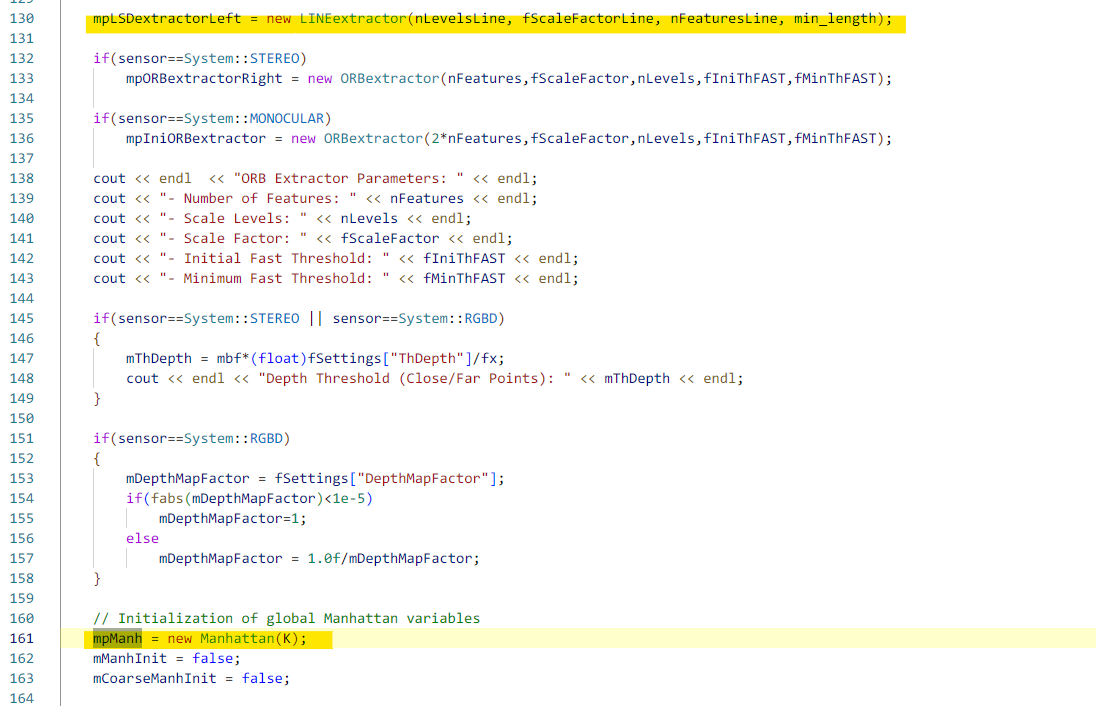
目录
- 前言
- 一、堆
- 二、堆的实现(重点)
- 1. 数据类型重定义
- 2. 堆结构的定义
- 3. 堆结构的重定义
- 三、堆中常见的基本操作(重点)
- 1. 声明
- 2. 定义
- (1)初始化
- (2)销毁
- (3)插入数据
- (4)向上调整
- (5)删除堆顶数据
- (6)向下调整
- (7)判空操作
- (8)堆顶元素
- (9)打印堆中的数据
- 四、堆排序(重要)
- 1. 采取额外的空间进行建堆
- 2. 向上调整算法进行建堆
- 3. 向下调整算法进行建堆
- 4. 堆排序的优化
- 五、TopK问题
- 六、测试堆逻辑
- 1.测试插入数据
- 2.测试删除堆顶元素
- 3.测试堆排序
前言
堆是一个很重要的数据结构,在排序中充当的角色非常重要,从而后面会衍生出一个堆排序,其效率是非常高的,用途广泛!!!
一、堆
说到堆,很多人可能会想到现实生活中的一些场景,比如垃圾堆,山堆…,比如:


数据结构中的堆确实长得和它很像,堆的本质其实在逻辑上是一棵完全二叉树,在物理上是存储在一个连续的数组中的,我们接下来所要学习的堆根据其性质的不同分为两类:大堆和小堆。大堆和小堆的不同是根据其中存储的数据的规律来进行分类的。
- 小堆:树中的所有父亲结点存储的值都要比子树小
- 大堆:树中的所有父亲结点存储的值都要比子树大
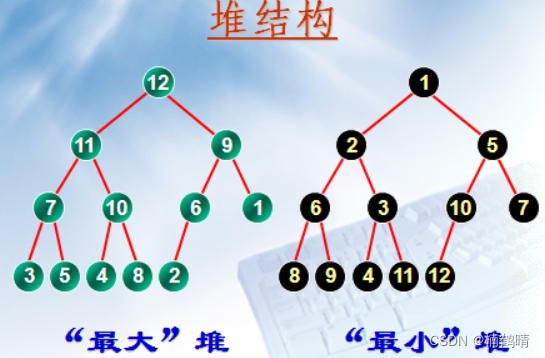
其实我们需要知道:堆本质就是一棵完全二叉树,然后我们将其中的结点按照顺序依次从数组下标为0的位置开始存储,从二叉树中的结点在数组中的下标就会满足一定的关系,我们知道,二叉树中的每一个子树都是由根节点和其子树组成的,所以,通过数组的顺序存储,我们就能够方便地表示出树中的父亲们与其孩子的关系,比如:知道父亲结点下标,如果左右孩子存在,那么就可以方便地算出左右孩子的下标,即在数组中的位置,即:若父亲的下标为i的话,左孩子如果存在,则左孩子的下标为:2i+1,右孩子如果存在,则右孩子的下标为:2i+2,这个是根据上面文章中讲解的二叉树的顺序存储中的一个性质来得出的。
二、堆的实现(重点)
1. 数据类型重定义
和前面学习的数据结构一样,我们为了方便存储各种数据类型,我们会先对堆存储的数据类型进行重定义
// 数据类型重定义
typedef int HeapDataType;
2. 堆结构的定义
我们知道,堆本质就是一棵完全二叉树,我们是采用顺序存储的方式来实现堆的,而前面我们学习过顺序表的实现,所以这里堆的实现我们可以类比顺序表的实现,我们知道堆是一棵完全二叉树,所以我们可以考虑将堆中树的结点存储的值,按照一定的顺序存储在一个数组中,那么数组当然就是采用动态开辟的数组比较方便进行随时的扩容,其实现可以参考顺序表的实现,所以,堆的结构中需要包含一个数据域,就是动态数组,还需要一个能够随时记录堆中存储的有效数据个数的变量,还需要一个可以随时记录堆中数组的容量的变量。
// 堆结构定义
struct Heap
{
HeapDataType* data; // 数据域
size_t size; // 记录堆中有效的数据个数
size_t capacity; // 堆的容量
};
3. 堆结构的重定义
和前面学习的数据结构实现一样,为了在使用的过程中能够方便表示堆,所以我们考虑堆堆类型进行重定义,这样后面再使用的时候就不用加上struct这个关键字了。
// 堆结构定义
typedef struct Heap
{
HeapDataType* data; // 数据域
size_t size; // 记录堆中有效的数据个数
size_t capacity; // 堆的容量
}Heap;
三、堆中常见的基本操作(重点)
1. 声明
// 初始化
void HeapInit(Heap* php);
// 销毁
void HeapDestroy(Heap* php);
// 插入数据
void HeapPush(Heap* php, HeapDataType data);
