本文讨论的内容参考自《神经网络与深度学习》https://nndl.github.io/ 第4章 前馈神经网络
前馈神经网络


神经元


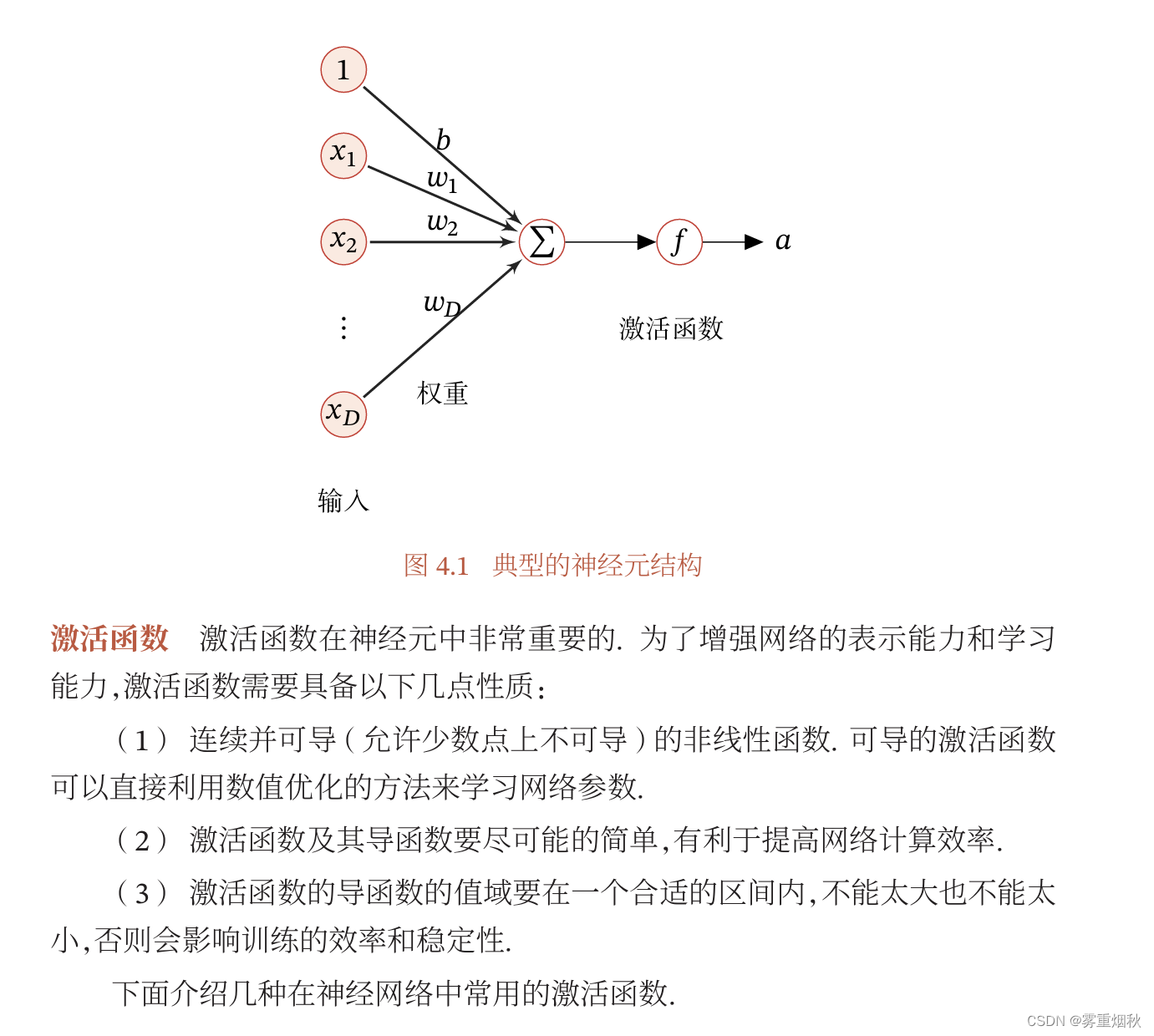
Sigmoid型函数


