文章目录
- 前言
- 一、分片和副本机制
- (一)分片机制
- (二)副本
- 二、Kafka如何保证数据不丢失
- (一)Producer生产者
- (二)Broker
- (三)Consumer消费者
- 三、消息存储和查询机制
- 总结
前言
#博学谷IT学习技术支持#
上篇文章主要讲解Kafka Shell命令和相关API,本文介绍Kafka中较为高级的知识,分片、副本机制等,让我们接着往下看。
一、分片和副本机制
(一)分片机制
分片机制主要解决单台服务器存储容量有限的问题,当数据量非常大的时候,一台服务器存储不了,可以通过将数据拆成多份,分别存在Kafka集群中的不同服务器中;一台服务器上的数据叫做一个分片。
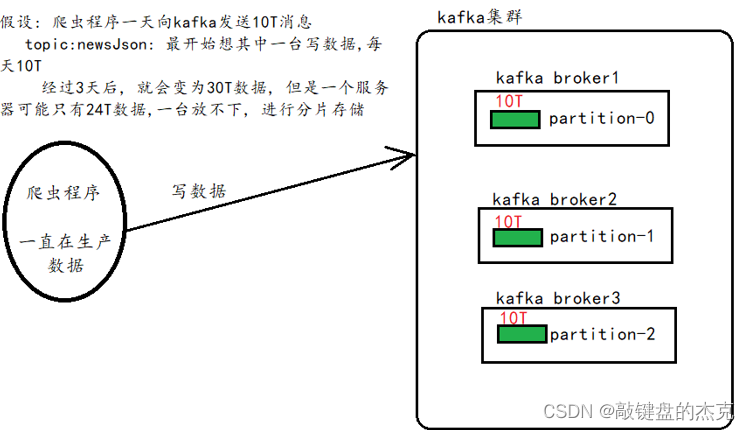
(二)副本
副本备份机制主要是解决数据安全性问题,如果数据只保存一份,那么存在数据丢失的风险,为了更好的容灾和容错,可以将同一份数据存储在不同的服务器上,从而保证数据的安全性。
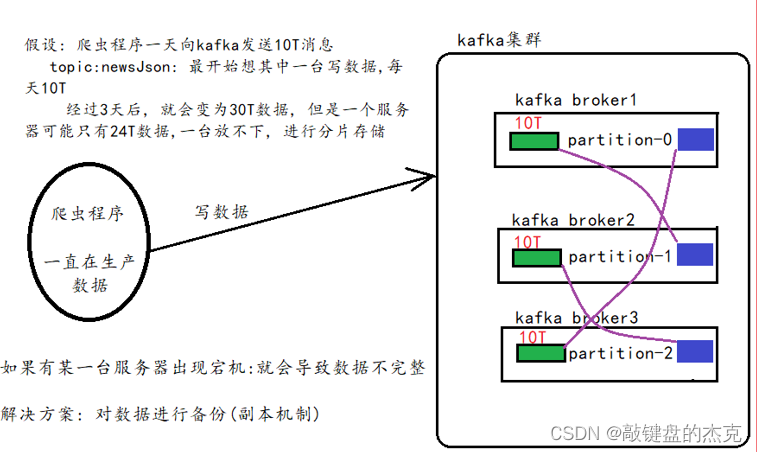
二、Kafka如何保证数据不丢失
保证数据不丢失主要有三个方面,分别是Producer生产者、Broker以及Consumer消费者。
(一)Producer生产者
如果保证生产者数据不丢失,生产数据时需要服务器返回一个响应码Ack,从而保证Kafka集群已经接受到数据,
关于Ack主要有三个状态,根据不同的需求选择不同的Ack状态值:
- 状态值为0:生产者只管生产数据,无需确认Kafka集群是否接收到数据;
- 状态值为1:Kafka集群中的Leader节点接收到数据后返回响应;
- 状态值为-1: Kafka集群中所有节点都接收到数据后返回响应
关于生产者生产数据,存在较为重要的三个问题:
- 如果生产数据时,Kafka集群没有回复Ack响应
- 一条一条发送到Kafka集群中,是否有占用带宽
- 在第2点基础上,如果数据存满后发送给Kafka集群,若此时集群没有及时响应,如何处理缓存池中的数据
针对上方三个问题,肯定有相对应的解决方案,
第一个问题的解决方案就是Producer设置一个TimeOut超时时间,一超时就认定为发送失败;
第二个问题主要的点在于一条一条发送会占用一定的带宽,将数据放进一个缓冲区中,达到一定数据量或者时间,再将缓存区中的数据统一发送给Kafka集群,即可解决问题;
第三个问题需要视具体需求而定,可以对Kafka集群进行设定,若出现该问题时设定是否情况缓冲池中的数据。

![[前端笔记——CSS] 10.层叠与继承、选择器](https://img-blog.csdnimg.cn/fbbfd08c59d4420d9bb683ae6779cad2.png)