// 删除堆顶数据
void HeapPop(Heap* php);
// 向上调整
void AjustUp(HeapDataType* a, size_t child);
// 向下调整
void AjustDown(HeapDataType* a, size_t size, size_t child);
// 判空操作
bool HeapEmpty(Heap* php);
// 堆顶元素
HeapDataType HeapTop(Heap* php);
// 打印堆中的数据
void HeapPrint(Heap* php);
在上面各个操作中的声明中,我们同样注意到参数中传的是堆的地址,而不是堆本身,原因和前面学习的数据结构是一样的。其中的向上调整算法和向下调整算法是堆中新学的算法,比较重要,后面会详细进行介绍,我们需要知道的就是调整的本质是堆数组中的数据的位置进行调整,保证调整后的结构仍然满足堆的性质。
在上面的基础上,也可以根据实际需求增加一个获取堆中有效数据个数的函数,和一个获取堆中数组当前容量的函数。
2. 定义
(1)初始化
初始化函数中需要做什么主要还是取决于这个结构中存在什么内容,堆结构中存在一个动态开辟的指针,所以需要对其进行初始化,一般情况下都是先将指针置成空指针,防止出现野指针导致野指针的访问从而造成程序崩溃,同时我们也需要对其中的size和capacity进行初始化,因为刚开始堆中啥数据都没有。
// 初始化
void HeapInit(Heap* php)
{
assert(php);
php->data = NULL;
php->size = php->capacity = 0;
}
(2)销毁
销毁函数中本质是需要对堆中向系统申请的空间进行释放,防止出现内存泄露,释放完之后最好也是需要对该指针进行置空操作。
// 销毁
void HeapDestroy(Heap* php)
{
assert(php);
free(php->data);
php->data = NULL;
php->size = php->capacity = 0;
}
(3)插入数据
在插入函数中首先需要注意是否可以向空间中插入数据,即空间是否已经满了,如果已经满了,那么首先需要考虑扩容问题,扩容的基本操作和顺序表中基本保持一致,这里需要注意一个特殊的点,就是在申请新空间的时候,我们需要临时自己先创建一个指针变量,而不能直接将realloc函数的返回值赋给我们堆中的数据域,因为扩容可能会出现失败,一旦失败,函数就会返回NULL,那你如果那样操作的话,就会将空指针赋给我们原先的指针了,那么如果那样操作的话,原来的指针变量就变成了空指针,那么原来空间中的数据也将找不到了。堆中的插入数据算法中,我们在插入数据的时候,只是将数据插入到堆中数组的最后一个位置,那么这个时候,插入数据之后,堆中的数据之间可能仍然满足堆的性质,也可能不满足堆的性质,所以,在插入数据之后我们需要对堆中的数据做进一步的调整,以保证插入数据之后,数组中的数据之间仍然可以保持堆的性质。
// 插入数据
void HeapPush(Heap* php, HeapDataType data)
{
assert(php);
// 考虑是否需要进行扩容
if (php->size == php->capacity)
{
size_t newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HeapDataType* tmp = (HeapDataType*)realloc(php->data, sizeof(HeapDataType) * newCapacity);
if (tmp == NULL)
{
printf("realloc fail\n");
return;
}
php->data = tmp;
php->capacity = newCapacity;
}
// 将数据插入到数组
php->data[php->size++] = data;
// 向上调整,保证插入数据之后,该树还能满足堆的性质
AjustUp(php->data, php->size - 1);
