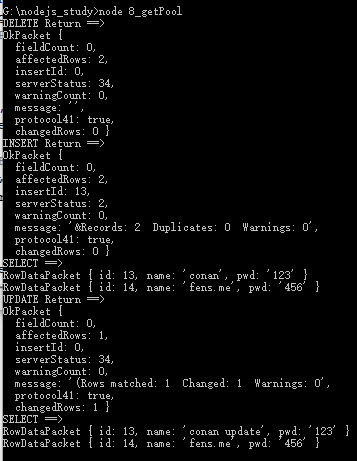
目标检测算法,主要分为两类:
- 一类是以R-CNN为代表的两阶段检测算法,将目标检测任务分为边界框回归和物体分类两个模块
- 二是yolo系列算法,是将目标检测任务看作是回归任务。
原理

yolov1将图像划分为S*S的网格,如果检测物体落到网格中心,那么就由这个网络来预测该物体。
每个网格预测B个边界框和那些边界框的置信度。置信度反映了该边界框是否包含目标且包含目标的准确度。置信度的定义:
![]()
左边表示概率,右边表示IOU。如果该网格中不存在检测物体,那么置信度为0.如果存在检测物体,那么置信度为预测框和真实框的IOU。
每个边界框有五个数字组成,分别为:x,y,w,h,置信度。(x,y)是边界框中心坐标相较于网格的坐标。h,w,是预测框相较于整个图像的高和宽。也就是说这里的x,y,w,h都是真实值,而是相对值,分别相较于网格和整个图像。最后置信度表示预测框和真实框的IOU.
每个网络还负责预测C个类条件概率。定义为:
![]()
这里只是预测每个网络含有每类物体的概率,不是每个预测框。
在测试的时候 ,将类条件概率和单个框的置信度相乘,就得到了每个边界框关于某个类别的置信度。该置信度表示了该类目标出现在该边界框的概率和该预测框和真实边界框的拟合程度。
![]()
比如说yolov1在PASCAL VOC数据集,S=7,B=2(即每个网络预测两个边界框)。PASCAL VOC有20个类别,所以C=20.所以最后的输出张量是7*7*30的形状。
网络设计
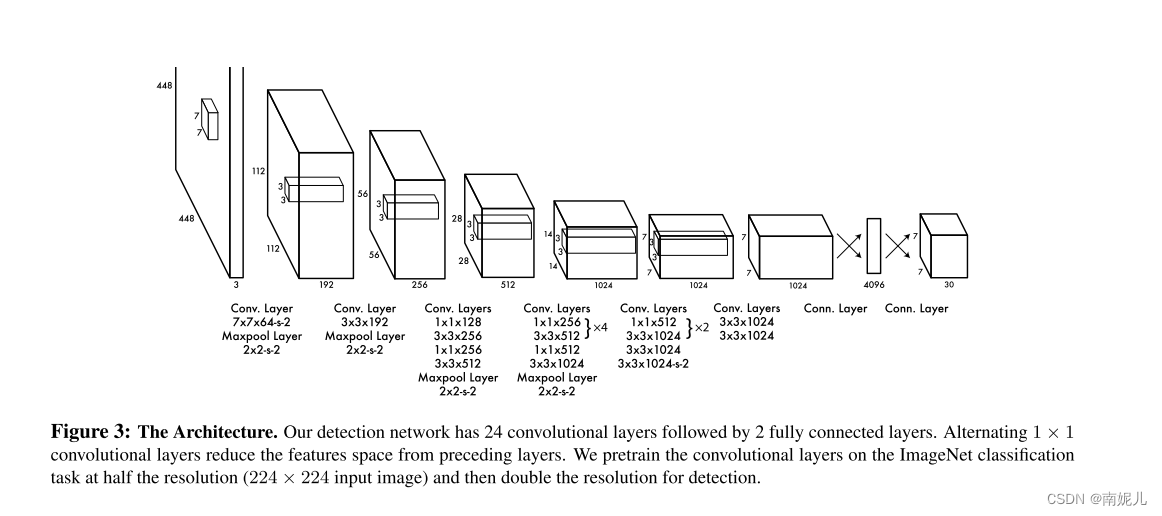
网络有24个卷积层和2个全连接层。受GoogleNet启发,在3*3卷积之后接1*1卷积。
训练
在Imagenet上预训练所有的卷积层。
在最后一层预测类别和边界框坐标。
用图像的宽和高来归一化边界框的宽度和高度,是坐标落在0和1之间。
将边界框x和y坐标参数化为特定网格的偏移量,因此也被限制在0-1之间。

像素坐标转yolo
def coordinates2yolo(xmin,ymin,xmax,ymax,img_w,img_h):
"""
输入左上角、右下角坐标和图像宽、高 :xmin, ymin, xmax, ymax, img_w, img_h
输出归一化后yolo坐标格式 :中心点坐标,宽、高:x, y, w1, h1
"""
# 保留6位小数
x = round((xmin+xmax)/(2.0*img_w),6)
y = round((ymin+ymax)/(2.0*img_h),6)
w1 = round((xmax-xmin)/(1.0*img_w),6)
h1 = round((ymax-ymin)/(1.0*img_h),6)
print( x,y,w1,h1)
return x,y,w1,h1yolo坐标转像素坐标
"""
输入yolo坐标和图像宽、高 :中心点坐标,宽、高:x, y, w1, h1, img_w, img_h
输出左上角、右下角坐标:xmin, ymin, xmax, ymax
"""
def yolo2coordinates(x,y,w1,h1,img_w,img_h):
xmin = round(img_w*(x-w1/2.0))
xmax = round(img_w*(x+w1/2.0))
ymin = round(img_h*(y-h1/2.0))
ymax = round(img_h*(y+h1/2.0))
print(xmin,ymin, xmax, ymax)
return xmin, ymin, xmax,ymaxYOLO 边框预测中的坐标系转换详解_ANTennaaa的博客-CSDN博客_yolo坐标
在最后一层使用线性激活函数,其他所有层使用leark relu

损失函数使用平方损失。使用平方误差是因为比较好优化,但是这并不符合最大化map的目的。这将定位误差和分类误差同等对待,这并不是最好的。而且,在每个图像中,许多网格可能并不包含任何对象。对与那些网格不包含检测物体的网格,置信度等于0。这导致模型训练不稳定。为了解决这一问题,增加了边界框坐标损失,减少了不包含物体的框的置信度的损失。我们使用两个参数λcoord和λnoobj来实现这一点。我们设λcoord = 5,λnoobj = .5。
