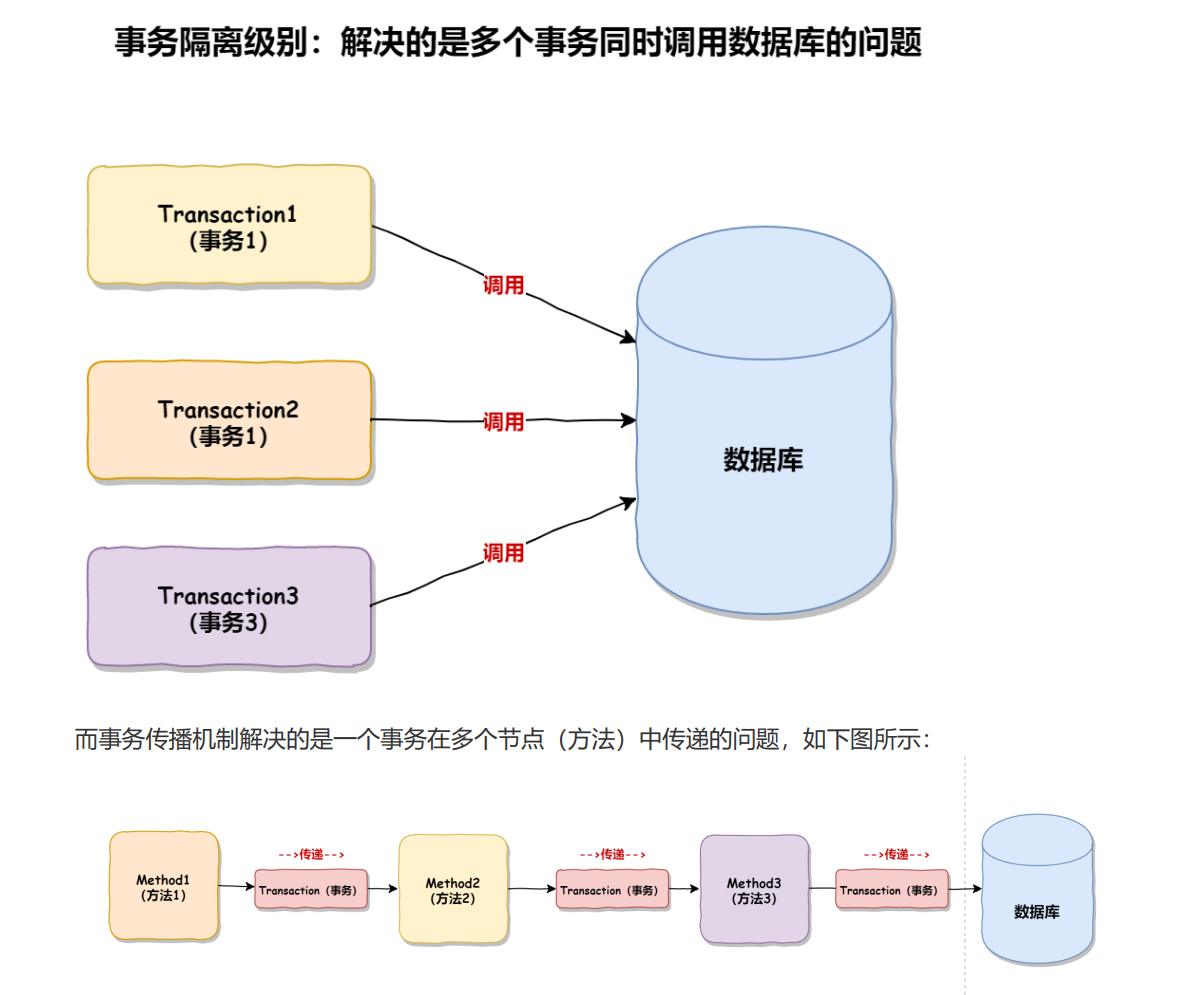
文章目录
- JdbcTemplate
- 准备工作
- 导入依赖
- 创建jdbc.properties
- 配置Spring的配置文件
- 配置测试类的环境
- 实例
- 声明式事务概念
- 先看看对应的编程式事务
- 声明式事务
- 通过一个案例了解声明式事务
- 前提准备
- 三层架构的构建
- 模拟场景的情况
- 添加事务
- Spring声明式事务的属性
- 事务注解标识的位置
- 事务属性:只读
- 事务属性:超时
- 事务属性:回滚策略
- 事务属性:事务隔离级别
- 事务引起的问题
- 幻读和不可重复读的区别
- 为什么要设置事务的隔离级别?
