《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
- 14 对于流数据基于 RRCF 的异常检测
- 15 通过无监督和主动学习进行实用的白盒异常检测
- 16 基于VAE和LOF的无监督KPI异常检测算法
- 17 基于 VAE-LSTM 混合模型的时间异常检测
- 18 USAD:多元时间序列的无监督异常检测
- 19 OmniAnomaly:基于随机循环网络的多元时间序列鲁棒异常检测
- 20 HotSpot:多维特征 Additive KPI 的异常定位
- 21 Anomaly Transformer: 基于关联差异的时间序列异常检测
- 22 Kontrast: 通过自监督对比学习识别软件变更中的错误
- 23 TimesNet: 用于常规时间序列分析的时间二维变化模型
- 24 TSB-UAD:用于单变量时间序列异常检测的端到端基准套件
- 25 DIF:基于深度隔离林的异常检测算法
- 26 Time-LLM:基于大语言模型的时间序列预测
- 27 Dejavu: Actionable and Interpretable Fault Localization for Recurring Failures in Online Service Systems
- 28 UNRAVEL ANOMALIES:基于周期与趋势分解的时间序列异常检测端到端方法
- 29 EasyTSAD: 用于时间序列异常检测模型的工业级基准
相关:
- VAE 模型基本原理简单介绍
