[Paper Reading] Towards Conversational Recommendation over Multi-Type Dialogs
文章目录
- [Paper Reading] Towards Conversational Recommendation over Multi-Type Dialogs
- 论文简介
- 快速回顾论文(借助scispace)
- 梳理一下文章内容(参考百度NLP公众号找到的解读)
- Abstract
- 动机
- 其他
- 各种积累
- 生词积累
- 术语积累
- 写作套路积累
- 先提及前人工作,然后突出自己做的好😎
- 引出自己的工作、贡献
- 呼应前文
- 关于未来工作
- acknowledgements
- 连接词
- 优美表达(好词好句)积累
- 常识积累
- NLP领域的学术会议
- Annual Meeting of the Association for Computational Linguistics (ACL)
- Conference on Empirical Methods in Natural Language Processing (EMNLP)
- North American Chapter of the Association for Computational Linguistics (NAACL)
- International Conference on Computational Linguistics (COLING)
- Conference on Computational Natural Language Learning (CoNLL)
- International Joint Conference on Natural Language Processing (IJCNLP):
- BibTex
- EndNote
- 参考资料
- 这篇论文是我仔细读了的,但是目前还达不到总结方法的程度,主要还是积累各种术语,以及学习经验贴,代入他人的阅读论文方法来读论文
论文简介
-
这篇文章主要是发表了一个数据集,后来百度又把这个数据集扩充为双语又发了一篇论文,原先的数据集在这篇论文里给出的链接[https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/Research/ACL2020-DuRecDial](https://github.com/PaddlePaddle/models/ tree/develop/PaddleNLP/Research/ACL2020-DuRecDial)里面是找不到的,
数据集目前在第二篇论文
DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation所给出的地址https://github.com/liuzeming01/durecdial -
这篇论文的bibtex
@inproceedings{liu2020towards, title={Towards Conversational Recommendation over Multi-Type Dialogs}, author={Liu, Z and Wang, H and Niu, ZYu and Wu, Hua and Che, W and Liu, T}, booktitle={58th Annual Meeting of the Association-for-Computational-Linguistics (ACL) Conference Location ELECTR NETWORK}, pages={1036--1049}, year={2020}, organization={ASSOC COMPUTATIONAL LINGUISTICS-ACL Location STROUDSBURG} }
快速回顾论文(借助scispace)
-
Describe practical implications(实用价值) of this paper
- The practical implications of this paper are that it provides a new testing platform for the task of conversational recommendation and establishes baseline results for future research.
-
What data is used for experiments?
- The experiments in this paper are conducted on the DuRecDial dataset, which contains 10k dialogs and 156k utterances. This dataset includes multiple sequential dialogs for every pair of a recommendation seeker (user) and a recommender (bot). Each dialogue consists of different types such as question-answering, conversation about entities or topics related to recommendations.
-
What’re the results of this paper?
- The results of this paper show that the DuRecDial dataset is a suitable testbed for conversational recommendation tasks. The baseline models used in the experiments achieved promising performance, demonstrating its potential to be further explored and developed by future studies.
-
Explain abstract in one line
- This paper presents a new task of conversational recommendation over multi-type dialogs, and provides baseline results on the DuRecDial dataset for future studies.
-
What has this paper contributed?
- This paper has contributed to the study of conversational recommendation in multi-type dialogs by creating a dataset called DuRecDial. This dataset contains 10k dialogues and 156k utterances, which allows us to systematically investigate different parts of the overall problem such as how to naturally lead a conversation towards recommendations, or how bots can interact with users for making effective recommendations. Additionally, this paper also provides baseline results on DuRecDial that will be useful for future studies.
-
What does this paper conclude?
- This paper concludes that we propose a task of conversational recommendation over multi-type dialogs, and create the DuRecDial dataset for testing. We also provide baseline results on this dataset to serve as foundation for future related work.
