简单直观的顺序,但由于要求全局的线程同步,因此也是开销最大的
#include <atomic>
#include <cassert>
#include <thread>
std::atomic<bool> x = false;
std::atomic<bool> y = false;
std::atomic<int> z = 0;
// 要么 1 happens-before 2,要么 2 happens-before 1
void write_x() {
x.store(true); // 1 happens-before 3(由于 3 的循环)
}
void write_y() {
y.store(true); // 2 happens-before 5(由于 5 的循环)
}
void read_x_then_y() {
while (!x.load()) { // 3 happens-before 4
}
if (y.load()) { // 4 为 false 则 1 happens-before 2
++z;
}
}
void read_y_then_x() {
while (!y.load()) { // 5 happens-before 6
}
if (x.load()) ++z; // 6 如果返回false则一定是2 happens-before 1
}
int main() {
std::thread t1(write_x);
std::thread t2(write_y);
std::thread t3(read_x_then_y);
std::thread t4(read_y_then_x);
t1.join();
t2.join();
t3.join();
t4.join();
assert(z.load() != 0); // z 一定不为0
// z 可能为 1(134256) 或 2(123456),
// 1和2 之间必定存在 happens-before 关系,顺序要么12,要么21
}
复制代码
总结
- cpp11中这些内存顺序相关的设计,主要还是为了从各种繁杂不同的平台上抽象出独立于硬件平台的并行操作。对于我们日常的开发工作,默认的顺序一致内存顺序memory_order_seq_cst足可以应付了,但是开发者想让多线程程序获得更好的性能的话,尤其是在一些弱内存顺序的平台上,建立原子操作间的内存顺序还是很有必要的,因为着能带来极大的性能提升,这也是一些弱一致性内存模型平台的优势。但是无锁编程确实比较难,而且想要完全写对那就成了变态难,因为他涉及到硬件,CPU,Cache和编译器,因此在没啃透之前,使用锁的方式才是明智的选择。
- 对于并行编程来说,可能最根本的,还是思考如何将大量计算的问题,按需分解成多个独立的、能够同时运行的部分,并找出真正需要在线程间共享的数据,实现为cpp11的原子类型。虽然有了原子类型的良好设计,实现这些都可以非常的便捷,但并不是所有的问题或者计算都适合用并行计算来解决,对于不适用的问题,强行用并行计算来解决会收效甚微,甚至起到相反效果。因此在决定使用并行计算解决问题之前,程序员必须要有清晰的设计规划。而在实现了代码并行后,进一步使用一些性能调试工具来提高并行程序的性能也是非常必要的。
参考:
《cpp Concurrency in Action》
为什么需要内存屏障 - 知乎 (zhihu.com)
高速缓存与一致性专栏索引 - 知乎 (zhihu.com)
此在没啃透之前,使用锁的方式才是明智的选择。
- 对于并行编程来说,可能最根本的,还是思考如何将大量计算的问题,按需分解成多个独立的、能够同时运行的部分,并找出真正需要在线程间共享的数据,实现为cpp11的原子类型。虽然有了原子类型的良好设计,实现这些都可以非常的便捷,但并不是所有的问题或者计算都适合用并行计算来解决,对于不适用的问题,强行用并行计算来解决会收效甚微,甚至起到相反效果。因此在决定使用并行计算解决问题之前,程序员必须要有清晰的设计规划。而在实现了代码并行后,进一步使用一些性能调试工具来提高并行程序的性能也是非常必要的。
参考:
《cpp Concurrency in Action》
为什么需要内存屏障 - 知乎 (zhihu.com)
高速缓存与一致性专栏索引 - 知乎 (zhihu.com)
www.apiref.com/cpp-zh/cpp/…