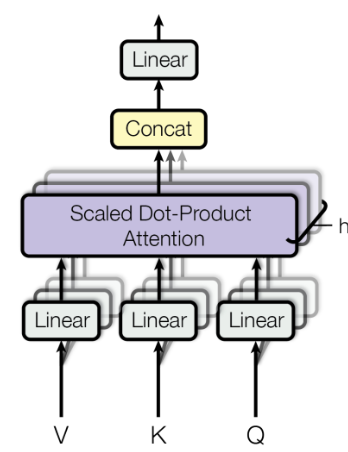
自适应注意力对比传统注意力机制,可以显著提高深度学习模型在处理复杂数据上的效率和准确性。
这种机制的核心在于:通过计算输入数据中不同部分之间的相关性或重要性,为这些数据部分分配不同的注意力权重,从而让模型能够更加专注于关键信息。
这样自适应注意力不仅可以提高模型处理信息的效率,还可以增强模型在各种任务和数据集上的性能表现,更适用于多种任务。它也因此拥有广泛的应用范围,成为了深度学习领域的一个热门方向。
为帮助各位快速了解这个新兴的、创新力十足的研究主题,我这次整理了9个最新的自适应注意力创新方案,并简单提炼了可参考的方法以及创新点,希望能给各位的论文添砖加瓦。
论文原文以及开源代码需要的同学看文末
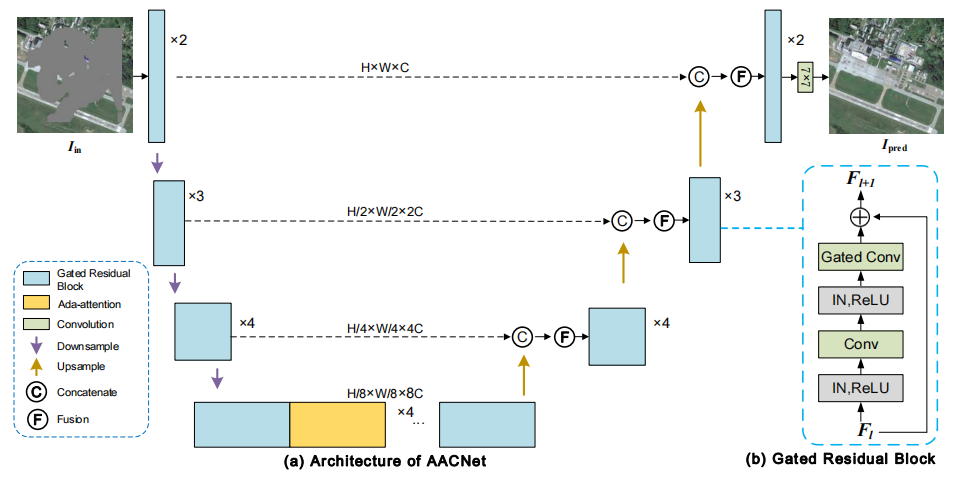
Adaptive-Attention Completing Network for Remote Sensing Image
方法:本文介绍了一种基于自适应注意力(Ada-attention)和门控残差块的U型AACNet模型,用于恢复遥感和自然图像中的缺失数据。Ada-attention通过数据依赖的偏移位置子网,选择性地关注相关的全局特征,而不是关注所有特征,从而减少了无关特征的干扰,并捕捉到了建模信息性的长期依赖关系。
创新点:
-
提出了自适应注意力(Ada-attention)机制,通过使用偏移位置子网动态选择相关的键和值,增强了注意力机制的能力,捕捉了更多信息丰富的长期依赖关系。
-
提出了自适应关注完成网络(AACNet),通过堆叠门控残差块和Ada-attention模块,实现了高效的遥感图像修复。