- 事务属性:事务传播行为
- Spring的几种事务传播机制
- 为什么需要事务传播机制?
JdbcTemplate
- Spring 框架对 JDBC 进行封装,使用 JdbcTemplate 方便实现对数据库操作
准备工作
导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lsc.spring</groupId>
<artifactId>spring_jdbctemplate</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- 基于Maven依赖传递性,导入spring-context依赖即可导入当前所需所有jar包 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.1</version>
</dependency>
<!-- Spring 持久化层支持jar包 -->
<!-- Spring 在执行持久化层操作、与持久化层技术进行整合过程中,需要使用orm、jdbc、tx三个
jar包 -->
<!-- 导入 orm 包就可以通过 Maven 的依赖传递性把其他两个也导入 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>5.3.1</version>
</dependency>
<!-- Spring 测试相关 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.3.1</version>
</dependency>
<!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<!-- 数据源 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.31</version>
</dependency>
</dependencies>
</project>
创建jdbc.properties
jdbc.user=root
jdbc.password=atguigu
jdbc.url=jdbc:mysql://localhost:3306/ssm
jdbc.driver=com.mysql.jdbc.Driver
配置Spring的配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<!-- 导入外部属性文件 -->
<context:property-placeholder location="classpath:jdbc.properties" />
<!-- 配置数据源 -->
<bean id="druidDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="url" value="${jdbc.url}"/>
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<!-- 配置 JdbcTemplate -->
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate">
<!-- 装配数据源 -->
<property name="dataSource" ref="druidDataSource"/>
</bean>
</beans>
配置测试类的环境
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:spring-jdbctemplate.xml")
public class JdbcTemplateTest {
@Autowired
private JdbcTemplate jdbcTemplate;
}
- @RunWith(SpringJUnit4ClassRunner.class)
- //指定当前测试类在Spring的测试环境中执行,此时就可以通过注入的方式直接获取IOC容器中bean
- @ContextConfiguration(“classpath:spring-jdbctemplate.xml”)
- //设置Spring测试环境的配置文件
实例
测试增删改功能
@Test
public void testInsert(){
String sql="insert into t_user values(null,?,?,?,?,?)";
jdbcTemplate.update(sql,"root", "123", 23, "女", "123@qq.com");
}
查询一条数据为实体类对象
@Test
public void testSelectUserById(){
String sql="select * from t_user where id =?";
User user=jdbcTemplate.queryForObject(sql,new BeanPropertyRowMapper<>(User.class),1);
System.out.println(user);
}
查询多条数据为一个list集合
@Test
public void testSelectList(){
String sql = "select * from t_user";
List<User> list = jdbcTemplate.query(sql, new BeanPropertyRowMapper<>(User.class));
list.forEach(emp -> System.out.println(emp));
}
查询单行单列的值
@Test
public void selectCount(){
String sql = "select count(id) from t_user";
Integer count = jdbcTemplate.queryForObject(sql, Integer.class);
System.out.println(count);
