小伙伴们大家好,本片文章将会讲解 用哈希桶封装 unordered_map & unordered_set 的相关内容。
如果看到最后您觉得这篇文章写得不错,有所收获,麻烦点赞👍、收藏🌟、留下评论📝。您的支持是我最大的动力,让我们一起努力,共同成长!
🎉系列文章: 1. 闭散列的线性探测实现哈希表
🎉系列文章: 2. 开散列的哈希桶实现哈希表
文章目录
- `0. 前言`
- `1. K模型和KV模型模板参数传递`
- ==<font color = blue><b>🎧1.0 相关解释🎧==
- ==<font color = blue><b>🎧1.1 模板参数传递思路🎧==
- ==<font color = blue><b>🎧1.2 模板参数传递图解🎧==
- `2. 哈希表中函数的修改`
- ==<font color = blue><b>🎧2.1 Insert函数修改思路🎧==
- ==<font color = blue><b>🎧2.2 Insert函数修改后的代码🎧==
- ==<font color = blue><b>🎧2.3 Find & Erase 函数的修改🎧==
- ==<font color = blue><b>🎧2.4 Find & Erase 修改后的代码🎧==
- `3. 哈希表迭代器的实现`
- ==<font color = blue><b> 🎧3.1 operator++() 的实现🎧==
- ==<font color = blue><b> 🎧3.2 operator*() & operator->() 的实现🎧==
- ==<font color = blue><b> 🎧3.3 operator!=()的实现🎧==
- ==<font color = blue><b> 🎧3.4 Begin() & End()的实现==
- `4. const迭代器的实现`
- `4. unordered_map的operator[]的实现`
- ==<font color = blue><b> 🎧4.1 Find()的修改==
- ==<font color = blue><b> 🎧4.2 Insert()的修改==
- ==<font color = blue><b> 🎧4.3 operator[]的实现==
- `5. 哈希桶封装的完整代码`
0. 前言
在之前的文章中我们详细描述了如何用 开放寻址法(闭散列)的线性探测 和 开散列的哈希桶 的方法来实现哈希表。此篇文章我们将用 哈希桶 来实现 unordered_map & unordered_set 的封装。
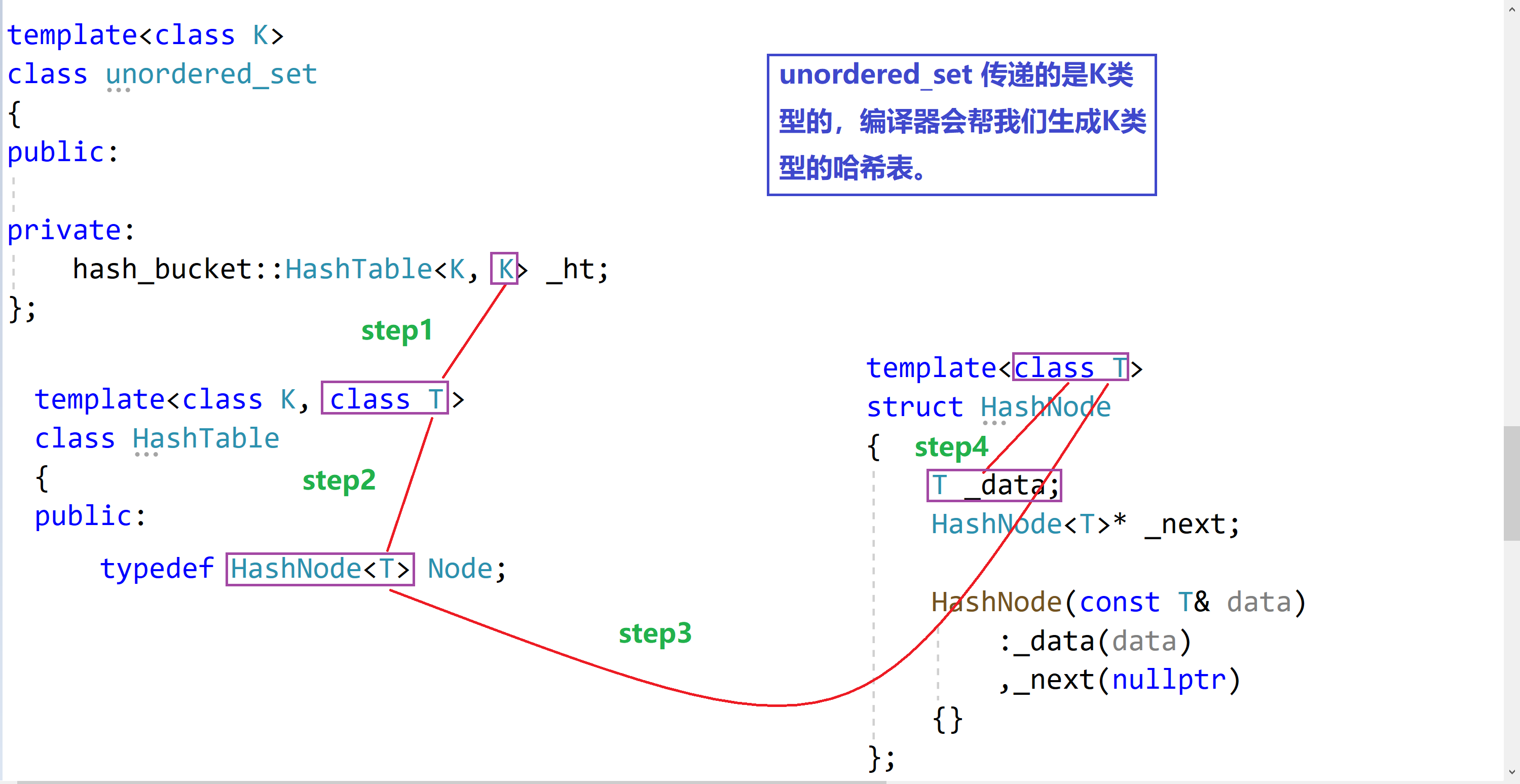
1. K模型和KV模型模板参数传递
🎧1.0 相关解释🎧
由于unordered_map和unordered_set的分别是 KV 类型和 K 类型,存储的数据类型是不相同的, 但是底层的哈希桶只有一份,这个时候我们得想到用模板的方法来解决此问题。(这块类似于红黑树那的封装)
🎧1.1 模板参数传递思路🎧
- 我们用哈希表来实现
unordered_map和unordered_set,因此他们两个的成员变量就是用哈希桶实现出的哈希表的对象; - 哈希表的前两个模板参数是
K和V(Key: 关键字和Value: 值),但是我们不能这样传递,我们可以将第二个参数改为T(Type: 类型):- 这个
T是我们在上一层:unordered_map和unordered_set进行传递的; - 如果是
unordered_map传递的就是KV类型的pair; - 如果是
unordered_set传递的就是K类型。
- 这个
- 由于哈希表中还封装了哈希节点,这个哈希节点的模板参数一开始传递的也是两个:
K和V(Key: 关键字和Value: 值),我们此时就将两个模板参数换为一个T(Type: 类型)。
🎧1.2 模板参数传递图解🎧
unordered_map模板参数的传递图示:

unordered_set模板参数的传递图示:
2. 哈希表中函数的修改
由于传递的模板参数改变了,所以我们对应的函数实现也要发生改变。
🎧2.1 Insert函数修改思路🎧
Inert函数的修改
- 起初给
Insert()函数传递的参数类型是const pair<K, V>& kv, 现在传递的参数类型是const T& data。 - 当
unordered_set调用Insert(),传入的参数是 K K K 类型( T T T 会被实例化成 K K K),当unordered_map调用Insert(),传入的参数类型是 K V KV KV 类型( T T T 会被实例化成pair<K, V>); - 那么问题就来了,对于
K
K
K 类型插入数据时要对
key使用哈希函数,对于 K V KV KV 类型的pair,比对pair的第一个参数使用哈希函数,因此我们要用仿函数来取出对应的值。