-
在多个数据集上进行了实验,通过定量指标(如PSNR、SSIM、MAE等)的比较,证明了AACNet模型在空间、结构和像素级别上的出色性能。

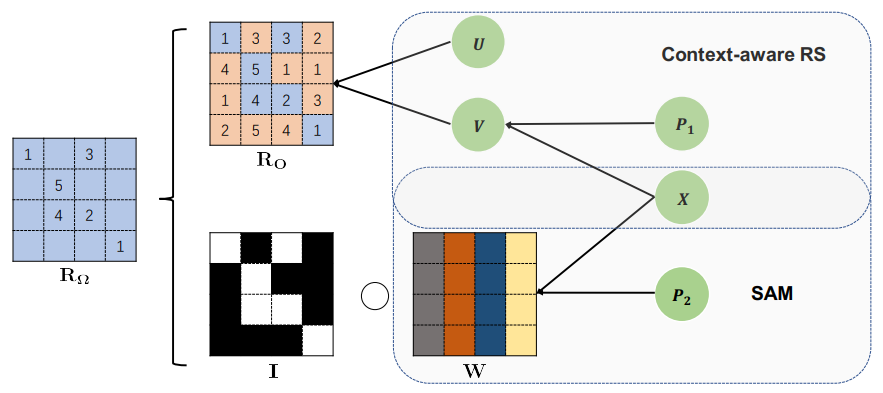
SAM: A Self-adaptive Attention Module for Context-Aware Recommendation System
方法:本文提出了一个自适应注意力模块(Self-adaptive Attention Module,简称SAM),它被用于上下文感知推荐系统。SAM的设计目的是通过捕获基于其表示的上下文信息来调整选择偏差,从而改善推荐系统的性能。
创新点:
-
提出了一种名为Self-adaptive Attention Module(SAM)的新颖通用的自适应模块,通过利用文本信息的表示来自适应学习注意力,以抵消选择偏差。
-
SAM可以无缝地集成到包含文本信息学习组件的模型中。
-
在三个真实数据集上的实证研究证明了SAM的有效性,并且广泛的实验表明SAM在极度稀疏的情况下具有巨大的潜力。
Multi-task Learning for Real-time Autonomous Driving Leveraging Task-adaptive Attention Generator
方法:论文设计一种适用于实时自动驾驶的多任务学习框架,包括单目三维目标检测、语义分割和密集深度估计,通过引入任务自适应注意力生成器来解决异构多任务学习中的负迁移问题,确保计算效率,并在各个任务中利用共享知识,实现任务自适应学习,从而取得了优越的性能。
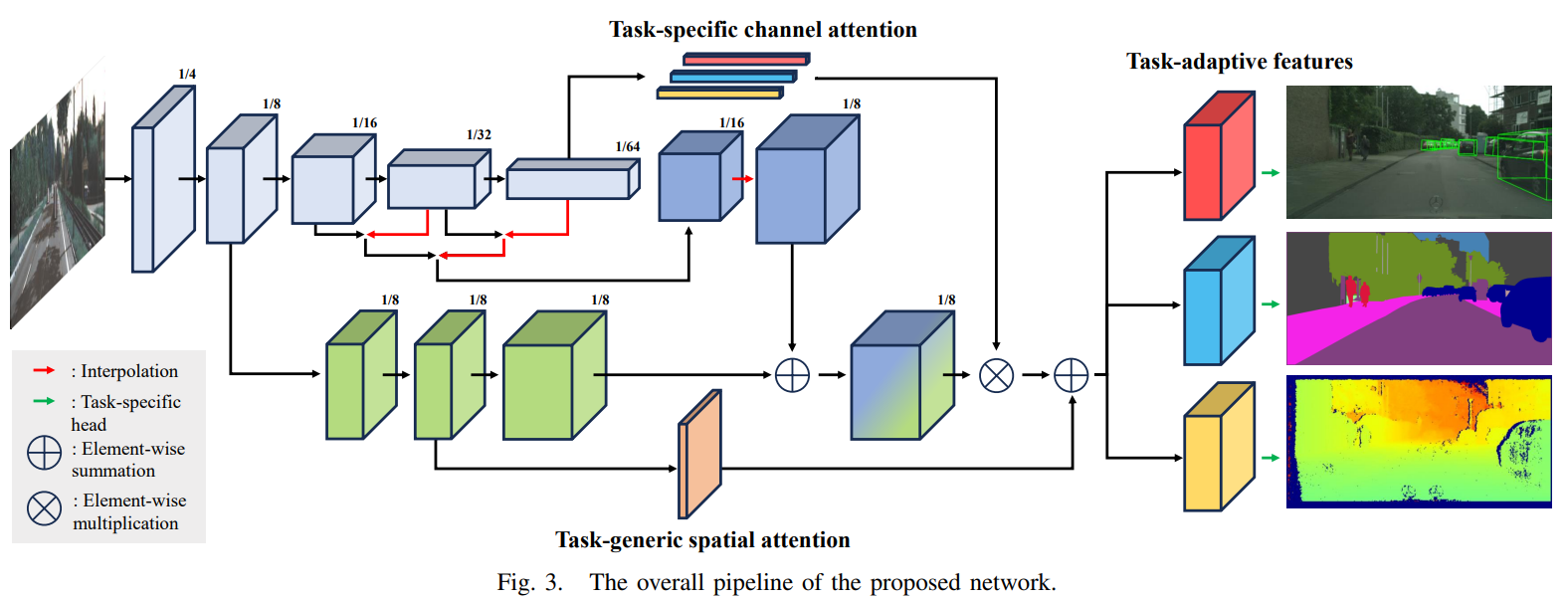