}
在插入数据之后,影响到的只是根节点到插入的位置的路径,其他路径不受影响。所以后期调整就是只需要调整这条路径而已,不需要调整其他位置。
(4)向上调整
向上调整算法是配合插入数据算法使用的,因为插入数据的时候,我们只需要将数据尾插到数组中,但是会存在一个问题,插入数据之后,数组中数据的特性不满足堆的性质了,那么此时我们就需要对数组进行向上调整处理,通过这样的分析,我们知道向上调整算法需要的条件有调整的数组和调整的起始位置,调整的数组一般是堆中的数组,调整的起始位置一般是插入数据的位置,即数组中记录有效数据的最后一个位置,也就是php->size--1的位置(数组下标是从0开始的)。
// 向上调整
void AjustUp(HeapDataType* a, size_t child)
{
// 调整为小堆
size_t parent = (child - 1) / 2;
while (child > 0)
{
// 调整成小堆
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
// 往上进行更新,直到根为止
child = parent;
parent = (child - 1) / 2;
}
else
{
// 在某一时刻,不需要调整了,则退出循环
break;
}
}
}
这里以小堆为例:在调整的过程中,我们是从数组中最后一个元素的位置开始的,不断的向上进行与父亲结点存储的值进行对比,如果出现孩子的值比父亲的值大,那么就需要交换此时的父亲和孩子的值,一直交换到child到达根节点为止,当然也可能出现比较好的情况,就是在交换的半途中就出现了满足堆的性质,那么此时就不再需要继续向上进行调整了。
时间复杂度的分析:
最好的情况:插入数据之后,数据仍然保持堆的性质,不需要进行调整
最坏的情况:插入数据之后,数据不能保持堆的性质,需要向上进行调整,如果此时该调整其实位置的值是数据中的最小(大)值,那么这次调整就需要一一直调整到根节点,显然,从最后一层一直调整到根节点,调整的次数就是该二叉树的高度次,根据上篇文章学习的性质可以知道:O(log2(N+1)),简化为:O(logN)
(5)删除堆顶数据
删除算法和前面学习的数据结构类似,我们并不需要实际地将数据从内存移除,而只需要将我们在结构中定义记录有效数据的变量的值减一即可,其实本质是因为我们在遍历打印堆中的数组的时候,循环变量的范围就是以这个有效数据个数为准的。
删除堆顶数据算法的思路:首先交换数组第一个数据和最后一个数据的值,然后删除最后一个数据,这个过程中的操作就是让数组中有效数据个数减一即可。然后再进行向下调整。
- 交换数组中第一个位置的值和最后一个位置的值:原先的堆顶元素就到达最后一个位置了
- 数组中有效数据个数减一:从逻辑的角度来看,就相当于删除了此时数组中的最后一个元素,因为最后位置的元素已经不属于数组中的有效数据了
- 向下调整:当我们将原先最后一个位置的数据放到堆顶的时候,此时堆中的数据不一定满足堆的性质,所以此时我们需要从根节点开始堆数组中的数据进行向下调整,以保证堆中的数据
之间仍然能够满足堆的性质。
// 删除堆顶数据
void HeapPop(Heap* php)
{
assert(php);
assert(php->size > 0);
Swap(&php->data[0], &php->data[php->size - 1]);
// 向下调整
AjustDown(php->data, php->size, 0);
}
(6)向下调整
向下调整算法一般是配合删除堆顶数据算法使用的,因为我们在删除堆顶数据算法中首先将数组中第一个数据和最后一个数据的值进行交换,交换之后,就会导致原来的堆结构受到影响,所以此时我需要对堆中的数组中的数据进行调整,使数组中的数据仍然能够保持堆的性质。向下调整算法需要具备的条件:调整的数组,调整的起始位置,数组中的有效数据个数。
调整的数组:给出需要调整的数据,使数组调整后保持堆的性质
调整的起始位置:一般情况下,向下调整算法都是从数组的第一个位置开始调整的
