检索增强生成 (Retrieval Augmented Generation,RAG) 可将存储在外部数据库中的新鲜领域知识纳入大语言模型以增强其文本生成能力。其提供了一种将公司数据与训练期间语言模型学到的知识分开的方式,有助于我们在性能、准确性及安全隐私之间进行有效折衷。
通过本文,你将了解到英特尔如何通过企业 AI 开放平台 OPEA 开源项目帮助你开发和部署 RAG 应用。你还将通过真实的 RAG 使用案例了解英特尔 Gaudi 2 AI 加速器和至强 CPU 如何助力企业级应用性能的显著飞跃。
OPEAhttps://opea.dev
导入
在深入了解细节之前,我们先要获取硬件。英特尔 Gaudi 2 专为加速数据中心和云上的深度学习训练和推理而设计。你可在 英特尔开发者云 (IDC) 上获取其公开实例,也可在本地部署它。IDC 是尝试 Gaudi 2 的最简单方法,如果你尚没有帐户,可以考虑注册一个帐户,订阅 “Premium”,然后申请相应的访问权限。
英特尔 Gaudi 2https://habana.ai/products/gaudi2/
英特尔开发者云 (IDC)https://www.intel.com/content/www/us/en/developer/tools/devcloud/overview.html
在软件方面,我们主要使用 LangChain 来构建我们的应用。LangChain 是一个开源框架,旨在简化 LLM AI 应用的构建流程。其提供了基于模板的解决方案,允许开发人员使用自定义嵌入模型、向量数据库和 LLM 构建 RAG 应用,用户可通过 LangChain 文档获取其更多信息。英特尔一直积极为 LangChain 贡献多项优化,以助力开发者在英特尔平台上高效部署 GenAI 应用。
在 LangChain 中,我们将使用 rag-redis 模板来创建我们的 RAG 应用。选型上,我们使用 BAAI/bge-base-en-v1.5 作为嵌入模型,并使用 Redis 作为默认向量数据库。下图展示了该应用的高层架构图。
BAAI/bge-base-en-v1.5https://hf.co/BAAI/bge-base-en-v1.5
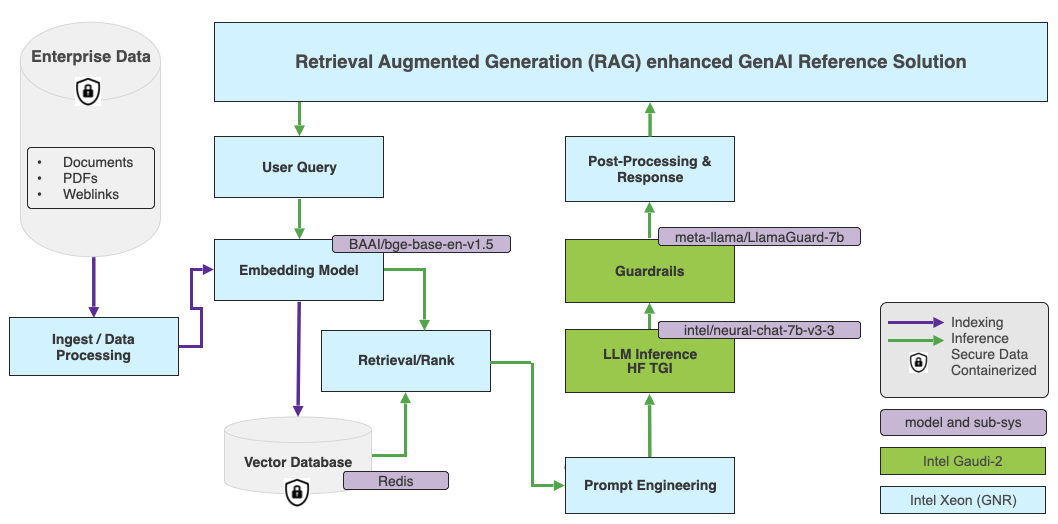
在我们的应用中,嵌入模型跑在 英特尔 Granite Rapids CPU 上。英特尔 Granite Rapids 架构专为高核数、性能敏感型工作负载以及通用计算工作负载而优化,并为此类工作负载提供最低的总拥有成本 (Cost Of Ownership,TCO)。GNR 还支持 AMX-FP16 指令集,这会为混合 AI 工作负载带来 2-3 倍的性能提升。
英特尔 Granite Rapidshttps://www.intel.com/content/www/us/en/newsroom/news/intel-unveils-future-generation-xeon.html#gs.6t3deu
我们将 LLM 跑在英特尔 Gaudi 2 加速器上。至于如何使用 Hugging Face 模型,Optimum Habana 库可将 Hugging Face Transformers 和 Diffusers 库桥接至 Gaudi 加速器。因此,用户可以用它针对各种下游任务在单卡和多卡场景下轻松进行模型加载、训练及推理。
Optimum Habanahttps://hf.co/docs/optimum/en/habana/index
Transformershttps://hf.co/docs/transformers/index
Diffusershttps://hf.co/docs/diffusers/index
我们提供了一个 Dockerfile 以简化 LangChain 开发环境的配置。启动 Docker 容器后,你就可以开始在 Docker 环境中构建向量数据库、RAG 流水线以及 LangChain 应用。详细的分步说明,请参照 ChatQnA 示例。
Dockerfilehttps://github.com/opea-project/GenAIExamples/tree/main/ChatQnA/langchain/docker
ChatQnAhttps://github.com/opea-project/GenAIExamples/tree/main/ChatQnA
创建向量数据库
我们用耐克的公开财务文件创建一个向量数据库,示例代码如下:
# Ingest PDF files that contain Edgar 10k filings data for Nike.
company_name = "Nike"
data_path = "data"
doc_path = [os.path.join(data_path, file) for file in os.listdir(data_path)][0]