仿函数逻辑
- 我们要在哈希表的模板参数中 增加一个仿函数的模板参数
KeyOfT,并在两个容器的成员变量中传入对应的仿函数。 - 对于
unordered_map的仿函数,我们要的就是key,因此直接返回 K K K 类型的变量即可; - 对于
unordered_map的仿函数,我们要的是pair的第一个参数,所以要返回传入的参数的第一个参数。
关于哈希函数
之前的文章讲过,对于不同类型的数据,我们要采用相应的哈希函数,使其在整数范围内有唯一的映射。尤其是对于字符串类型string,我们经常使用,还采用了模板的特化。
这一操作(模板特化、模板缺省参数的传递)我们是在哈希表的实现中完成的。
但是由于我们要对哈希表进行封装,对外暴露的就是unordered_set 和 unordered_map,要把以上的操作放在此层。
🎧2.2 Insert函数修改后的代码🎧
unordered_set的仿函数代码:
template<class K>
struct setKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
unordered_map的仿函数代码:
template<class K, class V>
struct mapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
Insert的修改代码:
bool Insert(const T& data)
{
// 定义哈希函数对象
HashFunc hf;
// 定义取值的对象
KeyOfT kot;
if (Find(kot(data)))
{
return false;
}
// 判断负载因子扩容
// 负载因子为1扩容
if (_n == _tables.size())
{
vector<Node*> newtable;
size_t newsize = 2 * _tables.size();
newtable.resize(newsize, nullptr);
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
Node* next = nullptr;
while (cur)
{
next = cur->_next;
// 先取出对应的Key值,然后用哈希函数映射到相应的整数
size_t hashi = hf(kot(cur->_data)) % newtable.size();
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtable);
}
// 先取出对应的Key值,然后用哈希函数映射到相应的整数
size_t hashi = hf(kot(data)) % _tables.size();
Node* newnode = new Node(data);
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}
🎧2.3 Find & Erase 函数的修改🎧
Find & Erase 函数的修改
- 由于
Find函数和Erase函数传递参数的时候就是Key,因此在函数内部的代码逻辑无需进行修改。 - 这同样体现了哈希表的第一个模板参数 K K K 的作用,如果只有第二个模板参数,那么将无法进行查询。
🎧2.4 Find & Erase 修改后的代码🎧
Find代码:
Node* Find(const K& key)
{
HashFunc hf;
size_t hashi = hf(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return cur;
}
else
{
cur = cur->_next;
}
}
return nullptr;
}
Erase代码:
bool Erase(const K& key)
{
HashFunc hf;
size_t hashi = hf(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
3. 哈希表迭代器的实现
如果用 原生指针的解引用、加加、箭头等 操作无法满足哈希表的相关操作,因此要对 节点指针进行封装,并采用运算符重载 来实现迭代器的相关操作。
🎧3.1 operator++() 的实现🎧
operator++() 实现思路
- 假设当前所在的节点为
cur,当前所在的哈希桶为i; - 如果当前节点不为空,加加到下一个节点;
- 如果当前节点为空,那么就要去下一个不为空的桶中寻找,问题就来了,如何寻找下一个桶呢?
- 因为要找到下一个桶,并且要访问桶中的元素,因此要把 哈希表的指针传到迭代器的类中;
- 之后,判断下个位置的指针是否为空,如果不为空,就让
_node == _node->next; - 如果为空,就寻找下一个不为空的桶:
- 先利用当前指针计算出当前位置所在的桶;
- 向后寻找不为空的桶,如果找到了,就让
cur = _tables[i],直到走到空为止,不然继续找下一个不为空的节点; - 如果一直到
i = _tables.size(),还没有找到不为空的节点,证明已经访问完毕,那么_node = nullptr。
- 最后返回此迭代器类型的对象
return *this;
operator()++代码:
__HashIterator<K, T, KeyOfT, HashFunc> operator++()
{
KeyOfT kot;
Node* cur = _node;
// 判断下个位置的指针是否为空,如果不为空,就让`_node == _node->next`
if (_node->_next)
{
_node = _node->_next;
}
else
{
// 先利用当前指针计算出当前位置所在的桶
size_t hashi = kot(cur->_data) % _pht->_tables.size();
// 向后寻找不为空的桶,如果找到了,
// 就让`cur = _tables[i]`,直到走到空为止,不然继续找下一个不为空的节点;
++hashi;
for (; hashi < _pht->_tables.size(); ++hashi)
{
if (_pht->_tables[hashi])
{
cur = _pht->_tables[hashi];
break;
}
}
// 出循环有两种情况,一种是找到了不为空的节点,一种是直到走到最后都没有找到不为空的节点,两种情况分别判断以下。
// 如果走到最后还未找到,就让_node = nullptr;
if (hashi == _pht->_tables.size())
{
_node = nullptr;
}
// 如果找到不为空的节点就让_node = cur;
else
{
_node = cur;
}
}
return *this;
}
🎧3.2 operator*() & operator->() 的实现🎧
operator*() 实现思路
- 返回
_node->_data即可。
operator->() 实现思路
- 返回
&_node->_data即可。- 这里在
unordered_set底层调用的时候实际上是用了两次->; - 一次是调用
operator->()的运算符重载,访问到了pair的地址; - 然后再用
->对pair进行解引用访问到它的first和second; - 但是编译器做了优化直接写一个
->即可。
- 这里在
operator*() & operator->()的代码:
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
🎧3.3 operator!=()的实现🎧
operator!=() 实现思路
- 判断两个
_node的地址是否相同即可:_node != h._node。
operator!=() 的代码:
bool operator!=(const __HashIterator<K, T, KeyOfT, HashFunc>& h)
{
return _node != h._node;
}
🎧3.4 Begin() & End()的实现
Begin()的实现思路
- 开始节点就是第一个不为空的桶中存放的节点:
- 我们先定义一个节点
cur,让他向后寻找到第一个不为空的位置。 - 找到了返回迭代器类型的数据,由于迭代器的构造函数是两个,要传两个参数,第一个是
cur指针,第二个是this指针:return Iterator(cur, this)- 因为迭代器中需要的是哈希表类型的指针,而
this就是能代表此哈希表类型的指针,所以用this即可。
- 因为迭代器中需要的是哈希表类型的指针,而
- 我们先定义一个节点
- 如果找不到为空的节点返回迭代器构造的
nullptr:return Iterator(nullptr, this)
End()的实现思路
- 返回迭代器构造的
nullptr:return Iterator(nullptr, this);
Begin() & End()的代码:
Iterator Begin()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
{
return Iterator(cur, this);
}
}
return End();
}
Iterator End()
{
return Iterator(nullptr, this);
}
4. const迭代器的实现
const迭代器也是借用了模板的功能,只是解引用和箭头的返回值不同。
const迭代器的实现思路:
- 首先要给迭代器的模板加两个参数
Ref和Ptr,代表传入的T类型的引用和指针; - 改变
