深度学习:DenseNet思想总结
- 前言
- DenseNet
- ResNet
- Dense connection
- Composite function
- Pooling layers
- Growth rate
- Bottleneck layers
- Compression
- Implementation Details
- 总结
前言
论文中提出的架构为了确保网络层之间的最大信息流,将所有层直接彼此连接。为了保持前馈特性,每个层从前面的所有层获得额外的输入,并将自己的特征映射传递到后面的所有层。该论文基于这个观察提出了以前馈的方式将每个层与其他层连接的密集卷积网络(DenseNet)。
DenseNet
ResNet
在原始的神经网络中,假设第l层的function 为
H
l
H_l
Hl,那么第l层的output
x
l
=
H
l
(
x
l
−
1
)
x_l=H_l(x_{l-1})
xl=Hl(xl−1),ResNet在网络中加入了identity mapping的机制,于是
x
l
=
H
(
x
l
−
1
)
+
x
l
−
1
x_l = H(x_{l-1})+x_{l-1}
xl=H(xl−1)+xl−1。
ResNet的优势是缓解了梯度消失,让训练更稳定,但是 identity mapping 采用了add 融合的机制,可能会阻碍信息流动。
Dense connection
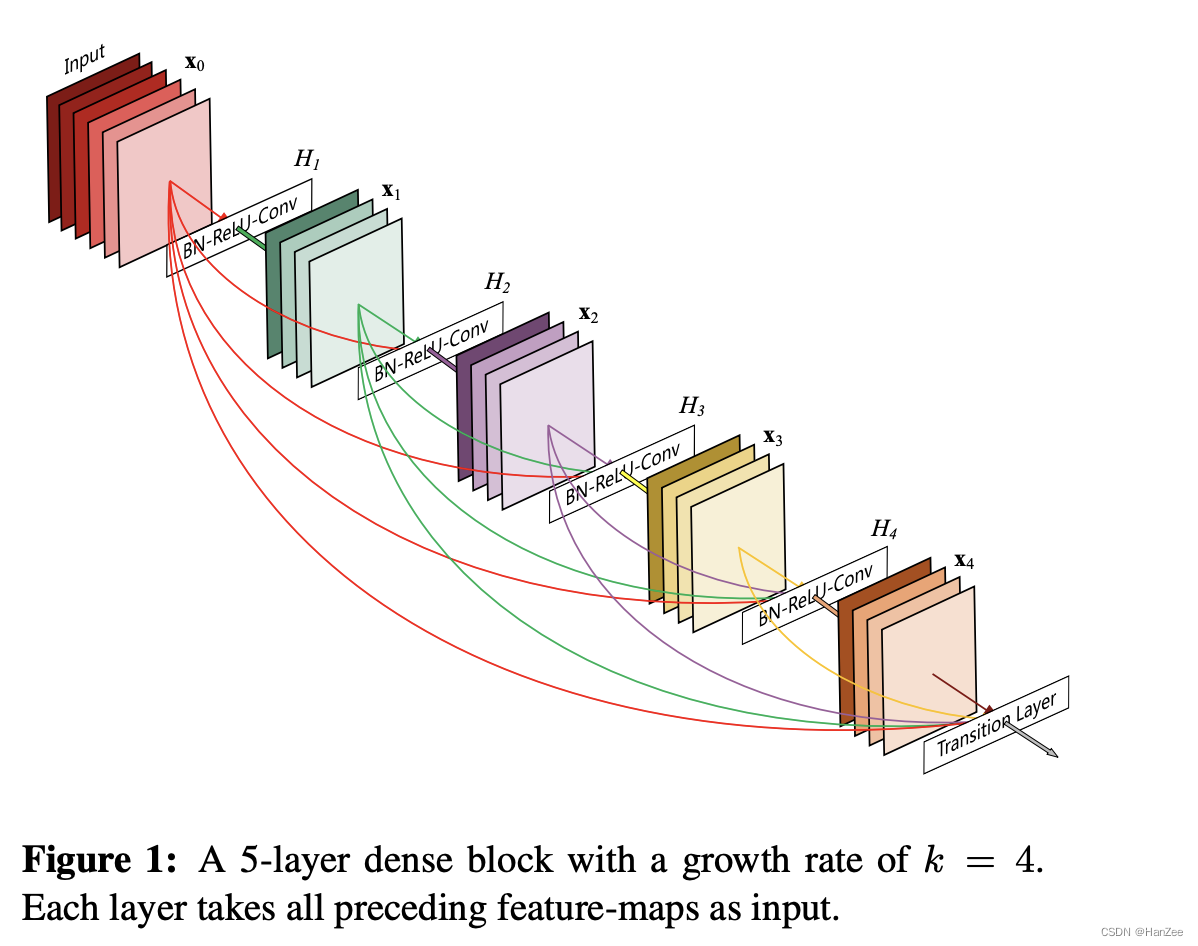
为了进一步的优化信息流动,作者提出了不同的连接形式如上图,每一层的输出都会直接传递到的后面所有网络,每一层的输入汇聚了前层所有的输出,这也是densenet的dense的由来,公式如下:
x
l
=
H
l
(
[
x
0
,
x
1
.
.
.
.
.
