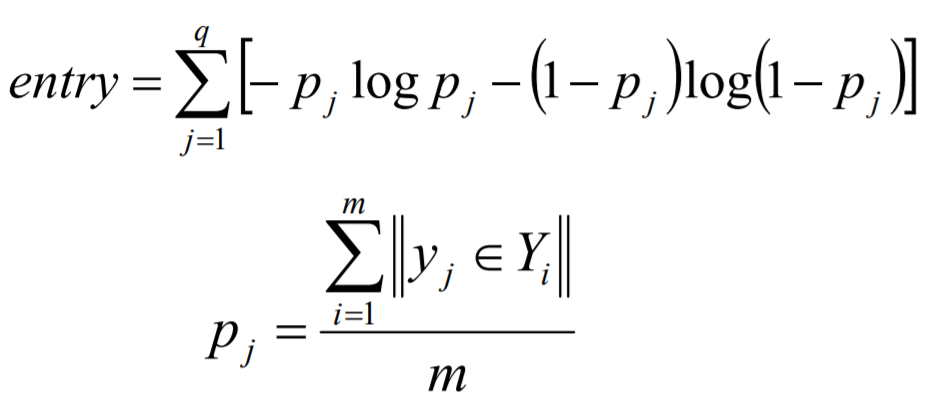赛题概要
请本赛题排行榜前10位的队伍,通过作品说明提交源代码,模型以及说明文档,若文件过大,可发送至官网邮箱AICompetition@iflytek.com, 若截止时间内为提交,官方会通过电话联系相关选手,若未接到通知或接通后5日内未提交,则视为弃权,具体提交规范,请点击下载: 科大讯飞代码审核规范.
赛题背景
问答系统中包括三个主要部分: 问题理解、信息检索和答案抽取。而问题理解是问答系统中第一部分也是非常关键的部分,问题理解有非常广泛的应用,如重复评论识别、相似度问题识别等。
重复问题检测是一个常见的问题文本挖掘任务,在很多实际问答社区都有相应的应用,重复问题检测可以方便的进行问题答案聚合。以及问题答案推荐以及QA等。由于中文词语的多样性和灵活性等,本赛题需要选手构建一个重复问题识别算法。
赛题任务
本赛题希望参赛选手对两个问题完成相似度打分。
- 训练集: 约5千条问题对和标签,若两个问题为相同的问题,标签为1,否则为0.
- 测试集: 约5千条问题时,需要选手预测标签。
三评审规则
数据说明
训练集给定问题对和标签,使用\t进行分隔**,测试集给定问题对**,使用\t进行分隔。
eg: 世界上什么东西最恐怖的,世界上最恐怖的东西是什么?
解析: “世界上什么东西最恐怖”与”世界上最恐怖的东西是什么“问题相同,故是重复问题,标签为1。
评估指标
本次竞赛的评价标准采用准确率指标,最高分为1,计算方法参考:

评测及排行
1、赛事提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2、每枝团队每天最多提交3次,
3、排行按照得分从高到底的排序,排行榜将选择团队历史最优成绩进行排名。
作品提交要求。
- 文件格式: 预测结果文件按照csv格式提交。
- 文件大小:无要求。
- 提交次数限制: 每枝队伍最多3次。
- 预测结果文件详细说明:
-
以csv格式提交,编码为UTF-8,第一行为表头。
-
提交前请确保预测结果的格式与sample_submit.csv中的格式一致。具体格式如下:

经验
验证该比赛,进行打比赛,会将各种比赛全部都将其搞定。会自己修改以及建立 b a s e l i n e s baselines baselines,会将各种的代码结构全部都将其搞定。都行啦的样子与打算。
- 会自己在各种模型架构行修改,以及调节参数,使用各种模型进行修改以及改进都行啦的回事与打算。
项目一常用库说明
distance
这个包为计算任意序列的相似性提供了帮助,包括:Levenshtein、Hamming、Jaccard和Sorensen distance 以及一些bonuses,所有的距离计算都是用纯python实现的,而且大多数都是用 C C C语言实现的。
编辑距离
- 汉明距离、sorensen相似系数、jaccard系数、ifast_comp
编辑距离
- 用来比较两个字符串的相似度.
Levenshtein
Levenshtein算法: 用来计算两个字符串之间的Levenshtein距离,而Levenshtein距离又称为编辑距离,是指两个字符串之间,由一个转换成另外一个所需要的最少编辑次数,许可的编辑操作包括将一个字符替换成另一个字符****,插入一个字符、删除一个字符。
概述
Levenshtein距离用来描述两个字符串之间的差异,我在一个网络爬虫程序里面使用这个算法来比较两个网页之间的版本,如果**网页的内容有足够多的变动,我便将它更新到我的数据库
**。
lightgbm
是一个实现GBDT算法思想的框架,由微软DMTK团队开源的boosting decision tree工具。
后续将这个算法自己整理一遍,然后再继续将其搞起来都行啦的回事与打算。
seaborn

xgboost
- 是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携
- Extreme Gradient Boosting。其基于梯度提升决策树 gradient boosted tree**(GBDT/GBRT/GBM**)。主要应用于监督学习中,是数据比赛中常用的大杀器。