平方和误差也同样对待大边界框和小边界框中的误差。误差度量应该反映出大边界框中的小偏差比小盒子中的小偏差影响更小。为了解决这个问题,我们预测边界框宽度和高度的平方根,而不是直接预测宽度和高度。
YOLOv1,每个网格预测多个边界框。在训练的时候,希望每一个边界框只负责预测一个检测物体。这里边界框的选取是基于IOU来进行选择的,判断预测的边界框和真实的边界框是最大的。
损失函数:

如果物体存在网格中,则损失函数仅惩罚分类错误。如果边界框对于真实边界框是可靠的,那么损失函数仅惩罚坐标误差。
- 损失函数的第一部分计算预测边界框和真实边界框中心点之间的误差
- 计算预测边界框和真实边界框宽高损失
- 第三部分和第四部分表示预测边界框的置信度和预测
- 最后一部分计算类概率损失
为了避免过拟合,使用了dropout和数据增强。
推理
在PASCAL VOC上,每个图像预测98个边界框和每个边界框的类概率。
通常情况下,一个物体只落在一个网格(grid cell)中,而且每个物体只有一个边界框(bounding boxes)。
对于一些大物体,或靠近多个网格的物体可以被多个物体很好的定位检测。
这时NMS(非极大抑制)可以用于修正这些多重检测。
yolov1的局限性:
- yolov1对边界框的预测施加了很强的空间约束,因为每个网格只能预测两个框并且只能包含一个物体类别。这限制了预测的数量,比如成群的鸟都无法预测。
- 模型是从数据集中,学习边界框,所以很难检测不同长宽比的对象。
- 损失函数同等对待小边界框的误差和大边界框的误差。大边界框的偏移是相对来说微小的,但是小边界框的偏移是巨大的。
代码
准备数据
这里使用pascal voc2012数据集进行训练。
数据集的详细介绍:PASCAL VOC2012数据集介绍_太阳花的小绿豆的博客-CSDN博客_voc2012数据集
"""
数据准备,将数据处理为两个文件,一个是train.csv,另一个是train.txt。同理也会有test.csv, test.txt
train.csv: 每一行是一张图片的标签,具体储存情况根据不同任务的需求自行设定
train.txt: 每一行是图片的路径,该文件每行的图片和train.csv的每一行标注应该是一一对应的
另外,根据需要将图片稍微离线处理一下,比如将原图片裁剪出训练使用的图片(resize成训练要求大小)后,保存在自定义文件夹中,train.txt里的路径应与自定义文件夹相同
"""
import xml.etree.ElementTree as ET
import numpy as np
import cv2
import random
import os
GL_CLASSES = ['person', 'bird', 'cat', 'cow', 'dog', 'horse', 'sheep',
'aeroplane', 'bicycle', 'boat', 'bus', 'car', 'motorbike', 'train',
'bottle', 'chair', 'diningtable', 'pottedplant', 'sofa', 'tvmonitor']
GL_NUMBBOX = 2
GL_NUMGRID = 7
STATIC_DATASET_PATH = r'./VOCdevkit/VOC2012/'
STATIC_DEBUG = False # 调试用
def convert(size, box):
"""将bbox的左上角点、右下角点坐标的格式,转换为bbox中心点+bbox的w,h的格式
并进行归一化"""
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
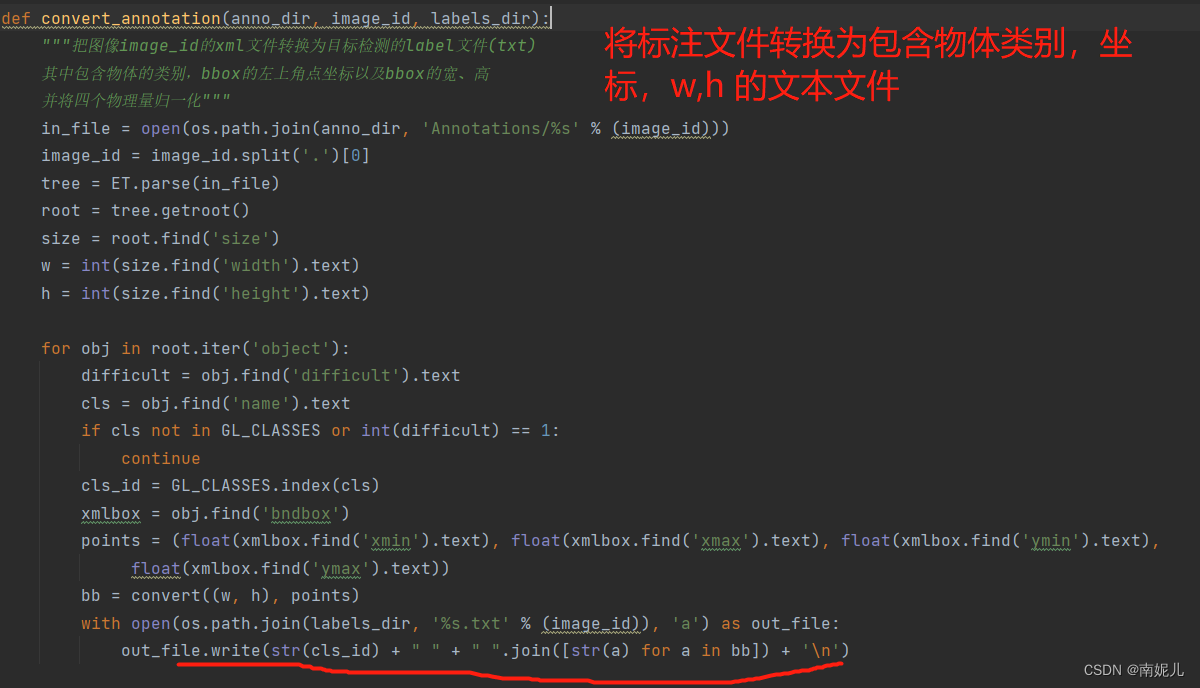
def convert_annotation(anno_dir, image_id, labels_dir):
"""把图像image_id的xml文件转换为目标检测的label文件(txt)
其中包含物体的类别,bbox的左上角点坐标以及bbox的宽、高
并将四个物理量归一化"""