.
x
l
−
1
]
)
x_l= H_l([x_0,x_1......x_{l-1}])
xl=Hl([x0,x1......xl−1])
其中跨层连接不在像ResNet采用add融合而是Concat融合,feature map
Composite function
这里作者对H()做了一个解释:这个函数分为三个操作,包括BN层,ReLU激活函数,3 * 3 Conv。
Pooling layers

由于跨层连接要求feature map的宽高一致,但是down- sampling在网络中也是必不可少的,所以引入了pooling layer(也叫做 transition layer)来对feature map下采样,这个网络层由 BN层 +1 * 1Conv +2 * 2 的average pooling layers。
Growth rate
这里我们定义了一个超参数k,他表示dense block中每层的channels数(也是卷积核的数量),假设dense block中input channels 为 k0,那么这个block第 l层的channels为k0+k(l-1)。k越大,代表每一层可以获得多少新的信息,block最后output的channels也就越大,于是我们把 k也叫做 growth rate。
Bottleneck layers
bottleneck 与resent的基本一致,没3 * 3 的Conv前面引入了 1 * 1的 Conv,那么我们定一个新的结构:
BN+ReLU+ 1 * 1Conv + BN +ReLU +Conv3 * 3叫做DenseNet-B。
Compression
没了进一步压缩模型,我们可以减少feature map的数量在 transition层,如果densenet block的output为 m 个feature map,那么通过transition后,channels变为theta * m,其中 theta为0到1之间的数。作者在实验中theta设置为0.5,把bottleneck+transition 叫做 DenseNet -BC。
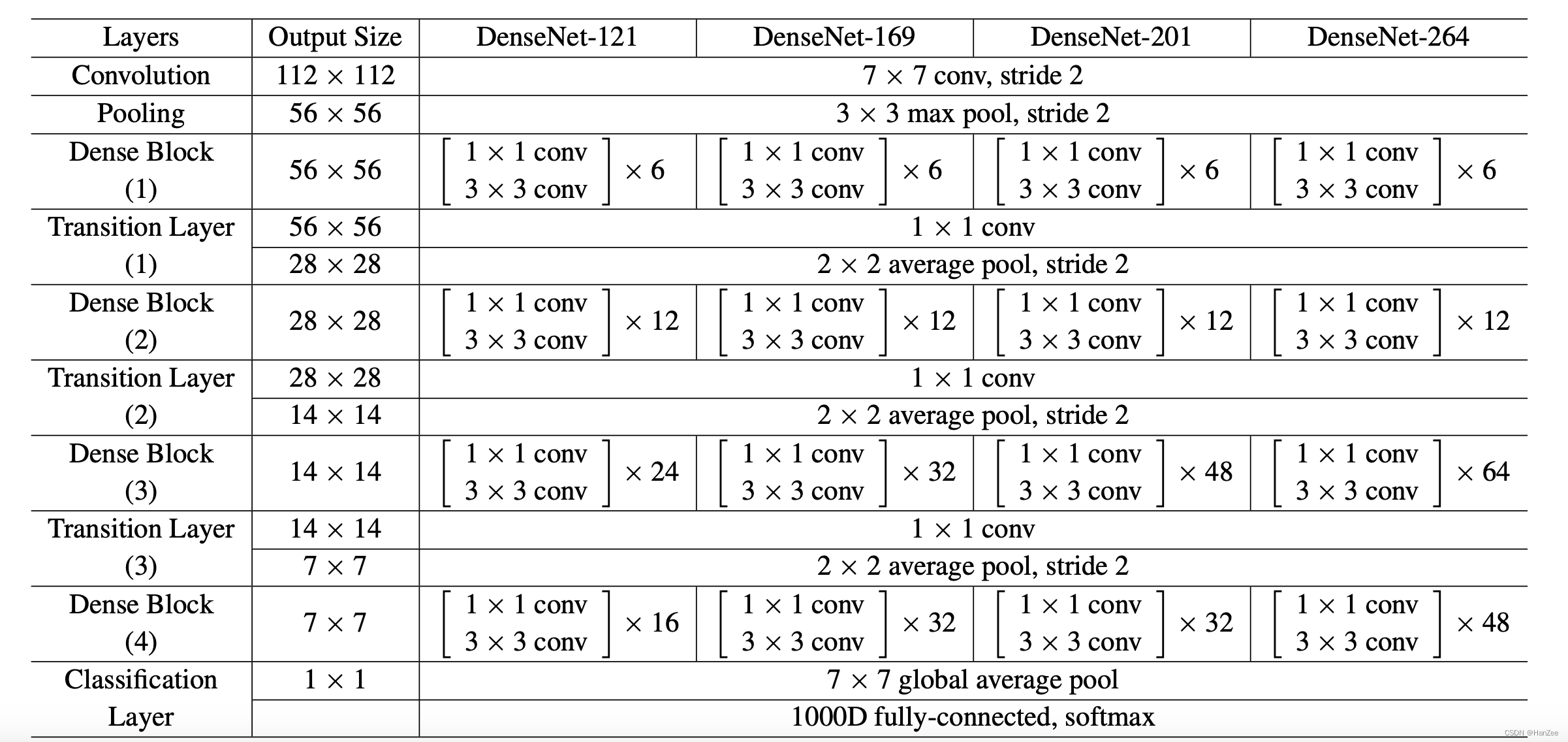
Implementation Details
总结
- DenseNet的跨层连接为concat,ResNet为add。
- DenseNet提升了梯度的利用率,loss可以获得前面每一层的梯度,网络的层数更多了。
- DenseNet致力于特征reuse,提高网络性能。
- DenseNet的dense connection有正则化的作用。