✍🏻记录学习过程中的输出,坚持每天学习一点点~
❤️希望能给大家提供帮助~欢迎点赞👍🏻+收藏⭐+评论✍🏻+指点🙏
1.5.4 Cache替换算法
Cache的页面淘汰算法
常用替换算法有:
• 随机替换算法RAND (Random):随机地选择Cache块进行替换
分析:没有考虑到局部性原理,运气不好的话刚调入的Cache块有会被马上替换出来
• 先进先出FIFO (first-in-first-out):顾名思义就是替换最先被使用的Cache块
分析:同样没有考虑到局部性原理,如果最先被使用的先被调出,而后又频繁使用1234块,就会发生【抖动现象】
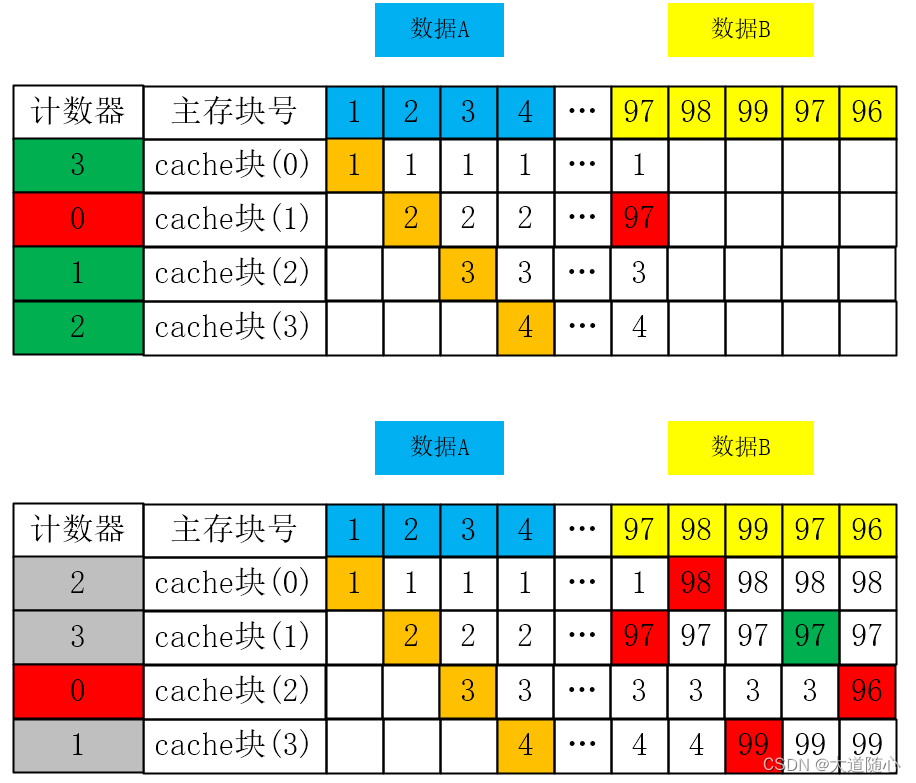
• 最近最少用LRU ( least-recently used):每个Cache都设置一个【计数器】,代表每个Cache块有多久没被访问,当Cache满的时候替换【计数器】最大的Cache块
分析:该算法比较好的利用了局部性原理(近期被访问的主存块可能在不就还会被访问到),因此该算法很不错
• 最不经常用LFU ( least-frequently used):每个Cache都设置一个【计数器】,用于记录每个Cache块被访问的次数,当Cache满的时候替换【计数器】最小的Cache块
分析:没有很好的利用局部性原理,因为已知经常用到的主存块在未来不一定要用到,其命中率相比LRU较低,且CPU访问主存的次数极高,代表计数器将会占用较多的空间
LRU和LFU比较:
LRU会替换最近最少访问的Cache块,而LFU会替换访问次数最小的Cache块
虽然算法不一样,但从说明上这么一看似乎LRU也可以理解成LFU,最近最少访问不就等于访问次数最小吗?