- GAN 数学原理简单介绍以及代码实践
- 单指标时间序列异常检测——基于重构概率的变分自编码(VAE)代码实现(详细解释)
29. EasyTSAD: 用于时间序列异常检测模型的工业级基准
论文名称:UNRAVEL ANOMALIES: AN END-TO-END SEASONAL-TREND DECOMPOSITION APPROACH FOR TIME SERIES ANOMALY DETECTION
会议期刊:目前还未发表,
论文地址:arxiv | 阿里云盘
源码地址:https://github.com/dawnvince/EasyTSAD
29.1 论文内容概述
这篇论文介绍了一个名为TimeSeriesBench的综合基准测试平台,用于评估单变量时间序列异常检测模型。
主要贡献:
-
在线排行榜:论文介绍了第一个时间序列异常检测算法的在线排行榜,从多个维度(如训练、推理、评估和数据集)增强了现有的评估框架。这帮助行业专家选择最佳的学术算法,并提供了工业级的评估方法。
-
最先进方法的评估:使用TimeSeriesBench评估了多种知名的最先进(SOTA)异常检测方法。结果提供了新的见解和未来优化的方向。
-
EasyTSAD工具包:开发并发布了名为EasyTSAD的全面评估工具包,该工具包使用Python构建,提供了数据处理、模型训练和评估的一站式解决方案。该工具包是开源的,旨在加速现有异常检测算法的优化。
-
精确的异常标注:为了解决现有公共数据集中异常标注不准确的问题,作者与一家全球公司合作,精细标注了在线系统中的异常。这些数据集作为TimeSeriesBench的一部分公开提供。
