综合类型数据挖掘任务
航空公司客户价值分析。航空公司客户价值分析。航空公司客户价值分析。航空公司已积累了大量的会员档案信息和其乘坐航班记录(air_data.csv),以2014年3月31日为结束时间抽取两年内有乘机记录的所有客户的详细数据。利用聚类算法对客户数据进行群体划分,并根据客户群体LRFMC指标分析并给出各客户群体的类型。
数据共有62988条,每条数据具有44个特征。包含会员卡号、入会时间、性别、年龄、会员卡级别、工作地城市、工作地所在省份、工作地所在国家、观测窗口结束时间、观测窗口乘机积分、飞行公里数、飞行次数、飞行时间、乘机时间间隔、平均折扣率等特征。
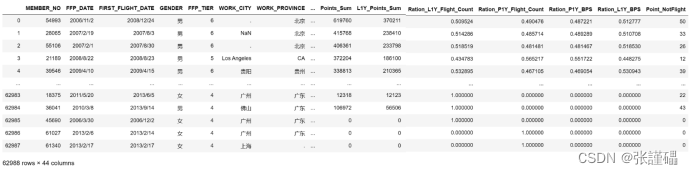
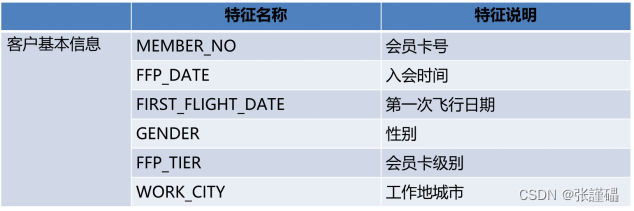
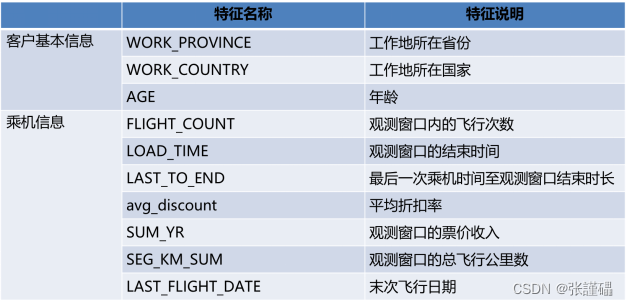
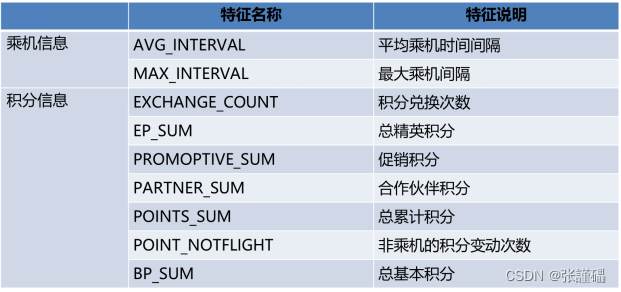
3.1数据预处理
航空公司客户原始数据存在少量的缺失值和异常值,需要清洗后才能用于分析。票价为空值、票价最小值为0、折扣率最小值为0总飞行千米数大于0的记录。票价为空值的数据可能是由于不存在乘机记录造成的。其他的数据可能是由于客户乘坐0折机票或者积分兑换造成的。
| 字段 | 异常情况 |
| SUM_YR_1 | NaN |
| SUM_YR_2 | NaN |
| avg_discount、SEG_KM_SUM | avg_discount=0&SEG_KM_SUM>0 |
| SUM_YR_1、SUM_YR_2 | 同时为0 |
处理后的数据有62044条。
# 读取原始数据
data = pd.read_csv('air_data.csv')
# 清洗数据
# 将票价为空值的数据删除
data = data[~data['SUM_YR_1'].isnull() & ~data['SUM_YR_2'].isnull()]
# 将票价为0或折扣率为0但总飞行千米数大于0的记录删除
data = data[~((data['avg_discount'] == 0) & (data['SEG_KM_SUM'] > 0))]
# 将SUM_YR_1和SUM_YR_2同时为0的记录删除
data = data[~((data['SUM_YR_1'] == 0) & (data['SUM_YR_2'] == 0))] 

3.2特征提取
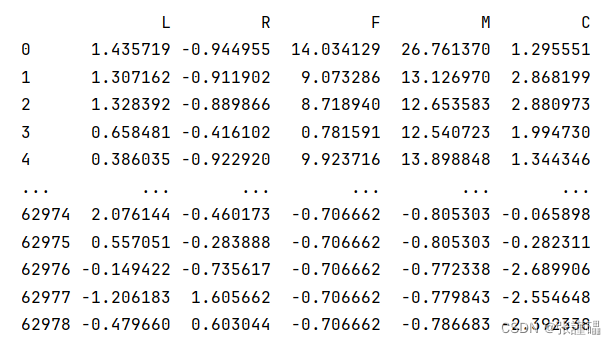
由于原始数据的特征过多,不便直接用于客户价值分析,因此需要对特征进行筛选,根据LRFMC模型挑选出衡量客户价值的关键特征,分别是:
- Length of Relationship: 客户关系时长,反映客户的活跃时长。
- Recency: 最近消费时间间隔,反映当前的活跃状态。
- Frequency: 客户消费频率,反映客户的忠诚度。
- Mileage: 客户总飞行里程,反映客户对乘机的依赖性。
- Coefficient of Discount: 客户所享受的平均折扣率,侧面反映客户价值高低。
| 特征 | 对应字段 |
| L | LOAD_TIME与FFP_DATE之差 |
| R | LAST_TO_END |
| F | FLIGHT_COUNT |
| M | SEG_KM_SUM |
| C | avg_discount |
特征提取后的数据为下图所示:
# 假设你的数据框称为 df,包含了原始数据和对应的特征字段
df = data
# 计算 LRFMC 模型对应的特征
df['L'] = (pd.to_datetime(df['LOAD_TIME']) - pd.to_datetime(df['FFP_DATE'])).dt.days
df['R'] = df['LAST_TO_END']
df['F'] = df['FLIGHT_COUNT']
df['M'] = df['SEG_KM_SUM']
df['C'] = df['avg_discount']
from sklearn.preprocessing import StandardScaler
# 创建一个标准化器
scaler = StandardScaler()
# 假设你的数据框称为 df,包含了需要标准化的特征字段
features_to_scale = ['L', 'R', 'F', 'M', 'C']
# 对选择的特征进行均值方差标准化
df[features_to_scale] = scaler.fit_transform(df[features_to_scale])
print(df)
3.3数据标准化
对提取的数据进行均值方差标准化。
# 标准化数据
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df2)
df_scaled = pd.DataFrame(scaled_features, columns=df2.columns)
