JVM学习
JVM常见面试题:
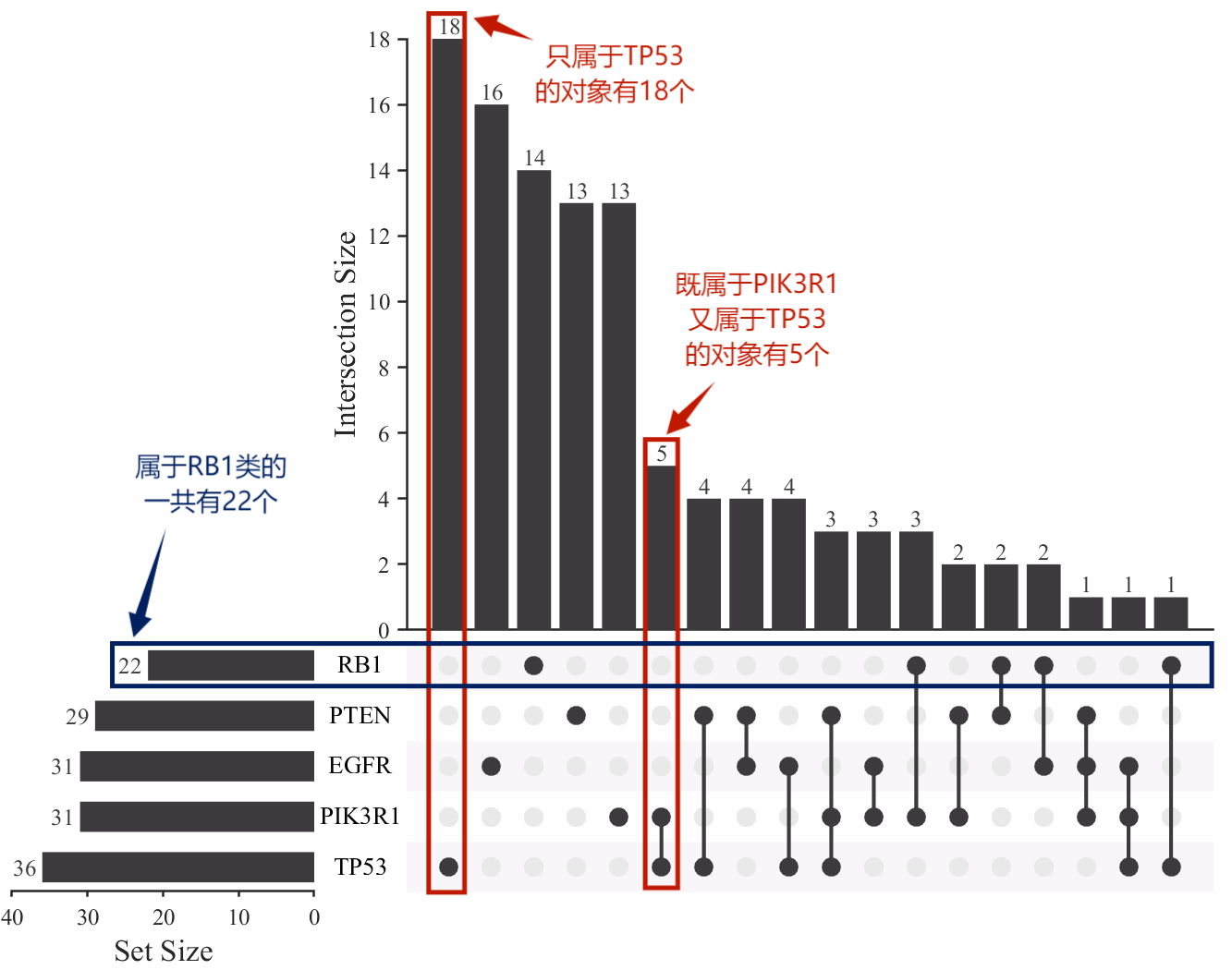
- 请你谈谈你对jvm的理解?Java8虚拟机和之前的变化更新?
- 什么是OOM?什么是栈溢出StackOverFlowError?怎么分析?
- jvm的常见调优参数有哪些?
- 内存快照如何抓取?怎么分析Dump文件?
- 谈谈jvm中,类加载器你的认识?
1、JVM简介
1.1、三种JVM
- Sun公司HotSpot(java -version可以查看)
- BEA的 JRockit
- IBM的 J9VM
1.2、JVM位置