29.2 论文核心方法
29.2.1 banchmark 概述
工业级问题和TimeSeriesBench关于基准单变量时间序列异常检测算法的解决方案。
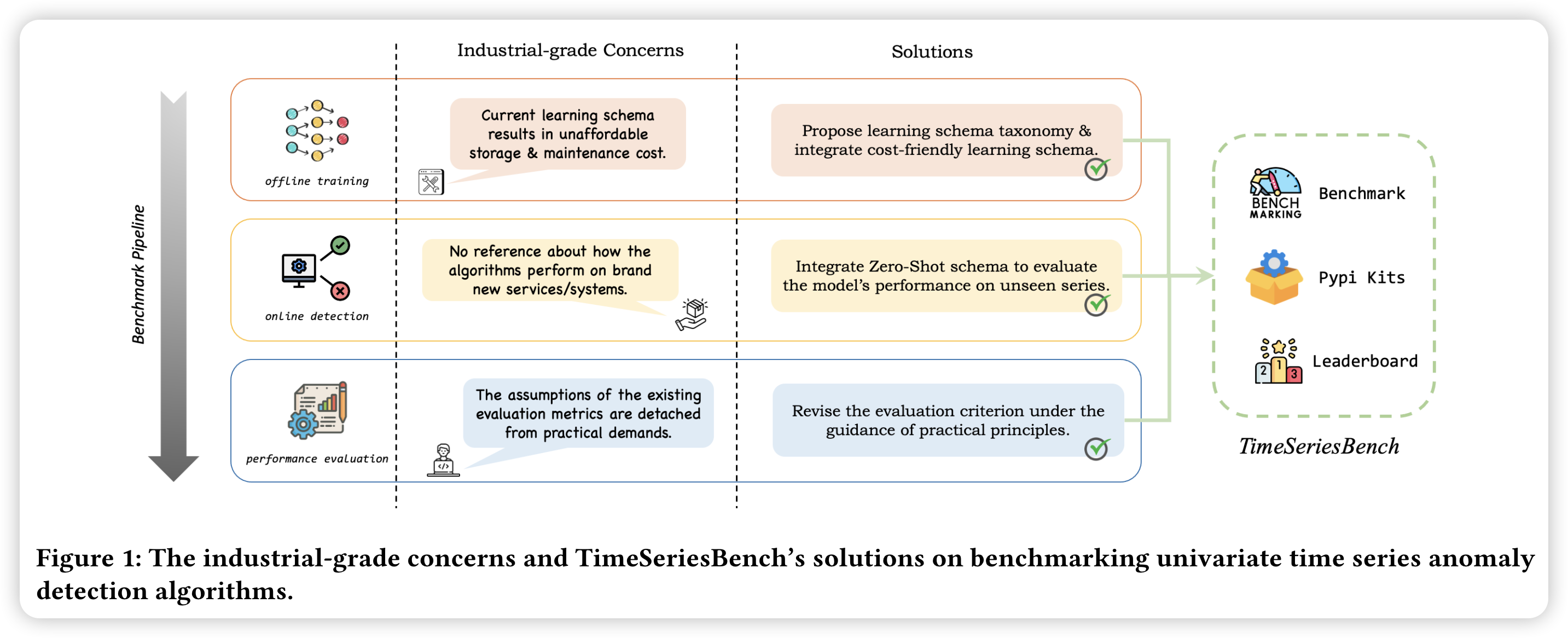
如图所示,从上往下看:
- 首先完成
offline training离线训练,这个过程中需要解决的是当前学习模式的负载问题,包括存储负载与维护的成本;而本论文提出的 benchmark 的解决方案是提 出学习模式分类法集成成本友好型学习模式。 - 其次在线检测过程,这个过程中需要解决的是原算法在全新服务/系统上的表现没有可以提及。本论文的解决方案是集成零样本模式以评估模型在不可见序列上的性能。
- 最后需要对算法的效果进行评估,需要解决的问题是现有评估指标的假设与实际需求脱节,本论文的解决方法是在实践原则指导下修订评价标准(在后面的内容中会提到基于best f1-score 以及基于事件发生的评估方法等)。
然后图片的右边进行了一个包裹操作,大概的意思就是,前面提到的所有,都可以在我这里(TimeSeriesBench)解决。
29.2.2 异常类型
前言、背景、动机我们统统跳过了,真的看麻了。
不过这里作者对异常类型的概述可以参考一下。
根据行为驱动的分类法,异常类型可以粗略地分为 点异常(Point-wise) 和 模式异常(Pattern-wise)(图2)。 点异常指的是在单个时间点或非常短的时间内出现的峰值或故障等意外事件时间段。模式异常值表示跨越特定时间范围的异常子序列,通常表现为数据中的不协调或不一致。