-
Explain the abstract in simple terms
- This paper focuses on the study of conversational recommendation in multi-type dialogs, where a bot can proactively and naturally lead conversations from nonrecommendation topics (e.g., QA) to recommendations based on user interests and feedback. To facilitate this research task, we created DuRecDial dataset which contains 10k dialogues with 156k utterances between users seeking for recommendations and bots providing them. This dataset allows us to investigate different aspects of the problem such as how to interactively engage users during conversation or how natural language processing models could be used for leading conversations towards making successful recommendations. Finally, baseline results are established using this data set that will help future studies in related areas.
-
What’s unique about this paper?
- This paper is unique in that it focuses on the study of conversational recommendation over multi-type dialogs, and creates a dataset DuRecDial with multiple dialog types and multidomain use cases. This complexity makes this data set an ideal testbed for tasks such as knowledge grounded conversation, domain transfer for dialogue modeling, target-guided conversations and multi-type dialogue modelling. Additionally, we also provide baseline results on DuRecDial which can be used to compare future studies against.
-
Describe the main approaches discussed?
- The main approaches discussed in this paper are related to the task of conversational recommendation over multi-type dialogs. This includes creating a dataset (DuRecDial) with multiple dialog types and multidomain use cases, demonstrating usability of this dataset, providing results from state-of-the art models for future studies as well as exploring tasks such as knowledge grounded conversation, domain transfer for dialogue modeling, target guided conversations and multi type dialogue modelling which will be left open for further research.
-
What are the key takeaways?
takeaway 从…中了解到的主要信息
- The key takeaways from this paper are that it proposes a task of conversational recommendation over multi-type dialogs, and creates the DuRecDial dataset for testing. It also provides baseline results on this dataset to serve as foundation for future related work. Additionally, by using this data set we can investigate different aspects of the problem such as how natural language processing models could be used for leading conversations towards making successful recommendations or how bots can interact with users during conversation in order to make effective recommendations.
-
What are the main challenges in conversational recommendation tasks?
- The main challenges in conversational recommendation tasks include understanding user intent, accurately predicting the next action of a conversation and providing relevant recommendations based on that. Additionally, it is also challenging to create natural conversations with users while leading them towards making successful recommendations.
-
How does the DuRecDial dataset facilitate research on this task?
- The DuRecDial dataset facilitates research on this task by providing a comprehensive set of data that covers multiple dialog types and domains. It also contains rich interaction variability for recommendation, which allows researchers to investigate different aspects of the problem such as how natural language processing models can be used to lead conversations towards making successful recommendations or how bots should interact with users in order to make effective recommendations.
-
What is OpenNMT and how does it help with S2S models?
- OpenNMT is an open source deep learning platform that provides tools for building neural machine translation systems. It helps with S2S models by providing the same parameters as OpenNMT, which can be used to train and optimize a model’s performance on tasks such as conversation generation or dialogue modelling. Additionally, it also allows researchers to easily compare different approaches in order to find the best solution for their problem.
-
How did you evaluate data quality for DuRecDial dataset?
- To evaluate the data quality for DuRecDial dataset, we conducted a series of experiments to measure its performance on various tasks. We used metrics such as accuracy and F1 score to assess how well our models were able to generate natural conversations with users while leading them towards making successful recommendations. Additionally, we also evaluated the knowledge usage in dialogs by conducting an ablation study where input goals or knowledge was replaced with “UNK”. This allowed us to compare different approaches and determine which one performed better when it came down recommending products or services based on user’s interests.
-
Could you explain what is meant by a goal sequence G in Problem Definition section of your paper ?
- A goal sequence G is a set of goals that the recommender needs to achieve in order for successful recommendation. It consists of tasks such as understanding user intent, accurately predicting the next action and providing relevant recommendations based on that. The goal sequence helps guide conversations towards making successful recommendations by helping both parties understand what they need to do or say during each step of conversation.