创新点:
-
提出了一个新的多任务学习方法,针对实时自动驾驶进行了定制化的研究,包括单目三维物体检测、语义分割和密集深度估计。
-
提出了一种独特设计的网络结构,解决了异构多任务学习中的负迁移问题,保证了计算效率。
-
提出的架构通过基于注意力的模块充分利用了任务间的共享知识,促进了任务自适应学习。
Voice Activity Detection Optimized by Adaptive Attention Span Transformer
方法:本文提出了一种基于自适应宽度注意力学习机制的自适应注意力跨度变换器模型(AAT-VAD),用于语音活动检测(VAD)。该方法通过从梅尔频率域提取梅尔频率倒谱系数(MFCC),为变换器注意力头添加掩蔽函数,并将变换器编码器层处理的特征输入分类器,以实现对长音频段的有效处理和减少计算成本。
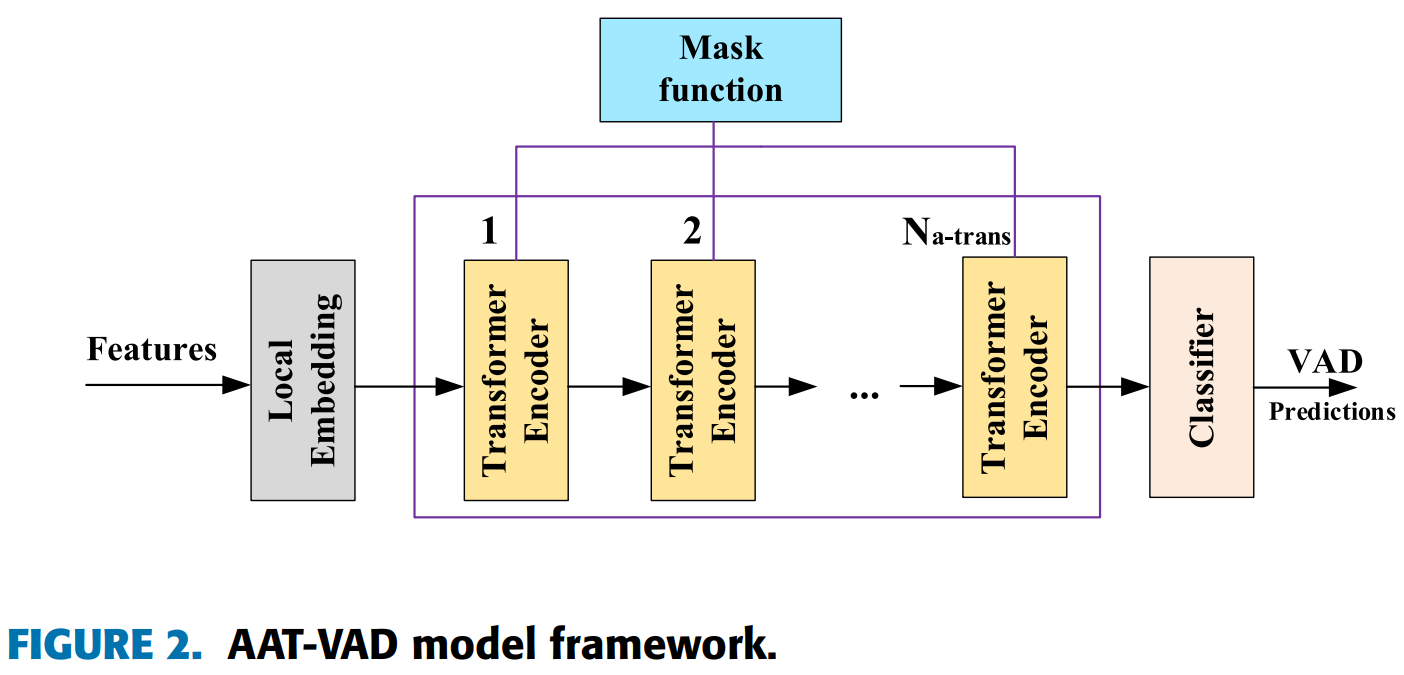
创新点:
-
自适应注意力跨度Transformer模型的构建,通过引入动态注意力学习和动态注意力机制,可以将音频信息分割为较小的单元,并应用深度卷积进行精确的语音活动检测。
-
在Transformer中引入高度可分的卷积块(DW)来补偿其在捕捉局部信息方面的不足,实现全局和局部连接。通过在模型中使用DW卷积层,可以提供对Transformer缺少的信息的局部关注,从而提高模型的泛化性能。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“自适应注意”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