【ARIXV2209】Multi-Scale Attention Network for Single Image Super-Resolution
代码:https://github.com/icandle/MAN
这是来自南开大学的工作,将多尺度机制与大核注意机制结合,用于图像超分辨率。
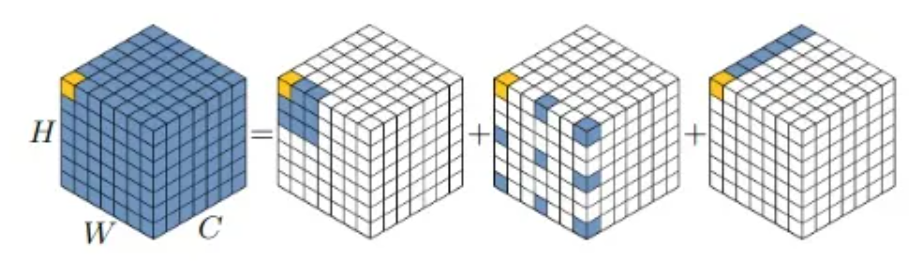
2022年初,大核卷积火了,Visual Attention Network (VAN)提出将大核卷积划为:depth-wise conv,dilated conv,和 point-wise conv 的组合(如下图所示)。VAN作者指出,图像超分任务中使用VAN,发现了一个很重要的问题:含膨胀的深度卷积会为超分任务带来“块状伪影(blocking artifacts)”
作者提出的方法叫做 Multi-scale Attention Network(MAN),总体框架如下图所示。核心模块为MAB,是一个 Transformer block,由 attention 和 FFN 组成。其中,attention 为 MLKA,FFN 为 GSAU。需要注意的是,最后还使用了一个LKAT,下面分别进行详细介绍。
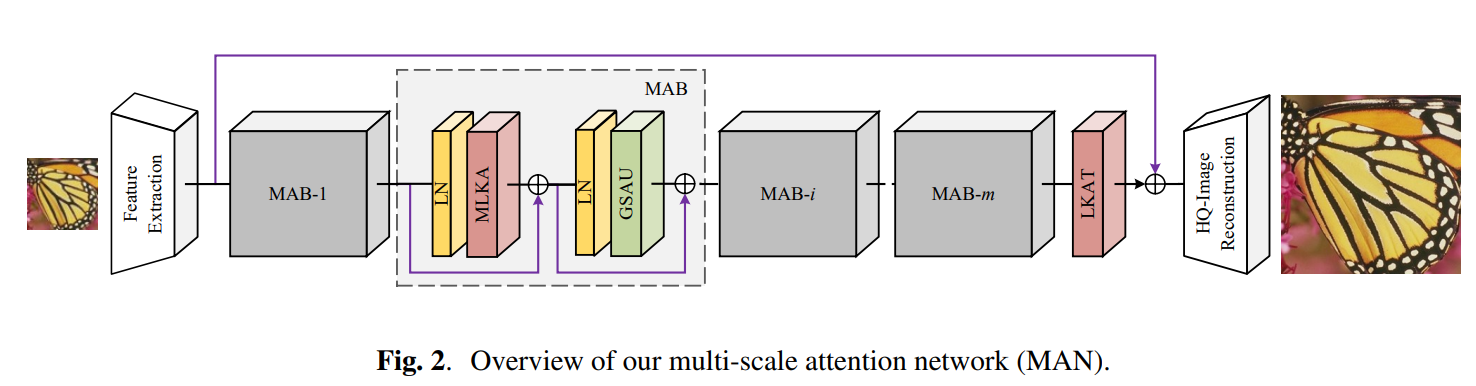
1、Multi-scale Large Kernel Attention (MLKA)
MLKA首先使用 Point-wise conv 改变通道数,然后将特征 split 成三组,每个组都使用 VAN 里提出的大核卷积来处理(即depth-wise conv,dilated conv,和 point-wise conv 的组合)。三组分别使用不同尺寸的大核卷积(7×7、21×21、35×35),膨胀率分别设置为(2,3,4)。

使用深度膨胀卷积会带来“块状伪影”问题。因此在分组后,作者引入门控聚合来动态调整LKA的输出。即上图中最上面的DWConv。在对应组中,与下方深度卷积使用的核尺寸一致,并将该卷积的输出与对应组中LKA的输出做逐元素乘法。作者将这一操作称为门控聚合,并且进行了可视化实验以说明其效果。
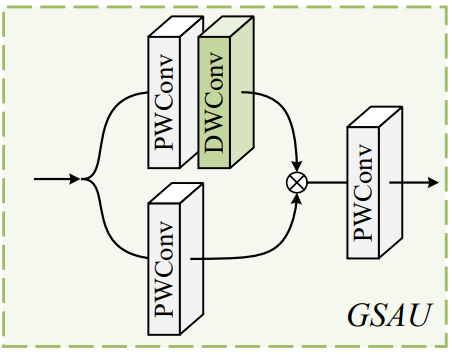
2、 Gated Spatial Attention Unit (GSAU)
普通的FFN是两个 point-wise conv 。为了进一步增强特征表示,作者引入了 spatial self-attention 和 gated linear unit (GLU) 的思路,具体如下图所示,上面分支加入了一个 dwconv 对结果加权,两个分支的特征进一步加强了特征表示。
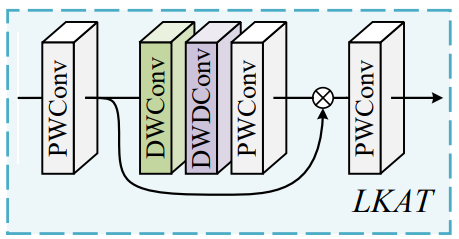
3、Large Kernel Attention Tail (LKAT)
作者采用了以前超分方法的范式,将一个LKA用在网络尾部,以进一步从特征中总结出可用的信息,提升图像修复性能。
本论文以VAN为基础,通过加入多尺度以及门控机制解决“块状伪影”问题,取得了非常好的性能。实部分可以参考作者论文,这里不再过多介绍。







![[C语言]柔性数组](https://img-blog.csdnimg.cn/58124fa67317420a88e80898b086f615.png)