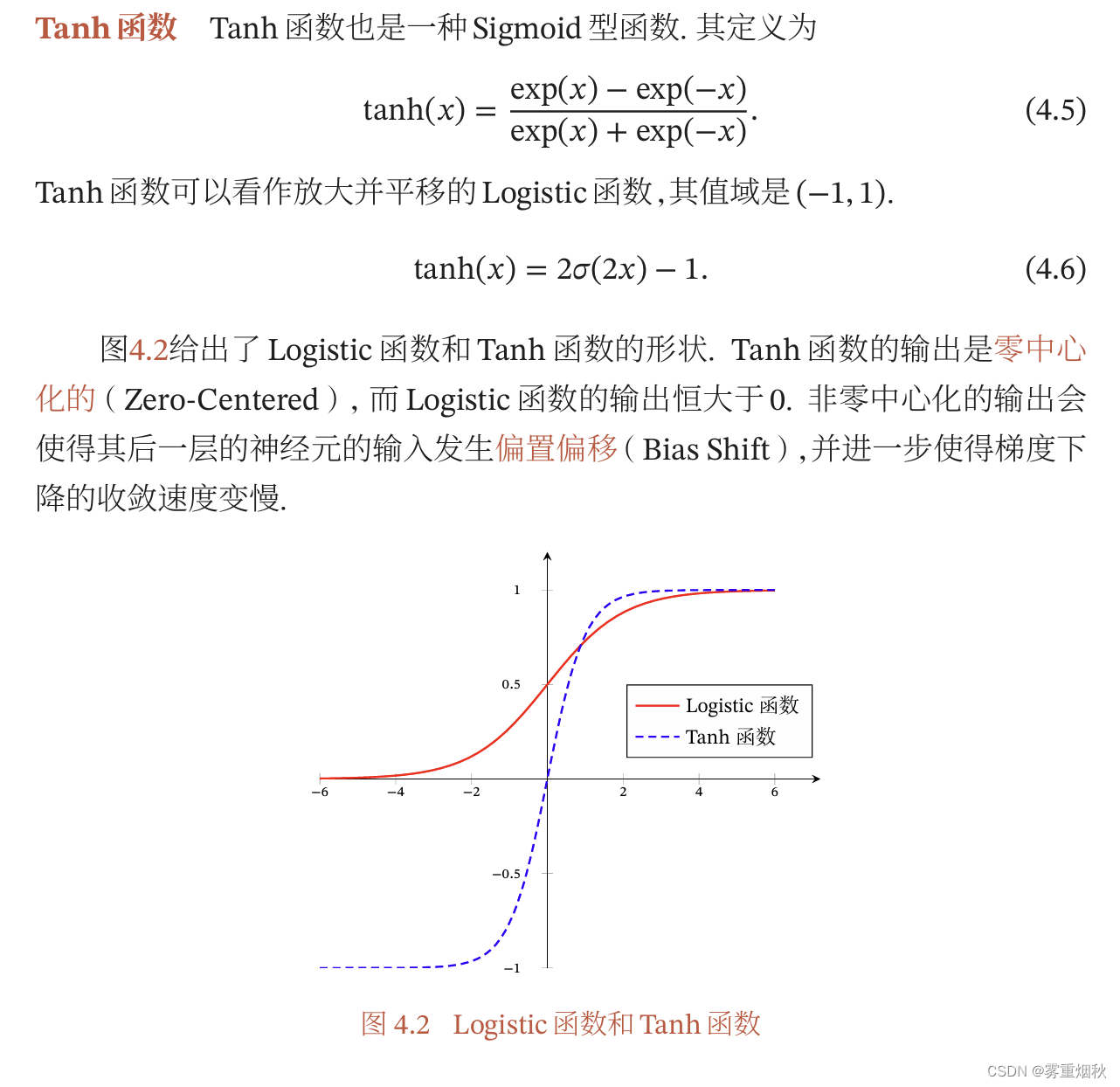
Hard-Logistic函数和Hard-Tanh函数


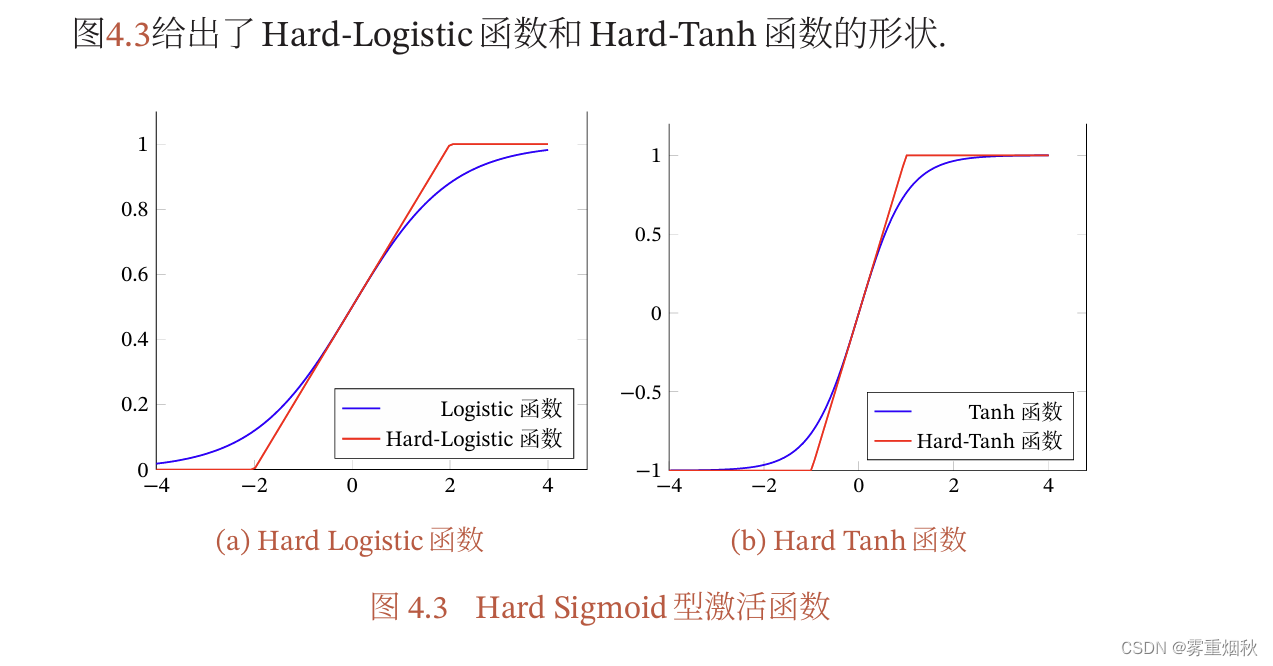
ReLU函数


