RDD的创建
如下代码,Spark RDD编程的入口对象是SparkContext对象(不论何种编程语言),只有构建出SparkContext,基于它才能执行后续的API调用和计算
本质上,Spark Context对编程来说,主要功能就是创建第一个RDD出来
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# setMaster("local[*]") 实际上在Linux上Spark单机环境跑的,并没有在yarn集群上
# 当master和控制台参数冲突时,代码优先级更高
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
# 通过SparkConf对象构建SparkContext
sc = SparkContext(conf=conf)
# 需求: wordcount单词计数,读取HDFS上的word.txt文件,对其内部的单词统计出现 的数量
# 可以读取HDFS文件,也可以读取工程的本地路径文件(就是Linux的文件,因为会同步到Linux中),但是提交到集群运行时,只能时HDFS的文件
file_rdd = sc.textFile("hdfs://node1:8020/input/words.txt") # 一行一个list,最终是一个list嵌套
# 将单词进行切割,得到一个存储全部单词的集合对象
word_rdd = file_rdd.flatMap(lambda line: line.split(" "))
# 将单词转换为元组,key是单词,value是数字1
word_with_one_rdd = word_rdd.map(lambda x: (x , 1))
# 将元组的value 按照key分组,对所有value执行聚合操作(相加)
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 通过collect方法收集RDD的数据,打印输出结果
print(result_rdd.collect())
RDD的创建方式
主要有两种:
1、通过并行化集合创建(本地对象 转 分布式RDD)
2、读取外部数据源(读取文件)
方式一:通过并行化集合创建(本地对象 转 分布式RDD)
概念:并行化创建,是指,将本地集合 转向 分布式RDD
这一步就是分布式的开端,本地转分布式
rdd = sparkcontext.parallelize(参数1,参数2)
# 参数1 集合对象即可,如list
# 参数2 分区数
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 并行化集合的方式创建RDD, 本地集合 -> 分布式对象(RDD)
rdd01 = sc.parallelize([1,2,3,4,5,6,7,8,9])
# parallelize 方法,不给分区数,默认分区数是根据CPU核心数,这儿使用的 单机模式哈
print("默认分区数:",rdd01.getNumPartitions())
rdd02 = sc.parallelize([1,2,3],3)
print("分区数:",rdd02.getNumPartitions())
# collect 方法,是将RDD(分布式对象)中每个分区的数据,都发送到Driver中,形成一个Python List对象
print("rdd01:",rdd01.collect())
print("rdd02:",rdd02.collect())
方式二:读取外部数据源(读取文件)
这个API可以读取本地数据,也可以读取HDFS数据
# 使用方法
sparkContext.textFile(参数1,参数2)
