获取本实验的项目代码和实验报告,请>=点击此处=<
[0] 摘要
近年来,随着python的迅速崛起,人工智能、图像识别、计算机视觉等新兴学科变得火热起来。Python的发展也伴随着它的各种衍生库、衍生编辑器的发展,其中OpenCV是比较经典的一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
本次大作业采用Pycharm编辑器和OpenCV类库,基于卷积神经网络对手写体的英文字母进行目标检测与识别。其中涉及的技术有:图片切片、目标检测、图片识别、图片定位、识别出来的字母重新写入到图片中。
关键字: 图像切割;手写体识别;字母识别;OpenCV
[1] 第1章 目标检测研究现状
[1.1] 目标检测简介
目标检测是将图像或者视频中的目标与其他不感兴趣区域进行区分,判断是否存在目标,确定目标位置,识别目标种类的计算机视觉任务,是机器视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是机器视觉领域最具有挑战性的问题。所以,目标检测是计算机视觉中的一个方向。
除了图像分类之外,目标检测要解决的核心问题是:①目标可能出现在图像的任何位置。②目标有各种不同的大小。③目标可能有各种不同的形状。
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于机器人导航、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。由于深度学习的广泛运用,目标检测算法得到了较为快速的发展。
[1.2] 目标检测的发展
[1.2.1] 2001年
2001年Paul Viola和MichaelJones在CVPR上发表了一篇跨时代意义的文章,后人将文章中的人脸检测算法称之为Viola-Jones(VJ)检测器。VJ检测器在17年前极为有限的计算资源下第一次实现了人脸的实时检测,速度是同期检测算法的几十甚至上百倍,极大程度地推动了人脸检测应用商业化的进程。VJ检测器的思想深刻地影响了目标检测领域至少10年的发展。
VJ检测器采用了最传统也是最保守的目标检测手段——滑动窗口检测,即在图像中的每一个尺度和每一个像素位置进行遍历,逐一判断当前窗口是否为人脸目标。这种思路看似简单,实则计算开销巨大。VJ人脸检测之所以器能够在有限的计算资源下实现实时检测,其中有三个关键要素:多尺度Haar特征的快速计算,有效的特征选择算法以及高效的多阶段处理策略。
[1.2.2] 2007年
可变形部件模型(Deformable Part based Model,DPM)是基于经典手工特征的检测算法发展的顶峰,连续获得VOC07、08、09三年的检测冠军。DPM最早由芝加哥大学的P. Felzenszwalb等人提出,后由其博士生R.Girshick改进。2010年,P.Felzenszwalb和R. Girshick被VOC授予“终身成就奖”。DPM的主要思想可简单理解为将传统目标检测算法中对目标整体的检测问题拆分并转化为对模型各个部件的检测问题,然后将各个部件的检测结果进行聚合得到最终的检测结果,即“从整体到部分,再从部分到整体”的一个过程。例如,对汽车目标的检测问题可以在DPM的思想下分解为分别对车窗、车轮、车身等部件的检测问题,对行人的检测问题也可以类似地被分解为对人头、四肢、躯干等部件的检测问题。
[1.2.3] 目标检测的发展
从 2006 年以来,在 Hinton、Bengio、Lecun 等人的引领下,大量深度神经网络的论文被发表,尤其是 2012 年,Hinton课题组首次参加 ImageNet图像识别比赛,其通过构建的 CNN 网络AlexNet一举夺得冠军,从此神经网络开始受到广泛的关注。

下图是谷歌学术检索目标检测相关关键字返回的历年文献数量,可见该领域20年来越来越受到学术界的关注。2018年有将近1200篇相关文献发表。

自从2012年之后,CNN受到广泛关注。而目标检测的算法大致分为2012年之前的传统检测方法与2012年之后出现的基于深度学习的检测方法。
传统方法比如V-J检测、HOG检测、DPM算法。
深度学习方法截然不同的分为两条技术路径:单阶段检测算法与两阶段检测算法。

