文章目录
- 1 关联规则
- 1.1 关联规则简介
- 1.2 典型例子
- 1.3 频繁项集的评估标准
- 1.3.1 支持度(support)
- 1.3.2 置信度(confidence)
- 1.3.3 提升度(lift)
- 1.4 最小支持度、最小置信度
- 2 Python实战
- 2.1 Python实战关联规则
- 2.2 数据集制作
- 在这里插入图片描述
- 2.3 电影数据集题材关联分析
- 3 Apriori算法实现
1 关联规则
1.1 关联规则简介
- 通过调查,在美国超市,在购买婴儿尿布的年轻父亲中,有30%-40%的人同时会买一些啤酒。随后超市将尿布和啤酒放在一起,明显增加了销售额。
- 若两个或多个变量的取值之间存在某种规律性,则称为关联。
- 关联规则是寻找在同一个事件中出现的不同项的相关性,例如,在一次购买活动中所买不同商品的相关性。
1.2 典型例子
-
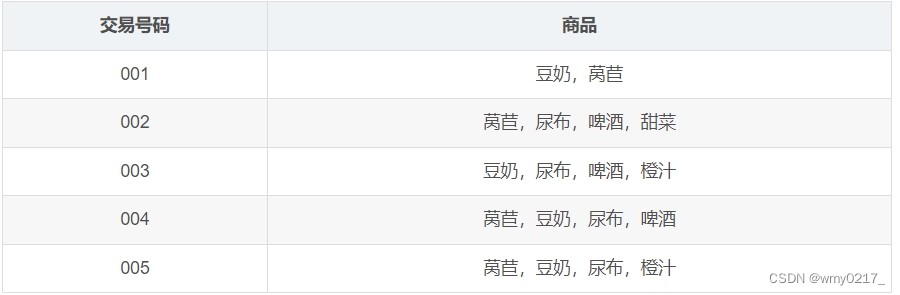
事物:每一条为一个事物。例如,上述例子包含5个事物。
-
项:每一个商品为一个项。例如,啤酒、尿布等。
-
项集:多个项组成的集合称为项集。
{啤酒}、{尿布}等都是1-项集。
{啤酒,尿布}、{豆奶,尿布}等都是2-项集。
{豆奶,尿布,啤酒}等都是3-项集。 -
X–>Y含义:
X和Y是项集
X是规则前项(antecedent)
Y是规则后项(consequent)
1.3 频繁项集的评估标准
1.3.1 支持度(support)
支持度是一个项集在所有事物中出现的频率。
项集X的支持度S(X) = X 出现的次数 总数据集 X出现的次数\over{总数据集} 总数据集X出现的次数
在1.2的例子中,{尿布,啤酒}出现了3次,所以support({尿布,啤酒}) = 3 5 3\over{5} 53=0.6
1.3.2 置信度(confidence)
置信度C(X—>Y)表示在购买X的前提下也购买Y的可能性。
C(X—>Y) = X 和 Y 同时出现的次数 X 出现的次数 X和Y同时出现的次数\over{X出现的次数} X出现的次数X和Y同时出现的次数
在1.2的例子中,C(尿布—>啤酒) = 3 4 3\over{4} 43 = 0.75
1.3.3 提升度(lift)
支持度和置信度是有局限性的,⽀持度的缺点在于许多潜在的有意义的模式由于包含⽀持度小的项而被删去,置信度的缺点在于置信度度量会忽略规则后件中出现的项集的⽀持度,高置信度的规则有时可能出现误导。
lift(X—>Y) = C ( X — > Y ) S ( Y ) C(X—>Y) \over{S(Y)} S(Y)C(X—>Y)
- 提升度 > 1,则 X —> Y 是有效的强关联规则
- 提升度 ≤ 1,则 X —> Y 是无效的强关联规则
if lift = 1,X与Y独立,X对Y出现的可能性没有提升作用,其值越大,则表明X对Y的提升程度越大,也表明关联性越强。
1.4 最小支持度、最小置信度
- 最小支持度(minsup)是用户或专家定义的衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性。
- 最小置信度(minconf)是用户或专家定义的衡量置信度的一个阈值,表示关联规则的最低可靠性。
- 同时满足最小支持度阈值和最小置信度阈值的规则称作强规则。
- 给定事务的集合T,关联规则发现是指找出支持度大于等于 minsup 并且置信度大于等于minconf 的所有规则。
2 Python实战
2.1 Python实战关联规则
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import pandas as pd
#自定义一份购物数据集
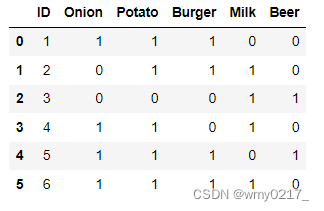
data={'ID':[1,2,3,4,5,6],'Onion':[1,0,0,1,1,1],
'Potato':[1,1,0,1,1,1],'Burger':[1,1,0,0,1,1],
'Milk':[0,1,1,1,0,1],'Beer':[0,0,1,0,1,0]}
df = pd.DataFrame(data)
df
frequent_itemsets = apriori(df[['Onion','Potato','Burger','Milk','Beer']],min_support=0.5,use_colnames=True)
frequent_itemsets