29.2.3 学习模式(learning schema)
这里需要注意作者概述的几个重要的概念,这些对于后面源码解析、配置参数关系密切。
朴素模型(Naive schema)。在这种模式下,我们输入一个时间序列用于训练/拟合模型,并且专门使用训练好的检测器在该特定序列上进行在线检测。直观地说,这使得模型能够根据足够的数据对时间模式做出更精确的描述。然而值得注意的是,单个序列的数据量往往不足。
一体化架构(All-in-one schema)。在这种模式下,仅使用数据集中的所有序列训练一个统一的模型实例,然后在数据集的所有序列中实时应用该模型进行异常检测。这种架构使模型能够接触各种系列中嵌入的更多模式,从而为模型提供了额外的机会来学习时间序列之间的共同且固有的特征。然而,由于不同系列对异常的定义不同,这可能会导致在线检测异常时(即特定曲线中存在的异常不一定被视为其他曲线中的异常)模型被相互矛盾的信息所混淆。一些新的方法已经采用了这种受实际需求驱动的架构。
零样本架构(Zero-shot schema)。在零样本模式下,整个数据集被分成两个不相交的子集。一个子集用于模型训练,另一个用于评估检测性能。这种架构是在实际考虑的基础上设计出来的。具体来说,它处理了这样一个情况:系统在没有历史数据的情况下新部署,并且需要一个健壮且适应性强的模型来穿越这个差距。这要求模型具有更高的能力来捕捉时间序列的内在表示。
29.2.4 评价标准