content = pdf_loader(doc_path)
chunks = text_splitter.split_text(content)
# Create vectorstore
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
_ = Redis.from_texts(
texts=[f"Company: {company_name}. " + chunk for chunk in chunks],
embedding=embedder,
index_name=INDEX_NAME,
index_schema=INDEX_SCHEMA,
redis_url=REDIS_URL,
)定义 RAG 流水线
在 LangChain 中,我们使用 Chain API 来连接提示、向量数据库以及嵌入模型。
你可在 该代码库 中找到完整代码。
该代码库https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/langchain/redis/rag_redis/chain.py
# Embedding model running on Xeon CPU
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
# Redis vector database
vectorstore = Redis.from_existing_index(
embedding=embedder, index_name=INDEX_NAME, schema=INDEX_SCHEMA, redis_url=REDIS_URL
)
# Retriever
retriever = vectorstore.as_retriever(search_type="mmr")
# Prompt template
template = """…"""
prompt = ChatPromptTemplate.from_template(template)
# Hugging Face LLM running on Gaudi 2
model = HuggingFaceEndpoint(endpoint_url=TGI_LLM_ENDPOINT, …)
# RAG chain
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()}) | prompt | model | StrOutputParser()
).with_types(input_type=Question)在 Gaudi 2 上加载 LLM
我们在 Gaudi2 上使用 Hugging Face 文本生成推理 (TGI) 服务运行聊天模型。TGI 让我们可以在 Gaudi2 硬件上针对流行的开源 LLM (如 MPT、Llama 以及 Mistral) 实现高性能的文本生成。
无需任何配置,我们可以直接使用预先构建的 Docker 映像并把模型名称 (如 Intel NeuralChat) 传给它。
model=Intel/neural-chat-7b-v3-3
volume=$PWD/data
docker run -p 8080:80 -v $volume:/data --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --ipc=host tgi_gaudi --model-id $modelTGI 默认使用单张 Gaudi 加速卡。如需使用多张卡以运行更大的模型 (如 70B),可添加相应的参数,如 --sharded true 以及 --num_shard 8 。对于受限访问的模型,如 Llama 或 StarCoder,你还需要指定 -e HUGGING_FACE_HUB_TOKEN= <kbd> 以使用你自己的 Hugging Face 令牌 获取模型。
Llamahttps://hf.co/meta-llama
StarCoderhttps://hf.co/bigcode/starcoder
Hugging Face 令牌https://hf.co/docs/hub/en/security-tokens
容器启动后,我们可以通过向 TGI 终端发送请求以检查服务是否正常。
curl localhost:8080/generate -X POST \
-d '{"inputs":"Which NFL team won the Super Bowl in the 2010 season?", \
"parameters":{"max_new_tokens":128, "do_sample": true}}' \
-H 'Content-Type: application/json'如果你能收到生成的响应,则 LLM 运行正确。从现在开始,你就可以在 Gaudi2 上尽情享受高性能推理了!