1.3、JVM体系结构


- Java栈、本地方法栈、程序计数器不存在垃圾回收,垃圾回收只在方法区和堆中,99%的JVM调优都是在堆中。


2、类加载器
2.1、简介
类加载器作用:加载Class文件。
类加载分为三个:
- 启动类(根)加载器( Bootstrap ClassLoader):负责加载 jre\lib 目录下的 rt.jar 包。
- 扩展类加载器(Extension ClassLoader):负责加载 jre\lib\ext 目录下的所有jar包。
- 应用程序加载器(Application ClassLoader):负责加载用户类路径上所指定的类库,如果应用程序中没有自定义加载器,那么此加载器就为默认加载器。
2.2、类加载的过程

测试代码:
package text01;
//双亲委派机制
public class Car{
public static void main(String[] args) {
//类是模版,对象是具体的
Car car1 = new Car();
Car car2 = new Car();
Car car3 = new Car();
//得到的hashCode不一样
System.out.println(car1.hashCode());
System.out.println(car2.hashCode());
System.out.println(car3.hashCode());
Class<? extends Car> c1 = car1.getClass();
Class<? extends Car> c2 = car2.getClass();
Class<? extends Car> c3 = car3.getClass();
//得到的hashCode是一样的
System.out.println(c1.hashCode());
System.out.println(c2.hashCode());
System.out.println(c3.hashCode());
//得到类加载器
ClassLoader classLoader = c1.getClassLoader();
System.out.println(classLoader);//AppClassLoader
System.out.println(classLoader.getParent());//ExtClassLoader /jre/lib/Ext
System.out.println(classLoader.getParent().getParent());//null 两种可能:1。不存在;2。java程序获取不到 /rt.jar
}
}
结果:
692404036
1554874502
1846274136
312714112
312714112
312714112
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@61bbe9ba
null
结论:
类是模版,是抽象的,而实例对象是具体的。我们新建的三个实例得到的hashCode都不一样,而这三个实例
getClass得到的类的hashCode是一样的。
2.3、双亲委派机制
参考大佬的博客
双亲委派机制的步骤:
- 类加载器收到类加载的请求。
- 将这个请求向上委托给父类加载器去完成 ,一直向上委托,直到启动类加载器(Boot)。
- 启动类加载器检查是否能够加载当前和这个类 ,能加载就结束,使用当前的加载器,否则,抛出异常,通知子加载器进行加载。
- 重复步骤3。
双亲委派机制的优点:
如果有人想替换系统级别的类:String.java。篡改它的实现,在这种机制下这些系统的类已经被 Bootstrap classLoader 加载过了(为什么?因为当一个类需要加载的时候,最先去尝试加载的就是Bootstrap ClassLoader),所以其他类加载器并没有机会再去加载,从一定程度上防止了危险代码的植入。
测试代码:
我们自定义一个String类,运行时发现会报错。
因为我们自定义的String加载时,总是由启动类加载器加载,而不是应用程序加载器。
package java.lang;
public class String {
public static void main(String[] args) {
String s = new String();
System.out.println(s.toString());
}
public String toString(){
return "Hello";
}
}

2.4、沙箱安全机制(了解)
Java安全模型的核心就是Java沙箱(sandbox),什么是沙箱?沙箱是一个限制程序运行的环境。沙箱机制就是将Java代码限定在虚拟机(JVM)特定的运行范围中,并且严格限制代码对本地系统资源访问,通过这样的措施来保证对代码的有效隔离,防止对本地系统造成破坏。沙箱主要限制系统资源访问,那系统资源包括什么?CPU、内存、文件系统、网络。不同级别的沙箱对这些资源访问的限制也可以不一样。
所有的Java程序运行都可以指定沙箱,可以定制安全策略。
在Java中将执行程序分成本地代码和远程代码两种,本地代码默认视为可信任的,而远程代码则被看作是不受信的。对于授信的本地代码,可以访问一切本地资源。而对于非授信的远程代码在早期的Java实现中,安全依赖于沙箱 Sandbox 机制。如下图所示JDK1.0安全模型:

但如此严格的安全机制也给程序的功能扩展带来障碍,比如当用户希望远程代码访问本地系统的文件时候,就无法实现。因此在后续的Java1.1版本中,针对安全机制做了改进,增加了安全策略,允许用户指定代码对本地资源的访问权限。如下图所示JDK1.1安全模型:

在Java1.2版本中,再次改进了安全机制,增加了代码签名。不论本地代码或是远程代码,都会按照用户的安全策略设定,由类加载器加载到虚拟机中权限不同的运行空间,来实现差异化的代码执行权限控制。如下图所示JDK1.2安全模型:

当前最新的安全机制实现,则引入了 域(Domain) 的概念。虚拟机会把所有代码加载到不同的系统域和应用域,系统域部分专门负责与关键资源进行交互,而各个应用域部分则通过系统域的部分代理来对各种需要的资源进行访问。虚拟机中不同的受保护域(Protected Domain),对应不一样的权限(Permission)。存在于不同域中的类文件就具有了当前域的全部权限。下图所示为最新的安全模型(jdk 1.6):