数组中有效数据个数:主要是为了防止在调整的过程中发生数组越界
向下调整算法的基本思路:
- 以小堆为例的话,先找到调整的结点的左右孩子中的最小值,比如为左孩子,再将左孩子的值和父亲结点的值进行交换,交换完成之后,更新父亲,找到新的孩子,继续重复上述的操作,直到找到的孩子的结点的下标是超出数组的有效数据个数的,那么就说明此时该结点的孩子是不存在的。
- 以大堆为例的话,先找到调整的结点的左右孩子中的最大值,比如为左孩子,再将左孩子的值和父亲结点的值进行交换,交换完成之后,更新父亲,找到新的孩子,继续重复上述的操作,直到找到的孩子的结点的下标是超出数组的有效数据个数的,那么就说明此时该结点的孩子是不存在的。
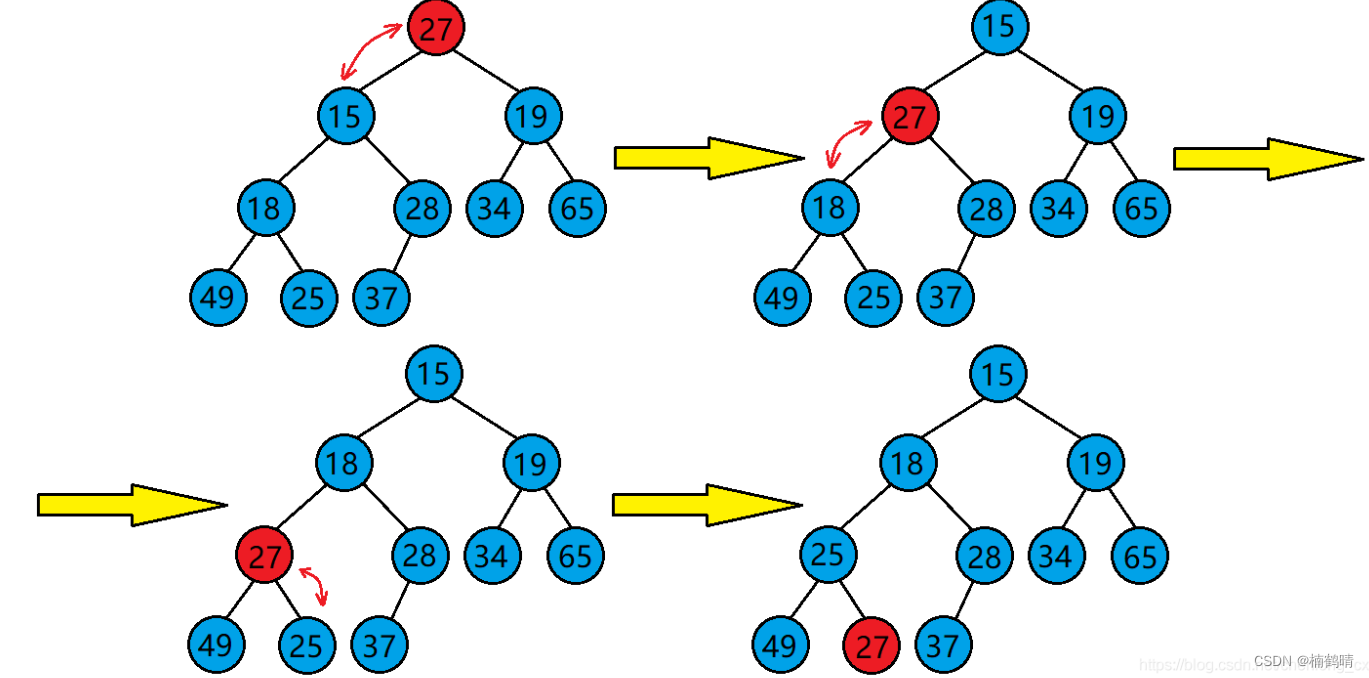
// 向下调整
void AjustDown(HeapDataType* a, size_t size, size_t root)
{
size_t parent = root;// 一般都是从根开始进行调整
size_t child = parent * 2 + 1; // 记录左右孩子中最小的那个孩子的下标
while (child < size)
{
// 找到左右孩子中最小的那个
if (child + 1 < size && a[child + 1] < a[child])
{
child++;
}
// 比较最小孩子与父亲的大小
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
时间复杂度分析:
分析的道理和向上调整算法中的分析思路基本一致,最坏的情况就是从根结点一致沿着对应的祖先路径,一直调整到最后一层,所以显然调整的次数也是二叉树的高度次,为:O(logN)
上面的代码中再找左右孩子中的最小结点的时候用的思路是非常重要的,其中先假设左孩子为最小的那个孩子结点,然后如果右孩子存在的话,那么再让左孩子和右孩子结点的值进行比较,如果发现右孩子的结点存储的值比左孩子结点存储的值小的话,那么就更新原来记录最小孩子结点的那个变量,上面代码为child
(7)判空操作
判空操作主要是通过堆中的记录有效数据个数的变量来进行判断的,如果该变量为0,说明此时堆为空,如果该变量的值不为0,那么就说明此时堆中存在数据,该堆不为空。
判空操作函数主要是在后面的堆排序中应用比较广泛,一般情况会配合取堆顶元素和删除堆顶元素算法进行使用
// 判空操作
bool HeapEmpty(Heap* php)
{
assert(php);
return php->size == 0;
}
(8)堆顶元素
堆顶元素起始就是数组中存在的第一个位置的元素,堆顶元素就是整个数据中的最大值或者最小值。当该堆为大堆时,此时堆顶元素为最大值。当该堆为小堆时,此时堆顶元素为最小值。
堆顶元素算法在堆排序中应用也是非常广泛的,一般会配合删除堆顶元素和判断堆是否为空算法进行使用。
// 堆顶元素
HeapDataType HeapTop(Heap* php)
{
assert(php);
return php->data[0];
}
(9)打印堆中的数据
打印堆中的数据其实本质就是在遍历堆中的数据,其实就是在遍历数组中的数据,使用一个循环就可以将数组中的数据打印出来了。
// 打印堆中的数据
void HeapPrint(Heap* php)
{
assert(php);
for (int i = 0; i < php->size; i++)
{
printf("%d ", php->data[i]);
}
printf("\n");
}
四、堆排序(重要)
场景:一般就是给定一组数据(数组)还有数据个数,将数据进行排序。
1. 采取额外的空间进行建堆
- 声明
// 堆排序
void HeapSort(HeapDataType* a, size_t size);
- 定义
// 堆排序
void HeapSort(HeapDataType* a, size_t size)
{
assert(a);
// 建堆
Heap hp;
HeapInit(&hp);