带泄露的ReLU


带参数的ReLU

ELU函数

Softplus函数

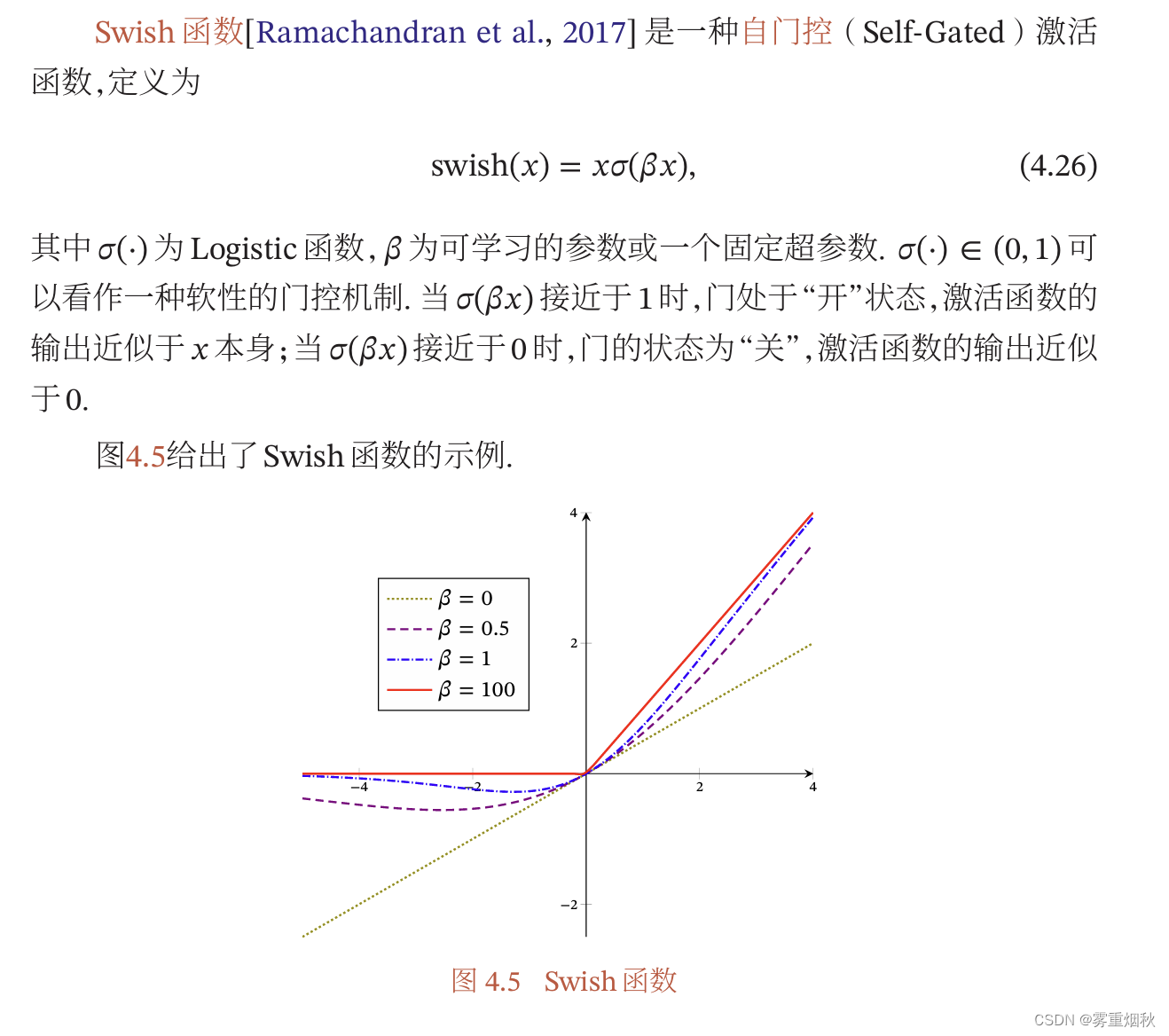
Swish函数


GELU函数

Maxout单元