3.4模型构建
本项目为聚类类型的任务,选择Kmeans对数据进行聚类,从而得到航空公司客户的类型分析结果。但要聚成多少类,很难断定。所以需要采用循环的方法,以聚类的个数作为循环变量(2到10),依次训练不同聚类个数的Kmeans模型,使用calinski_harabasz_score方法对各个Kmeans模型的结果进行评分。
# 创建一个空列表用于存放不同聚类数对应的评分
scores = []
# 设置循环,尝试不同的聚类个数
for n_clusters in range(2, 6):
# 创建并训练Kmeans模型
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(df_scaled)
# 使用calinski_harabasz_score方法对模型进行评分
score = calinski_harabasz_score(df_scaled, kmeans.labels_)
scores.append(score)
# 打印各个聚类数对应的评分
for n_clusters, score in zip(range(2, 6), scores):
print(f"Number of clusters: {n_clusters}, Calinski-Harabasz score: {score}") 
# 可视化不同聚类数对应的评分
plt.figure(figsize=(10, 6))
plt.plot(range(2, 6), scores, marker='o')
plt.title('Calinski-Harabasz Score for Different Number of Clusters')
plt.xlabel('Number of clusters')
plt.ylabel('Calinski-Harabasz Score')
plt.show() 
3.5模型训练
从上图中可以看出,聚类个数为2时模型评分最高,但仅将客户划分为2类会导致客户分类结果过于笼统,因此退而求其次,选择模型分数第二高的4作为聚类个数。
# 创建并训练最终的KMeans模型
final_kmeans = KMeans(n_clusters=4, random_state=42)
final_kmeans.fit(df_scaled)
# 将每个样本分配到对应的簇中
cluster_labels = final_kmeans.predict(df_scaled)
# 将簇标签添加到原始数据中
df2['cluster'] = cluster_labels
# 查看每个簇中样本的数量
cluster_counts = df2['cluster'].value_counts()
print(cluster_counts) 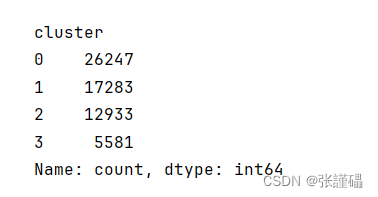
3.6结果分析
根据聚类结果绘制客户特征分析雷达图,根据雷达图显示的情况来对每个客户群的特征进行分析。
# 计算每个簇的平均特征值
cluster_means = df2.groupby('cluster').mean()
# 每个簇的特征名称
features = cluster_means.columns.tolist()
# 将第一个特征复制到列表末尾,以闭合雷达图
features.append(features[0])
# 绘制雷达图
plt.figure(figsize=(10, 8))
for cluster in range(4):
values = cluster_means.iloc[cluster].values.tolist()
values.append(values[0])
angles = np.linspace(0, 2 * np.pi, len(features), endpoint=False).tolist()
ax = plt.subplot(2, 2, cluster + 1, polar=True)
ax.fill(angles, values, 'b', alpha=0.1)
ax.plot(angles, values, linewidth=1.5, linestyle='solid', label=f'Cluster {cluster}')
ax.fill(angles, values, alpha=0.25)
ax.set_yticklabels([])
ax.set_thetagrids(np.degrees(angles), labels=features)
ax.set_title(f'Cluster {cluster}')
plt.show() 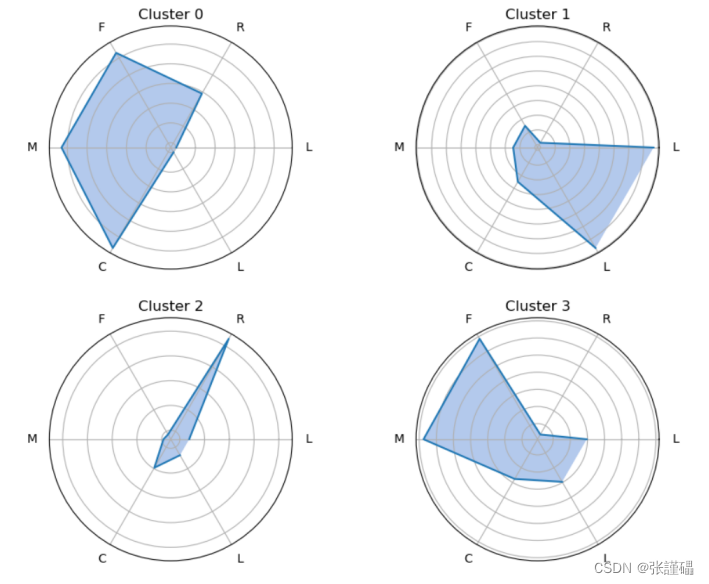
分析结果:
| 群体 | 类型 |
| 客户群体1 | 重要挽留客户 |
| 客户群体2 | 一般客户 |
| 客户群体3 | 低价值客户 |
| 客户群体4 | 重要保持客户 |