在过去的几年中(2011-2013),目标检测算法的发展几乎是停滞的,人们大多在低层特征表达基础上构建复杂的模型以及更加复杂的多模型集成来缓慢地提升检测精度。既然深度卷积网络能够学习到非常鲁棒且具有表达能力的特征表示,那么为何不将其引入目标检测流程中用来提取特征呢?当卷积神经网络在2012年ImageNet分类任务中取得了巨大成功后,
Girshick等人抓住了机会打破僵局,于2014年率先提出了区域卷积网络目标检测框架(Regionswith CNN features,R-CNN)。自此目标检测领域开始以前所未有的速度发展。
随着卷积神经网络层数的不断加深,网络的抽象能力、抗平移能力和抗尺度变化能力越来越强。对于图像分类任务来说这诚然是一件好事,然而对于检测任务来说却带来了另一个问题:目标包围框精准的位置越来越难以获得。由此便出现了一个矛盾:如果想让检测算法获得更强的平移不变性和尺度不变性,那就必须一定程度地牺牲特征在目标包围框位置和尺度变化上的敏感性,即协变性;相反,如果想要获得更精确的目标包围框定位结果,就必须在平移不变性和尺度不变性上做一些妥协。所以,如果想要将卷积网络有效应用于目标检测问题中,关键是如何有效解决深度网络的平移/尺度不变性和目标检测问题中平移/尺度协变性要求的矛盾。这迫使人们不得不放弃基于特征图+滑动窗口这一套检测方案,从而将关注点转向寻找更加定位精准的目标候选框检测(Object Proposal Detection)算法上来。
在过去的几年里,伴随着深度学习目标检测算法的发展,有非常多的Object ProposalDetection算法被提出,例如Selective Search、Edge Boxes、BING等等。需要注意的是,基于Object Proposal并非是深度学习检测算法的专属,早在传统的手工特征时期,Uijlings等人就尝试过使用Selective Search + 词袋(Bag of Words)特征进行目标检测。
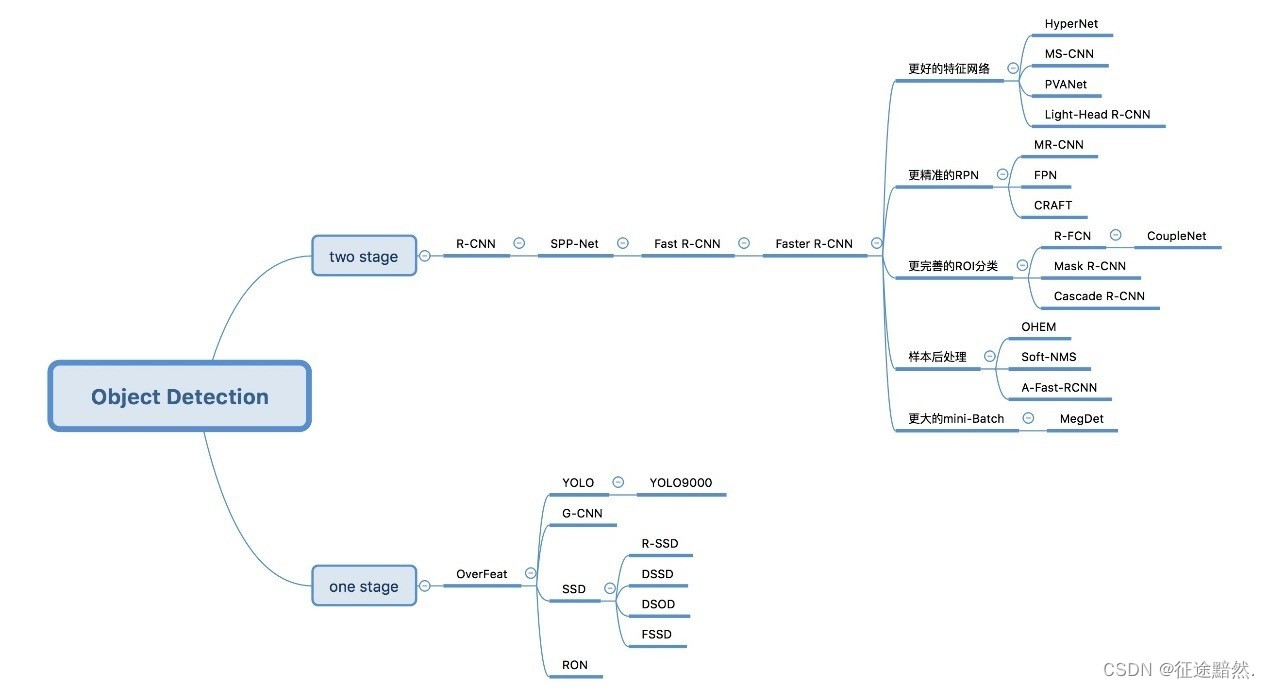
[2] 目标检测方法总结
[2.1] 目标检测算法分类
基于区域建议的算法 如,R-CNN、 Fast R-CNN、Faster R-CNN等。
基于目标回归的检测算法,如YOLO、SSD,retinanet,EfficientDet。
基于搜索的目标检测与识别算法, AttentionNet,强化学习。
基于Anchor-free的算法,如 CornerNet,CenterNet,FCOS 等。
[2.2] R-CNN算法介绍
目标检测有两个主要任务:物体分类和定位。为了完成这两个任务,R-CNN借鉴了滑动窗口思想,采用对区域进行识别的方案,具体是:
输入一张图片,通过指定算法从图片中提取 2000 个类别独立的候选区域(可能目标区域);
对于每个候选区域利用卷积神经网络来获取一个特征向量;
对于每个区域相应的特征向量,利用支持向量机SVM 进行分类,并通过一个bounding box regression调整目标包围框的大小。
[2.2.1] 提取候选区域
R-CNN目标检测首先需要获取2000个目标候选区域,能够生成候选区域的方法很多,比如:
1 objectness
2 selective search
3 category-independen object proposals
4 constrained parametric min-cuts(CPMC)
[2.2.2] 提取特征向量
对于上述获取的候选区域,需进一步使用CNN提取对应的特征向量,使用模型AlexNet (2012)。(需要注意的是 Alexnet 的输入图像大小是 227x227,而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227x227 的尺寸)。
训练过程如下:
①有监督预训练:训练网络参数
样本:ImageNet;这里只训练和分类有关的参数,因为ImageNet数据只有分类,没有位置标注;图片尺寸调整为227x227;最后一层:4097维向量->1000向量的映射。
②特定样本下的微调 :训练网络参数
采用训练好的AlexNet模型进行PASCAL VOC 2007样本集下的微调,学习率=0.001(PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签);mini-batch为32个正样本和96个负样本(由于正样本太少);修改了原来的1000为类别输出,改为21维【20类+背景】输出。
[2.2.3] SVM分类