TGI Gaudi 容器默认使用 bfloat16 数据类型。为获得更高的吞吐量,你可能需要启用 FP8 量化。根据我们的测试结果,与 BF16 相比,FP8 量化会带来 1.8 倍的吞吐量提升。FP8 相关说明可在 README 文件中找到。
READMEhttps://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md
最后,你还可以使用 Meta Llama Guard 模型对生成的内容进行审核。OPEA 的 README 文件提供了在 TGI Gaudi 上部署 Llama Guard 的说明。
Llama Guardhttps://hf.co/meta-llama/LlamaGuard-7b
READMEhttps://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md
运行 RAG 服务
我们运行下述命令启动 RAG 应用后端服务, server.py 脚本是用 fastAPI 实现的服务终端。
docker exec -it qna-rag-redis-server bash
nohup python app/server.py &默认情况下,TGI Gaudi 终端运行在本地主机的 8080 端口上 (即 http://127.0.0.1:8080 )。如果需将其运行至不同的地址或端口,可通过设置 TGI_ENDPOINT 环境变量来达成。
启动 RAG GUI
运行以下命令以安装前端 GUI 组件:
sudo apt-get install npm && \
npm install -g n && \
n stable && \
hash -r && \
npm install -g npm@latest然后,更新 .env 文件中的 DOC_BASE_URL 环境变量,将本地主机 IP 地址 ( 127.0.0.1 ) 替换为运行 GUI 的服务器的实际 IP 地址。
接着,运行以下命令以安装所需的软件依赖:
npm install最后,使用以下命令启动 GUI 服务:
nohup npm run dev &上述命令会运行前端服务并启动应用。
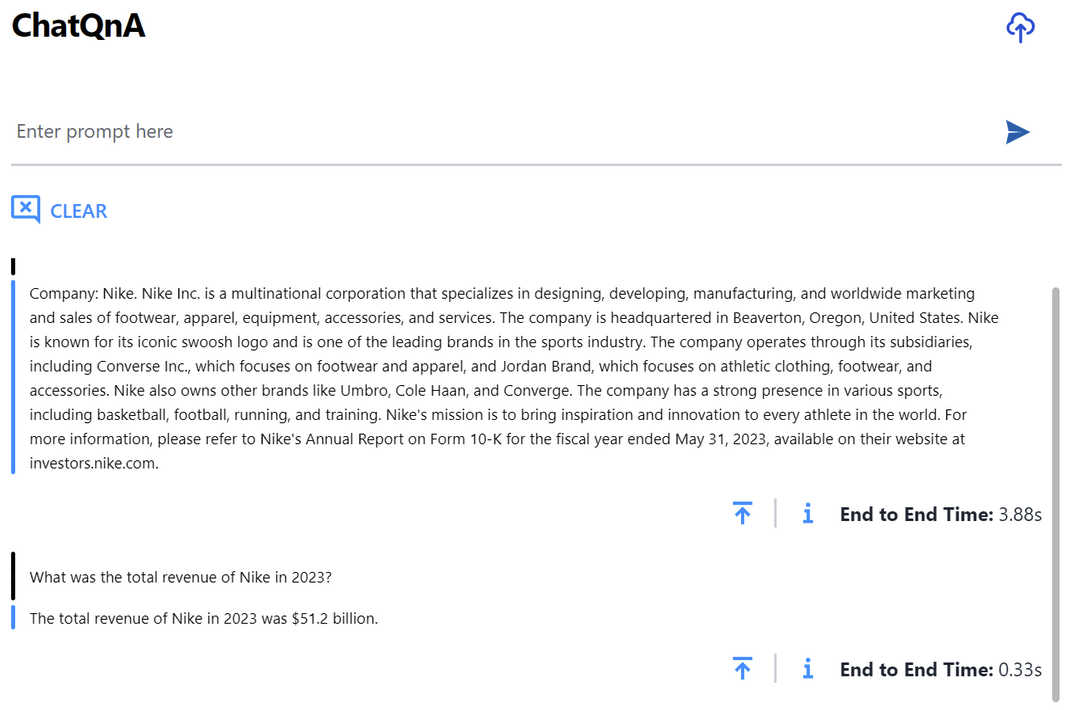
基准测试结果
我们针对不同的模型和配置进行了深入的实验。下面两张图展示了 Llama2-70B 模型在四卡英特尔 Gaudi 2 和四卡英伟达 H100 平台上,面对 16 个并发用户时的相对端到端吞吐量和性价比对比。
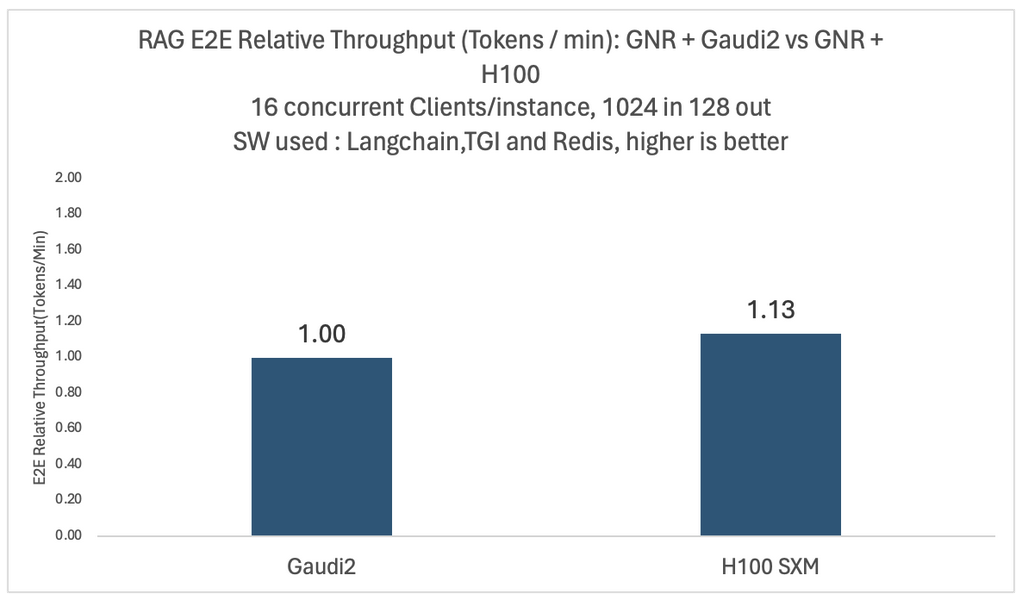