论文中提出的评估标准主要是针对实时异常检测需求。这个与我们前面提到的 Bagel,Donut,LOF-VAE 是一致的,需要考虑检测延迟等,也就是我们前面提到过的 best F1-score 的计算法和准许 delay 的方法。
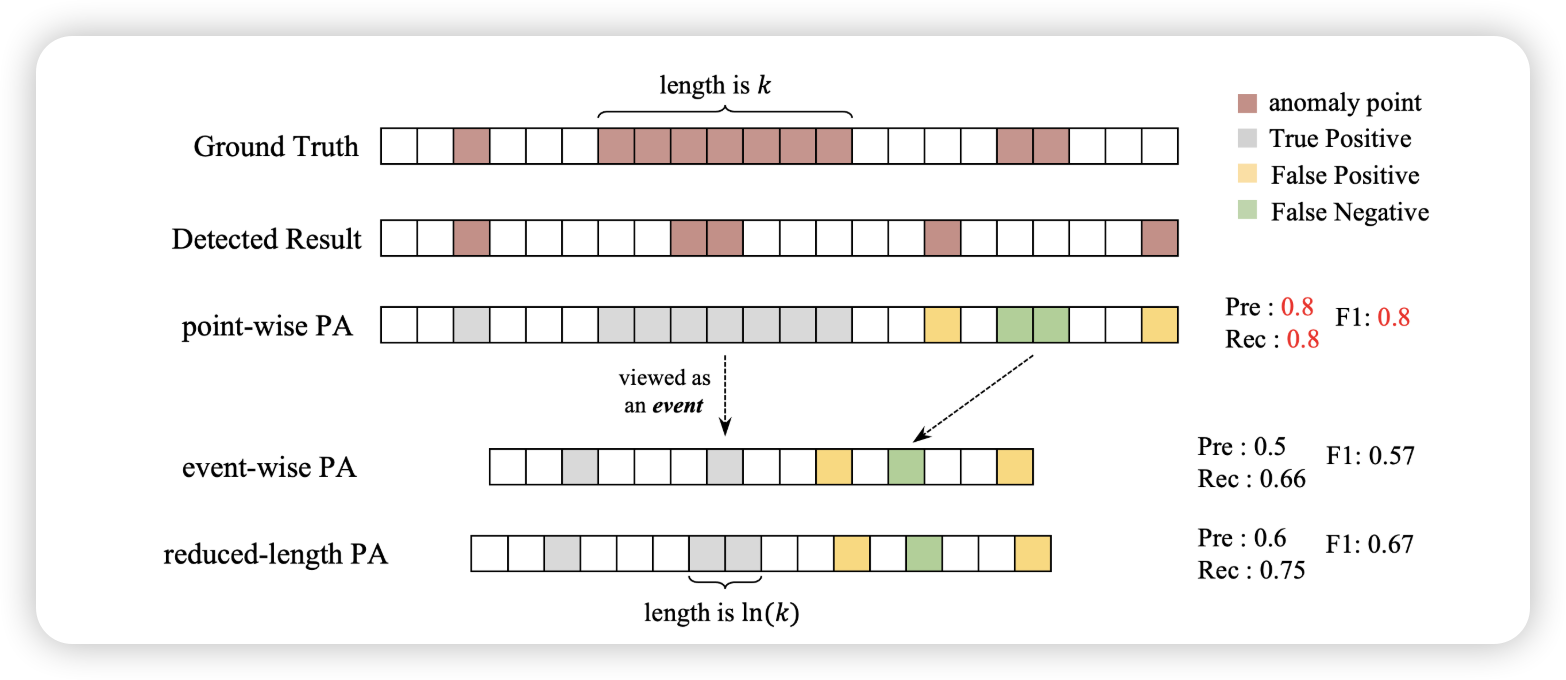
此外还有基于事件 event-wise 的评估方法,这个值得小伙伴们研究研究,如上图所示,如果一个 event 发生后,仅仅提供1个异常点,那么我们可以认为这个是突刺,但是如果出现多个连续的异常,我们可以认为这是一个事件event。在实际需求中,通常情况下我们也会更加关注 event-wise 的评估方法。我们可以认为异常发生,会带有一定长度的影响范围,而event-wise 就是指这种情况。
29.2.5 算法效果比较
这里我们主要需要知道两方面内容:
本benchmark给小伙伴们实现了很多算法;如果你们有新的算法,可以基于本benchmark直接评估。
当然,还有一层还有就是,小伙伴们引用本benchmark记得在reference中明确指出。
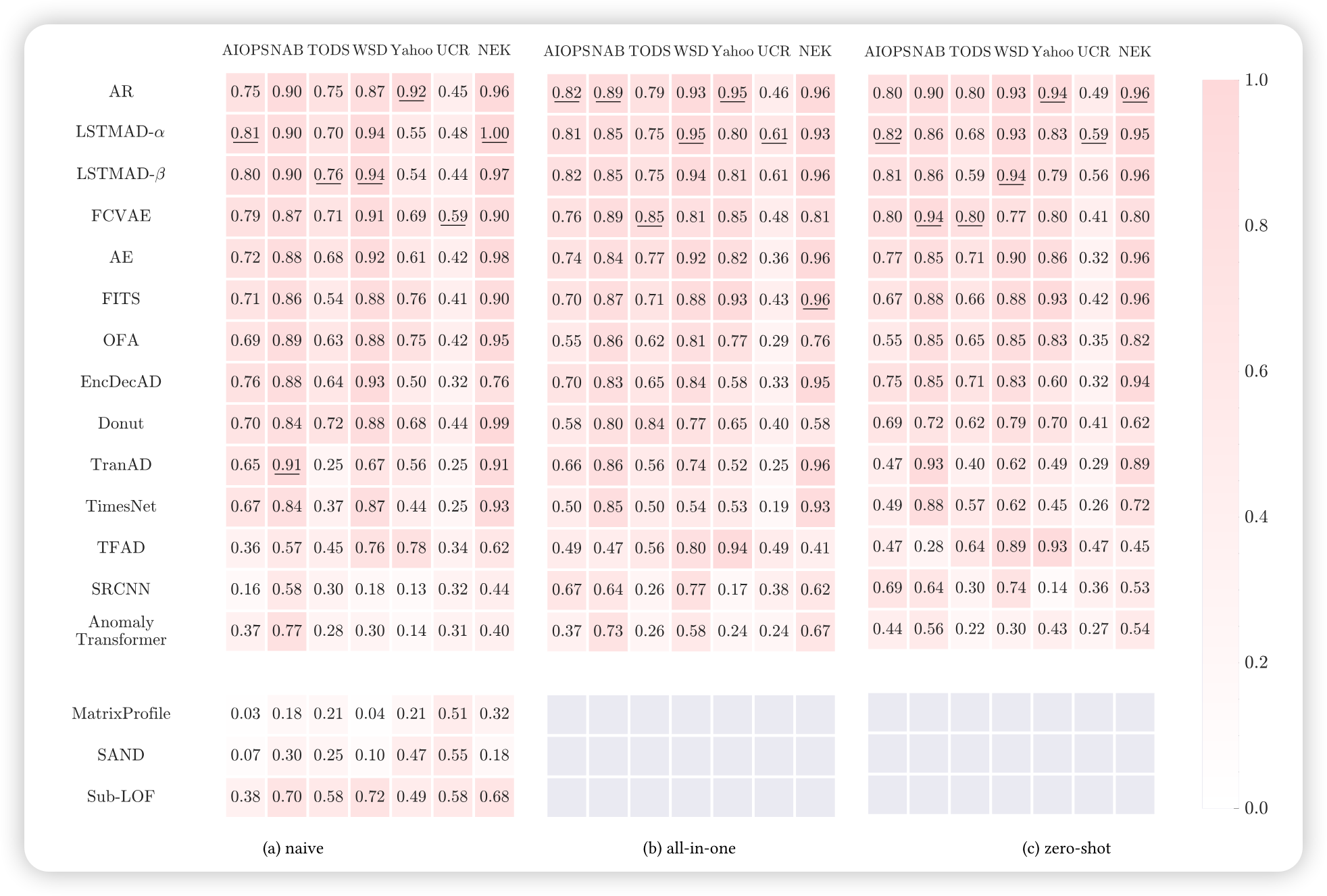
这里我们不做介绍,感兴趣的小伙伴们可以下载源码,跑一下这些实验。
当然,也可以基于这个benchmark开发自己的算法,跑完所有的实验后记得发一篇论文,然后也贴出这样的表格,表示自己的算法也很优秀。
29.3 源码阅读
前往 https://github.com/dawnvince/EasyTSAD 可以查看源码内容。这里我不关注计算细节,主要希望通过其中某一两个算法介绍整个benchmark的运行流程。