for (int i = 0; i < size; i++)
{
HeapPush(&hp, a[i]);
}
int j = 0;
// 每次不断取剩余数据中的最小值依次放到原来数组中,第一次取就是最小值,第二次就是次小值,以此类推。
while (!HeapEmpty(&hp))
{
a[j++] = HeapTop(&hp);
HeapPop(&hp);// 要知道中是边删除边调整的
}
// 销毁
HeapDestroy(&hp);
}
基本思路:首先将数组中的数据依次插入到堆中,数据在堆中就会满足堆的性质,其中堆顶元素就是整个数据的最大值或者最小值。然后我们通过每次取堆顶元素的数据重新从数组的开头开始依次放入数组,注意取完堆顶元素之后需要堆取的堆顶元素进行删除并调整数组。比如:此时堆为小堆的话,第一次取的就是数据中的最小值,取完之后将该值删除之后,第二次取堆顶元素时,取的就是剩余数据的最小值,每次按照顺序放入数组中,那么显然最终数据可以成功排成一个升序的序列。
时间复杂度的分析:
在将数据插入到堆的过程中,每次插入数据中都需要进行向上调整,时间复杂为O(NlogN),删除数据的过程中需要进行向下调整,平均为:O(NlogN),所以堆排序的时间复杂度为O(NlogN)。
空间复杂度的分析:
显然上面的算法中需要新建一个额外的堆,所以空间复杂度为O(N)。
注意:上面的算法中空间复杂度为O(N),显然是比较挫的,其本质原因就在于建堆算法中,采取的是额外建堆的方式,那么有没有一种比较好的算法能够避免这么大的空间复杂度呢?显然我们需要在原数组上进行建堆,那么这里我们将详细介绍两种比较优秀的建堆算法。
2. 向上调整算法进行建堆
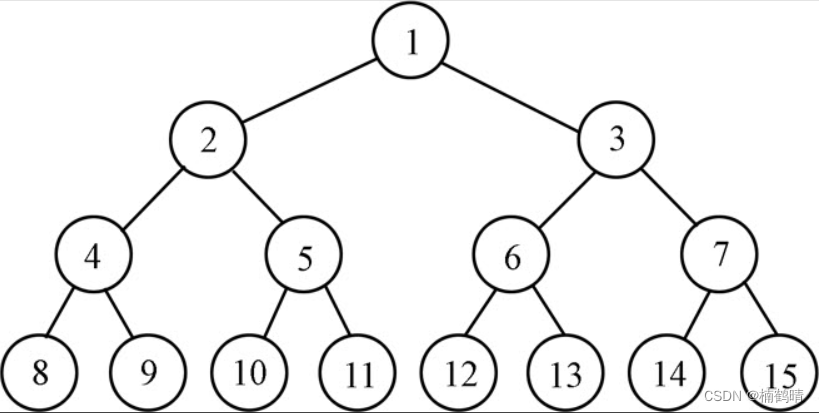
比如:我们将上面满二叉树中存储的值先随机放到一个数组中,从数组下标为1的位置开始,也就是从第二个位置开始,依次向后进行向上调整。当堆中只有一个数据的时候,显然是不需要进行调整的,所以我们是从第二个位置开始才需要进行调整。当调整第二个位置的时候,那么就能够使当前调整位置以上的所以树结构都能够满足堆的性质,当调整第三个位置的时候,同样也能够使调整以上的树的结构满足堆的性质,依次类推,当我们调整到最后一个位置的元素之后,那么就能够使所有的数据都满足堆的性质,这就是使用向上调整算法直接在原数组上进行建堆的思想。
- 时间复杂度的计算(难点)
这个算法的时间复杂度的计算需要使用到高中学习的一个解决等差乘以等比的求和方法:错位相减法。计算稍微复杂一点
证明过程:
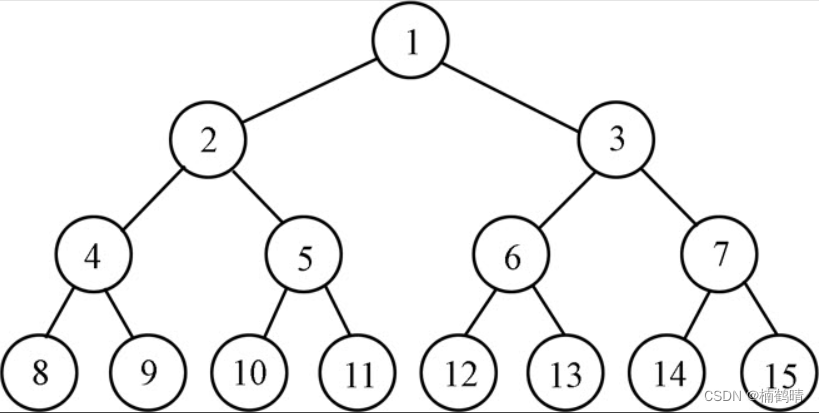
假设以满二叉树为例,树的高度为h,从第二层开始调整,第二层的结点数位:2^1,需要调整的次数为1,所以第二层的总调整数就是:2 ^1*1,第三层的结点数为:2 ^2,需要调整的次数为:2,所以第三层的总调整数就是:2 ^2 * 2,以此类推,到第h层,第h层的结点数位:2^(h-1),需要调整的次数为(h-1),所以第h层的总调整数就是:2 ^(h-1) * (h-1)。所以总的时间复杂度为:
T(N) = 2 ^1 * 1 + 2 ^2 * 2 + … + 2 ^(h-1) * (h-1)
使用错位相减法的求解过程如下:

代码:
// 向上调整算法建堆
void CreateHeapUp(int* a, int size)
{
for (int i = 1; i < size; i++)
{
AjustUp(a, i);
}
}
3. 向下调整算法进行建堆
向下调整算法的思想:从倒数第一个非叶子结点开始,向下进行调整,使每次调整之后,调整的结点以下的结构能够满足堆的性质,依次类推,当调整到根结点时,从根节点向下进行调整,那么就能够使整个树都能够满足堆的性质。
- 为什么是从倒数第一个非叶子结点开始调整呢?为啥不从最后一个结点开始进行调整?
我们知道我们这里是向下进行调整,如果调整的是叶子节点,那么调整的结点下面没有对应的子树,显然调整是没有意义的,所以我们需要从倒数第一个非叶子结点开始进行调整 - 倒数第一个非叶子结点的下标怎么算呢?