}
声明式事务概念
先看看对应的编程式事务
Connection conn = ...;
try {
// 开启事务:关闭事务的自动提交
conn.setAutoCommit(false);
// 核心操作
// 提交事务
conn.commit();
}catch(Exception e){
// 回滚事务
conn.rollBack();
}finally{
//关闭资源
}
- 我们还需要实现在一个事务中使用的数据库连接
声明式事务
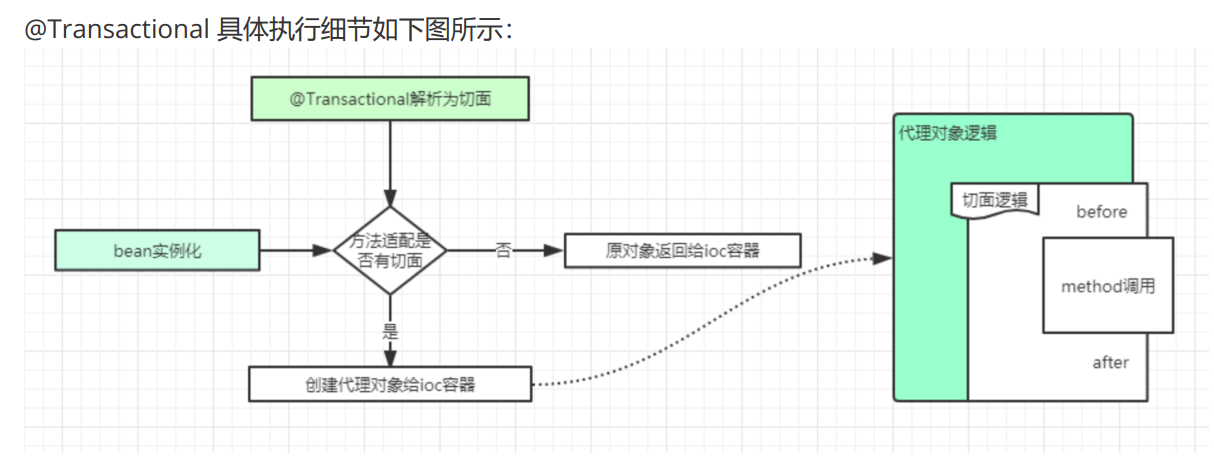
既然事务控制的代码有规律可循,代码的结构基本是确定的,所以框架就可以将固定模式的代码抽取出来,进行相关的封装。封装起来后,我们只需要在配置文件中进行简单的配置即可完成操作。
- 其背后的原理就是AOP思想,利用面对对象的思想是无法进行封装的
好处
- 好处1:提高开发效率
- 好处2:消除了冗余的代码
- 好处3:框架会综合考虑相关领域中在实际开发环境下有可能遇到的各种问题,进行了健壮性、性能等各个方面的优化
所以,我们可以总结下面两个概念:
- 编程式:自己写代码实现功能
- 声明式:通过配置让框架实现功能
其背后原理就是AOP思想
通过一个案例了解声明式事务
前提准备
- 关于jar引用跟前面的jdbcTemplate一致
我们模拟实际场景,买书的场景
- 我们这里使用的数据库框架是spring提供的jdbctemplate
数据表的创建
CREATE TABLE `t_book` (
`book_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`book_name` varchar(20) DEFAULT NULL COMMENT '图书名称',
`price` int(11) DEFAULT NULL COMMENT '价格',
`stock` int(10) unsigned DEFAULT NULL COMMENT '库存(无符号)',
PRIMARY KEY (`book_id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
insert into `t_book`(`book_id`,`book_name`,`price`,`stock`) values (1,'斗破苍穹',80,100),(2,'斗罗大陆',50,100);
CREATE TABLE `t_user` (
`user_id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`username` varchar(20) DEFAULT NULL COMMENT '用户名',
`balance` int(10) unsigned DEFAULT NULL COMMENT '余额(无符号)',
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
insert into `t_user`(`user_id`,`username`,`balance`) values (1,'admin',50);
三层架构的构建
Controller层
@Controller
public class BookController {
@Autowired
private BookService bookService;
public void buyBook(Integer bookId, Integer userId){
bookService.buyBook(bookId, userId);
}
}
Service层
public interface BookService {
void buyBook(Integer bookId, Integer userId);
}
@Service
public class BookServiceImpl implements BookService {
@Autowired
private BookDAO bookDao;
@Override
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
}
}
DAO层
public interface BookDAO {
Integer getPriceByBookId(Integer bookId);
void updateStock(Integer bookId);
void updateBalance(Integer userId, Integer price);
}
@Repository
public class BookDAOImpl implements BookDAO {
@Autowired
private JdbcTemplate jdbcTemplate;
@Override
public Integer getPriceByBookId(Integer bookId) {
String sql = "select price from t_book where book_id = ?";
return jdbcTemplate.queryForObject(sql, Integer.class, bookId);
}
@Override
public void updateStock(Integer bookId) {
String sql = "update t_book set stock = stock - 1 where book_id = ?";
jdbcTemplate.update(sql, bookId);
}
@Override
public void updateBalance(Integer userId, Integer price) {
String sql = "update t_user set balance = balance - ? where user_id = ?";
jdbcTemplate.update(sql, price, userId);