梳理一下文章内容(参考百度NLP公众号找到的解读)
参考:ACL 2020论文分享 | 新任务:融合多个对话类型的对话式推荐
Abstract
We propose a new task of conversational recommendation over multi-type dialogs, where the bots can proactively and naturally lead a conversation from a non-recommendation dialog (e.g., QA) to a recommendation dialog, taking into account user’s interests and feedback. To facilitate the study of this task, we create a human-to-human Chinese dialog dataset DuRecDial (about 10k dialogs, 156k utterances), which contains multiple sequential dialogs for every pair of a recommendation seeker (user) and a recommender (bot). In each dialog, the recommender proactively leads a multi-type dialog to approach recommendation targets and then makes multiple recommendations with rich interaction behavior. This dataset allows us to systematically investigate different parts of the overall problem, e.g., how to naturally lead a dialog, how to interact with users for recommendation. Finally we establish baseline results on DuRecDial for future studies.
动机
-
随着voice-based bots(智能音箱、语音助手那些)的普及,对话式推荐变得原来越重要,对话式推荐指通过基于对话的人机交互形式实现高质量的自动推荐
-
前人的工作主要可以 fall into two categories
- 基于任务类对话的建模方式 (task-oriented dialog-modeling approaches)
- 基于更自由的开放域对话的建模方式。(non-task dialog-modeling approaches with more freeform interactions)
-
前人工作集中于单一类型的对话
- Almost all these work focus on a single type of dialogs, either task oriented dialogs for recommendation, or recommendation oriented open-domain conversation.
-
但是实际应用中,人机对话(human-bot conversations) 通常包含多个对话类型(multi-type dialogs)
- such as chit-chat, task oriented dialogs, recommendation dialogs, and even question answering
-
基于以上考虑,研究人员提出一个新对话任务:融合多个对话类型的对话式推荐。研究人员期望系统主动且自然地从任意类型对话(闲聊/问答等)引导到推荐目标上。
- To address this challenge, we present a novel task, conversational recommendation over multitype dialogs, where we want the bot to proactively and naturally lead a conversation from a non-recommendation dialog to a recommendation dialog.

- 如图所示,给定一个起始对话(例如问答),系统可为推荐规划一个对话目标序列,然后基于该目标序列驱动自然的对话,最后完成目标实体的推荐。
- the bot can take into account user’s interests to determine a recommendation target
(the movie <The message>)as a long-term goal, and then drives the conversation in a natural way by following short-term goals, and completes each goal in the end.
-
本论文中的任务设定与前人工作的区别在于:
- 论文中的对话包含多个对话类型;
- 论文强调系统的主动对话能力(emphasize the initiative of the recommender),例如系统可主动规划一个对话目标序列(the bot proactively plans a goal sequence to lead the dialog, and the goals are unknown to the users),而该序列通常对用户是不可见的。
-
为辅助该任务的研究,研究人员构建了一个支持多对话类型的人-人对话推荐数据集(DuRecDial)。
-
该数据集的特点包括: 每个对话session包含多个对话类型;
-
包括丰富的交互逻辑;
-
对话领域的多样性;
-
为每个用户建立个性化的profile,支持个性化的推荐。
-
-
在这个任务和数据集,研究人员尝试解决目前人机对话存在的一些问题:
- 自然的融合多种类型对话; 机器根据用户长期偏好规划对话目标序列,并主动引领对话;
- 包含丰富的对话逻辑,如用户转移话题,也可产生合理回复;
- 充分利用之前对话,对话结束会根据用户反馈,实时更新用户Profile,更新的Profile会影响后续对话。
其他
任务设置、数据集建设、基线模型建设、实验及结果,我主要挑我的关注点来整理了.