operator*() & operator->()的返回值,分别是:Ref和Ptr - 在哈希表类中增加
const类型的Begin() & End(); - 这里有三个问题:
__HashIterator中有一个HashTable的对象,所以要在__HashIterator前先声明一下HashTable,不然会报错。- 由于
_tables是HashTable类中的private成员变量,因此要在HashTable增加__HashIterator的友元声明。 - 🔎这两个问题都可以用内部类来解决,因为内部类是是外部类的友元,但是C++不太喜欢用内部类,博主这里就不用内部类实现了,而且内部类实现的方法也相对简单。🔍
- 由于迭代器中有
HashTable*类型的指针,而普通迭代器的指针类型就是HashTable*,而const迭代器的指针类型是const HashTable*,我们知道权限只能缩小,不能放大,因此要把__HashIterator中的HashTable*的成员变量一直修改为const HashTable*。
完整的迭代器的相关代码:
// 先声明
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable;
template<class K, class T, class KeyOfT, class HashFunc, class Ref, class Ptr>
class __HashIterator
{
public:
typedef HashNode<T> Node;
typedef __HashIterator<K, T, KeyOfT, HashFunc, Ref, Ptr> Self;
__HashIterator(Node* node, const HashTable<K, T, KeyOfT, HashFunc>* pht)
:_node(node)
,_pht(pht)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self operator++()
{
KeyOfT kot;
Node* cur = _node;
if (_node->_next)
{
_node = _node->_next;
}
else
{
size_t hashi = kot(cur->_data) % _pht->_tables.size();
++hashi;
for (; hashi < _pht->_tables.size(); ++hashi)
{
if (_pht->_tables[hashi])
{
cur = _pht->_tables[hashi];
break;
}
}
if (hashi == _pht->_tables.size())
{
_node = nullptr;
}
else
{
_node = cur;
}
}
return *this;
}
bool operator!=(const Self& h)
{
return _node != h._node;
}
private:
Node* _node;
const HashTable<K, T, KeyOfT, HashFunc>* _pht;
};
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable
{
public:
typedef typename __HashIterator<K, T, KeyOfT, HashFunc, T&, T*> Iterator;
typedef typename __HashIterator<K, T, KeyOfT, HashFunc, const T&, const T*> Const_Iterator;
typedef HashNode<T> Node;
// 友元声明
friend __HashIterator<K, T, KeyOfT, HashFunc, T&, T*>;
friend __HashIterator<K, T, KeyOfT, HashFunc, const T&, const T*>;
Const_Iterator Begin() const
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
{
return Const_Iterator(cur, this);
}
}
return End();
}
Const_Iterator End() const
{
return Const_Iterator(nullptr, this);
}
Iterator Begin()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
if (cur)
{