}
}
模拟场景的情况
用户购买图书,先查询图书的价格,再更新图书的库存和用户的余额
假设用户id为1的用户,购买id为1的图书
用户余额为50,而图书价格为80
- 购买图书之后,用户的余额为-30,数据库中余额字段设置了无符号,因此无法将-30插入到余额字段此时执行sql语句会抛出SQLException
无事务的情况
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:spring-jdbctemplate.xml")
public class test1 {
@Autowired
private BookService bookController;
@Test
public void testBuyBook(){
bookController.buyBook(1, 1);
}
}
//输出爆出了异常
- 因为没有添加事务,图书的库存更新了(书本库存减1了),但是用户的余额没有更新
- 显然这样的结果是错误的,购买图书是一个完整的功能,更新库存和更新余额要么都成功要么都失败
添加事务
添加事务配置
在Spring的配置文件中添加配置:
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="druidDataSource"></property>
</bean>
<!--
开启事务的注解驱动
通过注解@Transactional所标识的方法或标识的类中所有的方法,都会被事务管理器管理事务
-->
<!-- transaction-manager属性的默认值是transactionManager,如果事务管理器bean的id正好就
是这个默认值,则可以省略这个属性 -->
<tx:annotation-driven transaction-manager="transactionManager" />
在我们的service层添加注解标签
@Service
@Transactional
public class BookServiceImpl implements BookService {
@Autowired
private BookDAO bookDao;
@Override
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
}
}
- 因为service层表示业务逻辑层,一个方法表示一个完成的功能,因此处理事务一般在service层处理
观察结果
- 由于使用了Spring的声明式事务,更新库存和更新余额都没有执行
Spring声明式事务的属性
事务注解标识的位置
- @Transactional标识在方法上,只会影响该方法
- @Transactional标识的类上,咋会影响类中所有的方法
事务属性:只读
对一个查询操作来说,如果我们把它设置成只读,就能够明确告诉数据库,这个操作不涉及写操作。这样数据库就能够针对查询操作来进行优化
使用方式
@Transactional(readOnly = true)
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
//System.out.println(1/0);
}
注意 对增删改操作设置只读会抛出下面异常:
- Caused by: java.sql.SQLException: Connection is read-only. Queries leading to data modificationare not allowed
事务属性:超时
事务在执行过程中,有可能因为遇到某些问题,导致程序卡住,从而长时间占用数据库资源。而长时间占用资源,大概率是因为程序运行出现了问题(可能是Java程序或MySQL数据库或网络连接等等)。此时这个很可能出问题的程序应该被回滚,撤销它已做的操作,事务结束,把资源让出来,让其他正常程序可以执行
@Transactional(timeout = 3)
public void buyBook(Integer bookId, Integer userId) {
try {
TimeUnit.SECONDS.sleep(5);//就是让当前执行这个方法的线程休眠5秒
} catch (InterruptedException e) {
e.printStackTrace();
}
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
//System.out.println(1/0);
}
- timeout = 3设置 超过3秒就会进行回滚
执行过程中抛出异常
org.springframework.transaction.TransactionTimedOutException: Transaction timed out:
deadline was Fri Jun 04 16:25:39 CST 2022
事务属性:回滚策略
声明式事务默认只针对运行时异常回滚,编译时异常不回滚。
可以通过@Transactional中相关属性设置回滚策略
- rollbackFor属性:需要设置一个Class类型的对象 因为什么而回滚
- rollbackForClassName属性:需要设置一个字符串类型的全类名 因为什么而回滚
- noRollbackFor属性:需要设置一个Class类型的对象 发生什么不会发生回滚
- rollbackFor属性:需要设置一个字符串类型的全类名 发生什么不会发生回滚
@Transactional(noRollbackFor = ArithmeticException.class)
//@Transactional(noRollbackForClassName = "java.lang.ArithmeticException")
public void buyBook(Integer bookId, Integer userId) {
//查询图书的价格
Integer price = bookDao.getPriceByBookId(bookId);