-
论文中严格的数据质量控制流程

-
由于对话的开放性,对话的自动评估存在很多不足,因此在自动评估基础上进一步使用人工评估的来评估对话效果。实验设计如下所示:

-
其中人工评估:
研究人员进一步对自动评估中效果最好的三个+gl.+kg.模型进行单轮和多轮人工评估。多轮评估时使用类似于数据标注的方法先生成多轮评估数据,不同的是将数据标注时扮演机器角色的标注专员替换成候选模型。每个模型生成100组评估数据,然后3个评估专员共同评估。
-
单轮评估包括:流畅性、合理度、信息多样性、主动性等4个指标。
-
多轮评估指标有Goal完成度和多轮一致性coherence等2个指标**。**评估结果如下所示

-
-
各种积累
生词积累
-
proactive 主动的
-
chitchat 闲聊
-
mimic 模仿
-
synthetic 人造的,合成的
-
take the initiative 采取主动
-
enumerate 枚举
-
pair up 配对
-
denote 表示,象征
-
retrieval 取回;索回;数据检索
-
segment 段
-
leverage
- n. 杠杆,杠杆作用,影响力
- v.发挥杠杆作用,施加影响; 利用
-
ablation (冰川、冰山)消融;(岩石等物质)融蚀、水蚀
-
auxiliary
- n. 助动词;辅助工;辅助人员
- adj.辅助的
-
latent
- 潜在的
-
concatenate
- adj.连锁状的
- v.使(成串地)连结[衔接]起来
-
coherence 连贯性
术语积累
-
SOTA
- SOTA stands for “state-of-the-art.” It refers to the current best performance or most advanced technology in a particular field or area of research. In machine learning, SOTA models are often benchmarked against large datasets and evaluated based on their accuracy, precision, recall, and other metrics. SOTA models are frequently updated as new research and advancements are made in the field.
-
multi-type dialog modeling
-
conversational recommendation 会话式推荐
- A sample of conversational recommendation over multi-type dialogs
-
task-oriented dialog modeling approaches
-
target-guided conversation
-
non-task dialog-modeling approaches with more free form interactions
-
grounded on knowledge graph and a goal sequence
-
user’s interests and topic transition naturalness
-
real-world application scenarios
-
a human-to-human multi-turn recommendation dialog dataset
-
a multi-domain multi-turn conversations grounded on Wikipedia articles
-
in-depth discussions
-
a retrieval model 检索模型
-
Convolutional neural network (CNN) 卷积神经网络
-
Retrieval-based Response Model 基于检索的响应模型
-
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种
-
ablation study 消融实验
-
其实就是控制变量法
名词解释 | 论文中的Ablation study - CV技术指南的文章 - 知乎 https://zhuanlan.zhihu.com/p/389091953
-
https://www.cnblogs.com/sakuraie/p/13341451.html
-
-
open-domain conversation generation 开放域对话生成
-
metrics 指标
-
outperform 表现优于
-
knowledge grounded conversation
-
testbed
- The complexity in DuRecDial makes it a great testbed for more tasks such as knowledge grounded conversation (Ghazvininejad et al., 2018), domain transfer for dialog modeling, target-guided conversation (Tang et al., 2019a) and multi-type dialog modeling (Yu et al., 2017). The study of these tasks will be left as the future work.
-
fine-grained 细粒度的
写作套路积累
会议论文几乎没读过几个,但就感到非常八股,有很多套路可循😂
先提及前人工作,然后突出自己做的好😎
哈哈哈太套路了
-
However, to our knowledge, there is less previous work on this problem.
-
instead of a single dialogue type as done in previous work
-
inspired by the work of (前人xxx) , we present a multi-goal driven conversation generation framework(MGCG)
-
To our knowledge, this goal-driven dialog policy mechanism for multi-type dialog modeling is not studied in previous work.