组成沙箱的基本组件:
- 字节码校验器(bytecode verifier) :确保Java类文件遵循Java语言规范。这样可以帮助Java程序实现内存保护。但并不是所有的类文件都会经过字节码校验,比如核心类。
- 类装载器(class loader):其中类装载器在3个方面对Java沙箱起作用。
- 它防止恶意代码去干涉善意的代码;
- 它守护了被信任的类库边界;
- 它将代码归入保护域,确定了代码可以进行哪些操作。
虚拟机为不同的类加载器载入的类提供不同的命名空间。命名空间由一系列唯一的名称组成, 每一个被装载的类将有一个名字,这个命名空间是由Java虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
类装载器采用的机制是双亲委派模式。
1、从最内层JVM自带类加载器开始加载,外层恶意同名类得不到加载从而无法使用;
2、由于严格通过包来区分了访问域,外层恶意的类通过内置代码也无法获得权限访问到内层类,破坏代码就自然无法生效。
- 存取控制器(access controller) :存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。
- 安全管理器(security manager) :是核心API和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。
- 安全软件包(security package) : java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
- 安全提供者
- 消息摘要
- 数字签名
- 加密
- 鉴别
3、native关键字
- native:凡是带了native关键字的,说明java的作用范围到达不了,回去调用底层C语言的库!
- 会进入本地方法栈,调用本地方法接口 JNI。
- JNI作用:扩展java的使用,融合不同的编程语言为java所用!如:C,C++
- Java诞生的时候 C、C++ 横行,想要立足,必须要有调用C、C++的程序
- 它在内存区域中专门开辟了一块标记区域:Native Method Stack,登记 native 方法
- 在最终执行的时候,通过本地接口 (JNI)加载本地方法库中的方法,如下面代码:
private native void start0();//我们发现这不是一个接口也不是一个抽象类,为什么可以这么写?

4、方法区(Method Area)
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说,所有定义的方法的信息都保存在该区域,此区域属于共享空间。
静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关。
5、PC寄存器(Program Counter Register)
每个线程都有一个程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码(用来存储指向一条指令的地址,也即将要执行的指令代码),在执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
6、栈(Stack)
栈:先进后出、后进先出
队列:先进先出(FIFO:First Input First Output)
喝多了吐就是栈,吃多了拉就是队列!
为什么 main 方法先执行,最后结束?

栈:栈内存,主管程序的运行,生命周期与线程同步。
线程结束,栈内存也就释放,对于栈来说,不存在垃圾回收问题。一旦线程结束,栈就over了。
栈存放:8大基本类型 + 对象引用 + 实例的方法
栈运行原理:栈帧
栈如果满了,就会报错:StackOverFlowError

栈 + 堆 +方 法区的交互关系:

7、堆(Heap)
Heap,一个JVM 只有一个堆内存,堆内存的大小是可以调节的。
类加载器读取了类文件后,一般会把什么东西放到堆中:类的实例、方法、常量、变量~,保存我们所有引用类型的真实对象。
堆内存中还要细分为三个区域:
- 新生区(伊甸园区)Young/New
- 养老区 old
- 永久区 Perm

GC 垃圾回收主要是在伊甸园区和养老区。
假设内存满了,OOM ,堆内存不够!会报错:java.lang.OutOfMemoryError: Java heap space
在JDK 8以后,永久存储区改了个名字(元空间)。
7.1、新生区
新生区包括:伊甸园区、幸存0区、幸存1区。是类诞生和成长、甚至死亡的地方。
所有的的对象都是在伊甸园区new 出来的!
7.2、永久区
这个区域是常驻内存的,用来存放JDK自身携带的Class对象、Interface元数据,存储的是Java运行时的一些环境或类信息。这个区域不存在垃圾回收!关闭JVM虚拟机就会释放这个区域的内存。
**什么情况下永久区出现OOM:**一个启动器,加载了大量的第三方jar包,Tomcat部署了太多应用,大量动态生成的反射类,直到内存满,就会出现OOM。
常量池在哪:
- jdk 1.7之前:常量池是在存放在方法区(HotSpot VM对方法区的实现称为永久代)中,方法区与堆是独立的。
- jdk 1.7 :常量池从永久代中移到了堆内存中,属于堆内存的一部分。
- jdk 1.8之后:移除了永久代并由元空间代替,存放在本地内存中,并没有对常量池再做变动,即常量池一直在堆中。
方法区就像是一个接口,永久代与元空间分别是两个不同的实现类。只不过永久代是这个接口最初的实现类,后来这个接口一直进行变更,直到最后彻底废弃这个实现类,由新实现类—元空间进行替代。
元空间逻辑上存在,物理上不存在(元空间使用的是本地内存):