# 参数1:必填,文件路径,支持本地文件,也支持HDFS和一些S3协议
# 参数2:可选,表示最小分区数
# 注意:参数2 话语权不足,spark有自己判断,在它允许范围内,参数2有效果,超出spark允许的范围,参数2失效
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
file_rdd01 = sc.textFile("../data/input/word.txt")
# 对于读取本地文件来说,分区数和CPU无关,和文件大小有关
# 如果读取HDFS,分区数和Block块的数量有关
print("默认分区数:", file_rdd01.getNumPartitions())
print("file_rdd01 内容:", file_rdd01.collect())
# 加最小分数参数的测试
file_rdd02 = sc.textFile("../data/input/word.txt",3)
file_rdd03 = sc.textFile("../data/input/word.txt",100)
print("file_rdd02分区数:", file_rdd02.getNumPartitions()) # 3
print("file_rdd03分区数:", file_rdd03.getNumPartitions()) # 67 最小分区数是参考值,Spark有自己判断,给的太大Spark不会理会
# 读取HDFS文件数据测试
hdfs_rdd = sc.textFile("hdfs://node1:8020/input/words.txt")
print("hdfs_rdd内容:",hdfs_rdd.collect())
还有一个API
wholeTextFile
读取文件的API,有个使用场景:适合读取一堆小文件
这个API是小文件读取专用
这个API偏向于少量分区读取数据
因为,这个API表名了自己是小文件读取专用,那么文件的数据很小,分区很多,导致shuffle的几率更高,所以尽量少分区读取数据。进而提高性能。
用法:
sparkContext.wholeTextFile(参数1,参数2)
# 参数1:必填,文件路径,支持本地文件,也支持HDFS和一些S3协议
# 参数2:可选,表示最小分区数
# 注意:参数2 话语权不足,这个API 分区数量最多只能开到文件数量
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 读取小文件的文件夹,里面有多个小文件
rdd = sc.wholeTextFiles("../data/input/tiny_files")
# 存放数据是list,元素是二元元组,[(文件路径1,文件内容1),(文件路径2,文件内容2)]
print(rdd.collect())
RDD算子
算子:分布式集合对象上的API称之为算子
主要为了和本地对象的API进行区分,本地对象的API叫做方法/函数。分布式对象的API叫做算子。
算子分两类:
- Transformation : 转换算子
- Action : 动作(行为)算子
Transformation算子
定义:RDD的算子,返回值仍旧是一个RDD,称之为转换算子(转换RDD形态)
特性:这类算子是 lazy 懒加载的,如果没有action算子,Transformation算子是不工作的。
Action算子
定义:返回值不是RDD的就是action算子。
对于这两类算子来说,Transformation算子 相当于在构建执行计算,action算子是一个指令,让这个执行计划开始工作。