假设我们先频繁访问了某程序的主存数据A【主存块号为1、2、3、4】,将其全部装入Cache,如果未来需要频繁访问程序的主存数据B【97、98、99】
(1)对LFU算法而言,就会出现频繁调入调出计数器最小的【Cache块(1)】,即抖动现象
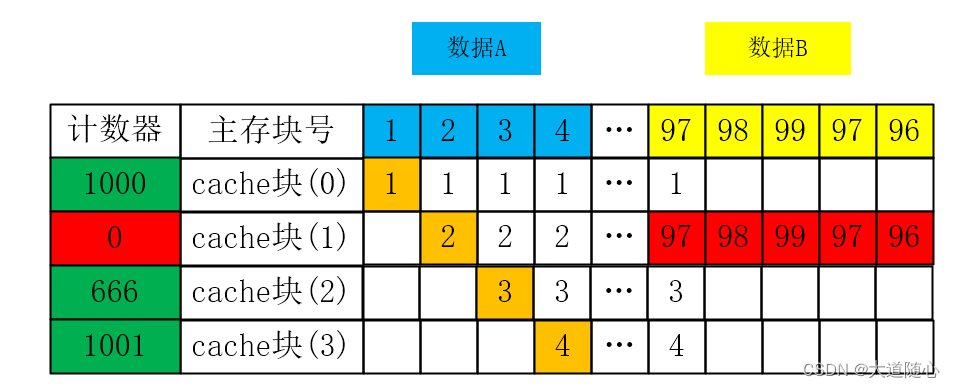
(2)但对于LRU算法的影响较小,LRU算法能更快的把数据A的Cache块全部替换成数据B的主存块
Cache的读写过程
写直达:同时写Cache与内存
写回:只写Cache,淘汰页面时,写回内存
标记法:只写入内存,并将标志位清零,若用到此数据,只需要再次调取
练习题
Cache的替换算法中,( B )算法计数器位数多,实现困难。
A.FIFO
B. LFU
C. LRU
D. RAND
1.5.5 磁盘(外存储器)
● 机械磁盘存在两组运动:
◎ 磁盘的旋转运动
◎ 机械臂控制磁头沿半经方向的直线运动
● 存取时间=寻道时间+等待时间
◎ 寻道时间:指磁头移动到磁道所需的时间
◎ 等待时间:等待读写的扇区转到磁头下方所用的时间
分 磁道和扇区
练习题
在磁盘调度管理中,通常( C )(2019下半年试题)
A.先进行旋转调度,再进行移臂调度
B.在访问不同柱面的信息时,只需要进行旋转调度
C.先进行移臂调度,再进行旋转调度
D.在访问同一磁道的信息时,只需要进行移臂调度
1.6.1 输入/输出技术
● 直接程序控制
◎ 分为无条件传送和程序查询方式
◎ 降低了CPU的效率
◎ 对外部的突发事件无法做出实时响应
● 程序中断方式
◎ 利用中断方式完成数据的输入/输出
◎ CPU接到中断请求信号后,保存正在执行程序的现场
◎ 与程序控制方式相比,因为CPU无须等待而提高了效率
● DMA
◎ 在主存与I/O设备(外设)之间建立数据通路进行数据的交换处理
◎ 在DMA传送过程中无须CPU的干预
◎ DMA传送数据时要占用系统总线,此时,CPU不能使用总线
◎ DMA传送结束为中断
● 输入/输出处理机(IOP)
◎ 分担了CPU的一部分功能,可以实现对外围设备的统一管理,完成外围设备与主存之间的数据传送
◎ 大大提高了CPU的工作效率,这种效率的提高是以增加更多的硬件为代价的
练习题
DMA控制方式是在( C )之间直接建立数据通路进行数据的交换处理。(2019年上半年试题软设)
A.CPU与主存
B.CPU与外设
C.主存与外设
D.外设与外设
计算机运行过程中,CPU需要与外设进行数据交换。采用( B )控制技术时,CPU与外设可并行工作。
(2017年下半年)
A.程序查询方式和中断方式
B.中断方式和DMA方式
C.程序查询方式和DMA方式
D.程序查询方式、中断方式和DMA方式
1.7.1 flynn分类法
计算机系统结构的分类方法之一
1966年M.J.Flynn提出了如下定义:
指令流(Instruction Stream)——机器执行的指令序列。
数据流 (Data Stream)——指令调用的数据序列,包括输入数据和中间结果。
多倍性(Multiplicity)——在系统最受限制的元件上同时处于同一执行阶段指令或数据执行的最大可能个数。
按照指令和数据流不同的组织方式,计算机系统可分为四类:
单指令单数据流(Single Instruction stream and Single Data stream,SISD):SISD其实就是传统的顺序执行的单处理器计算机,其指令部件每次只对一条指令进行译码,并只对一个操作部件分配数据。流水线方式的单处理机有时也被当成SISD。
单指令多数据流(SIMD) 特性:各处理机以同步的形式执行同一条指令