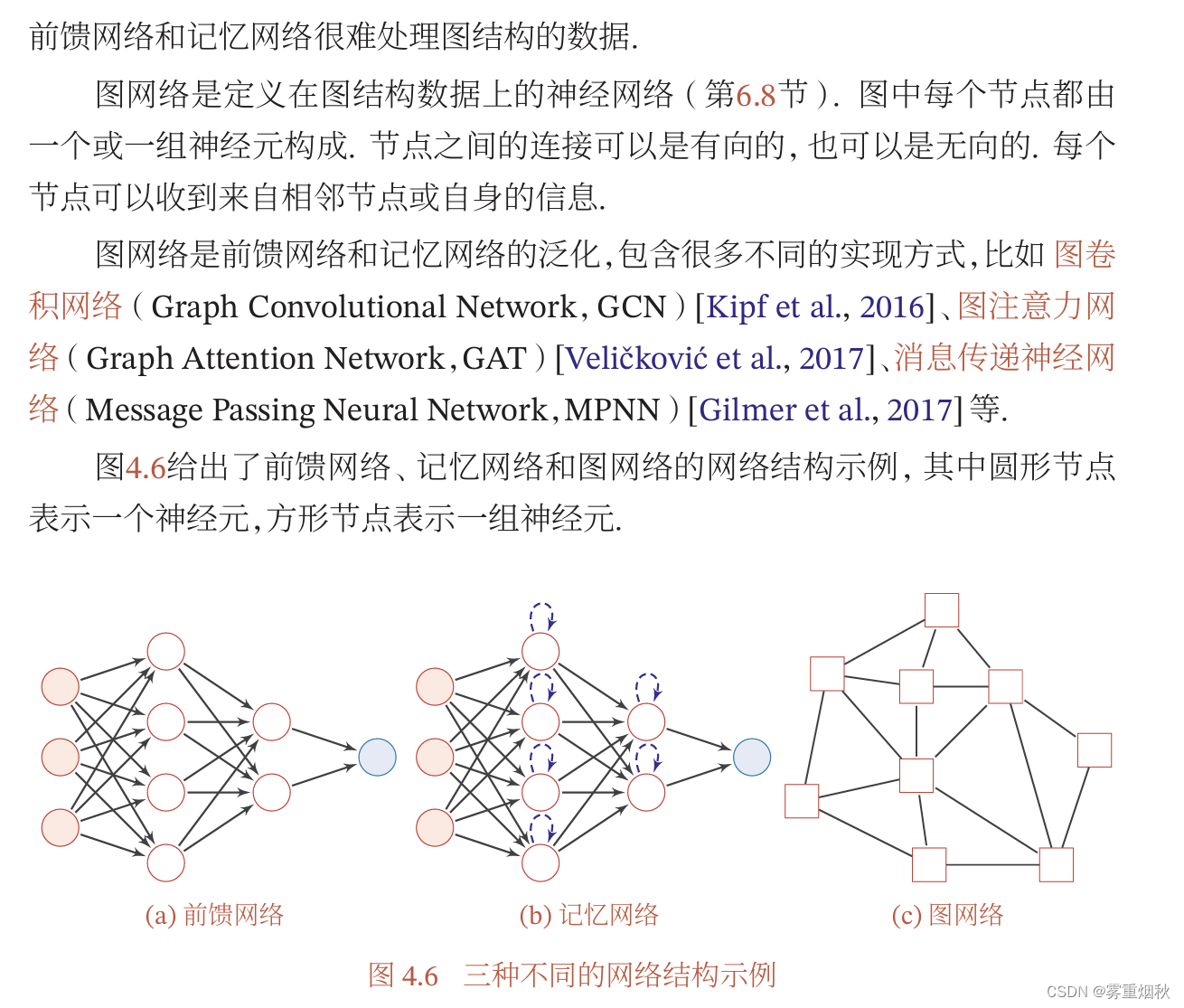
网络结构

前馈网络

记忆网络

图网络

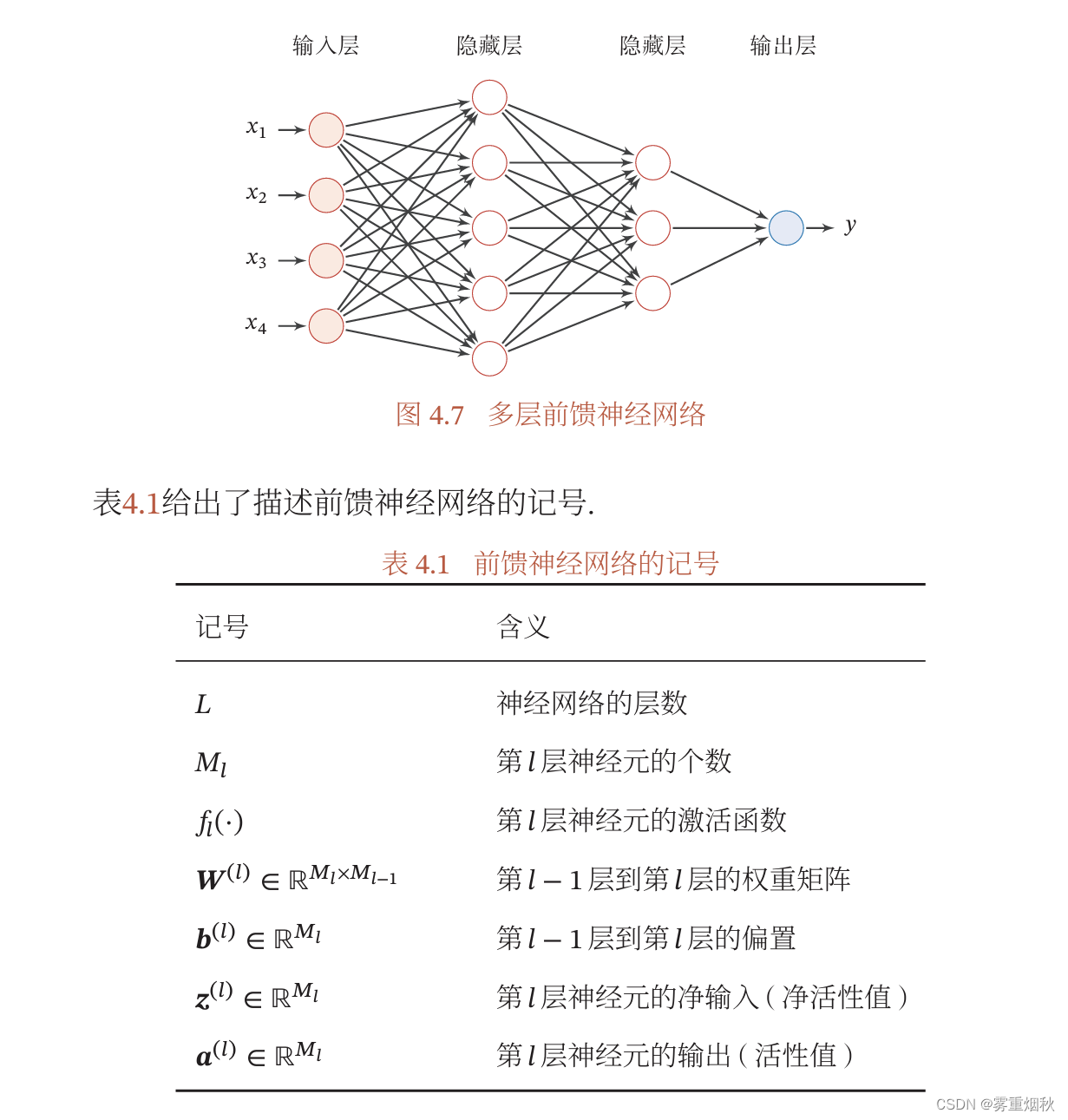
前馈神经网络



通用近似定理


应用到机器学习


参数学习


反向传播算法






所以实际上反向传播类似于动态规划,一般来说对所有神经元都需要单独进行链式法则求梯度,但反向传播从最后一层向前传,防止重复计算,提高了计算效率,而且这种计算是自动的(下节的自动梯度计算)。
自动梯度计算