return Iterator(cur, this);
}
}
return End();
}
Iterator End()
{
return Iterator(nullptr, this);
}
private:
vector<Node*> _tables;
size_t _n = 0;
};
4. unordered_map的operator[]的实现
这里 o p e r a t o r [ ] operator[ ] operator[] 的用法和红黑树那里的相同:
1. 首先不管是否存在,都执行 插入的逻辑;
- 如果存在,则返回一个
pair类型(first:对应值位置的迭代器,second:bool类型,是否插入成功,此处为false); - 如果不存在,依然返回一个
pair类型(first:新插入位置的迭代器,second:bool类型,是否插入成功,此处true)。
2. 取出 pair 的 first,也就是迭代器,根据迭代器找到它的 second,也就是 value,返回它的 value。
🎧4.1 Find()的修改
Find()的修改逻辑:
Find()原本返回的是节点类型的指针,现在要返回迭代器类型:- 迭代器类型,第一个参数还是节点类型的指针,第二个参数是
this指针 。
- 迭代器类型,第一个参数还是节点类型的指针,第二个参数是
Find() 修改后的代码:
Iterator Find(const K& key)
{
HashFunc hf;
size_t hashi = hf(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return Iterator(cur,this);
}
else
{
cur = cur->_next;
}
}
return Iterator(nullptr, this);
}
🎧4.2 Insert()的修改
Insert()的修改逻辑:
- 当对应的key值能用
Find()函数找到的时候,则返回pair类型,first是对应节点的迭代器,second是false; - 当
key找不到进行插入操作时,依然返回pair类型,first是插入节点的迭代器,second时true。
Insert 修改后的代码:
pair<Iterator, bool> Insert(const T& data)
{
HashFunc hf;
KeyOfT kot;
Iterator it = Find(kot(data));
if (it != End())
{
return make_pair(it, false);
}
// 判断负载因子扩容
// 负载因子为1扩容
if (_n == _tables.size())
{
vector<Node*> newtable;
size_t newsize = 2 * _tables.size();
newtable.resize(newsize, nullptr);
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
Node* next = nullptr;
while (cur)
{
next = cur->_next;
size_t hashi = hf(kot(cur->_data)) % newtable.size();
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtable);
}
size_t hashi = hf(kot(data)) % _tables.size();
Node* newnode = new Node(data);
// 头插
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
// 先用当前节点的指针和this指针构造迭代器类,
// 再用迭代器和bool类型构造pair
return make_pair(Iterator(_tables[hashi], this), true);
}
🎧4.3 operator[]的实现
operator[]的实现思路:
- 对于传入的
key值进行对应的插入操作,因为插入返回类型是pair,取它的first,也就是迭代器类型,取变量名为ret; - 取
ret的second,也就是value的值即可,实现思路较为简单。
operator[]的实现代码:
V& operator[](const K& k)
{
iterator ret = _ht.Insert(make_pair(k, V())).first;
return ret.operator->()->second;
}
5. 哈希桶封装的完整代码
🎧有需要的小伙伴自取哈,博主已经检测过了,无bug🎧
🎨博主gitee链接: Jason-of-carriben 哈希桶封装的完整代码