如果没有action,Transformation算子之间的迭代关系,就是一个没有通电的流水线,只有action到来,这个数据处理的流水线才开始工作。
比如将上面的示例代码复制下来分析:
file_rdd = sc.textFile("hdfs://node1:8020/input/words.txt")
word_rdd = file_rdd.flatMap(lambda line: line.split(" "))
word_with_one_rdd = word_rdd.map(lambda x: (x , 1))
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
print(result_rdd.collect())
RDD的迭代关系 file_rdd -> word_rdd -> word_with_one_rdd -> result_rdd
这些对应的算子都是转换算子。
这就类似于构建执行计算,这些都是逻辑代码。
最后运行的时候,要靠 action算子(collect)进行触发。
用自己话说:前面的都是执行计算,需要action算子去触发执行计算。 没有action算子,上面的转换算子是不生效的。
常见的转换算子
1、map算子
功能:map算子,是将RDD的数据一条条处理(处理的逻辑 基于算子中接收的处理函数),返回新的RDD
# 语法
rdd.map(func)
# func : f(T) -> U
# (T) -> U 表示方法的定义
# (T)表示 传入1个参数 () 表示没有传入参数
# T 泛型,表示任意参数
# U 泛型,表示任意参数
# ->U 表示返回值
# (T) -> U : 这个方法接收一个参数传入,传入参数类型不限。返回一个返回值,返回值类型不限
# (A) -> A : 这个方法接收一个参数传入,传入参数类型不限。返回一个返回值,但是返回值类型必须和传入参数类型保持一致。
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1,2,3,4,5,6],3)
def add(data):
return data * 10
print(rdd.map(add).collect())
print("-----------------")
print(rdd.map(lambda x : x*10).collect())
# 对于算子的接收函数来书,两种方式都可以
# lambda表达式,适用于一行代码就能搞定的函数体,如果是多行,需要定义独立的方法
2、flatMap算子
功能: 对rdd 执行map操作,然后进行 解除嵌套 操作
flatMap 和 map 传入参数一样,就是多了一个解除嵌套的功能
解除嵌套:
嵌套的list
list = [ [1,2,3] , [3,4], [5,6] ]
解除嵌套
list= [ 1,2,3,3,4,5,6 ]
代码示例:
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["a b c" , "d e f", "g h i"], 3)
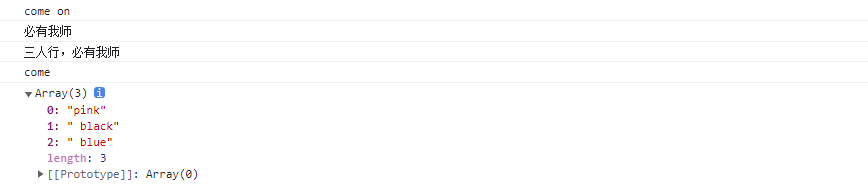
print(rdd.flatMap(lambda x : x.split(" ")).collect())
map执行结果:
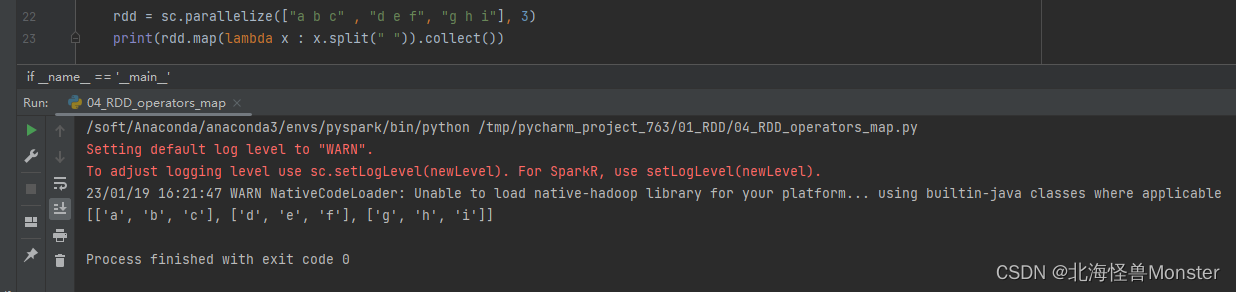
flatMap执行结果:
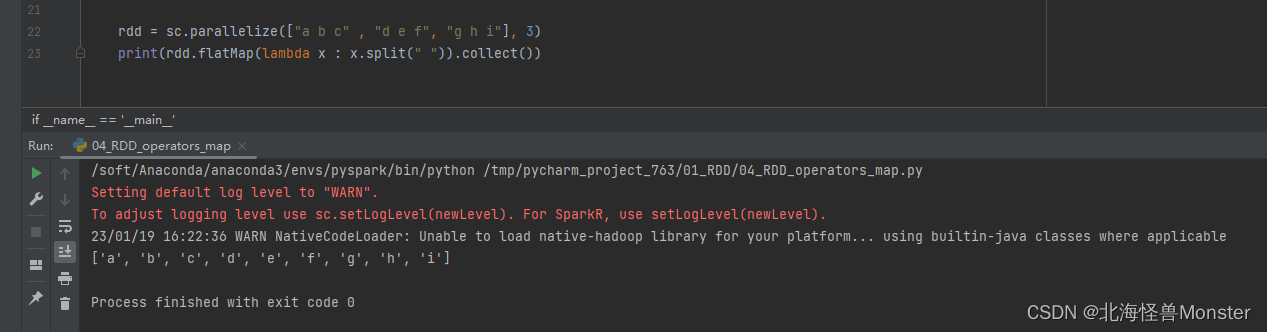
以上直观对比了什么叫解除嵌套。
3、reduceByKey算子
功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