通过上述卷积神经网络获取候选区域的特征向量,进一步使用SVM进行物体分类,关键如下:
使用了一个SVM进行分类:向SVM输入特征向量,输出类别得分;用于训练多个SVM的数据集是ImageNet数据;将2000×4096维特征(2000个候选框,每个候选框获得4096的特征向量)与20个SVM组成的权值矩阵4096×20相乘(20种分类,SVM是二分类器,每个种类训练一个SVM,则有20个SVM),获得2000×20维矩阵表示每个建议框是某个物体类别的得分;分别对上述2000×20维矩阵中每列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些候选框。
[2.2.4] 边框修正
使用一个回归器进行边框回归:输入为卷积神经网络pool5层的4096维特征向量,输出为x、y方向的缩放和平移,实现边框的修正。在进行测试前仍需回归器进行训练。
在2014年R-CNN横空出世的时候,颠覆了以往的目标检测方案,精度大大提升。对于R-CNN的贡献,可以主要分为如下方面:
使用了卷积神经网络进行特征提取;使用bounding box regression进行目标包围框的修正;
但是,R-CNN仍然有一些问题:
耗时的selective search,对一张图像,需要花费2s;耗时的串行式CNN前向传播,对于每一个候选框,都需经过一个AlexNet提取特征,为所有的候选框提取特征大约花费47s;三个模块(CNN特征提取、SVM分类和边框修正)是分别训练的,并且在训练的时候,对于存储空间的消耗很大。
[2.3] Fast R-CNN算法介绍
面对R-CNN的缺陷,Ross在2015年提出的Fast R-CNN进行了改进,概述Fast R-CNN的解决方案:
首先采用selective search提取2000个候选框RoI;
使用一个卷积神经网络对全图进行特征提取;
使用一个RoI Pooling Layer在全图特征上摘取每一个RoI对应的特征;
分别经过为21和84维的全连接层(并列的,前者是分类输出,后者是回归输出)
Fast R-CNN通过CNN直接获取整张图像的特征图,再使用RoI Pooling Layer在特征图上获取对应每个候选框的特征,避免了R-CNN中的对每个候选框串行进行卷积(耗时较长)。
[2.4] YOLO v1算法介绍
这是继RCNN,fast-RCNN和faster-RCNN之后,rbg(RossGirshick)针对DL目标检测速度问题提出的另外一种框架。YOLO V1其增强版本GPU中能跑45fps,简化版本155fps。
[2.4.1] YOLO的核心思想
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别;
faster RCNN中也直接用整张图作为输入,但是faster-RCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。
[2.4.2] YOLO的实现方法
将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准两重信息,其值是这样计算的:
其中如果有object落在一个grid cell里,第一项取1,否则取0。 第二项是预测的bounding box和实际的groundtruth之间的IoU值。

每个bounding box要预测(x, y, w, h)和confidence共5个值,每个网格还要预测一个类别信息,记为C类。则SxS个网格,每个网格要预测B个bounding box还要预测C个categories。输出就是S x S x (5*B+C)的一个tensor。
[3] 程序实现
[3.1] 程序需求分析
随着计算机视觉方向的发展与各种开源库的涌现,目标检测与图像识别的步骤也越来越规范并且趋于简单化。
本次大作业采用Pycharm编辑器,应用Python的OpenCV图像处理库,基于深度学习的卷积神经网络来识别图像中的手写的大写英文字母。具体功能步骤是:对图像进行切片、目标检测、图像识别、图像定位、识别出来的字母重新写入到图片中。
[3.2] 程序开发技术介绍
[3.2.1] PyCharm编辑器