固定算法,就是最后一个结点的父亲结点,也就是你首先需要知道最后一个结点的下标,假如为:i,那么就可以通过i来求其父亲:(i-1)/2。
具体的时间复杂度的证明过程如下:

代码:
// 向下调整算法建堆
void CreateHeapDown(int* a, int size)
{
for (int i = (size - 1 - 1) / 2; i >= 0; i--)
{
AjustDown(a, size, i);
}
}
4. 堆排序的优化
如果我们要将数据排成升序,那么我们需要将原来数组建立成一个大堆,因为大堆中堆顶的数据就是整个数据的最大值,我们每次将堆顶的数据和堆的最后一个数据进行交换,那么最大的数据就到了最后一个位置,此时我们再将堆的范围缩小一个数据,再对堆中的数据进行调整,使数据仍然能够保持大堆的性质,这样一来,堆顶的数据就是剩余数据的最大值,此时同样和最后一个数据进行交换,此时所有数据的次大数就到达倒数第二个位置,依次类推,也就是每次将剩余数据的最大值调整到对应数据的最后一个位置,然后缩小堆的范围,再对剩下堆中的数据进行调整,以保证大堆的性质。
代码1:使用向下调整算法实现堆排序
// 堆排序的优化
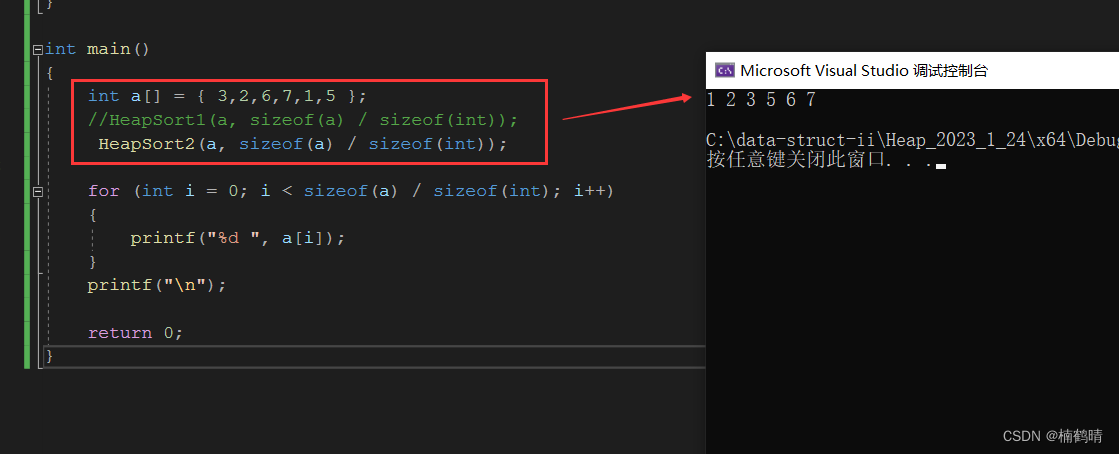
void HeapSort1(int* a, int size)
{
CreateHeapDown(a, size);
int end = size - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AjustDown(a, end, 0);
end--;
}
}
代码2:使用向上调整算法实现堆排序
// 堆排序的优化
void HeapSort2(int* a, int size)
{
CreateHeapUp(a, size);