我们这里选中的是 AR 算法。
29.3.1 环境准备
首先将源码 clone 到本地,并且前往 https://github.com/CSTCloudOps/datasets 克隆数据集到我们的项目中,最后的目录文件如下:
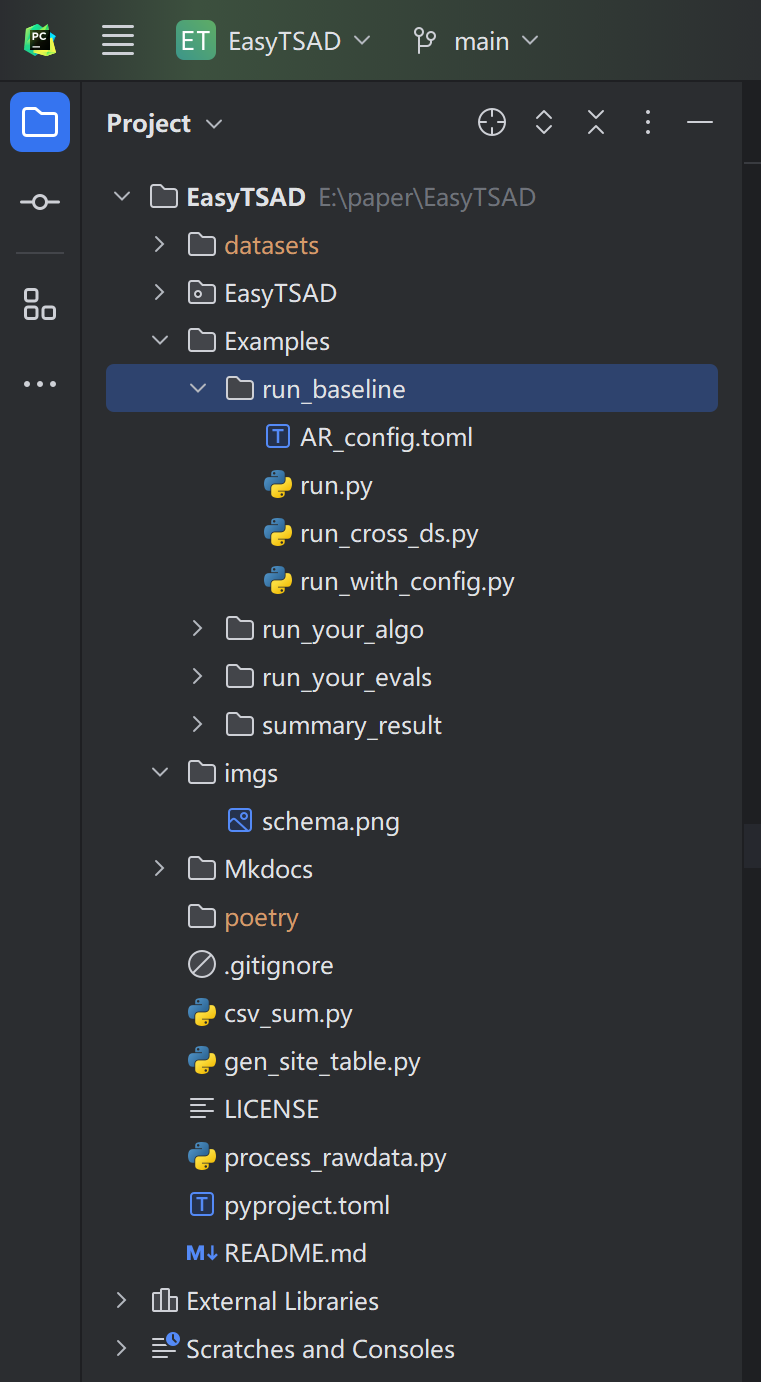
解下安装相关依赖
首先需要安装 toml ,避免出现 No module named 'toml' 这样的错误提示。
$ pip install toml
同样地,需要安装 poetry
$ pip install poetry
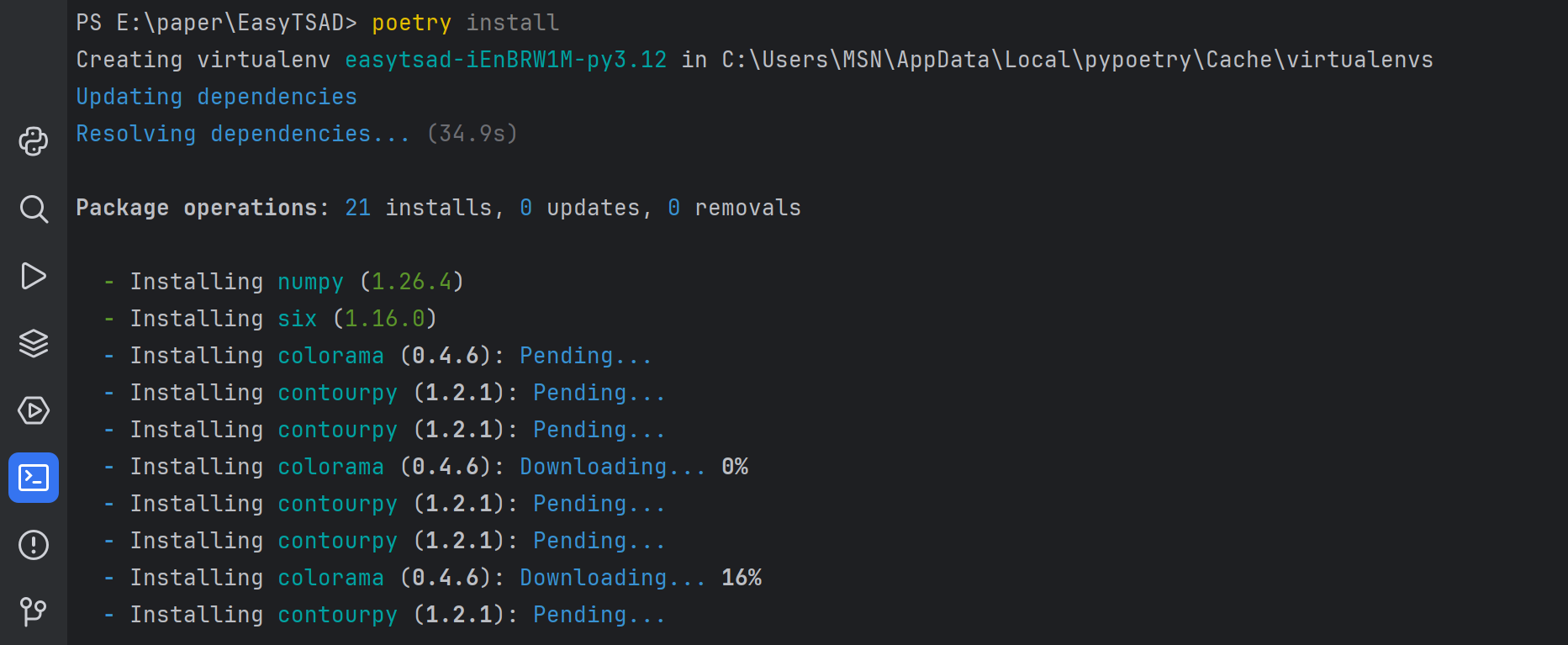
安装完成以后,我们需要使用 poetry 安装相关依赖到虚拟环境中。
$ poetry install
接着点击运行 Examples/run_baseline/run.py 还是报错如下:
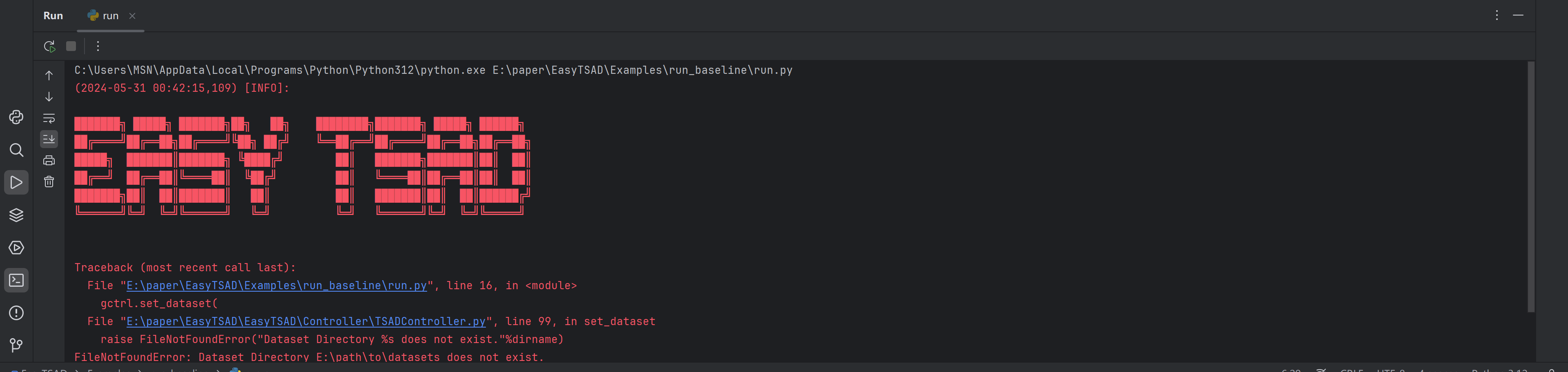
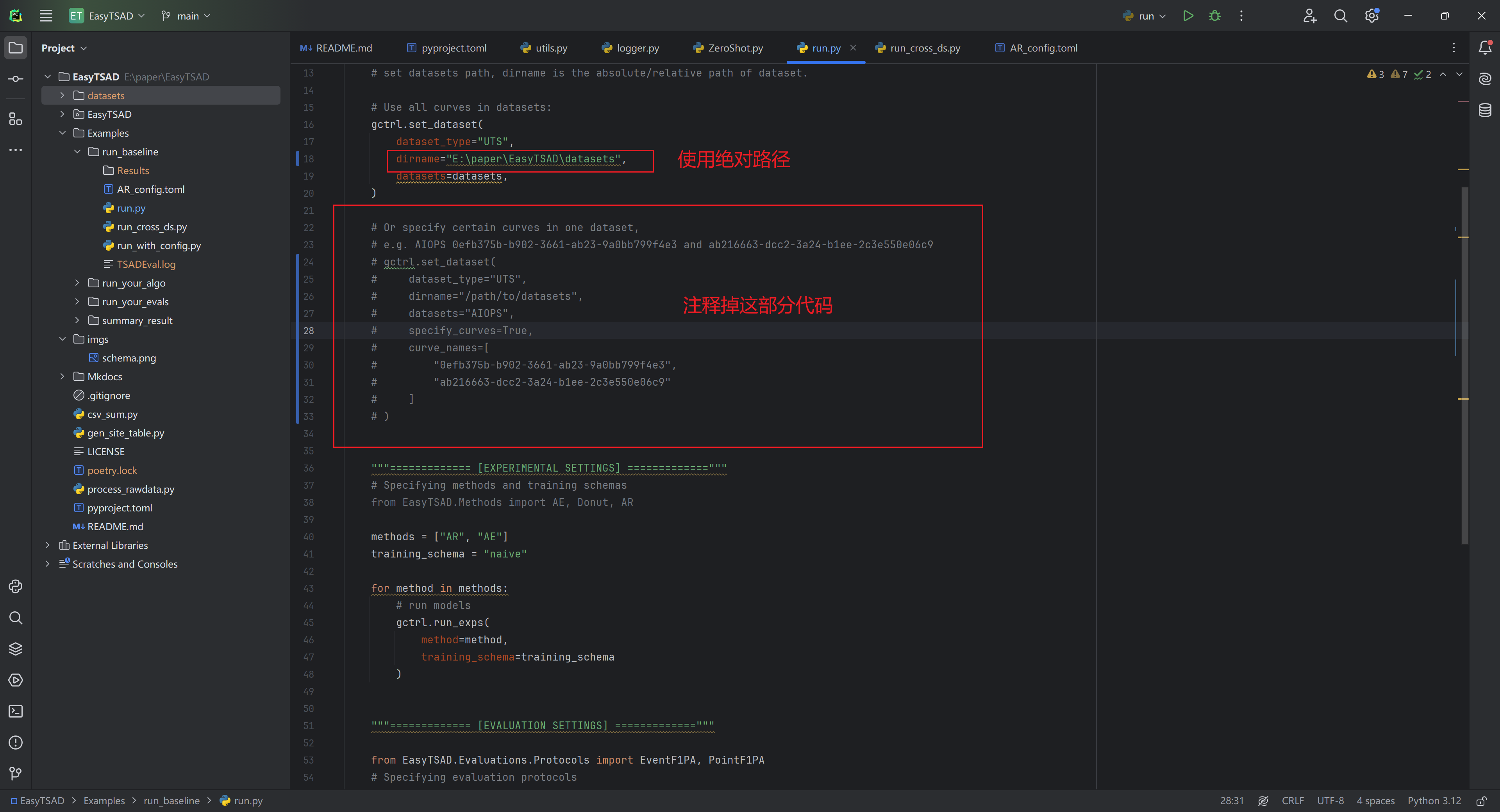
这个是因为找不到 datasets 目录导致的。需要修改如图所示的目录
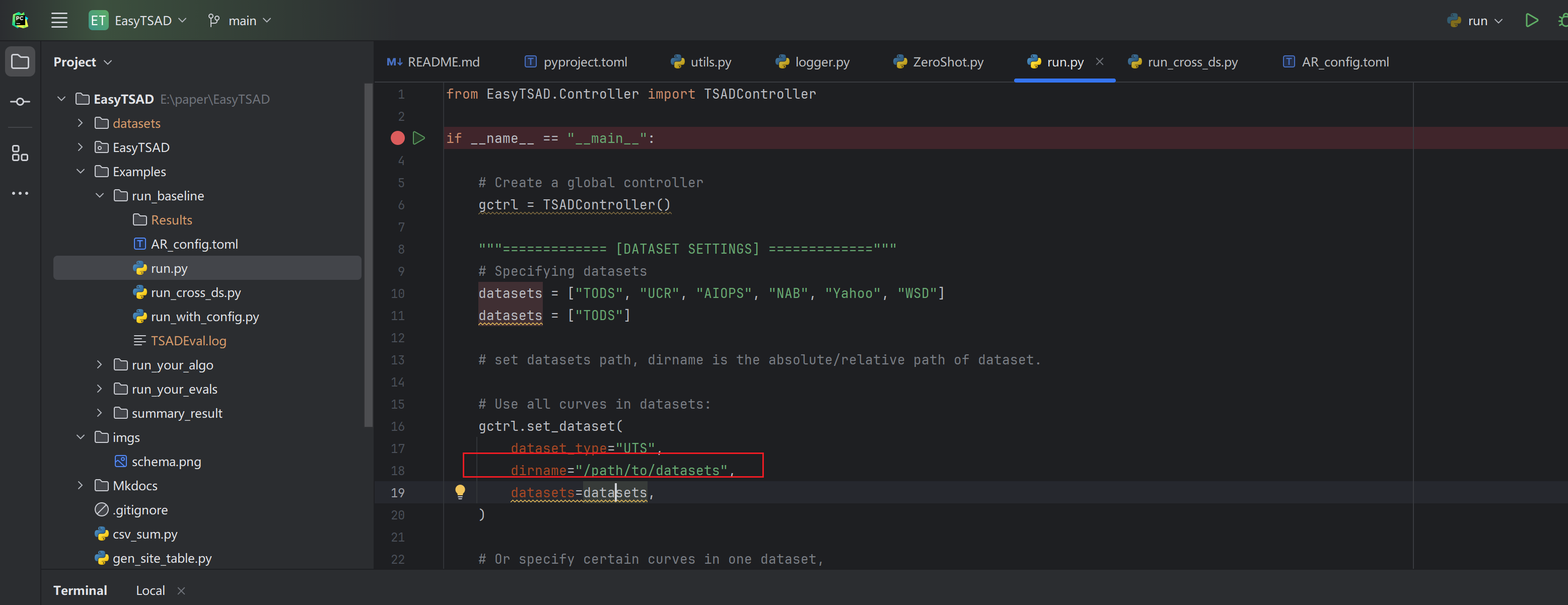
建议使用绝对路径,并注释掉后面一部分代码(用于指定特别数据集的指定KPI),如下图所示:
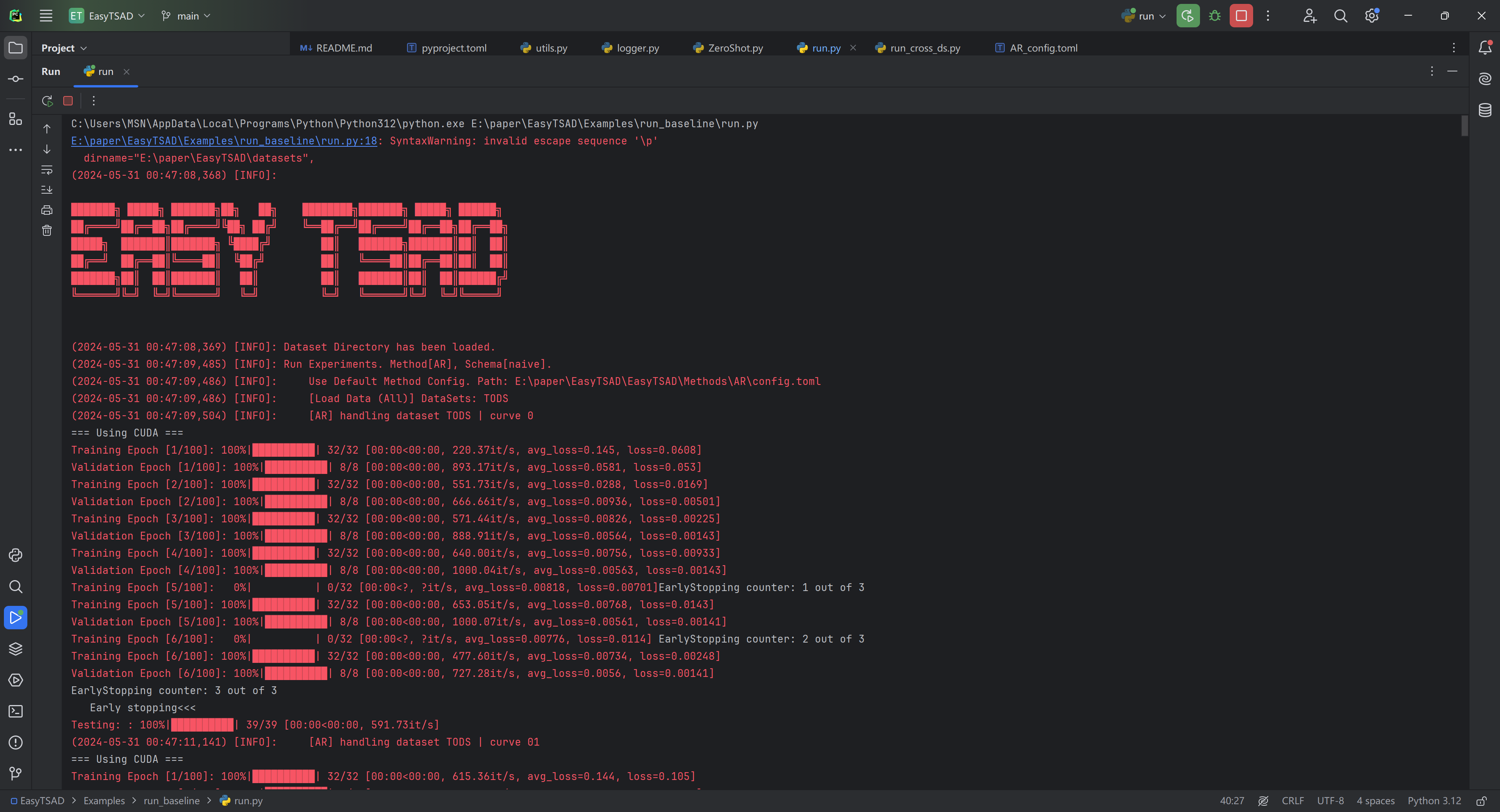