PyCharm是一种Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如,调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制等等。此外,IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。同时支持Google App Engine,支持IronPython。这些功能在先进代码分析程序的支持下,使PyCharm成为Python专业开发人员和刚起步人员使用的有力工具。
PyCharm的主要功能有:
1、编码协助:其提供了一个带编码补全,代码片段,支持代码折叠和分割窗口的智能、可配置的编辑器,可帮助用户更快更轻松的完成编码工作。
2、项目代码导航:该IDE可帮助用户即时从一个文件导航至另一个,从一个方法至其申明或者用法甚至可以穿过类的层次。若用户学会使用其提供的快捷键的话甚至能更快。
3、代码分析:用户可使用其编码语法,错误高亮,智能检测以及一键式代码快速补全建议,使得编码更优化。
4、Python重构:有了该功能,用户便能在项目范围内轻松进行重命名,提取方法/超类,导入域/变量/常量,移动和前推/后退重构。
5、支持Django:有了它自带的HTML, CSS 和 JavaScript编辑器 ,用户可以更快速的通过Djang框架进行Web开发。此外,其还能支持CoffeeScript, Mako 和 Jinja2。
6、支持Google App引擎:用户可选择使用Python 2.5或者2.7运行环境,为Google APp引擎进行应用程序的开发,并执行例行程序部署工作。
7、集成版本控制登入,录出,视图拆分与合并–所有这些功能都能在其统一的VCS用户界面(可用于Mercurial, Subversion, Git, Perforce 和其他的 SCM)中得到。
8、图形页面调试器用户可以用其自带的功能全面的调试器对Python或者Django应用程序以及测试单元进行调整,该调试器带断点,步进,多画面视图,窗口以及评估表达式。
9、集成的单元测试用户可以在一个文件夹运行一个测试文件,单个测试类,一个方法或者所有测试项目。
[3.2.2] OpenCV图像处理库
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口。该库也有大量的Python、Java and MATLAB/OCTAVE(版本2.5)的接口。这些语言的API接口函数可以通过在线文档获得。如今也提供对于C#、Ch、Ruby,GO的支持。
所有新的开发和算法都是用C++接口。一个使用CUDA的GPU接口也于2010年9月开始实现。
OpenCV于1999年由Intel建立,如今由Willow Garage提供支持。OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows和Mac OS操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。最新版本是3.4,2017年12月23日发布。
OpenCV 拥有包括 500 多个C函数的跨平台的中、高层 API。它不依赖于其它的外部库——尽管也可以使用某些外部库。
OpenCV 为Intel Integrated Performance Primitives(IPP)提供了透明接口。这意味着如果有为特定处理器优化的IPP库,OpenCV将在运行时自动加载这些库。
[3.3] 程序代码实现
[3.3.1] 程序文件介绍

程序的文件目录如图3-3所示。
其中,my_net2文件夹中,存放的是卷积神经网络的权重参数。
Cnn.pyfind_charater.pytotal.pywrite.py分别是编写的4个python文件。
First.jpg是文件进行识别的初始图片,result.jpg是文件识别之后导出的文件。
[3.3.2] 程序算法介绍
①. 首先,在total文件中,导入各个文件。
②. 调用cut()函数。主要是对图像进行处理,灰度处理,高斯滤波虚化,二值化,之后对图片的轮廓进行检测识别,最后对图片进行切片。
在cut函数中,首先调用cv2.imread()读取图片,然后通过cv2.cvtColor()函数来生成灰度图,通过cv2.GaussianBlur()来进行高斯滤波虚化,通过cv2.threshold(gray, 100, 255, 0)对图像进行二值化操作,最后用cv2.findContours()检测字母的轮廓并对图片进行提取切片。