int end = size - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AjustDown(a, end, 0);
end--;
}
}
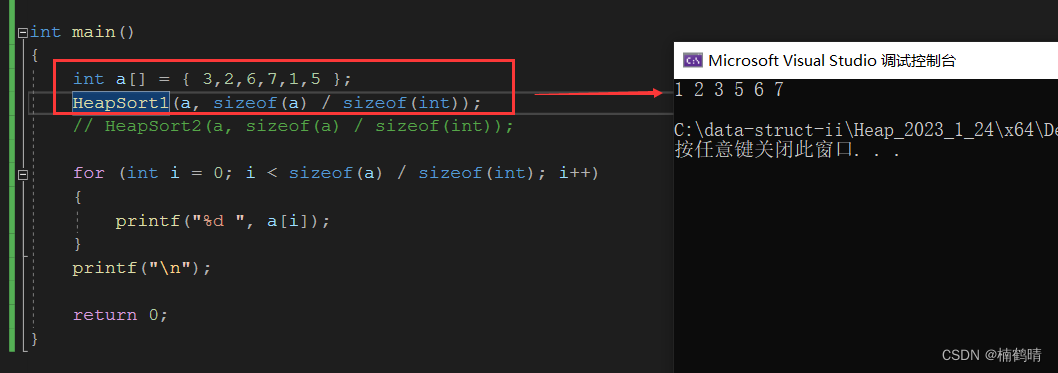
结果:
五、TopK问题
六、测试堆逻辑
1.测试插入数据
- 测试代码
void Test_Heap1()
{
Heap hp;
// 初始化
HeapInit(&hp);
// 插入数据
HeapPush(&hp, 1);
HeapPush(&hp, 3);
HeapPush(&hp, 2);
HeapPush(&hp, 6);
HeapPush(&hp, 8);
HeapPush(&hp, 2);
HeapPush(&hp, 5);
// 打印数据
HeapPrint(&hp);
// 销毁
HeapDestroy(&hp);
}
*测试结果:
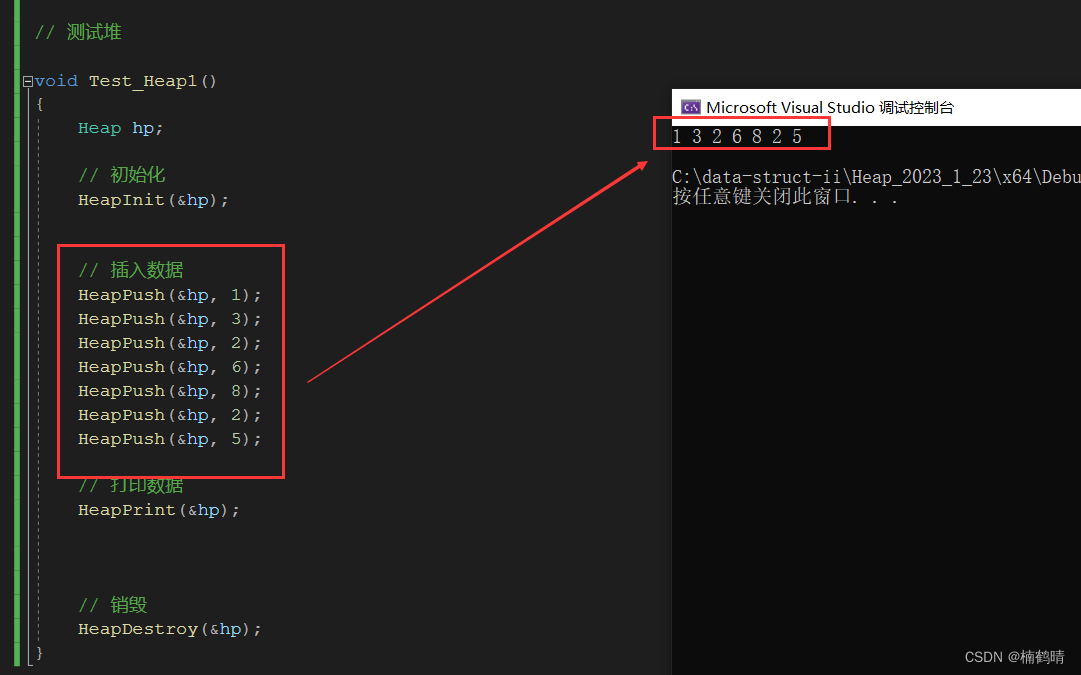
输出的结果显然满足小堆的性质
2.测试删除堆顶元素
- 测试代码1:数据删完了,继续删除
void Test_Heap2()
{
Heap hp;
// 初始化
HeapInit(&hp);
// 插入数据
HeapPush(&hp, 1);
HeapPush(&hp, 3);
HeapPush(&hp, 2);
HeapPush(&hp, 6);
HeapPush(&hp, 8);
HeapPush(&hp, 2);
HeapPush(&hp, 5);
// 打印数据
HeapPrint(&hp);
// 删除堆顶元素
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
// 销毁
HeapDestroy(&hp);
}
- 测试结果