数值微分

符号微分


自动微分





这里解释了,对于一般的函数形式
f
:
R
N
→
R
M
f:R^N \rightarrow R^M
f:RN→RM,前向模式需要对每一个输入变量都进行一遍遍历,共需要
N
N
N遍,而反向模式需要对每一个输出进行遍历,共需要
M
M
M遍,当
N
>
M
N>M
N>M时,反向模式更高效。在前馈神经网络的参数学习中,风险函数为
f
:
R
N
→
R
f:R^N \rightarrow R
f:RN→R,输出为标量,因此采用反向模式时最有效的计算方式,只需要一遍计算。
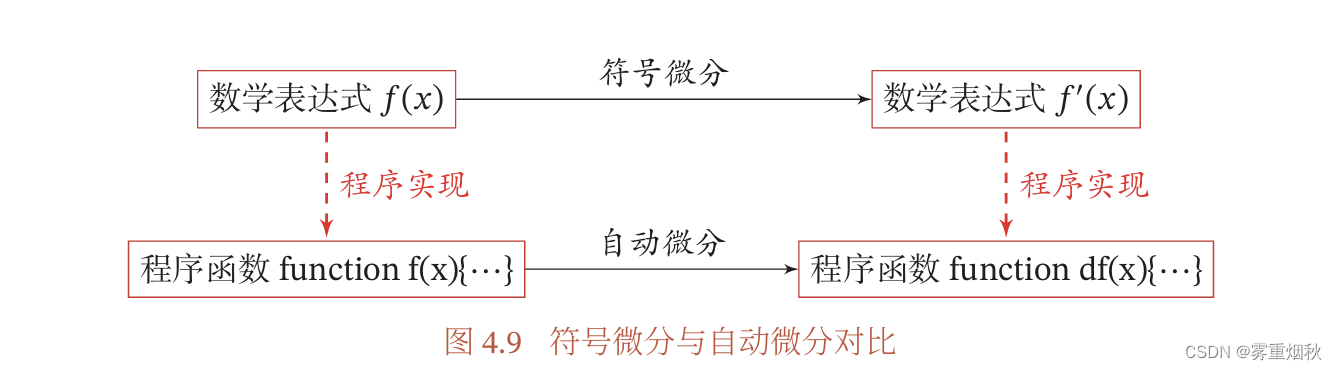
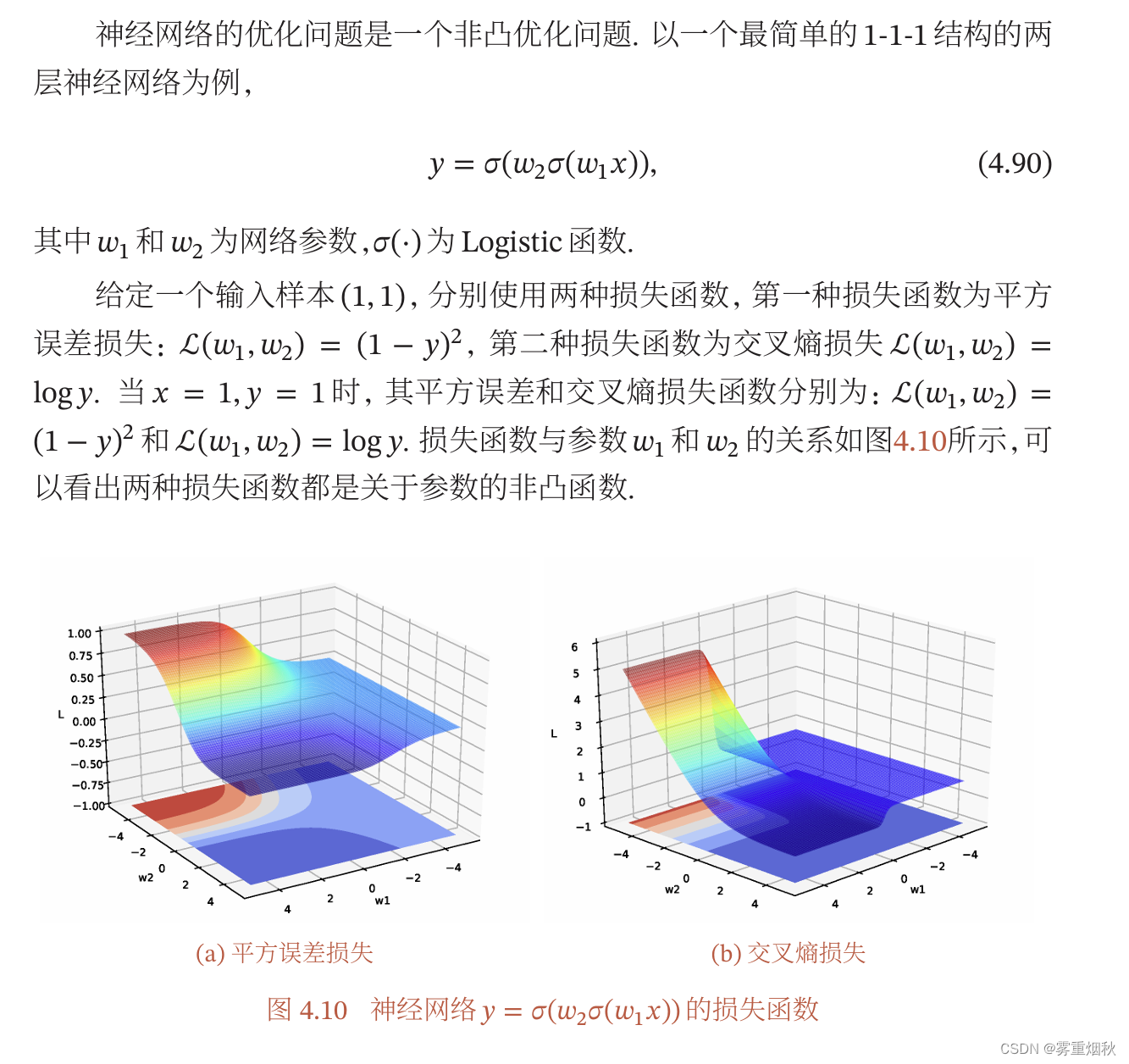
优化问题