明天将该算法自己整理以下,后续会自己根据其好好研究一下。
catboost
CatBoost: 是一种能够很好的处理类别形特征的梯度提升算法库。本文中,我们对CatBoost的基本原理及应用实例,做个相似的介绍。后面小猴子还将针对其中几个重要特性做专门介绍,如 CatBoost 对类别型特征处理、特征选择、文本特征处理、超参数调整以及多标签目标处理,敬请期待,看完记得点个赞支持下!
- 类别型特征处理。
- 特征选择
- 文本特征处理
- 超参数调整
- 多标签目标处理。
梯度提升概述
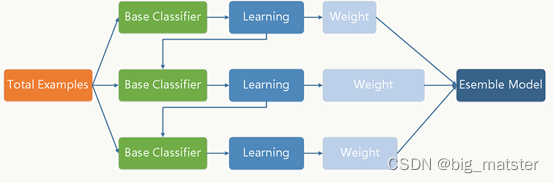
要理解boosting: 我们首先理解集成学习,为了获得更好的预测性能,集成学习结合多个模型(弱学习器)的预测结果。它的策略就是大力出奇迹,因为弱学习器的有效组合可以生成更准确和更鲁棒的模型。集成学习方法分为三大类:
- 弱学习器的有效组合可以生成更准确和更鲁棒的模型
- Bagging: 该技术用于使用随机技术子集,并行构建不同的模型,并聚合所有预测变量的预测结果。
- Boosting: 该技术是可迭代的,顺序进行的和自适应的,因为每个预测器都是针对上一个模型的错误进行修正的。
- Stacking: 这是一种元学习技术,涉及结合来自多种机器学习算法的预测, 例如bagging和boosting。
什么是CatBoost

CatBoost是一种基于对称决策树,为基学习器实现的参数较少,支持类别型变量和高准确性的GBDT框架,主要解决痛点是高效合理的处理类别型特征。这一点从其名字中可以看出来,CatBoost 是由 Categorical 和 Boosting 组成。此外,CatBoost 还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。(解决了梯度偏差以及预测偏移的问题)
- 此外,CatBoost梯度提升算法库中的学习算法基于GPU实现,打分 算法基于CPU实现。
- 主要特点**: 优于同类产品的一些关键特性**。
经验
- 明天将各种的常用算法给其搞一波都行啦的理由与打算。慢慢的将其搞定都行啦的回事与打算。
numba
o
y
t
h
o
n
oython
oython有解释器,比C语言慢十倍甚至百倍。
使用
J
I
T
JIT
JIT技术,使python实现C语言的速度。
python解释器工作原理
python自带虚拟机,用解释器将源代码转换成可执行的字解码,字节码再虚拟机上运行。
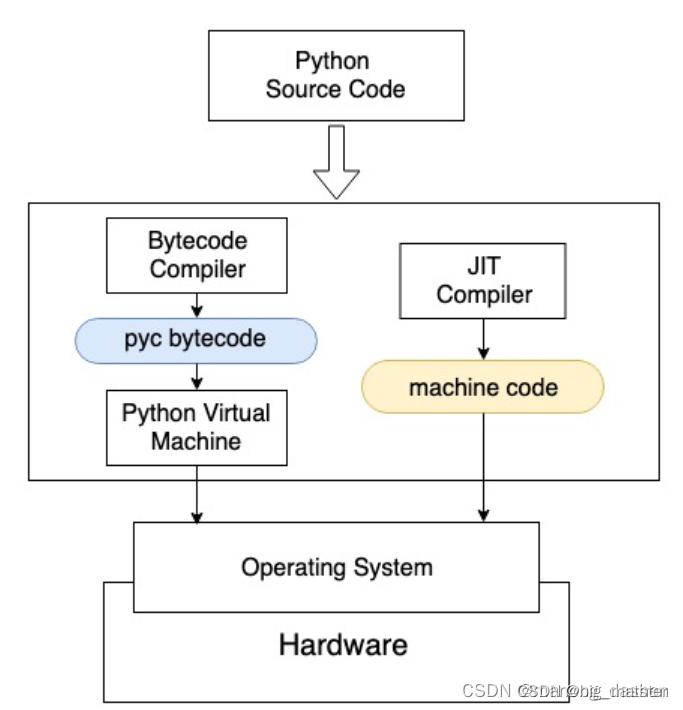
使用python example.py执行源代码时,Python解释器,会在后台启动字节码编译器,将源代码转换成字节码。字节码只能在虚拟机上运行,字节码默认后缀.pyc,python生成.pyc后一般放在内存中继续使用。pyc 字节码通过Python虚拟机与硬件交互, 虚拟机的出现导致程序和硬件之间增加了中间层, 运行效率折扣.Just-In-Time(JIT)技术为解释语言提供了优化.JIT编译器将python源代码编译成可执行的机器语言,可以在CPU等硬件上运行,跳过虚拟机.
*JIT编译器将python源代码编译成可执行的机器语言, 直接在CPU等硬件上运行。
Numba时开源JIT编译器,可以对Python代码进行CPU和GPU加速
使用Numba只需要在原生函数上加一个装饰器.这些函数使用及时编译方式生成机器码,近乎机器码的速度运行.
经验
- 各种库搞定,会自己编写各种库,将其全部都搞定再说的样子与打算。有经验以后,会将其全部都搞定。将其全部都完全搞定都行啦的样子与打算。明天,将相关库涉及的算法全部学习一遍。