in_file = open(os.path.join(anno_dir, 'Annotations/%s' % (image_id)))
image_id = image_id.split('.')[0]
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in GL_CLASSES or int(difficult) == 1:
continue
cls_id = GL_CLASSES.index(cls)
xmlbox = obj.find('bndbox')
points = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), points)
with open(os.path.join(labels_dir, '%s.txt' % (image_id)), 'a') as out_file:
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
def make_label_txt(anno_dir, labels_dir):
"""在labels文件夹下创建image_id.txt,对应每个image_id.xml提取出的bbox信息"""
filenames = os.listdir(os.path.join(anno_dir,'Annotations'))[:13]
for file in filenames:
convert_annotation(anno_dir, file, labels_dir)
def img_augument(img_dir, save_img_dir, labels_dir):
imgs_list = [x.split('.')[0]+".jpg" for x in os.listdir(labels_dir)]
for img_name in imgs_list:
print("process %s"%os.path.join(img_dir, img_name))
img = cv2.imread(os.path.join(img_dir, img_name))
h, w = img.shape[0:2]
input_size = 448 # 输入YOLOv1网络的图像尺寸为448x448
# 因为数据集内原始图像的尺寸是不定的,所以需要进行适当的padding,将原始图像padding成宽高一致的正方形
# 然后再将Padding后的正方形图像缩放成448x448
padw, padh = 0, 0 # 要记录宽高方向的padding具体数值,因为padding之后需要调整bbox的位置信息
if h > w:
padw = (h - w) // 2
img = np.pad(img, ((0, 0), (padw, padw), (0, 0)), 'constant', constant_values=0)
elif w > h:
padh = (w - h) // 2
img = np.pad(img, ((padh, padh), (0, 0), (0, 0)), 'constant', constant_values=0)
img = cv2.resize(img, (input_size, input_size))
cv2.imwrite(os.path.join(save_img_dir, img_name), img)
# 读取图像对应的bbox信息,按1维的方式储存,每5个元素表示一个bbox的(cls,xc,yc,w,h)
with open(os.path.join(labels_dir,img_name.split('.')[0] + ".txt"), 'r') as f:
bbox = f.read().split('\n')
bbox = [x.split() for x in bbox]
bbox = [float(x) for y in bbox for x in y]
if len(bbox) % 5 != 0:
raise ValueError("File:"
+ os.path.join(labels_dir,img_name.split('.')[0] + ".txt") + "——bbox Extraction Error!")