rules = association_rules(frequent_itemsets,metric='lift',min_threshold=1)
rules[(rules['lift']>1.125) & (rules['confidence']>0.8)]

结果表明:
- (洋葱和马铃薯)(汉堡和马铃薯)可以搭配着卖
- 如果顾客一句买了汉堡和洋葱,那么他买马铃薯的可能性也比较大,可以进行推荐。
2.2 数据集制作
retail_shopping_basket = {
'ID': [1, 2, 3, 4, 5, 6],
'Basket':[
['Onion', 'Beer', 'Chicken', 'Drink', 'Burger', 'Chips', 'Disper'],
['Onion', 'Beer', 'Chicken', 'Burger', 'Chips', ],
['Onion', 'Chicken', 'Drink', 'Burger', 'Chips', 'Disper'],
['Onion', 'Chicken', 'Drink'],
['Beer', 'Chicken', 'Drink', 'Burger', 'Chips', 'Disper'],
['Drink', 'Burger', 'Chips', 'Disper']
]
}
retail = pd.DataFrame(retail_shopping_basket)
retail

retail_id = retail.drop('Basket',1)
retail_Basket = retail.Basket.str.join(',')
retail_Basket

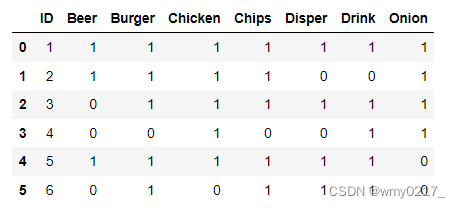
retail_Basket = retail_Basket.str.get_dummies(',')
retail_Basket