客户群体LRFMC指标分析:
| 群体 | 会员资历L | 最近乘机R | 乘机次数F | 飞行里程M | 平均折扣C |
| 重要保持客户 | ★★★★ | ★ | ★★★★★ | ★★★★★ | ★★★★ |
| 重要发展客户 | ★★★ | ★★★★ | ★★ | ★★ | ★★★★★ |
| 重要挽留客户 | ★★★★★ | ★★★ | ★★★★ | ★★★★ | ★★★ |
| 一般客户 | ★ | ★★★★ | ★★ | ★★ | ★ |
| 低价值客户 | ★★ | ★★★★★ | ★ | ★ | ★★ |
客户群体特点及策略:
| 群体 | 特点及策略 |
| 重要保持客户 | 平均折扣率高(C↑),最近有乘机记录(R↓),乘机次数高(F↑)或里程高(M↑) 这类客户机票票价高,不在意机票折扣,经常乘机,是最理想的客户类型。公司应优先将资源投放到他们身上,维持这类客户的忠诚度。 |
| 重要发展客户 | 平均折扣率高(C↑),最近有乘机记录(R↓),乘机次数低(F↓)或里程低(M↓) 这类客户机票票价高,不在意机票折扣,最近有乘机记录,但总里程低,具有很大的发展潜力。公司应加强这类客户的满意度,使他们逐渐成为忠诚客户。 |
| 重要挽留客户 | 平均折扣率高(C↑),乘机次数高(F↑)或里程高(M↑),最近无乘机记录(R↑) 这类客户总里程高,但较长时间没有乘机,可能处于流失状态。公司应加强与这类客户的互动,召回用户,延长客户的生命周期。 |
| 一般客户 | 平均折扣率低(C↓),最近无乘机记录(R↑),乘机次数高(F↓)或里程高(M↓),入会时间短(L↓) 这类客户机票票价低,经常买折扣机票,最近无乘机记录,可能是趁着折扣而选择购买,对品牌无忠诚度。公司需要在资源支持的情况下强化对这类客户的联系。 |
| 低价值客户 | 平均折扣率低(C↓),最近无乘机记录(R↑),乘机次数高(F↓)或里程高(M↓),入会时间短(L↓)这类客户与一般客户类似,机票票价低,经常买折扣机票,最近无乘机记录,可能是趁着折扣而选择购买,对品牌无忠诚度。 |
完整代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
from sklearn.preprocessing import StandardScaler
#%%
# 读取原始数据
data = pd.read_csv('air_data.csv')
# 清洗数据
# 将票价为空值的数据删除
data = data[~data['SUM_YR_1'].isnull() & ~data['SUM_YR_2'].isnull()]
# 将票价为0或折扣率为0但总飞行千米数大于0的记录删除
data = data[~((data['avg_discount'] == 0) & (data['SEG_KM_SUM'] > 0))]
# 将SUM_YR_1和SUM_YR_2同时为0的记录删除
data = data[~((data['SUM_YR_1'] == 0) & (data['SUM_YR_2'] == 0))]
#%%
# 假设你的数据框称为 df,包含了原始数据和对应的特征字段
df = data
# 计算 LRFMC 模型对应的特征
df['L'] = (pd.to_datetime(df['LOAD_TIME']) - pd.to_datetime(df['FFP_DATE'])).dt.days
df['R'] = df['LAST_TO_END']
df['F'] = df['FLIGHT_COUNT']
df['M'] = df['SEG_KM_SUM']
df['C'] = df['avg_discount']
#%%
# 创建一个标准化器
scaler = StandardScaler()
# 假设你的数据框称为 df,包含了需要标准化的特征字段
features_to_scale = ['L', 'R', 'F', 'M', 'C']
# 对选择的特征进行均值方差标准化
df[features_to_scale] = scaler.fit_transform(df[features_to_scale])
#%%
# 创建DataFrame
df2 = pd.DataFrame()
df2['L']=df['L']
df2['R']=df['R']
df2['F']=df['F']
df2['M']=df['M']
df2['C']=df['C']
#%%
# 标准化数据
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df2)
df_scaled = pd.DataFrame(scaled_features, columns=df2.columns)
#%%
# 创建一个空列表用于存放不同聚类数对应的评分
scores = []
# 设置循环,尝试不同的聚类个数
for n_clusters in range(2, 15):