# 根据padding、图像增广等操作,将原始的bbox数据转换为修改后图像的bbox数据
if padw != 0:
for i in range(len(bbox) // 5):
bbox[i * 5 + 1] = (bbox[i * 5 + 1] * w + padw) / h
bbox[i * 5 + 3] = (bbox[i * 5 + 3] * w) / h
if STATIC_DEBUG:
cv2.rectangle(img, (int(bbox[1] * input_size - bbox[3] * input_size / 2),
int(bbox[2] * input_size - bbox[4] * input_size / 2)),
(int(bbox[1] * input_size + bbox[3] * input_size / 2),
int(bbox[2] * input_size + bbox[4] * input_size / 2)), (0, 0, 255))
elif padh != 0:
for i in range(len(bbox) // 5):
bbox[i * 5 + 2] = (bbox[i * 5 + 2] * h + padh) / w
bbox[i * 5 + 4] = (bbox[i * 5 + 4] * h) / w
if STATIC_DEBUG:
cv2.rectangle(img, (int(bbox[1] * input_size - bbox[3] * input_size / 2),
int(bbox[2] * input_size - bbox[4] * input_size / 2)),
(int(bbox[1] * input_size + bbox[3] * input_size / 2),
int(bbox[2] * input_size + bbox[4] * input_size / 2)), (0, 0, 255))
# 此处可以写代码验证一下,查看padding后修改的bbox数值是否正确,在原图中画出bbox检验
if STATIC_DEBUG:
cv2.imshow("bbox-%d"%int(bbox[0]), img)
cv2.waitKey(0)
with open(os.path.join(labels_dir, img_name.split('.')[0] + ".txt"), 'w') as f:
for i in range(len(bbox) // 5):
bbox = [str(x) for x in bbox[i*5:(i*5+5)]]
str_context = " ".join(bbox)+'\n'
f.write(str_context)
def convert_bbox2labels(bbox):
"""将bbox的(cls,x,y,w,h)数据转换为训练时方便计算Loss的数据形式(7,7,5*B+cls_num)
注意,输入的bbox的信息是(xc,yc,w,h)格式的,转换为labels后,bbox的信息转换为了(px,py,w,h)格式"""
gridsize = 1.0/GL_NUMGRID
labels = np.zeros((7,7,5*GL_NUMBBOX+len(GL_CLASSES))) # 注意,此处需要根据不同数据集的类别个数进行修改
for i in range(len(bbox)//5):
gridx = int(bbox[i*5+1] // gridsize) # 当前bbox中心落在第gridx个网格,列
gridy = int(bbox[i*5+2] // gridsize) # 当前bbox中心落在第gridy个网格,行
# (bbox中心坐标 - 网格左上角点的坐标)/网格大小 ==> bbox中心点的相对位置
gridpx = bbox[i * 5 + 1] / gridsize - gridx
gridpy = bbox[i * 5 + 2] / gridsize - gridy
# 将第gridy行,gridx列的网格设置为负责当前ground truth的预测,置信度和对应类别概率均置为1
labels[gridy, gridx, 0:5] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])
labels[gridy, gridx, 5:10] = np.array([gridpx, gridpy, bbox[i * 5 + 3], bbox[i * 5 + 4], 1])
labels[gridy, gridx, 10+int(bbox[i*5])] = 1
labels = labels.reshape(1, -1)
return labels
def create_csv_txt(img_dir, anno_dir, save_root_dir, train_val_ratio=0.9, padding=10, debug=False):
"""
TODO:
将img_dir文件夹内的图片按实际需要处理后,存入save_dir
最终得到图片文件夹及所有图片对应的标注(train.csv/test.csv)和图片列表文件(train.txt, test.txt)
"""
labels_dir = os.path.join(anno_dir, "labels")
if not os.path.exists(labels_dir):
os.mkdir(labels_dir)
make_label_txt(anno_dir, labels_dir)
print("labels done.")
save_img_dir = os.path.join(os.path.join(anno_dir, "voc2012_forYolov1"), "img")
if not os.path.exists(save_img_dir):
os.mkdir(save_img_dir)
img_augument(img_dir, save_img_dir, labels_dir)
imgs_list = os.listdir(save_img_dir)
n_trainval = len(imgs_list)
shuffle_id = list(range(n_trainval))
random.shuffle(shuffle_id)
n_train = int(n_trainval*train_val_ratio)
train_id = shuffle_id[:n_train]
test_id = shuffle_id[n_train:]
traintxt = open(os.path.join(save_root_dir, "train.txt"), 'w')
traincsv = np.zeros((n_train, GL_NUMGRID*GL_NUMGRID*(5*GL_NUMBBOX+len(GL_CLASSES))),dtype=np.float32)
for i,id in enumerate(train_id):
img_name = imgs_list[id]
img_path = os.path.join(save_img_dir, img_name)+'\n'
traintxt.write(img_path)
with open(os.path.join(labels_dir,"%s.txt"%img_name.split('.')[0]), 'r') as f:
bbox = [float(x) for x in f.read().split()]
traincsv[i,:] = convert_bbox2labels(bbox)
np.savetxt(os.path.join(save_root_dir, "train.csv"), traincsv)
print("Create %d train data." % (n_train))
testtxt = open(os.path.join(save_root_dir, "test.txt"), 'w')
testcsv = np.zeros((n_trainval - n_train, GL_NUMGRID*GL_NUMGRID*(5*GL_NUMBBOX+len(GL_CLASSES))),dtype=np.float32)
for i,id in enumerate(test_id):
img_name = imgs_list[id]
img_path = os.path.join(save_img_dir, img_name)+'\n'
testtxt.write(img_path)
with open(os.path.join(labels_dir,"%s.txt"%img_name.split('.')[0]), 'r') as f:
bbox = [float(x) for x in f.read().split()]
testcsv[i,:] = convert_bbox2labels(bbox)
np.savetxt(os.path.join(save_root_dir, "test.csv"), testcsv)
print("Create %d test data." % (n_trainval-n_train))
if __name__ == '__main__':
random.seed(0)
np.set_printoptions(threshold=np.inf)
img_dir = os.path.join(STATIC_DATASET_PATH, "JPEGImages") # 原始图像文件夹
anno_dirs = [STATIC_DATASET_PATH] # 标注文件
save_dir = os.path.join(STATIC_DATASET_PATH, "voc2012_forYolov1") # 保存处理后的数据(图片+标签)的文件夹
if not os.path.exists(save_dir):
os.mkdir(save_dir)
# 分别处理
for anno_dir in anno_dirs:
create_csv_txt(img_dir, anno_dir, save_dir, debug=False)




dataset
from torch.utils.data import Dataset, DataLoader
import numpy as np
import os
import random
import torch
from PIL import Image
import torchvision.transforms as transforms
class MyDataset(Dataset):
def __init__(self, dataset_dir, seed=None, mode="train", train_val_ratio=0.9, trans=None):
"""
:param dataset_dir: 数据所在文件夹
:param seed: 打乱数据所用的随机数种子
:param mode: 数据模式,"train", "val", "test"
:param train_val_ratio: 训练时,训练集:验证集的比例
:param trans: 数据预处理函数
TODO:
1. 读取储存图片路径的.txt文件,并保存在self.img_list中
2. 读取储存样本标签的.csv文件,并保存在self.label中
3. 如果mode="train", 将数据集拆分为训练集和验证集,用self.use_ids来保存对应数据集的样本序号。
注意,mode="train"和"val"时,必须传入随机数种子,且两者必须相同
4. 保存传入的数据增广函数
"""
if seed is None:
seed = random.randint(0, 65536)
random.seed(seed)
self.dataset_dir = dataset_dir
self.mode = mode
if mode=="val":
mode = "train"
img_list_txt = os.path.join(dataset_dir, mode+".txt").replace('\\','/') # 储存图片位置的列表
label_csv = os.path.join(dataset_dir, mode+".csv").replace('\\','/') # 储存标签的数组文件
self.img_list = []
self.label = np.loadtxt(label_csv) # 读取标签数组文件
# 读取图片位置文件
with open(img_list_txt, 'r') as f:
for line in f.readlines():
self.img_list.append(line.strip())
# 在mode=train或val时, 将数据进行切分
# 注意在mode="val"时,传入的随机种子seed要和mode="train"相同
self.num_all_data = len(self.img_list)
all_ids = list(range(self.num_all_data))
num_train = int(train_val_ratio*self.num_all_data)
if self.mode == "train":
self.use_ids = all_ids[:num_train]
elif self.mode == "val":
self.use_ids = all_ids[num_train:]
else:
self.use_ids = all_ids
# 储存数据增广函数
self.trans = trans
def __len__(self):
"""获取数据集数量"""
return len(self.use_ids)
def __getitem__(self, item):
"""
TODO:
1. 按顺序依次取出第item个训练数据img及其对应的样本标签label
2. 图像数据要进行预处理,并最终转换为(c, h, w)的维度,同时转换为torch.tensor
3. 样本标签要按需要转换为指定格式的torch.tensor
"""
id = self.use_ids[item]
label = torch.tensor(self.label[id, :])
img_path = self.img_list[id]
img = Image.open(img_path)
if self.trans is None:
trans = transforms.Compose([
# transforms.Resize((112,112)),
transforms.ToTensor(),
])
else:
trans = self.trans
img = trans(img) # 图像预处理&数据增广
# transforms.ToPILImage()(img).show() # for debug
# print(label)
return img, label
if __name__ == '__main__':
# 调试用,依次取出数据看看是否正确
dataset_dir = "./VOCdevkit/VOC2012/voc2012_forYolov1"
dataset = MyDataset(dataset_dir)
image,label=dataset[1]
print(image.shape)
print(label.shape)
# dataloader = DataLoader(dataset, 1)
# for i in enumerate(dataloader):
# input("press enter to continue")网络结构
import torch
import torch.nn as nn
import torchvision.models as tvmodel
GL_CLASSES = ['person', 'bird', 'cat', 'cow', 'dog', 'horse', 'sheep',
'aeroplane', 'bicycle', 'boat', 'bus', 'car', 'motorbike', 'train',
'bottle', 'chair', 'diningtable', 'pottedplant', 'sofa', 'tvmonitor']
GL_NUMBBOX = 2
GL_NUMGRID = 7
def calculate_iou(bbox1, bbox2):
"""计算bbox1=(x1,y1,x2,y2)和bbox2=(x3,y3,x4,y4)两个bbox的iou"""
if bbox1[2]<=bbox1[0] or bbox1[3]<=bbox1[1] or bbox2[2]<=bbox2[0] or bbox2[3]<=bbox2[1]:
return 0 # 如果bbox1或bbox2没有面积,或者输入错误,直接返回0
intersect_bbox = [0., 0., 0., 0.] # bbox1和bbox2的重合区域的(x1,y1,x2,y2)
intersect_bbox[0] = max(bbox1[0],bbox2[0])
intersect_bbox[1] = max(bbox1[1],bbox2[1])
intersect_bbox[2] = min(bbox1[2],bbox2[2])
intersect_bbox[3] = min(bbox1[3],bbox2[3])
w = max(intersect_bbox[2] - intersect_bbox[0], 0)