如果还提示别的缺包,使用 pip install 命令安装即可,最终执行效果大概如下:
执行的过程中,可以使用 nvidia-smi 命令查看 GPU 显存使用情况。
最后输出结果大概如下:
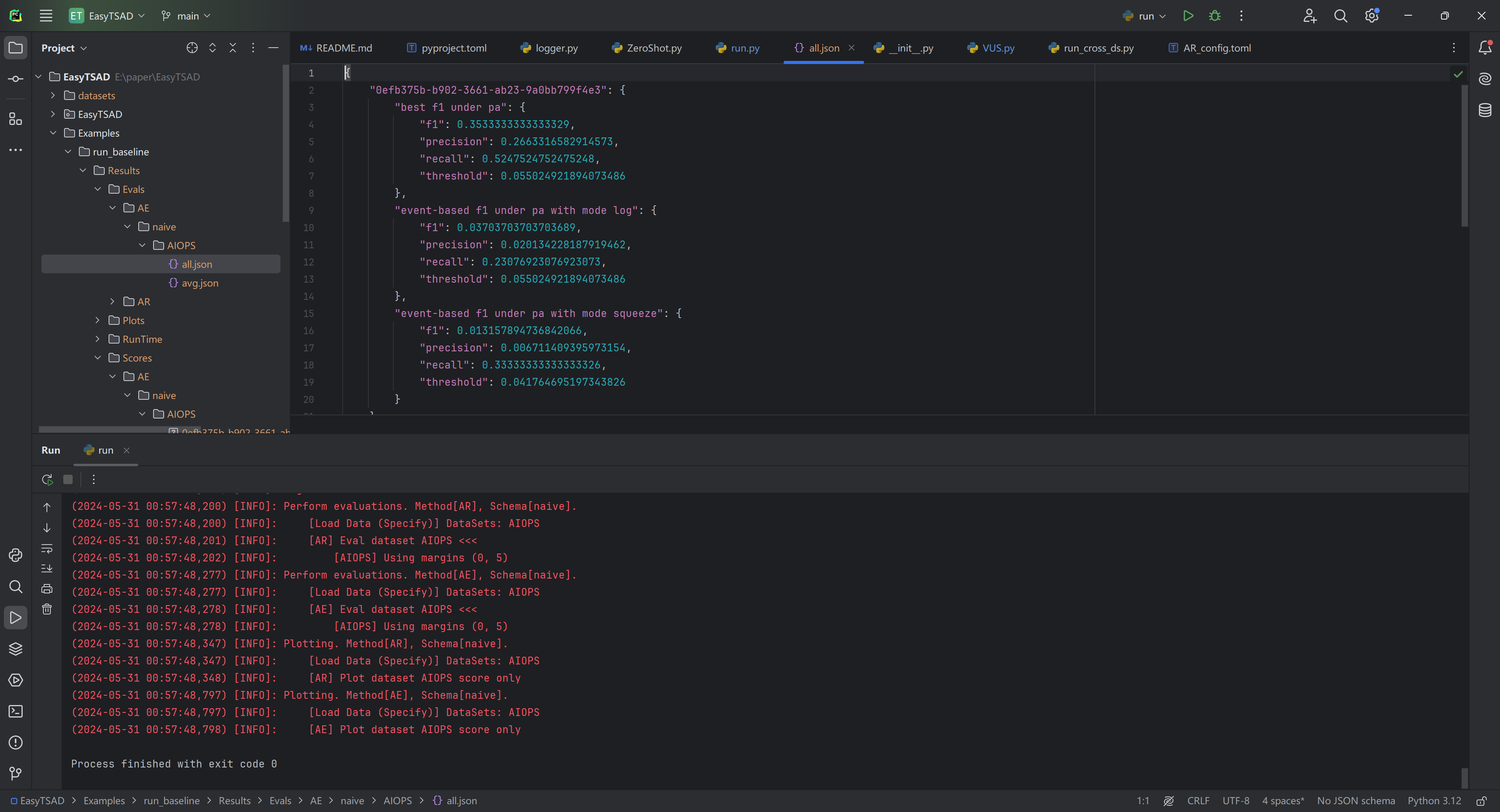
可以查看结果文件中的评分,以及基于事件识别的绘图等等,具体内容请自行了解。
29.4 基于 benchmark 研发自己的算法
这部分内容请参考 https://github.com/dawnvince/EasyTSAD/tree/main 的 README 内容,按照步骤逐个完成即可。比如准备数据,编辑配置文件,编写自己方法的主要类,继承于 BaseMethod 类等。
其他参考内容包括:
- https://github.com/dawnvince/EasyTSAD/tree/main/Examples/run_your_algo
- https://dawnvince.github.io/EasyTSAD/
也可以考虑直接在AR的基础上进行修改,然后完成自己的模型结构开发,优化过程开发等等。
此外,需要注意的是,作者对原始数据的缺失点都进行了填充,所以如果小伙伴们的算法需要关注 “由于缺失引起的异常” 的话,请不要使用这个 benchmark。
其他一些配置细节这里不再重复介绍,需要根据需要结合文档进行调整。
29.5 总结
前面在第24章的时候,提到过 benchmark 的作用,也提到过需要发paper的小伙伴们可以考虑这方面的工作,另外开辟一条赛道,个人认为这篇论文就是一个很好的例子,尽管目前还没有正式发表,但总体而言这篇论文还是很值得研究学习。