-
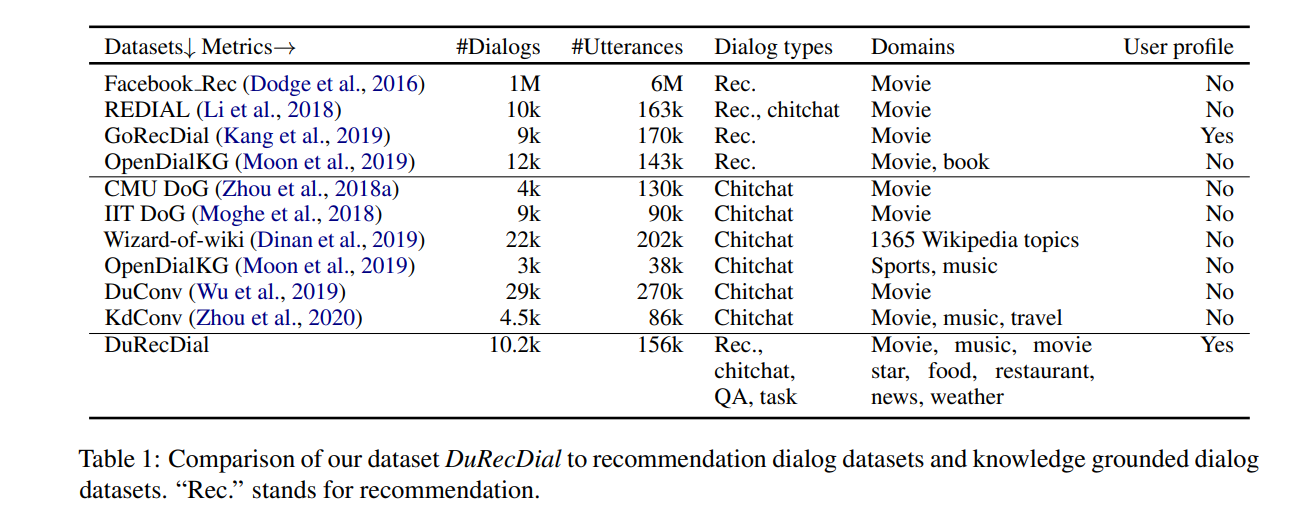
To facilitate the study of conversational recommendation, multiple datasets have been created in previous work, as shown in Table 1.
-
Compared with them, our dataset contains multiple dialogue types, multi-domain use cases, and rich interaction variability.
-
Recently, imposing goals on open-domain conversation generation models having attracted lots of research interests (Moon et al., 2019; Li et al., 2018; Tang et al., 2019b; Wu et al., 2019) since it provides more controllability to conversation generation, and enables many practical applications, e.g., recommendation of engaging entities. However, these models can just produce a dialog towards a single goal, instead of a goal sequence as done in this work. We notice that the model by Xu et al. (2020) can conduct multi-goal planning for conversation generation. But their goals are limited to in-depth chitchat about related topics, while our goals are not limited to in-depth chitchat.
-
Our work is more close to the second category(这是前文提及的前人的), and differs from them in that we conduct multi-goal planning to make proactive conversational recommendation over multi-type dialogs.
引出自己的工作、贡献
-
To address the task
-
To address the problem
-
To address this problem
-
To facilitate the study of this task
-
This work makes the following contributions
呼应前文
- which corresponds to the first difficulty
- corresponding to the second difficulty
上面这俩,一个定从,一个非谓语结构,一个意思,hhh
关于未来工作
- … , which will be left as the future work.
- there is still much room for performance improvement in terms of appropriateness and goal success rate, which will be left as the future work.
acknowledgements
- We would like to thank Ying Chen for dataset annotation and thank Yuqing Guo and the reviewers for their insightful comments. This work was supported by the National Key Research and Development Project of China (No. 2018AAA0101900) and the Natural Science Foundation of China (No. 61976072).
连接词
- Moreover
- In addition
- Therefore
优美表达(好词好句)积累
-
by a large margin
- As shown in Table 5, our two systems outperform S2S by a large margin, especially in terms of appropriateness, informativeness, goal success rate and coherence(连贯性,一致性).
-
be equipped with
- Each seeker is equipped with an explicit unique profile (a groundtruth profile), which contains the information of name, gender, age, residence city, occupation, and his/her preference on domains and entities.