h = max(intersect_bbox[3] - intersect_bbox[1], 0)
area1 = (bbox1[2] - bbox1[0]) * (bbox1[3] - bbox1[1]) # bbox1面积
area2 = (bbox2[2] - bbox2[0]) * (bbox2[3] - bbox2[1]) # bbox2面积
area_intersect = w * h # 交集面积
iou = area_intersect / (area1 + area2 - area_intersect + 1e-6) # 防止除0
# print(bbox1,bbox2)
# print(intersect_bbox)
# input()
return iou
class MyNet(nn.Module):
def __init__(self):
"""
:param args: 构建网络所需要的参数
TODO:
在__init__()函数里,将网络框架搭好,并存在self里
"""
super(MyNet, self).__init__()
resnet = tvmodel.resnet34(pretrained=True) # 调用torchvision里的resnet34预训练模型
resnet_out_channel = resnet.fc.in_features # 记录resnet全连接层之前的网络输出通道数,方便连入后续卷积网络中
self.resnet = nn.Sequential(*list(resnet.children())[:-2]) # 去除resnet的最后两层
# 以下是YOLOv1的最后四个卷积层
self.Conv_layers = nn.Sequential(
nn.Conv2d(resnet_out_channel, 1024, 3, padding=1),
nn.BatchNorm2d(1024), # 为了加快训练,这里增加了BN层,原论文里YOLOv1是没有的
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, stride=2, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1024, 3, padding=1),
nn.BatchNorm2d(1024),
nn.LeakyReLU(inplace=True),
)
# 以下是YOLOv1的最后2个全连接层
self.Conn_layers = nn.Sequential(
nn.Linear(GL_NUMGRID * GL_NUMGRID * 1024, 4096),
nn.LeakyReLU(inplace=True),
nn.Linear(4096, GL_NUMGRID * GL_NUMGRID * (5*GL_NUMBBOX+len(GL_CLASSES))),
nn.Sigmoid() # 增加sigmoid函数是为了将输出全部映射到(0,1)之间,因为如果出现负数或太大的数,后续计算loss会很麻烦
)
def forward(self, inputs):
x = self.resnet(inputs)
x = self.Conv_layers(x)
x = x.view(x.size()[0], -1)
x = self.Conn_layers(x)
self.pred = x.reshape(-1, (5 * GL_NUMBBOX + len(GL_CLASSES)), GL_NUMGRID, GL_NUMGRID) # 记住最后要reshape一下输出数据
return self.pred
def calculate_loss(self, labels):
"""
TODO: 根据labels和self.outputs计算训练loss
:param labels: (bs, n), 对应训练数据的样本标签
:return: loss数值
"""
self.pred = self.pred.double()
labels = labels.double()
num_gridx, num_gridy = GL_NUMGRID, GL_NUMGRID # 划分网格数量
noobj_confi_loss = 0. # 不含目标的网格损失(只有置信度损失)
coor_loss = 0. # 含有目标的bbox的坐标损失
obj_confi_loss = 0. # 含有目标的bbox的置信度损失
class_loss = 0. # 含有目标的网格的类别损失
n_batch = labels.size()[0] # batchsize的大小
# 可以考虑用矩阵运算进行优化,提高速度,为了准确起见,这里还是用循环
for i in range(n_batch): # batchsize循环
for n in range(num_gridx): # x方向网格循环
for m in range(num_gridy): # y方向网格循环
if labels[i, 4, m, n] == 1: # 如果包含物体
# 将数据(px,py,w,h)转换为(x1,y1,x2,y2)
# 先将px,py转换为cx,cy,即相对网格的位置转换为标准化后实际的bbox中心位置cx,xy
# 然后再利用(cx-w/2,cy-h/2,cx+w/2,cy+h/2)转换为xyxy形式,用于计算iou
bbox1_pred_xyxy = ((self.pred[i, 0, m, n] + n) / num_gridx - self.pred[i, 2, m, n] / 2,
(self.pred[i, 1, m, n] + m) / num_gridy - self.pred[i, 3, m, n] / 2,
(self.pred[i, 0, m, n] + n) / num_gridx + self.pred[i, 2, m, n] / 2,
(self.pred[i, 1, m, n] + m) / num_gridy + self.pred[i, 3, m, n] / 2)
bbox2_pred_xyxy = ((self.pred[i, 5, m, n] + n) / num_gridx - self.pred[i, 7, m, n] / 2,
(self.pred[i, 6, m, n] + m) / num_gridy - self.pred[i, 8, m, n] / 2,
(self.pred[i, 5, m, n] + n) / num_gridx + self.pred[i, 7, m, n] / 2,
(self.pred[i, 6, m, n] + m) / num_gridy + self.pred[i, 8, m, n] / 2)
bbox_gt_xyxy = ((labels[i, 0, m, n] + n) / num_gridx - labels[i, 2, m, n] / 2,
(labels[i, 1, m, n] + m) / num_gridy - labels[i, 3, m, n] / 2,
(labels[i, 0, m, n] + n) / num_gridx + labels[i, 2, m, n] / 2,
(labels[i, 1, m, n] + m) / num_gridy + labels[i, 3, m, n] / 2)
iou1 = calculate_iou(bbox1_pred_xyxy, bbox_gt_xyxy)
iou2 = calculate_iou(bbox2_pred_xyxy, bbox_gt_xyxy)
# 选择iou大的bbox作为负责物体
if iou1 >= iou2:
coor_loss = coor_loss + 5 * (torch.sum((self.pred[i, 0:2, m, n] - labels[i, 0:2, m, n]) ** 2) \
+ torch.sum((self.pred[i, 2:4, m, n].sqrt() - labels[i, 2:4, m, n].sqrt()) ** 2))
obj_confi_loss = obj_confi_loss + (self.pred[i, 4, m, n] - iou1) ** 2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou2
noobj_confi_loss = noobj_confi_loss + 0.5 * ((self.pred[i, 9, m, n] - iou2) ** 2)
else:
coor_loss = coor_loss + 5 * (torch.sum((self.pred[i, 5:7, m, n] - labels[i, 5:7, m, n]) ** 2) \