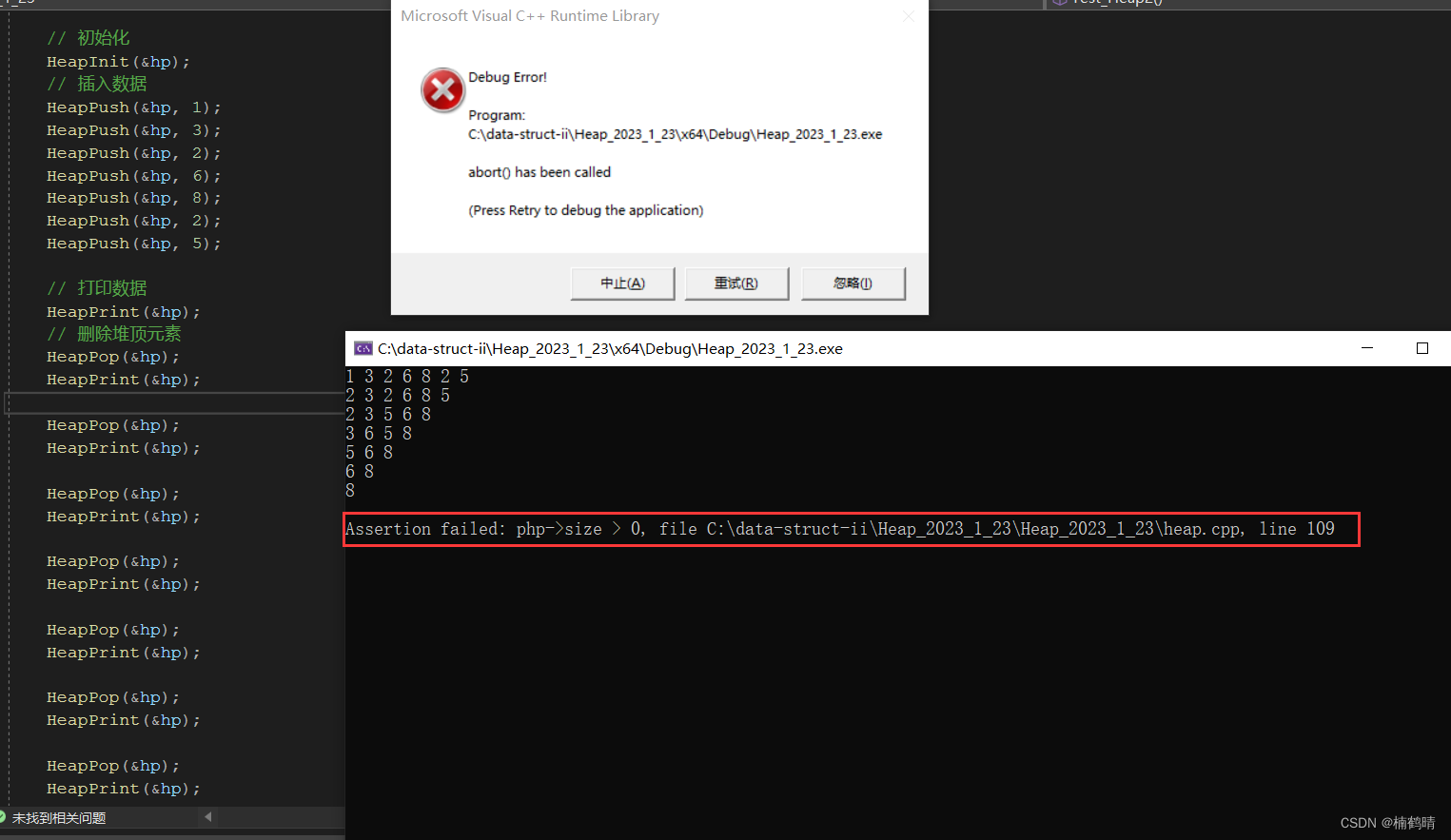
当数据删完了,就不能继续删除数据了 - 测试代码2:删除的次数不超过有效数据的个数
void Test_Heap2()
{
Heap hp;
// 初始化
HeapInit(&hp);
// 插入数据
HeapPush(&hp, 1);
HeapPush(&hp, 3);
HeapPush(&hp, 2);
HeapPush(&hp, 6);
HeapPush(&hp, 8);
HeapPush(&hp, 2);
HeapPush(&hp, 5);
// 打印数据
HeapPrint(&hp);
// 删除堆顶元素
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
/*HeapPop(&hp);
HeapPrint(&hp);*/
// 销毁
HeapDestroy(&hp);
}
- 测试结果
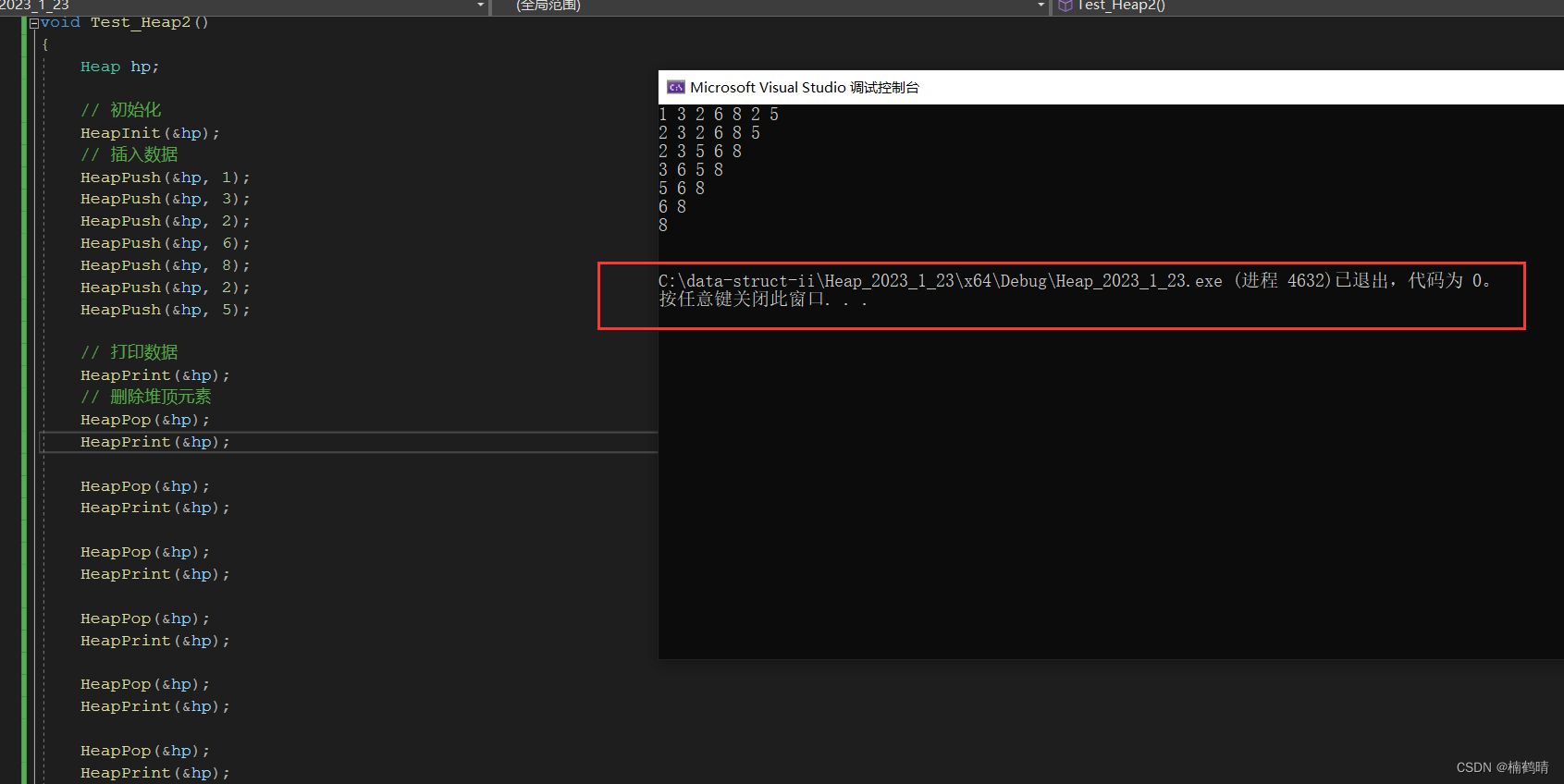
3.测试堆排序
- 测试代码
void Test_HeapSort()
{
int a[] = { 3,6,2,7,9,1,6 };
size_t size = sizeof(a) / sizeof(int);
HeapSort(a, size);
for (int i = 0; i < size; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
- 测试结果

通过我们实现的堆排序,数据确实可以被排成升序。









![[QMT]08-从本地行情数据解析历史K线信息](https://img-blog.csdnimg.cn/img_convert/d0b88aeecb825ce13e0c96487e05008b.png)