用法:
rdd.reduceByKey(func)
# func : (V,V) -> V
# 接收两个传入参数,类型一致。返回一个返回值,返回值类型和传入参数类型一致
首先按照key自动进行分组,然后再针对 value 进行聚合。
我们传入的参数就是 聚合的逻辑。
所以两个形参,就代表两个value
value的聚合逻辑需要注意以下:
b永远是新元素,a 除了第一次以外是默认元素,后面所有的a都是上一次的聚合结果作为a。

代码示例:
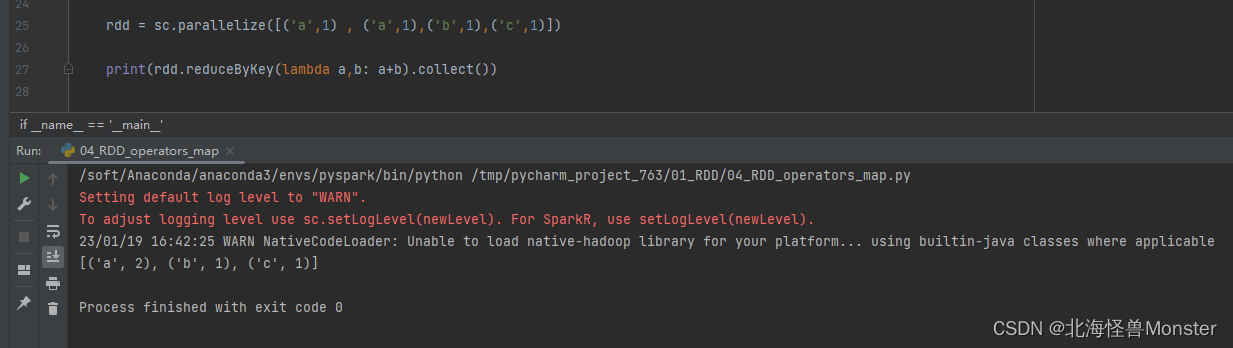
4、mapValues算子
功能:针对 二元元组 RDD,对其内部的二元元组的Value执行map操作
语法:
rdd.mapValues(func)
# func : (V) - > v
# 注意: 传入的参数,是二元元组 的value值
我们这个传入的方法,只对value进行处理
代码示例:
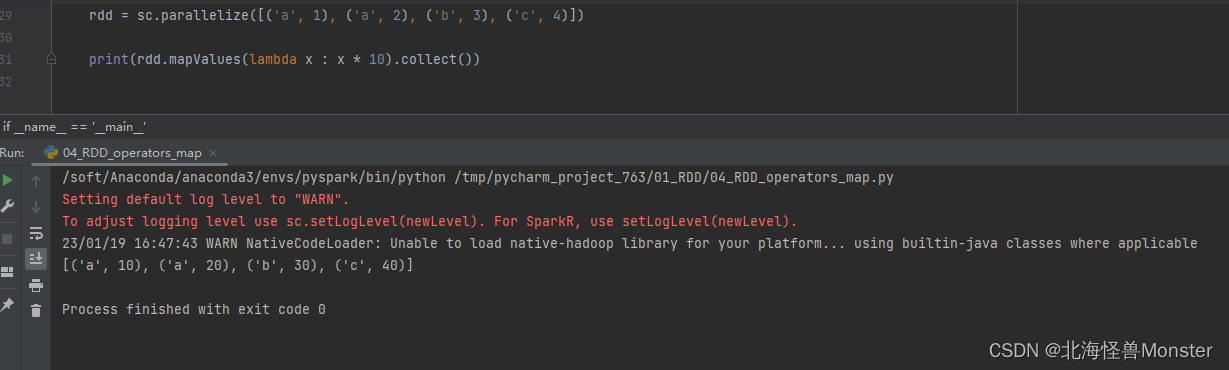
如果使用map算子,需要将value取出来,使用mapValues,就只针对value进行操作
rdd.map(lambd x : ( x[0], x[1] * 10 ))
5、groupBy算子
功能:将rdd的数据进行分组,分组效果和sql的分组是一致的,就是hash分组
语法:
rdd.groupBy(func)
# func 函数
# func : (T) -> K
# 函数要求传入一个参数,返回一个返回值,类型无所谓
# 这个函数是 拿到你的返回值后,将所有相同返回值放入到一个组中
# 分组完成后,每一个组是一个二元元组,key就是返回值,所有同组的数据放入一个迭代器对象中作为value
代码示例:
第一个打印结果,显示的是迭代器对象
第二个打印结果,将迭代器对象强制转换为 list,为了方便显示结果

示例2:
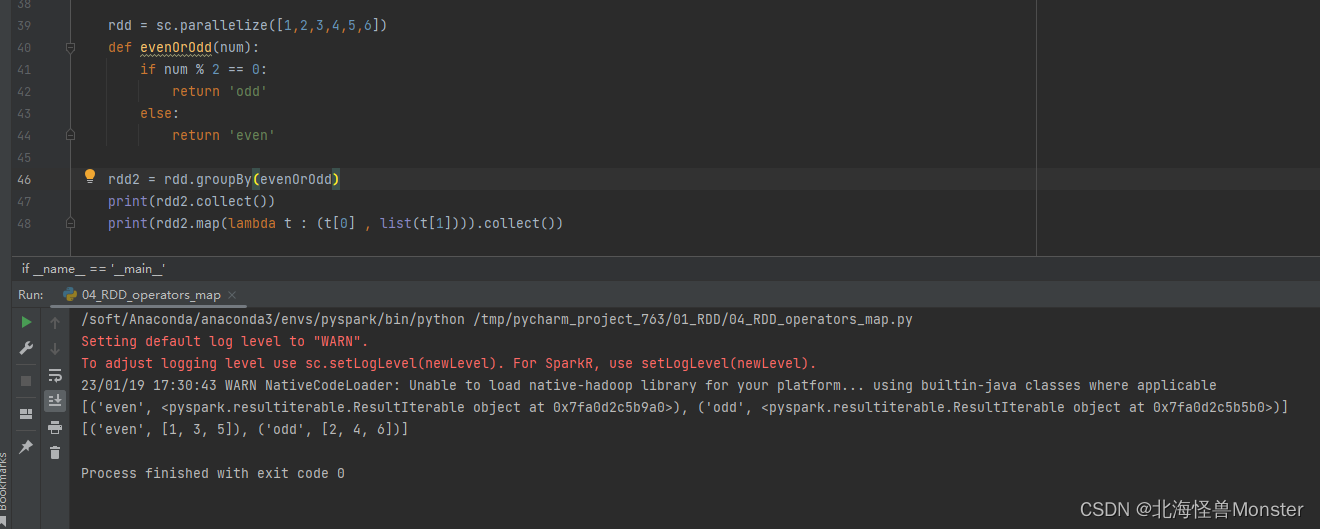
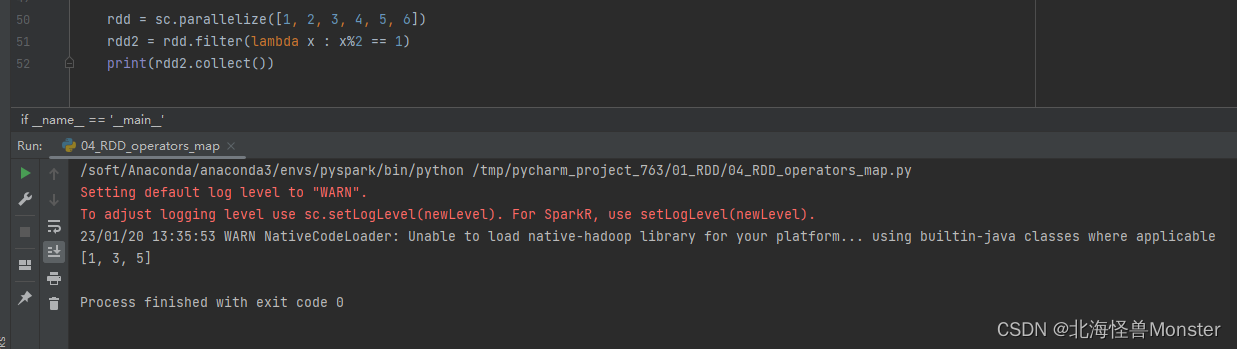
6、filter算子
功能:过滤想要的数据并进行保留
语法:
rdd.filter(func)
# func : (T) -> bool
# 传入1个任意类型的参数,返回值只能是布尔类型
# 返回值为 True的数据保留 , 返回值为 False的数据被丢弃
代码示例:
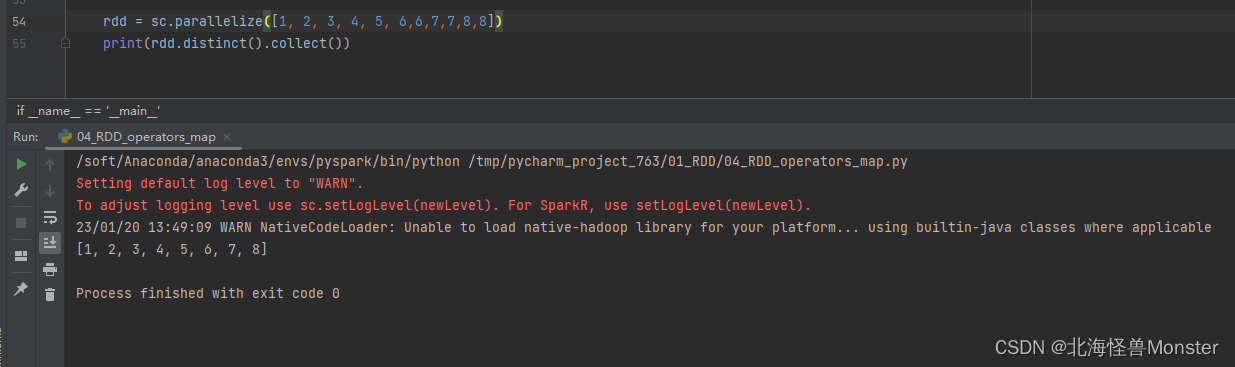
7、distinct算子
功能:对RDD数据进行去重,返回新RDD
语法:
rdd.distinct(参数1)
# 参数1: 去重分区数量,一般不用传。就是按照几个分区去重
# 还可以去重元组,字符串等类型。不管什么类型,只要有重复,都可以完成去重操作
代码示例:
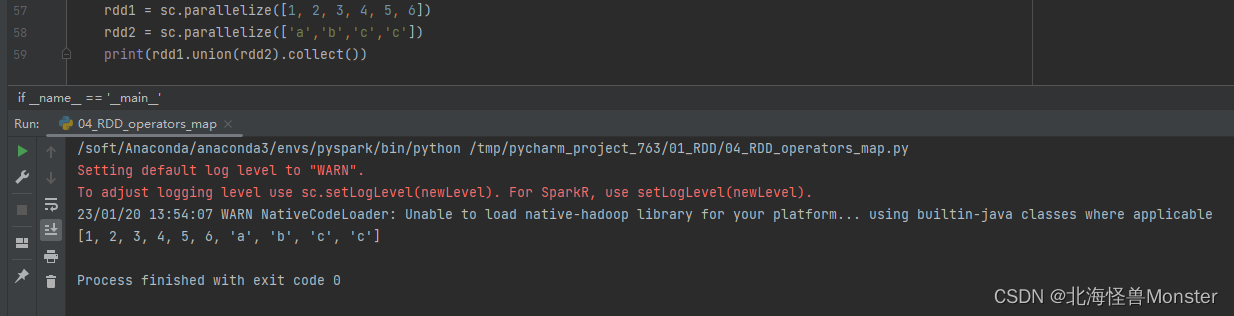
8、union算子
功能:将两个rdd合并为1个rdd,并进行返回
语法:
rdd.union(other_rdd)
# 注意:只是合并,不会去重
# rdd数据类型不同也可以合并
代码示例:
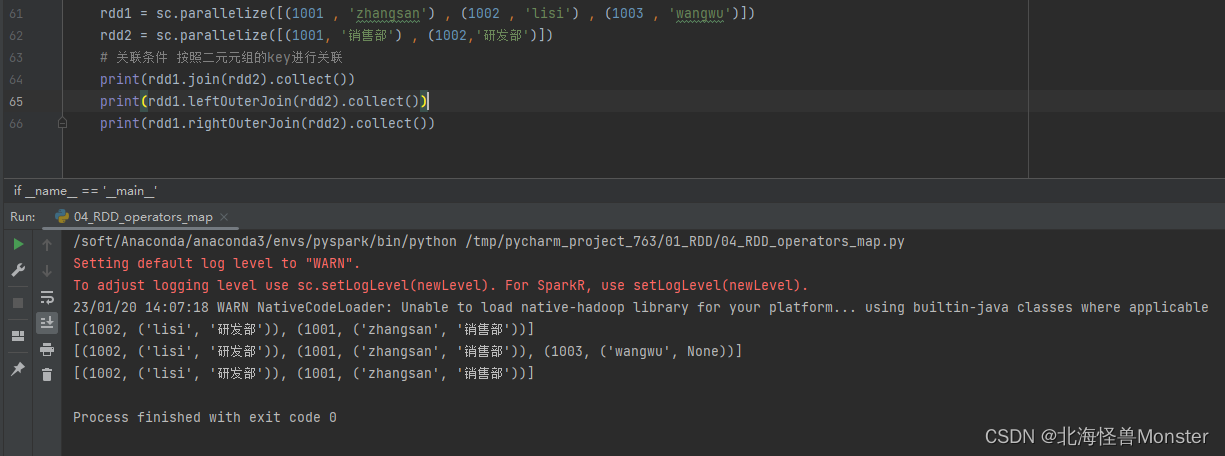
9、join算子
功能:对两个RDD执行JOIN操作,可实现SQL的内/外连接
注意:join算子只能用于二元元组
语法:
rdd.join(other_rdd) # 内连接
rdd.leftOuterJoin(other_rdd) # 左外连接
rdd.rightOuterJoin(other_rdd) # 右外连接
# 关联条件 按照二元元组的key进行关联
代码示例:
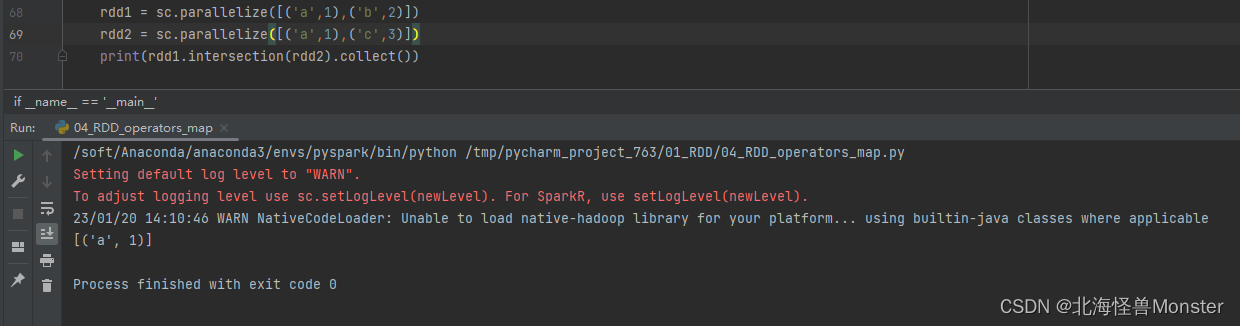
10、intersection算子
功能:求2个rdd的交集,返回一个新的rdd
语法:
rdd.intersection(other_rdd)
代码演示:
11、glom算子
功能:将RDD的数据,加上嵌套,这个嵌套按照分区进行
比如 RDD数据 [1,2,3,4,5] 有两个分区
那么,被glom之后,数据变成: [ [1,2,3] , [4,5] ]
简单的讲就是,按照存储分区给rdd的数据加上嵌套。
语法:
rdd.glom()
代码演示:

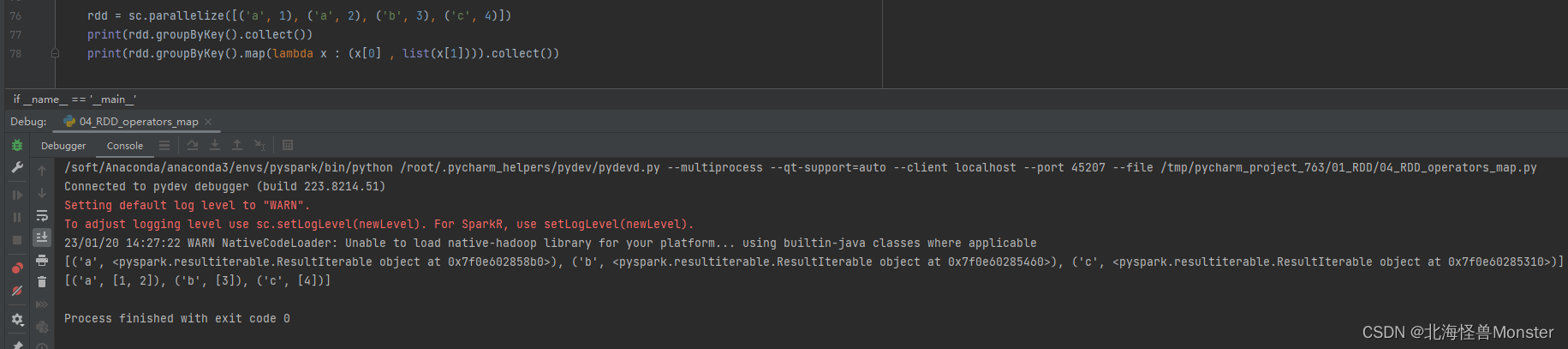
12、groupByKey算子
功能:针对 KV 型 RDD,自动按照key分组
和groupBy 类型,groupBy需要自己设置分组规则,这个直接按照key分组
语法:
rdd.groupByKey()
# 和groupBy 还是有一点区别,首先分组规则就不说了。
# 在返回值时,groupByKey 是直接将 value值聚合,groupBy 是将整个元组聚合
代码示例:
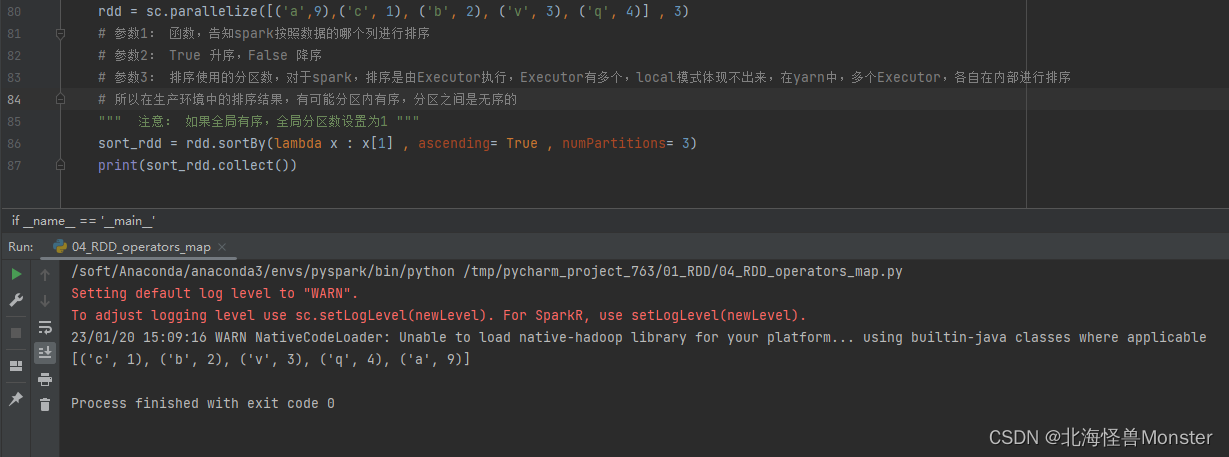
13、sortBy算子
功能:对RDD数据进行排序,基于你指定的排序依据
语法:
rdd.sortBy(func , ascending = False , numPartitions = 1)
# func : (T) -> U , 按照rdd中的哪个数据进行排序,比如:lambda x : x[1] 表示按照rdd中的第二列元素进行排序
# ascending , True 升序, False 降序
# numPartitions : 用多少分区排序
代码示例:
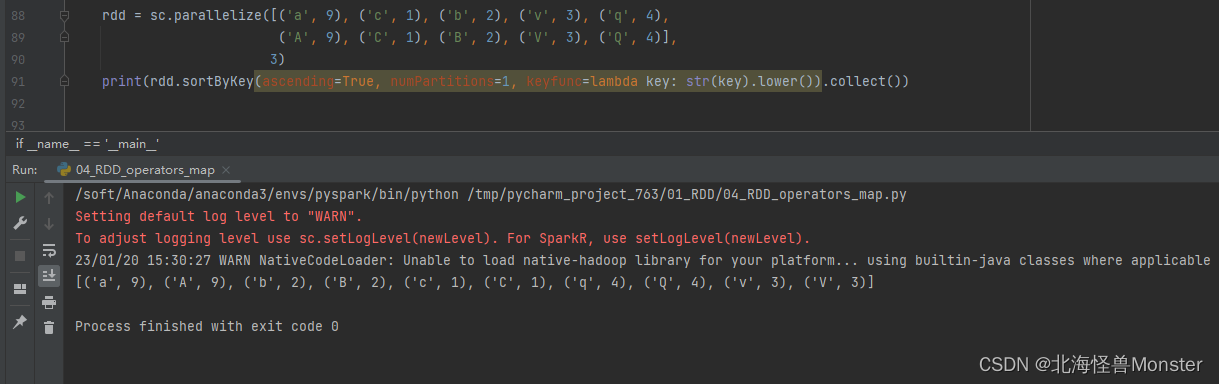
14、sortByKey算子
功能: 针对 KV 型,按照key进行排序
语法:
rdd.sortByKey(ascending = True , numPartitions = None , keyfunc = func)
# ascending : True 升序,False降序,默认为True
# numPartitions : 按照几个分区进行排序,如果全局有序设置为1
# Keyfunc : 在排序之前对key 进行处理,语法 (k) -> U 一个参数传入,返回一个值
相比 sortBy,sortByKey 函数中的形参直接就代表key值。sortBy算子函数中的形参代表元组。
Demo
Demo数据:
{"id":1,"timestamp":"2019-05-08T01:03.00Z","category":"平板电脑","areaName":"北京","money":"1450"}|{"id":2,"timestamp":"2019-05-08T01:01.00Z","category":"手机","areaName":"北京","money":"1450"}|{"id":3,"timestamp":"2019-05-08T01:03.00Z","category":"手机","areaName":"北京","money":"8412"}
{"id":4,"timestamp":"2019-05-08T05:01.00Z","category":"电脑","areaName":"上海","money":"1513"}|{"id":5,"timestamp":"2019-05-08T01:03.00Z","category":"家电","areaName":"北京","money":"1550"}|{"id":6,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"杭州","money":"1550"}