+ torch.sum((self.pred[i, 7:9, m, n].sqrt() - labels[i, 7:9, m, n].sqrt()) ** 2))
obj_confi_loss = obj_confi_loss + (self.pred[i, 9, m, n] - iou2) ** 2
# iou比较小的bbox不负责预测物体,因此confidence loss算在noobj中,注意,对于标签的置信度应该是iou1
noobj_confi_loss = noobj_confi_loss + 0.5 * ((self.pred[i, 4, m, n] - iou1) ** 2)
class_loss = class_loss + torch.sum((self.pred[i, 10:, m, n] - labels[i, 10:, m, n]) ** 2)
else: # 如果不包含物体
# hh=self.pred[i,[4,9],m,n]**2 ## 4 和 9 说明只有置信度损失参与计算,边界框损失和类别损失不参与计算
noobj_confi_loss = noobj_confi_loss + 0.5 * torch.sum(self.pred[i, [4, 9], m, n] ** 2)
loss = coor_loss + obj_confi_loss + noobj_confi_loss + class_loss
return loss / n_batch
def calculate_metric(self, preds, labels):
"""
TODO: 根据preds和labels,以及指定的评价方法计算网络效果得分, 网络validation时使用
:param preds: 预测数据
:param labels: 预测数据对应的样本标签
:return: 评估得分metric
"""
preds = preds.double()
labels = labels[:, :(self.n_points*2)]
l2_distance = torch.mean(torch.sum((preds-labels)**2, dim=1))
return l2_distance
if __name__ == '__main__':
# 自定义输入张量,验证网络可以正常跑通,并计算loss,调试用
x = torch.zeros(5,3,448,448)
net = MyNet()
a = net(x)
# labels = torch.zeros(5, 30, 7, 7)
labels=torch.ones(5,30,7,7)
loss = net.calculate_loss(labels)
print(loss)
print('a shape',a.shape)



训练
import os
import datetime
import time
import torch
from torch.utils.data import DataLoader
from model import MyNet
from data import MyDataset
from my_arguments import Args
from prepare_data import GL_CLASSES, GL_NUMBBOX, GL_NUMGRID
from util import labels2bbox
class TrainInterface(object):
"""
网络训练接口,
__train(): 训练过程函数
__validate(): 验证过程函数
__save_model(): 保存模型函数
main(): 训练网络主函数
"""
def __init__(self, opts):
"""
:param opts: 命令行参数
"""
self.opts = opts
print("=======================Start training.=======================")
@staticmethod
def __train(model, train_loader, optimizer, epoch, num_train, opts):
"""
完成一个epoch的训练
:param model: torch.nn.Module, 需要训练的网络
:param train_loader: torch.utils.data.Dataset, 训练数据集对应的类
:param optimizer: torch.optim.Optimizer, 优化网络参数的优化器
:param epoch: int, 表明当前训练的是第几个epoch
:param num_train: int, 训练集数量
:param opts: 命令行参数
"""
model.train()
device = opts.GPU_id
avg_metric = 0. # 平均评价指标
avg_loss = 0. # 平均损失数值
# log_file是保存网络训练过程信息的文件,网络训练信息会以追加的形式打印在log.txt里,不会覆盖原有log文件
log_file = open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+")
localtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 打印训练时间
log_file.write(localtime)
log_file.write("\n======================training epoch %d======================\n"%epoch)
for i,(imgs, labels) in enumerate(train_loader):
labels = labels.view(1, GL_NUMGRID, GL_NUMGRID, 30)
labels = labels.permute(0,3,1,2)
if opts.use_GPU:
imgs = imgs.to(device)
labels = labels.to(device)
preds = model(imgs) # 前向传播
loss = model.calculate_loss(labels) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 优化网络参数
# metric = model.calculate_metric(preds, labels) # 计算评价指标
# avg_metric = (avg_metric*i+metric)/(i+1)
avg_loss = (avg_loss*i+loss.item())/(i+1)
if i % opts.print_freq == 0: # 根据打印频率输出log信息和训练信息
print("Epoch %d/%d | Iter %d/%d | training loss = %.3f, avg_loss = %.3f" %
(epoch, opts.epoch, i, num_train//opts.batch_size, loss.item(), avg_loss))
log_file.write("Epoch %d/%d | Iter %d/%d | training loss = %.3f, avg_loss = %.3f\n" %
(epoch, opts.epoch, i, num_train//opts.batch_size, loss.item(), avg_loss))
log_file.flush()
log_file.close()
@staticmethod
def __validate(model, val_loader, epoch, num_val, opts):
"""
完成一个epoch训练后的验证任务
:param model: torch.nn.Module, 需要训练的网络
:param _loader: torch.utils.data.Dataset, 验证数据集对应的类
:param epoch: int, 表明当前训练的是第几个epoch
:param num_val: int, 验证集数量
:param opts: 命令行参数
"""
model.eval()
log_file = open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+")
log_file.write("======================validate epoch %d======================\n"%epoch)
preds = None
gts = None
avg_metric = 0.