# 创建并训练Kmeans模型
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
kmeans.fit(df_scaled)
# 使用calinski_harabasz_score方法对模型进行评分
score = calinski_harabasz_score(df_scaled, kmeans.labels_)
scores.append(score)
# 打印各个聚类数对应的评分
for n_clusters, score in zip(range(2, 15), scores):
print(f"Number of clusters: {n_clusters}, Calinski-Harabasz score: {score}")
#%%
# 可视化不同聚类数对应的评分
plt.figure(figsize=(10, 6))
plt.plot(range(2, 15), scores, marker='o')
plt.title('Calinski-Harabasz Score for Different Number of Clusters')
plt.xlabel('Number of clusters')
plt.ylabel('Calinski-Harabasz Score')
plt.show()
#%%
# 创建并训练最终的KMeans模型
final_kmeans = KMeans(n_clusters=4, random_state=42)
final_kmeans.fit(df_scaled)
# 将每个样本分配到对应的簇中
cluster_labels = final_kmeans.predict(df_scaled)
# 将簇标签添加到原始数据中
df2['cluster'] = cluster_labels
# 查看每个簇中样本的数量
cluster_counts = df2['cluster'].value_counts()
print(cluster_counts)
#%%
# 计算每个簇的平均特征值
cluster_means = df2.groupby('cluster').mean()
# 每个簇的特征名称
features = cluster_means.columns.tolist()
# 将第一个特征复制到列表末尾,以闭合雷达图
features.append(features[0])
# 绘制雷达图
plt.figure(figsize=(10, 8))
for cluster in range(4):
values = cluster_means.iloc[cluster].values.tolist()
values.append(values[0])
angles = np.linspace(0, 2 * np.pi, len(features), endpoint=False).tolist()
ax = plt.subplot(2, 2, cluster+1, polar=True)
ax.fill(angles, values, 'b', alpha=0.1)
ax.plot(angles, values, linewidth=1.5, linestyle='solid', label=f'Cluster {cluster}')
ax.fill(angles, values, alpha=0.25)
ax.set_yticklabels([])
ax.set_thetagrids(np.degrees(angles), labels=features)
ax.set_title(f'Cluster {cluster}')
plt.show()
#%%
plt.figure(figsize=(10, 8))
# 创建一个极坐标子图
ax = plt.subplot(111, polar=True)
for cluster in range(4):
values = cluster_means.iloc[cluster].values.tolist()
values.append(values[0])
angles = np.linspace(0, 2 * np.pi, len(features), endpoint=False).tolist()
# 绘制雷达图
ax.fill(angles, values, alpha=0.1)
ax.plot(angles, values, linewidth=1.5, linestyle='solid', label=f'Cluster {cluster}')
ax.fill(angles, values, alpha=0.25)
# 隐藏雷达图的刻度和标签
ax.set_yticklabels([])
ax.set_thetagrids(np.degrees(angles), labels=features)
# 添加图例
plt.legend(loc='upper right')
plt.show()
#%%