非凸优化问题
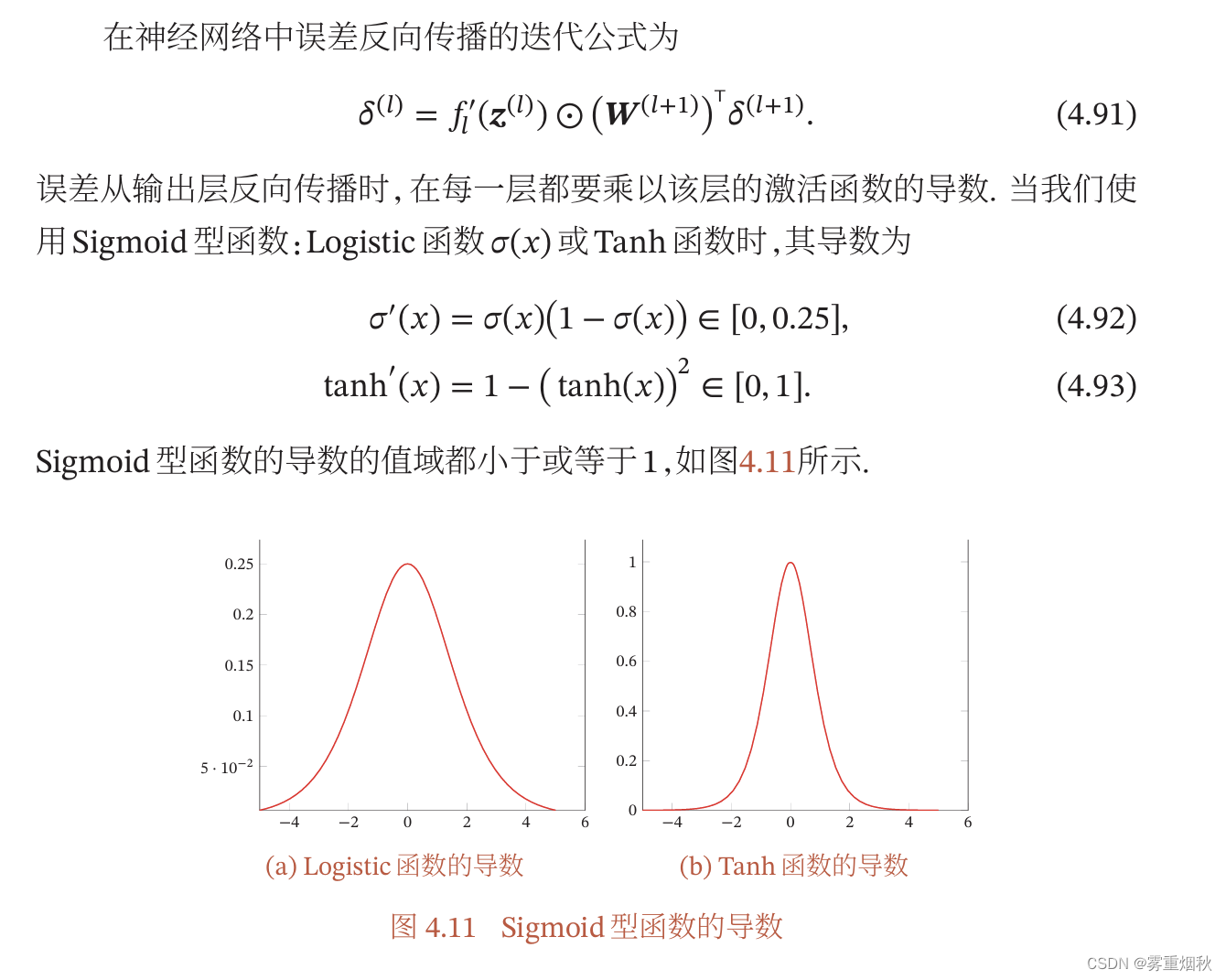
梯度消失问题

总结和深入阅读


习题

如果进行0均值化,那么输入的
x
\bm x
x要么大于0要么小于0,在0附近,sigmoid函数的导数在0附近是最大的,所以收敛速度很快。当输入恒大于0的时候,均值肯定大于0,那么有可能就到了sigmoid函数的平缓部分,所以收敛速度更慢。