//更新图书的库存
bookDao.updateStock(bookId);
//更新用户的余额
bookDao.updateBalance(userId, price);
System.out.println(1/0);
}
观察结果
虽然购买图书功能中出现了数学运算异常(ArithmeticException),但是我们设置的回滚策略是,当出现ArithmeticException不发生回滚,因此购买图书的操作正常执行
事务属性:事务隔离级别
数据库系统必须具有隔离并发运行各个事务的能力,使它们不会相互影响,避免各种并发问题。一个事务与其他事务隔离的程度称为隔离级别。SQL标准中规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性越弱。
隔离级别一共有四种
-
读未提交:处在隔离级别的事务可以看到其他事务还没有提交对数据库的修改——RU
- 如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,
但允许其他事务读此行数据,该隔离级别可以通过“排他写锁”,但是不排斥读线程实现。这样就避免了更新丢失,却可能出现脏读,也就是说事务B读取到了事务A未提交的数据
- 如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,
-
读已提交,处在该隔离级别的事务可以看到其他事务已经提交对数据库的修改——RC,Oracle数据库的默认的隔离级别
- 如果是一个读事务(线程),则允许其他事务读写,如果是写事务将会禁止其他事务访问该行数据,该隔离级别避免了脏读,但是可能出现不可重复读。事务A事先读取了数据,事务B紧接着更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
-
可重复读,InnoDB引擎默认的隔离级别,一个事务一旦开启,在该隔离级别下,该事务提交之前,多次查询看到的结果是一样的,无论别的事务怎么修改数据库,在当前事务下都是不可见的
- 可重复读取是指在一个事务内,多次读同一个数据,在这个事务还没结束时,其他事务不能访问该数据(包括了读写),这样就可以在同一个事务内两次读到的数据是一样的,因此称为是可重复读隔离级别
- 读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务(包括了读写),这样避免了不可重复读和脏读,但是有时可能会出现幻读。(读取数据的事务)可以通过“共享读锁”和“排他写锁”实现。
-
串行化:事务的最高隔离级别,所有事务都串行访问数据库,不会发生冲突,不会产生任何事务的问题,就没有并发执行了,串行化其实就是在底层给我们的读操作加上写锁就可以实现了读写阻塞,和写写阻塞
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | 有 | 有 | 有 |
| READ COMMITTED | 无 | 有 | 有 |
| REPEATABLE READ | 无 | 无 | 有 |
| SERIALIZABLE | 无 | 无 | 无 |
@Transactional(isolation = Isolation.DEFAULT)//使用数据库默认的隔离级别
@Transactional(isolation = Isolation.READ_UNCOMMITTED)//读未提交
@Transactional(isolation = Isolation.READ_COMMITTED)//读已提交
@Transactional(isolation = Isolation.REPEATABLE_READ)//可重复读
@Transactional(isolation = Isolation.SERIALIZABLE)//串行化
事务引起的问题
- 脏读,事务A在修改数据,事务B读取了事务A修改后的数据,但是事务A进行了回滚,前面修改的数据不算了,那么事务B读到的数据就是脏数据,这种情况就称脏读
- 不可重复读,同一个事务在多次相同操作查询到数据不同(本事务中读取的信息是最新的),(在不同的查询时,其他事务提交的修改对本事务是可见的),比如select name from stu,我查询学生表所有学生的姓名,如果这时候有别的事务修改了几个学生的姓名,那么再select name from stu,得到的数据跟上次查询就不一样了
- 幻读:解决了不重复读
就是每次查询得到的值是相同的,保证了同一个事务里,查询的结果都是事务开始时的状态(一致性)。但是,如果另一个事务同时提交了新数据,本事务再更新时,就会“惊奇的”发现了这些新数据,貌似之前读到的数据是“鬼影”一样的幻觉。- 我们插入一个主键id,在别的事务中插入了信息,我们在本事务中是查询不到的,但是我们在本事务就是插入不进去这个主键
借鉴并改造了一个搞笑的比喻:
- 脏读。假如,中午去食堂打饭吃,看到一个座位被同学小Q占上了,就认为这个座位被占去了,就转身去找其他的座位。不料,这个同学小Q起身走了。事实:该同学小Q只是临时坐了一小下,并未“提交”。
- 不重复读。假如,中午去食堂打饭吃,看到一个座位是空的,便屁颠屁颠的去打饭,回来后却发现这个座位却被同学小Q占去了。
- 幻读。假如,中午去食堂打饭吃,看到一个座位是空的,便屁颠屁颠的去打饭,回来后,发现这些座位都还是空的(重复读),窃喜。走到跟前刚准备坐下时,却惊现一个恐龙妹,严重影响食欲。仿佛之前看到的空座位是“幻影”一样。
幻读和不可重复读的区别
- 不可重复读的重点是修改;同样的条件,第1次和第2次读取的值不一样。幻读的重点在于新增或者删除;同样的条件, 第1次和第2次读出来的记录数不一样。从控制角度来看,不可重复读只需要锁住满足条件的记录,幻读要锁住满足条件及其相近的记录。
不可重复读的重点是修改:
同样的条件, 你读取过的数据, 再次读取出来发现值不一样了
幻读的重点在于新增或者删除
同样的条件, 第1次和第2次读出来的记录数不一样
当然, 从总的结果来看, 似乎两者都表现为两次读取的结果不一致.