-
fall into two categories
- Previous work on conversational recommender systems fall into two categories:…
-
is proportional to 与…成正比
常识积累
NLP领域的学术会议
Annual Meeting of the Association for Computational Linguistics (ACL)
Association for Computational Linguistics 计算语言学协会
Annual Meeting of the Association for Computational Linguistics 国际计算语言学学会年会
- ACL stands for Association for Computational Linguistics. It is a professional organization for researchers and practitioners in the field of computational linguistics, which is an interdisciplinary(跨学科的) field that combines knowledge and techniques from computer science and linguistics to develop computational models of natural language processing (NLP).
- The organization hosts a number of conferences and workshops, including the Annual Meeting of the Association for Computational Linguistics (ACL), which is the premier conference in the field of NLP. The conference is a forum(论坛) for researchers to present and discuss new ideas, innovations, and research results in the field of computational linguistics and NLP.
Conference on Empirical Methods in Natural Language Processing (EMNLP)
- The Conference on Empirical Methods in Natural Language Processing (EMNLP) is one of the leading conferences in the field of natural language processing (NLP). It is a bi-annual(一年两次) event that covers a wide range of topics in NLP, including machine learning, syntax, semantics, and speech recognition.
- The conference is known for its focus on empirical(经验主义的)research, which involves the use of data and experiments to test hypotheses and evaluate models. The conference typically includes a mix of paper presentations, tutorials, and workshops, and it attracts a diverse group of researchers from academia and industry.
North American Chapter of the Association for Computational Linguistics (NAACL)
- The North American Chapter of the Association for Computational Linguistics (NAACL) is also a leading conference in the field of NLP. Like EMNLP, it covers a wide range of topics in NLP, including machine learning, syntax, semantics, and speech recognition.
- The conference is organized by the Association for Computational Linguistics (ACL) and is typically held once a year in North America. The conference features keynote speeches, oral presentations, poster sessions, and tutorials, and it attracts a diverse group of researchers from academia and industry.
International Conference on Computational Linguistics (COLING)
-
The International Conference on Computational Linguistics (COLING) is a conference organized by the International Committee on Computational Linguistics (ICCL) that focuses on computational linguistics and natural language processing (NLP). The conference is held every two years and it covers a wide range of topics in NLP, including machine learning, syntax, semantics, and speech recognition.
COLING is considered one of the top venues for presenting and discussing new research in the field of NLP. The conference features keynote speeches, oral presentations, poster sessions, and tutorials, and it attracts a diverse group of researchers from academia and industry. The conference is known for its high-quality research, strong program committees, and competitive paper selection processes, which guarantees that the conference’s program reflects the current state-of-the-art in NLP research.
COLING brings together researchers from various countries and cultures, which makes it a unique forum for the exchange of ideas and for the discussion of the latest developments in the field of computational linguistics. The conference also features pre- and post-conference workshops(研讨会), tutorials, and shared tasks, which allows attendees to gain a deeper understanding of specific topics and techniques.
Conference on Computational Natural Language Learning (CoNLL)
-
CoNLL (Conference on Computational Natural Language Learning) is a conference that focuses on natural language processing and machine learning, with a particular emphasis on computational models of linguistic structure and meaning. It is held annually and it covers a wide range of topics in natural language processing, including syntactic parsing, semantic role labeling, and machine translation.
The conference features keynote speeches, oral presentations, poster sessions, and tutorials and it attracts a diverse group of researchers from academia and industry. It is known for its high-quality research and its competitive paper selection process, which guarantees that the conference’s program reflects the current state-of-the-art in natural language processing research.
CoNLL is considered one of the most important conferences in the field of natural language processing, particularly for its focus on computational models of linguistic structure and meaning. It is a premier platform for researchers to present their latest findings and developments in the field, and to discuss the challenges and opportunities in this rapidly evolving field. It also provides opportunities for researchers to establish collaborations, share resources and knowledge, and learn about the latest trends and innovations in the field.