③.调用reshape()函数。对图像数组的格式进行变换,把28*28的二维数组改变成一维。
④.调用cnn()函数。CNN是卷积神经网络,cnn()函数的目的在于,把切片好的一组图片,送进cnn()函数里面进行处理、比对标签,输出数组。
⑤.然后调用write()函数。把上一步cnn()函数导出的pre数组作为输入比对,比对出神经网络识别出的大写字母,最后把对应的大写字母写在原图片上面。
⑥.调用cv2.imwrite(‘result.png’,img)函数。把图片导出,图片名为result.jpg。
⑦.最后,cv2.imshow(‘a’,img)函数,显示导出的图片。
[3.3.3] 程序代码展示
total.py文件:
from find_charater import cut
from cnn import cnn
from writer import writer
import cv2
def main():
path='first.jpg'
num,p,q,img=cut(path)
num=num.reshape(-1,28*28)
pre=cnn(num)
img=writer(pre,p,q,img)
cv2.imwrite('result.png',img)
cv2.imshow('a',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
main()
write.py文件:
import cv2
def writer(num,p,q,img):
list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
for i in range(len(p)):
a=list[num[i]]
img=cv2.putText(img,a,(p[i]-55,q[i]-55),cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
img = cv2.resize(img, (800, 600), interpolation=cv2.INTER_NEAREST)
return img
find_charater.py文件:
import cv2 #opencv库
import matplotlib.pyplot as plt
import numpy as np
def cut(path):
img=cv2.imread(path) #读取
img = cv2.resize(img, (800, 600), interpolation=cv2.INTER_NEAREST)
a,b=img.shape[:2] #长和宽
MAX=a*b #面积
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #灰度图
gray = cv2.GaussianBlur(gray, (5, 5), 0) #高斯滤波虚化
ret, thresh = cv2.threshold(gray, 100, 255, 0) #二值化
image, contours, hierarchy = cv2.findContours(thresh, cv2.RETR_CCOMP, cv2.CHAIN_APPROX_SIMPLE)
num=[]
p=[] #横坐标
q=[] #纵坐标
for i in range(len(contours)):
x, y, w, h = cv2.boundingRect(contours[i])
if cv2.contourArea(contours[i])>(MAX/500) and cv2.contourArea(contours[i])<(MAX/2):
cv2.rectangle(img,(x-25,y-25),(x+w+25,y+h+25),(150,199,199),4)
p.append(x)
q.append(y)
newimg=thresh[y-15:y + h+15,x-15:x + w+15]
newimg = cv2.resize(newimg, (28, 28), interpolation=cv2.INTER_LINEAR)
newimg=[(255-x)*1 for x in newimg]
num.append(newimg)
num=np.array(num)
return num ,p,q,img
cnn.py文件:
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
os.environ['TF_CPP_MIN_LOG_LEVEL'] = "4"
tf.set_random_seed(1)
np.random.seed(1)
LR = 0.001
tf_x = tf.placeholder(tf.float32, [None, 28*28])
image = tf.reshape(tf_x, [-1, 28, 28, 1])
tf_y = tf.placeholder(tf.int32, [None, 8])
def weight_variable(shape): # 初始化权重,初始化为接近0的很小的正值
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape): # 初始化偏置
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W): # 卷积和池化,使用卷积步长为1(stride size),0边距(padding size)池化用简单传统的2x2大小的模板做max pooling
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def cnn(img):
# 第一层 卷积层
W_conv1 = weight_variable([5, 5, 1, 16])
b_conv1 = bias_variable([16])
h_conv1 = tf.nn.relu(conv2d(image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
# 第二层 卷积层
W_conv2 = weight_variable([5, 5, 16, 32])
b_conv2 = bias_variable([32])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
keep_prob = tf.placeholder("float")
h_pool2 = tf.nn.dropout(h_pool2, keep_prob)
flat = tf.reshape(h_pool2, [-1, 7*7*32])
output = tf.layers.dense(flat, 8) # 输出层
loss = tf.compat.v1.losses.softmax_cross_entropy(onehot_labels=tf_y, logits=output) # 计算
train_op = tf.compat.v1.train.AdamOptimizer(LR).minimize(loss)
accuracy = tf.compat.v1.metrics.accuracy(labels=tf.argmax(tf_y, axis=1), predictions=tf.argmax(output, axis=1),)[1]
with tf.Session() as sess:
saver = tf.train.Saver()
init_op = tf.group(tf.compat.v1.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init_op)
saver.restore(sess, 'my_net2/save_net.ckpt')
pre = sess.run(output, {tf_x: img,keep_prob:1})
pre_y=np.argmax(pre,1)
return pre_y
[4] 实验结果
[4.1] 实验结果展示
待识别的图片:

程序导出的图片:

参考文献
[1] 姚敏. 数字图像处理(第2版)[M]. 北京:机械工业出版社,2012.
[2] Bradski[美],Kaehler[美] 著;于仕琪,刘瑞祯 译. 学习OpenCV(中文版)[M]. 北京:清华大学出版社,2009.
[3] 陈胜勇. 基于OpenCV的计算机视觉技术实现[M]. 北京:科学出版社出版,2014.
[4] 周志华. 解析深度学习:卷积神经网络原理与视觉实践[M]. 北京:电子工业出版社,2018.
[5] 毛星云. OpenCV3编程入门[M]. 北京:电子工业出版社,2015.