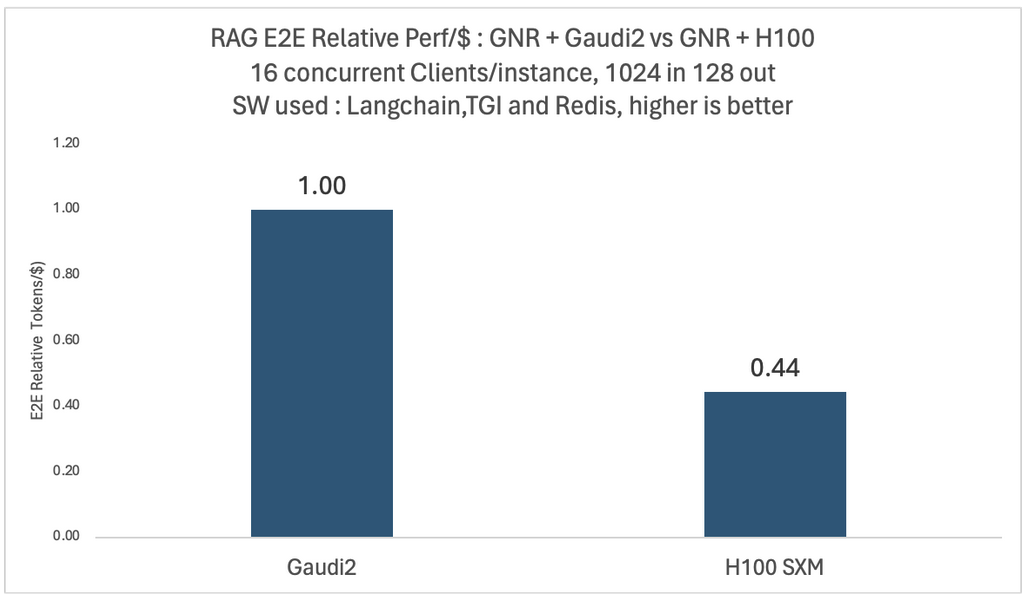
在这两种测例中,向量数据库和嵌入模型都运行在相同的英特尔 Granite Rapids CPU 平台上。为了比较每美元的性能,我们使用了与 MosaicML 团队于 2024 年 1 月使用的数据相同的公开定价数据来计算每美元的平均训练性能。
MosaicMLhttps://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators
如你所见,与 Gaudi 2 相比,基于 H100 的系统虽然吞吐量提高了 1.13 倍,但每美元性能仅为 0.44 倍。这些比较可能会因云厂商不同以及客户折扣不同而有所不同,我们在文末列出了详细的基准配置。
总结
上例成功演示了如何在英特尔平台上部署基于 RAG 的聊天机器人。此外,英特尔会不断发布成熟的 GenAI 示例,以期通过这些经过验证的工具助力开发人员简化创建、部署流程。这些示例功能多样且易于定制,非常适合用户基于其在英特尔平台上开发各种应用。
运行企业级 AI 应用时,基于英特尔 Granite Rapids CPU 和 Gaudi 2 加速器的系统的总拥有成本更低。另外,还可通过 FP8 优化进一步优化成本。
以下开发者资源应该可以帮助大家更平滑地启动 GenAI 项目。
OPEA GenAI 示例https://github.com/opea-project/GenAIExamples
基于 Gaudi 2 的 TGIhttps://github.com/huggingface/tgi-gaudi
英特尔 AI 生态之 Hugging Facehttps://www.intel.com/content/www/us/en/developer/ecosystem/hugging-face.html
Hugging Face hub 英特尔页https://hf.co/Intel
如果你有任何问题或反馈,我们很乐意在 Hugging Face 论坛 上与你互动。感谢垂阅!
Hugging Face 论坛https://discuss.huggingface.co/
致谢:
我们要感谢 Chaitanya Khened、Suyue Chen、Mikolaj Zyczynski、Wenjiao Yue、Wenxin Zhu、Letong Han、Sihan Chen、Hanwen Cheng、Yuan Wu 和 Yi Wang 对在英特尔 Gaudi 2 上构建企业级 RAG 系统做出的杰出贡献。
基准测试配置
Gaudi2 配置: HLS-Gaudi2 配备 8 张 Habana Gaudi2 HL-225H 夹层卡及 2 个英特尔至强铂金 8380 CPU@2.30GHz,以及 1TB 系统内存; 操作系统: Ubuntu 22.04.03,5.15.0 内核