with torch.no_grad(): # 加上这个可以减少在validation过程时的显存占用,提高代码的显存利用率
for i,(imgs, labels) in enumerate(val_loader):
if opts.use_GPU:
imgs = imgs.to(opts.GPU_id)
pred = model(imgs).cpu().squeeze(dim=0).permute(1,2,0)
pred_bbox = labels2bbox(pred) # 将网络输出经过NMS后转换为shape为(-1, 6)的bbox
metric = model.calculate_metric(preds, gts)
print("Evaluation of validation result: average L2 distance = %.5f"%(metric))
log_file.write("Evaluation of validation result: average L2 distance = %.5f\n"%(metric))
log_file.flush()
log_file.close()
return metric
@staticmethod
def __save_model(model, epoch, opts):
"""
保存第epoch个网络的参数
:param model: torch.nn.Module, 需要训练的网络
:param epoch: int, 表明当前训练的是第几个epoch
:param opts: 命令行参数
"""
model_name = "epoch%d.pth" % epoch
save_dir = os.path.join(opts.checkpoints_dir, model_name)
torch.save(model, save_dir)
def main(self):
"""
训练接口主函数,完成整个训练流程
1. 创建训练集和验证集的DataLoader类
2. 初始化带训练的网络
3. 选择合适的优化器
4. 训练并验证指定个epoch,保存其中评价指标最好的模型,并打印训练过程信息
5. TODO: 可视化训练过程信息
"""
opts = self.opts
if not os.path.exists(opts.checkpoints_dir):
os.mkdir(opts.checkpoints_dir)
random_seed = opts.random_seed
train_dataset = MyDataset(opts.dataset_dir, seed=random_seed, mode="train", train_val_ratio=0.9)
val_dataset = MyDataset(opts.dataset_dir, seed=random_seed, mode="val", train_val_ratio=0.9)
train_loader = DataLoader(train_dataset, opts.batch_size, shuffle=True, num_workers=opts.num_workers)
val_loader = DataLoader(val_dataset, batch_size=1, shuffle=False, num_workers=opts.num_workers)
num_train = len(train_dataset)
num_val = len(val_dataset)
if opts.pretrain is None:
model = MyNet()
else:
model = torch.load(opts.pretrain)
if opts.use_GPU:
model.to(opts.GPU_id)
optimizer = torch.optim.SGD(model.parameters(), lr=opts.lr, momentum=0.9, weight_decay=opts.weight_decay)
# optimizer = torch.optim.Adam(model.parameters(), lr=opts.lr, weight_decay=opts.weight_decay)
best_metric=1000000
for e in range(opts.start_epoch, opts.epoch+1):
t = time.time()
self.__train(model, train_loader, optimizer, e, num_train, opts)
t2 = time.time()
print("Training consumes %.2f second\n" % (t2-t))
with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:
log_file.write("Training consumes %.2f second\n" % (t2-t))
if e % opts.save_freq==0 or e == opts.epoch+1:
# t = time.time()
# metric = self.__validate(model, val_loader, e, num_val, opts)
# t2 = time.time()
# print("Validation consumes %.2f second\n" % (t2 - t))
# with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:
# log_file.write("Validation consumes %.2f second\n" % (t2 - t))
# if best_metric>metric:
# best_metric = metric
# print("Epoch %d is now the best epoch with metric %.4f\n"%(e, best_metric))
# with open(os.path.join(opts.checkpoints_dir, "log.txt"), "a+") as log_file:
# log_file.write("Epoch %d is now the best epoch with metric %.4f\n"%(e, best_metric))
self.__save_model(model, e, opts)
if __name__ == '__main__':
# 训练网络代码
args = Args()
args.set_train_args() # 获取命令行参数
train_interface = TrainInterface(args.get_opts())
train_interface.main() # 调用训练接口
参考文献:
lavendelion/YOLOv1-from-scratch: YOLOv1-from-scratch (github.com)