这篇论文在提供一个全面且实际的评估平台方面做出了重要贡献,其提出的多样化数据集、新评估标准和多种学习模式为时间序列异常检测的研究和应用提供了宝贵的资源和指导。
最后我们总结一下这篇论文值得参考的地方:
- 项目开源。小伙伴们可以基于这个开源的项目学习不同的算法实现,比如 Donut 等;(个人认为这个是最重要的,尤其是对于不太会动手写代码的小伙伴们来说,先有个模板用于学习非常重要)
- 新的评估方法(有些方法已经提过),相关方法的实现也便于我们使用。比如我们可以基于某个评估指标来评估自己的算法,并且要注意 “自圆其说”,比如我提出 “xxx” 算法,这个算法主要是针对 “event” 类的异常检测,然后再解释为什么自己的算法在这方面表现好等等。
- 多种学习模式。包括零样本学习和全样本学习,以模拟不同的实际应用环境。这对于研究在不同数据可用性条件下模型的性能具有重要意义。
- 数据集的多样性。TimeSeriesBench使用了多种数据集,涵盖了广泛的应用场景。这些数据集来源于不同的行业和应用,具有很高的多样性和代表性,有助于评估模型在不同环境下的泛化能力。
- 工业级基准测试框架。该论文提出的TimeSeriesBench是一个工业级的基准测试平台,涵盖了多种实际应用场景。这为研究人员提供了一个统一的评估标准,可以帮助他们在更真实的环境中测试和比较各种算法的性能。
希望能帮到各位小伙伴 ~ 万分感谢各位的点赞、评论与关注支持 ~

Smileyan
2024.05.31 23:24