retail = retail_id.join(retail_Basket)
retail
2.3 电影数据集题材关联分析
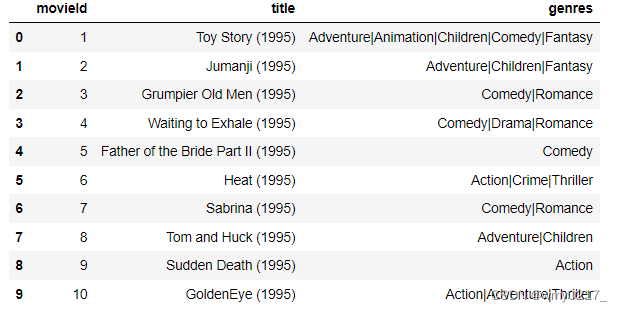
movies = pd.read_csv('movies.csv')
movies.head(10)
movies_ohe = movies.drop('genres',1).join(movies.genres.str.get_dummies())
movies_ohe.head()
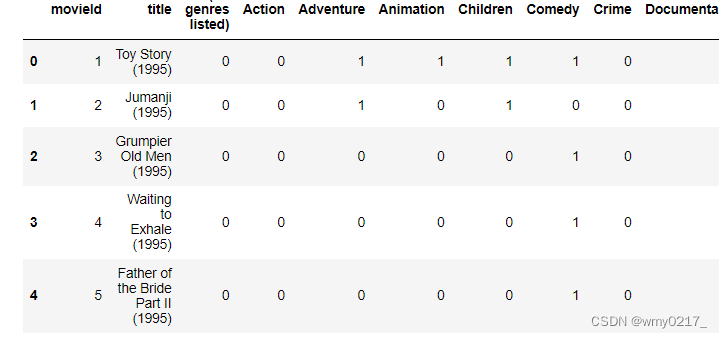
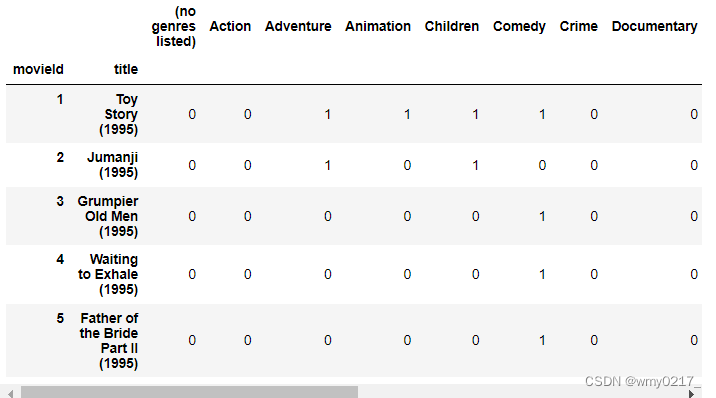
pd.options.display.max_columns=100
movies_ohe.set_index(['movieId','title'],inplace=True)
movies_ohe.head()
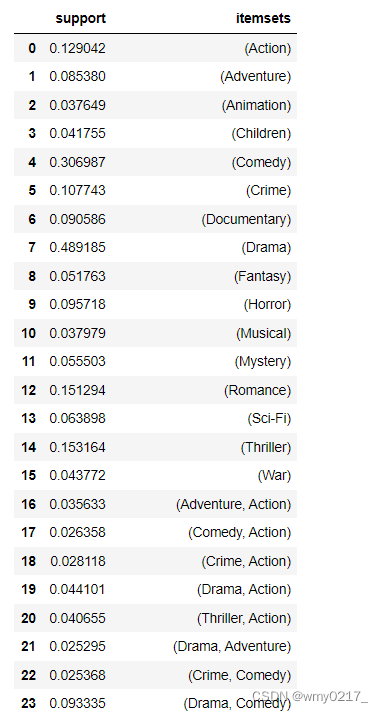
frequent_itemsets_movies = apriori(movies_ohe,use_colnames=True,min_support=0.025)
frequent_itemsets_movies
rules_movies = association_rules(frequent_itemsets_movies,metric='lift',min_threshold=1.25)
rules_movies

rules_movies[(rules_movies.lift>3)].sort_values(by=['lift'])
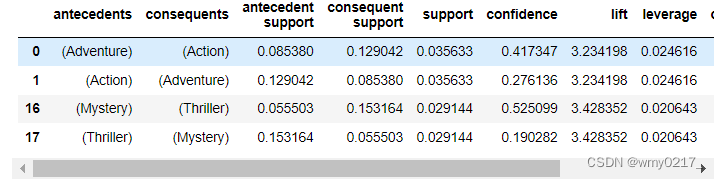
由结果可知:
- Adventure和Action题材比较相关
- Mystery和Thriller题材比较相关
3 Apriori算法实现
待补充