{"id":7,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"北京","money":"5611"}|{"id":8,"timestamp":"2019-05-08T03:01.00Z","category":"家电","areaName":"北京","money":"4410"}|{"id":9,"timestamp":"2019-05-08T01:03.00Z","category":"家具","areaName":"郑州","money":"1120"}
{"id":10,"timestamp":"2019-05-08T01:01.00Z","category":"家具","areaName":"北京","money":"6661"}|{"id":11,"timestamp":"2019-05-08T05:03.00Z","category":"家具","areaName":"杭州","money":"1230"}|{"id":12,"timestamp":"2019-05-08T01:01.00Z","category":"书籍","areaName":"北京","money":"5550"}
{"id":13,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"5550"}|{"id":14,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"1261"}|{"id":15,"timestamp":"2019-05-08T03:03.00Z","category":"电脑","areaName":"杭州","money":"6660"}
{"id":16,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"天津","money":"6660"}|{"id":17,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"9000"}|{"id":18,"timestamp":"2019-05-08T05:01.00Z","category":"书籍","areaName":"北京","money":"1230"}
{"id":19,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"杭州","money":"5551"}|{"id":20,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"2450"}
{"id":21,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"5520"}|{"id":22,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"6650"}
{"id":23,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"1240"}|{"id":24,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"天津","money":"5600"}