H100 SXM 配置: Lambda labs 实例 gpu_8x_h100_sxm5; 8 张 H100 SXM 及 2 个英特尔至强铂金 8480 CPU@2 GHz,以及 1.8TB 系统内存; 操作系统 ubuntu 20.04.6 LTS,5.15.0 内核
Llama2 70B 部署至 4 张卡 (查询归一化至 8 卡)。Gaudi2 使用 BF16,H100 使用 FP16
嵌入模型为
BAAI/bge-base v1.5。测试环境: TGI-gaudi 1.2.1、TGI-GPU 1.4.5、Python 3.11.7、Langchain 0.1.11、sentence-transformers 2.5.1、langchain benchmarks 0.0.10、redis 5.0.2、cuda 12.2.r12.2/compiler.32965470_0, TEI 1.2.0RAG 查询最大输入长度 1024,最大输出长度 128。测试数据集: langsmith Q&A。并发客户端数 16
Gaudi2 (70B) 的 TGI 参数:
batch_bucket_size=22,prefill_batch_bucket_size=4,max_batch_prefill_tokens=5102,max_batch_total_tokens=32256,max_waiting_tokens=5,streaming=falseH100 (70B) 的 TGI 参数:
batch_bucket_size=8,prefill_batch_bucket_size=4,max_batch_prefill_tokens=4096,max_batch_total_tokens=131072,max_waiting_tokens=20,max_batch_size=128,streaming=falseTCO 参考:https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators
英文原文: https://hf.co/blog/cost-efficient-rag-applications-with-intel
原文作者: Julien Simon,Haihao Shen,Antony Vance Jeyaraj,Matrix Yao,Leon Lv,Greg Serochi,Deb Bharadwaj,Ke Ding
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。