多指令单数据流(MISD) 特性:被证明不可能,至少是不实际
多指令多数据流(MIMD) 特性:能够实现作业,任务,指令等各级全面并行
| Single | Multiple | |
|---|---|---|
| Single | SISD | MISD |
| Multiple | SIMD | MIMD |
练习题
Flymn分类法根据计算机在执行程序的过程中( A )的不同组合,将计算机分为4类。当前主流的多核计算机属于( D )计算机。
A.指令流和数据流
B.数据流和控制流
C.指令流和控制流
D.数据流和总线带宽
A.SISD
B.SIMD
C.MISD
D.MIMD
1.7.2 CISC和RISC
CISC,全称为Complex Instruction Set Computing,意为复杂指令集计算。它是一种指令集设计理念,其特点是指令数量多、格式多样、长度不一、功能强大。CISC可以用较少的指令完成较复杂的操作,典型的代表是X86架构。这种架构的处理器芯片被广泛应用于Windows操作系统的服务器,是目前主流的服务器架构。
CISC架构的主要优点有:
指令执行效率高,可以用较少的指令周期完成较复杂的任务,提高CPU利用率。
编译器设计简单,因为指令功能强大,编译器可以用较少的指令生成目标代码,降低编译难度和时间。
程序可移植性好,由于指令集兼容性高,程序可以在不同的平台上运行,提高软件开发效率。
然而,CISC架构也存在一些缺点:
指令译码复杂,由于指令格式多样、长度不一,CPU需要更多的硬件电路和时间来译码执行指令,这增加了芯片面积和功耗。
指令执行速度慢,因为每条指令需要更多的时钟周期来完成,这降低了程序运行速度。
指令集臃肿,指令数量多,有些指令很少使用或者功能重复,造成了指令集的浪费和冗余。
RISC,全称为Reduced Instruction Set Computer,意为精简指令系统计算机。RISC的特点包括选取使用频率较高的一些简单指令以及一些很有用但不复杂的指令,让复杂指令的功能由频率较高的简单指令的组合完成。此外,RISC的指令长度固定,指令格式种类少,寻址方式种类少,并且大部分指令在一个时钟周期内完成。
RISC架构的主要优点有:
指令执行时间短,因为90%的指令是由硬件直接完成,只有10%的指令是由软件以组合的方式完成。
适合采用流水线处理架构的设计,平均一周期可以完成一指令。
然而,RISC架构也存在一些缺点,如指令精简化后造成应用程序码变大,需要较大的存储器空间。
总的来说,CISC和RISC各有其特点和优缺点,适用于不同的场景和需求。在实际应用中,需要根据具体的应用场景和需求来选择适合的指令集架构。
| 指令系统类型 | 指令 | 寻址方式 | 实现方式 | 其他 | 代表 |
|---|---|---|---|---|---|
| CISC(复杂) | 数量多,使用频率差别大,可变长格式 | 支持多种 | 微程序控制技术(微码) | 研制周期长 | X86 |
| RISC(精简) | 数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存 | 支持方式少 | 增加了通用寄存器;硬布线逻辑控制为主;更适合采用流水线 | 优化编译,有效支持高级语言(如java) | RISC-V、ARM |
练习题
(2022年上半年)以下关于RISC和CISC的叙述中,不正确的是(B )
A.RISC的大多指令在一个时钟周期内完成
B.RISC普遍采用微程序控制器,CISC则普遍采用硬布线控制器
C.RISC的指令种类和寻指方式相对于CISC更少
D.RISC和CISC都采用流水线技术