XOR问题即异或问题,有
0
X
O
R
0
=
0
0 XOR 0 = 0
0XOR0=0,
0
X
O
R
1
=
1
0 XOR 1 = 1
0XOR1=1,
1
X
O
R
0
=
1
1 XOR 0 = 1
1XOR0=1,
1
X
O
R
1
=
0
1 XOR 1 = 0
1XOR1=0,分类时就必须把(0,1)、(1,0)分为类别1,把(0,0)、(1,1)分为类别0,可以看到这是线性不可分的,那么用一个前馈神经网络来解决这个问题,
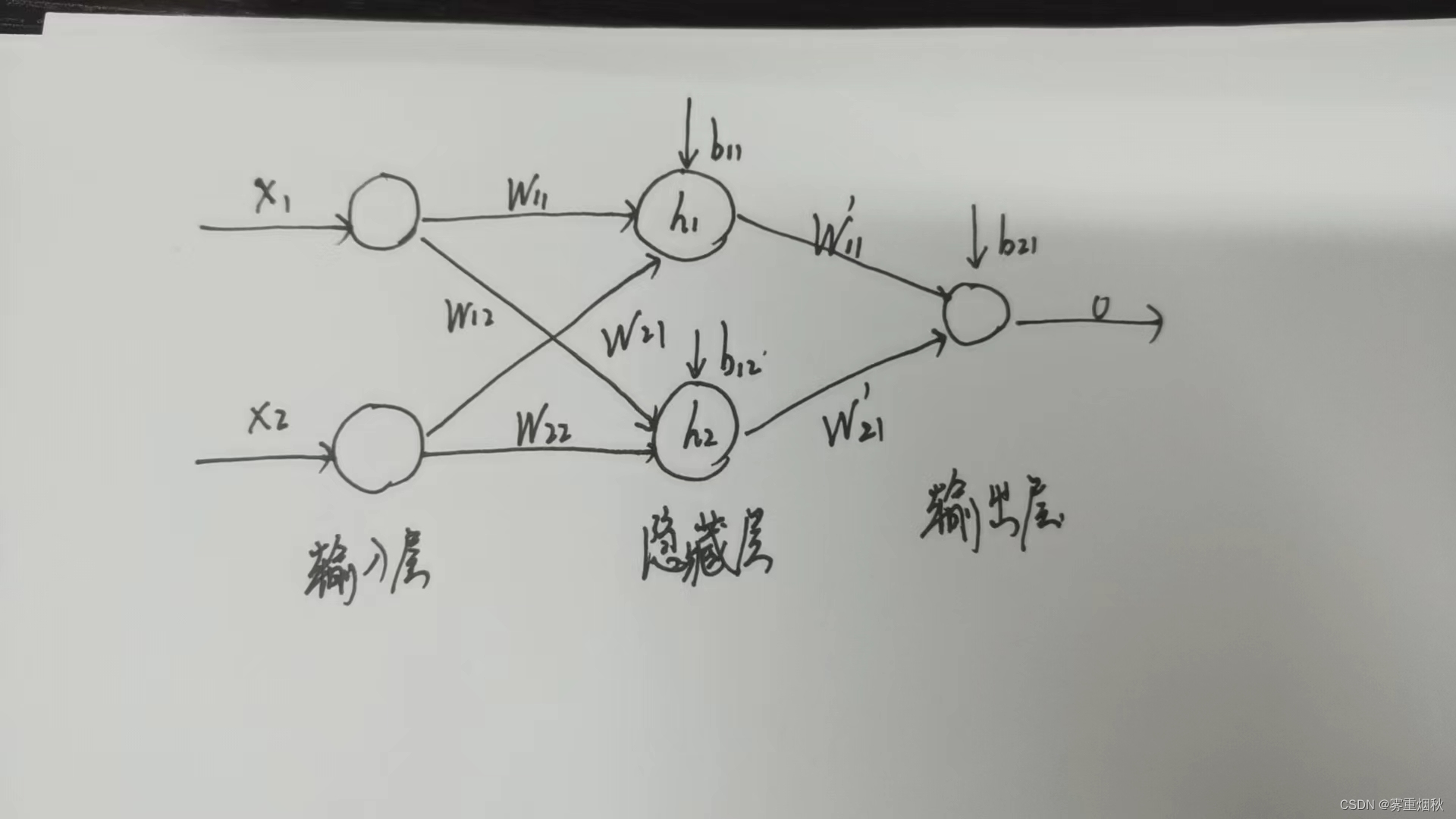
代码实现如下:
import torch
from torch import nn
class XOR(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(2, 2)
self.linear2 = nn.Linear(2, 1)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.sigmoid(x)
return x
model = XOR()
learning_rate = 0.1
epochs = 1000
loss_function = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
input = torch.tensor([[0, 0], [0, 1.0], [1, 0], [1, 1]])
target = torch.tensor([[0], [1], [1.0], [0]])
for epoch in range(epochs):
optimizer.zero_grad()
output = model(input)
loss = loss_function(output, target)
loss.backward()
optimizer.step()
input_test = input
output_test = model(input_test)
print("input_x", input_test.flatten())
print("output_y", [(lambda x: 1 if x > 0.5 else 0)(x) for x in output_test])
结果为:
input_x tensor([0., 0., 0., 1., 1., 0., 1., 1.])
output_y [0, 1, 1, 0]
在写代码过程中,发现如果输出层用ReLU激活函数,那么大概率会出错,用Sigmoid函数可以确保百分百的正确率。

比如说在权重更新的时候,在某个神经元上的所有样本的输出全部都是负数,那么因为用的是ReLU,梯度为0,所以此处的权重再也不能更新了,成了死亡神经元,解决可以用带泄露的ReLU、带参数的ReLU、ELU函数和Softplus函数等。

偏置
b
\bm b
b对函数来说是平移,对输入的改变是不敏感的,因为相对于
ω
\bm \omega
ω,偏置训练准确需要的数据很少,weight指定了两个变量的关系,而bias只控制一个变量,如果对bias进行正则化,对于控制过拟合的作用是有限的,而对weight进行正则化可以防止某些参数过大导致过拟合。

如果全都设为0,那么第一遍前向计算过程中所有隐藏层神经元的激活值都相同,反向传播时参数更新也一样,相当于隐藏层只有一个神经元,没有区分性,这种现象称为对称权重现象。

可以通过增加学习率缓解梯度消失问题,但是不能解决梯度消失,梯度消失是指梯度在最后一层往前传的过程中不断减小,直至为0,如果学习率变大,那么梯度会放大,相对来说可能变大了,但是如果学习率过大,和最开始的较大的导数相乘,就会导致梯度爆炸,因此不论学习率大或小,都有可能出现梯度消失或爆炸的问题。









![[学习笔记]知乎文章-PyTorch的Transformer](https://img-blog.csdnimg.cn/direct/345499481ba8421791f8bb6a9e2ed31d.png)