测试代码:
package text01;
public class demo03 {
public static void main(String[] args) {
//返回虚拟机试图使用的最大内存
long max = Runtime.getRuntime().maxMemory();//1MB = 1024 * 1024 B(字节)
//返回JVM初始化的总内存
long total = Runtime.getRuntime().totalMemory();
System.out.println("max="+max+"字节\t"+(max/(double)1024/1024)+"MB");//1820.5MB
System.out.println("max="+total+"字节\t"+(total/(double)1024/1024)+"MB");//123.0MB
//默认情况下:分配的总内存是电脑内存的 1/4,而初始化的内存是电脑内存的 1/64
//调参:-Xms1024m -Xmx1024m -XX:+PrintGCDetails
//OOM问题解决:
//1.尝试扩大堆内存看结果
//2.分析内存,看一下哪个地方出现了问题(专业工具)
}
}
结果:

我们看到新生区和老年区的内存相加为JVM总内存(305664K+699392K = 1005056K=981.5M),因此,元空间逻辑上存在,物理上不存在。
7.3、堆内存调优
使用JProfiler解决OOM问题:
Jprofiler作用:
- 分析Dump内存文件,快速定位内存泄漏
- 获得堆中的数据
- 获得占内存大的对象
下载Jprofiler:
- 先在idea的插件中下载Jprofiler插件:

- 下载客户端
mac下载参考博客
- 下载之后配置

mac的路径为:/Applications/JProfiler.app
分析OOM问题
- 编写一个制造OOM错误的方法。
package text01;
import java.util.ArrayList;
//-Xms:设置初始化内存分配大小,默认为电脑内存的1/64
//-Xmx:设置最大分配内存,默认为电脑内存的1/4
//-XX:+PrintGCDetails:打印GC垃圾回收
//-XX:+HeapDumpOnOutOfMemoryError:得到OOM的dump文件
public class demo04 {
byte[] arr = new byte[1*1024*1024];//1M
public static void main(String[] args) {
ArrayList<demo04> list = new ArrayList<>();
int count = 0;
try {
while (true){
list.add(new demo04());//问题所在
count++;
}
} catch (Error e) {
System.out.println("count = " + count);
e.printStackTrace();
}
}
}
- 配置参数:

-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
- 运行会在项目的源文件中得到一个文件,直接打开:
会发现哪个对象占用的内存最大:

查看线程,可以看到错误代码在第几行:

8、GC垃圾回收
JVM 在进行垃圾回收(GC)时,并不是在堆的三个区域统一回收,大部分时候,回收都是新生代。
GC 两种类:轻GC(普通GC),重GC (全局GC)。轻GC 指针对新生代和偶尔走一下幸存区,重GC全部清完。
GC题目:
- JVM的内存模型和分区,详细到每一个区放什么?
- 堆里面的分区有哪些?Eden,from,to,老年区,说说他们的特点!
- GC的算法有哪些?标记清除法、标记压缩、复制算法、引用计数法,怎么用的?
- 轻GC和重GC分别在什么时候发生?
8.1、引用计数法
在 JVM 中几乎不用。每个对象在创建的时候,就给这个对象绑定一个计数器(有消耗)。每当有一个引用指向该对象时,计数器加一;每当有一个指向它的引用被删除时,计数器减一。这样,当没有引用指向该对象时,该对象死亡,计数器为0,这时就应该对这个对象进行垃圾回收操作。

8.2、复制算法


- 好处:没有内存的碎片。
- 坏处:浪费了内存空间:多了一半空间 to 永远是空。假设对象100%存活(极端情况),不适合使用复制算法。
复制算法最佳使用场景:新生区(对象存活度较低)
8.3、标记清除算法

- 优点:不需要额外的空间。
- 缺点:两次扫描,严重浪费时间,会产生内存碎片。
8.4、标记清除压缩算法

一般可以进行多次标记清除,再进行一次压缩。
8.5、总结
内存效率:复制算法 > 标记清除算法 > 标记压缩算法(时间复杂度)
内存整齐度:复制算法 = 标记压缩算法 > 标记清除算法
内存利用率:标记压缩算法 = 标记清除算法 > 复制算法
思考一个问题:难道没有最优算法吗?
答案:没有,没有最好的算法,只有最合适的算法——》GC:分代收集算法
年轻代:
- 存活率低
- 复制算法
老年代:
- 区域大:存活率高
- 标记清除(内存碎片太多)+标记压缩混合实现
9、JMM
这里感觉啥也没讲!
参考大佬博客
学习方式:
-
JMM是什么?
-
它干嘛的?
-
它如何学习?