International Joint Conference on Natural Language Processing (IJCNLP):
-
The International Joint Conference on Natural Language Processing (IJCNLP) is a joint(联合) event of several international organizations that focuses on natural language processing (NLP). The conference covers a wide range of topics in NLP, including machine learning, syntax, semantics, and speech recognition. The conference is held biennially and it aims to bring together researchers from different countries and regions to share their latest findings and developments in NLP.
IJCNLP is a collaboration of three main organizations in NLP: the Association for Computational Linguistics (ACL), the Asian Federation of Natural Language Processing (AFNLP), and the Pacific Association for Computational Linguistics (PACLING). The conference is considered one of the top venues for presenting and discussing new research in the field of NLP. The conference features keynote speeches, oral presentations, poster sessions, and tutorials, and it attracts a diverse group of researchers from academia and industry.
IJCNLP is known for its high-quality research, strong program committees, and competitive paper selection processes, which guarantees that the conference’s program reflects the current state-of-the-art in NLP research. It is also known for its diversity and inclusivity, and for its efforts to bring together researchers from different countries, cultures and backgrounds.
- 参考
- 「自然语言处理(NLP)」你必须要知道的八个国际会议! - NLP自然语言处理的文章 - 知乎 https://zhuanlan.zhihu.com/p/99619745
- NLP领域有哪些国际顶级会议? - AIPM事务所的文章 - 知乎 https://zhuanlan.zhihu.com/p/140491821
- https://www.junglelightspeed.com/the-top-10-nlp-conferences/
- IJCNLP在nlp领域是怎样的存在?国际认可度如何? - Fei Cheng的回答 - 知乎 https://www.zhihu.com/question/57439092/answer/335186972
- What are some of the top conferences in Natural Language Processing for a potential researcher?
BibTex
- 这个在谷歌学术点击一篇论文的时候可以看到,然后写论文要用引用的时候也需要用到
- 那么Bibtex到底是啥呢
- BibTeX is a tool for managing bibliographic(书目的) references in LaTeX documents. It uses a simple file format to store references, which can then be inserted into a LaTeX document using commands such as
\cite{}. This allows for consistent formatting of references and makes it easy to update or manage a large number of references in a document. BibTeX is widely used in the academic community for formatting bibliographies and citations in papers and research documents.
- BibTeX is a tool for managing bibliographic(书目的) references in LaTeX documents. It uses a simple file format to store references, which can then be inserted into a LaTeX document using commands such as
EndNote

-
Endnote is a style of referencing used in academic writing, where citations and additional information are included at the end of a document, rather than within the text itself. These notes are indicated in the text with numbers or other symbols and are referred to as endnotes.
Endnotes are used for a variety of purposes, such as providing citations for sources used in the document, including additional information or explanations that don’t fit smoothly into the main text, or providing a list of references for further reading. They are often used in the humanities and social sciences, where footnotes are more common in the natural sciences and engineering.
Endnotes are typically numbered consecutively throughout the document, and the corresponding number is placed in superscript in the text where the reference occurs. The endnotes themselves are usually placed at the end of the document, before the bibliography or works cited page.
-
详细的还可以看看这篇文章:What Are Endnotes? | Guide with Examples
-
谷歌学术与zotero的配合使用
-
浏览器中有个
Zotero Connector插件在谷歌学术中点击endNote的时候就会跳出这个界面

-
- 此外,有个很有名的文献管理工具也叫EndNote
- A reference manager software, which helps users save time formatting citations and stay organized, collaborate with colleagues and get published. It can be used to create bibliographies in various citation styles and it will also help you to organize your research and keep track of your references.
参考资料
-
ACL 2020论文分享 | 新任务:融合多个对话类型的对话式推荐
-
怎样阅读论文(台湾彭明辉)https://www.zhihu.com/question/20169638/answer/18205965
-
硕士论文你有哪些经验与收获? - 珵cici的回答 - 知乎 https://www.zhihu.com/question/20141321/answer/14112630
-
如何读一篇优秀的计算机论文? - 珵cici的回答 - 知乎 https://www.zhihu.com/question/20169638/answer/14204360