但如果你从控制的角度来看, 两者的区别就比较大
- 对于前者, 只需要锁住满足条件的记录
- 对于后者, 要锁住满足条件及其相近的记录
为什么要设置事务的隔离级别?
设置事务的隔离级别是用来保障多个并发事务执行更可控,更符合操作者预期的。
什么是可控呢?
比如近几年比较严重的新冠病毒,我们会把直接接触到确证病例的人员隔离到酒店,而把间接接触者(和直接接触着但未确诊的人)隔离在自己的家中,也就是针对不同的人群,采取不同的隔离级别,这种隔离方式就和事务的隔离级别类似,都是采取某种行动让某个事件变的“更可控”。而事务的隔离级别
就是为了防止,其他的事务影响当前事务执行的一种策略。
事务属性:事务传播行为
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行
- Spring 事务传播机制定义了多个包含了事务的方法,相互调用时,事务是如何在这些方法间进行传递的。
测试
创建接口CheckoutService:
public interface CheckoutService {
void checkout(Integer[] bookIds, Integer userId);
}
创建实现类CheckoutServiceImpl:
@Service
public class CheckoutServiceImpl implements CheckoutService {
@Autowired
private BookService bookService;
@Override
@Transactional
//一次购买多本图书
public void checkout(Integer[] bookIds, Integer userId) {
for (Integer bookId : bookIds) {
bookService.buyBook(bookId, userId);
}
}
}
- bookService.buyBook(bookId, userId),我们的bookService有对应的事务
- checkout 也有自己对应的事务
在BookController中添加方法:
@Autowired
private CheckoutService checkoutService;
public void checkout(Integer[] bookIds, Integer userId){
checkoutService.checkout(bookIds, userId);
}
在数据库中将用户的余额修改为100元
观察结果
- 可以通过@Transactional中的propagation属性设置事务传播行为
- 修改BookServiceImpl中buyBook()上,注解@Transactional的propagation属性
@Transactional(propagation = Propagation.REQUIRED),默认情况,表示如果当前线程上有已经开启的事务可用,那么就在这个事务中运行。经过观察,购买图书的方法buyBook()在checkout()中被调用,checkout()上有事务注解,因此在此事务中执行。所购买的两本图书的价格为80和50,而用户的余
额为100,因此在购买第二本图书时余额不足失败,导致整个checkout()回滚,即只要有一本书买不了,就都买不了
@Transactional(propagation = Propagation.REQUIRES_NEW),表示不管当前线程上是否有已经开启的事务,都要开启新事务。同样的场景,每次购买图书都是在buyBook()的事务中执行,因此第一本图书购买成功,事务结束,第二本图书购买失败,只在第二次的buyBook()中回滚,购买第一本图书不受
影响,即能买几本就买几本
Spring的几种事务传播机制
- Propagation.REQUIRED:默认的事务传播级别,它表示如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- Propagation.SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- Propagation.MANDATORY:(mandatory:强制性)如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- Propagation.REQUIRES_NEW:表示创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,
- Propagation.REQUIRES_NEW 修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
- Propagation.NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- Propagation.NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
- Propagation.NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 PROPAGATION_REQUIRED。
为什么需要事务传播机制?
事务隔离级别是保证多个并发事务执行的可控性的(稳定性的),而事务传播机制是保证一个事务在多个调用方法间的可控性的(稳定性的)。
例子:像新冠病毒一样,它有不同的隔离方式(酒店隔离还是居家隔离),是为了保证疫情可控,然而在每个人的隔离过程中,会有很多个执行的环节,比如酒店隔离,需要负责人员运送、物品运送、消杀原生活区域、定时核算检查和定时送餐等很多环节,而事务传播机制就是保证一个事务在
传递过程中是可靠性的,回到本身案例中就是保证每个人在隔离的过程中可控的。