{"id":25,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"7801"}|{"id":26,"timestamp":"2019-05-08T01:01.00Z","category":"服饰","areaName":"北京","money":"9000"}
{"id":27,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"5600"}|{"id":28,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"8000"}|{"id":29,"timestamp":"2019-05-08T02:03.00Z","category":"服饰","areaName":"杭州","money":"7000"}
需求:计算出北京有多少销售类别
代码示例:
# coding:utf8
from pyspark import SparkConf, SparkContext
import json
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 读取文件数据
file_rdd = sc.textFile("../data/order.txt")
# print(file_rdd.collect()) # 一行为一个元素
# 通过 | 分隔符 进行数据切分
jsons_rdd = file_rdd.flatMap(lambda x : x.split("|"))
# print(jsons_rdd.collect()) # 一个json字符串为一个元素
# 通过Python内置的json库,将json字符串转换为 字典对象
dict_rdd = jsons_rdd.map(lambda json_str : json.loads(json_str))
# print(dict_rdd.collect()) # 将json字符串转换为 字典对象
# 过滤数据
beijing_rdd = dict_rdd.filter(lambda d : d['areaName'] == "北京")
# 组合北京和商品类型形成新的字符串
category_rdd = beijing_rdd.map(lambda x : x['areaName'] + "_" + x["category"])
# 去重
result_rdd = category_rdd.distinct()
print(result_rdd.collect())
执行结果:

将demo提交到YARN中执行
提交方式1:在PyCharm中直接提交
#改动1:加入环境变量,让pycharm直接提交yarn的时候,知道hadoop配置在哪儿,可以去读取yarn的信息
import os
os.environ["HADOOP_CONF_DIR"] = "/export/server/hadoop/etc/hadoop"
# 在集群中运行 本地文件就不可以了,需要使用hdfs文件
rdd = sc.textFile("hdfs://node1:8020/input.order.txt")
# 如果在PyCharm 中直接提交到yarn,依赖了其他的python文件,可以通过设置属性来指定依赖代码
# 如果在代码中运行,那么依赖的其他文件,可以通过spark.pyFiles属性来设置
# conf对象,可以通过setAPI 设置数据,参数1 是key , 参数2 是value
conf.set("spark.submit.pyFiles","defs.py")
代码更改:
主代码:
# coding:utf8
from pyspark import SparkConf, SparkContext
from defs_06 import city_with_category
import json
import os
os.environ["HADOOP_CONF_DIR"] = "/soft/hadoop/hadoop-3.3.4-src/hadoop-dist/target/hadoop-3.3.4/etc/hadoop"
if __name__ == '__main__':
# 通过SparkConf对象构建SparkContext
conf = SparkConf().setAppName("test").setMaster("yarn")
# 如果提交到集群运行,除了主代码以外,还依赖了其他代码文件
# 还需要设置一个参数,告知spark,还有其他依赖文件需要同步上传到集群中
# 参数 spark.submit.pyFiles,参数的值可以是 单个.py文件,也可以是.zip压缩包(有多个依赖文件时,可以使用zip压缩后上传)
conf.set("spark.submit.pyFiles","defs_06.py")
sc = SparkContext(conf=conf)
# 读取文件数据
file_rdd = sc.textFile("hdfs://node1:8020/input/order.txt")
# print(file_rdd.collect()) # 一行为一个元素
# 通过 | 分隔符 进行数据切分
jsons_rdd = file_rdd.flatMap(lambda x : x.split("|"))
# print(jsons_rdd.collect()) # 一个json字符串为一个元素
# 通过Python内置的json库,将json字符串转换为 字典对象
dict_rdd = jsons_rdd.map(lambda json_str : json.loads(json_str))
# print(dict_rdd.collect()) # 将json字符串转换为 字典对象
# 过滤数据
beijing_rdd = dict_rdd.filter(lambda d : d['areaName'] == "北京")
# 组合北京和商品类型形成新的字符串
category_rdd = beijing_rdd.map(city_with_category)
# 去重
result_rdd = category_rdd.distinct()
print(result_rdd.collect())
defs_06.py
# coding:utf8
def city_with_category(data):
return data['areaName'] + "_" + data["category"]
提交方式2:在服务器上通过spark-submit 提交到集群运行
当你的开发环境没有和生产环境连通,或者测试环境连通。那么你需要将文件提交到生产/测试环境中,使用命令行的方式进行提交。
# --py-files 可以帮你指定 你依赖的其他python代码,支持 .zip(一堆),也可以单个 .py 文件都行
/export/server/spark/bin/spark-submit --master yarn --py-files ./def.zip ./main.py
/export/server/spark/bin/spark-submit --master yarn --py-files 依赖文件路径 主文件路径
依赖文件可以指定压缩包,也可以指定单个文件


![[Android]Bitmap Drawable](https://img-blog.csdnimg.cn/accc337971af4ee3839114832f7bffe6.jpeg)