特别说明:参考官方开源的yolov10代码、瑞芯微官方文档、地平线的官方文档,如有侵权告知删,谢谢。
模型和完整仿真测试代码,放在github上参考链接 模型和代码。
yolov8、v9还没玩热乎,这不yolov10又来了,那么部署也又来了。
1 模型和训练
老规矩,训练代码参考官方开源的yolov10代码。
2 导出 yolov10 onnx
导出onnx增加以下几行代码:
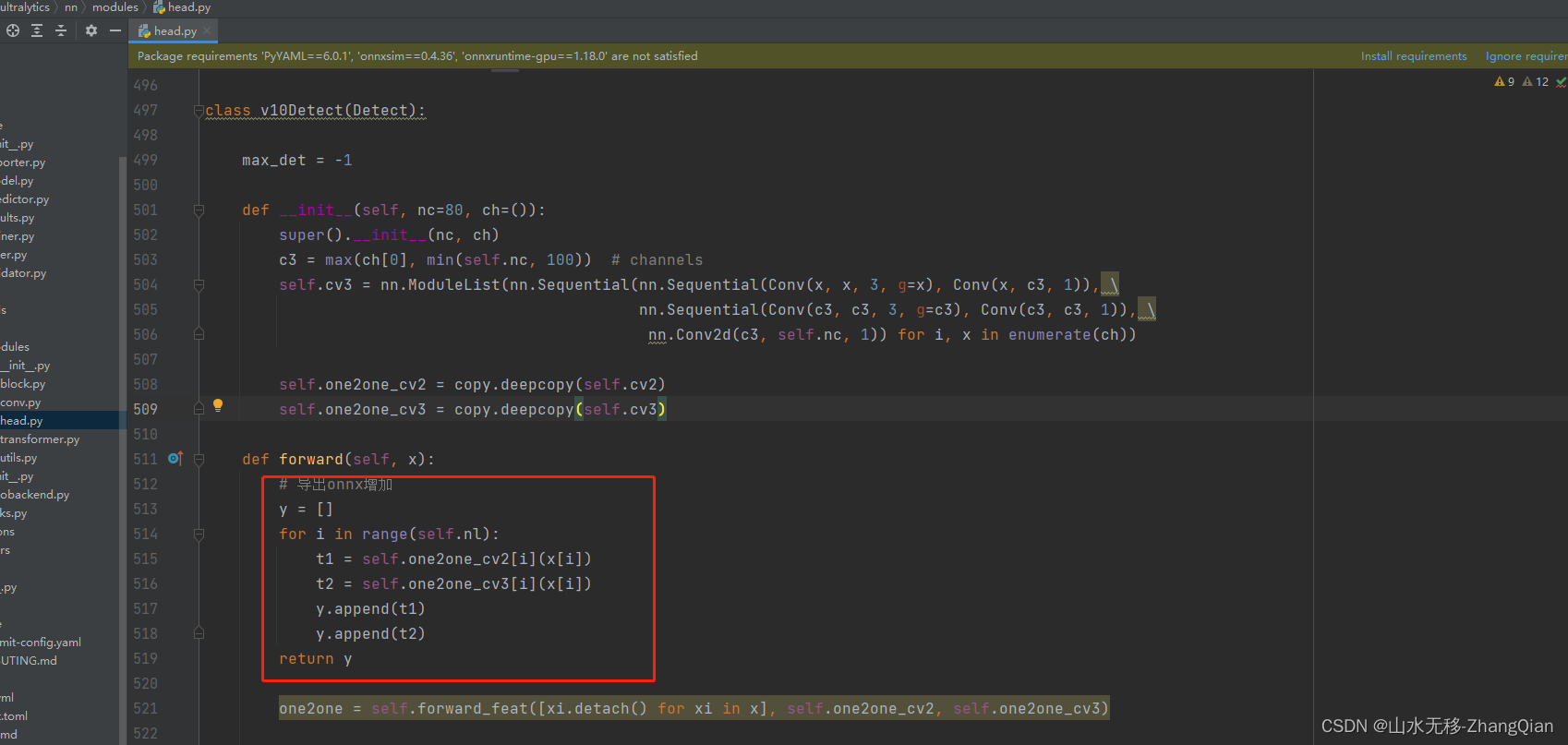
# 导出onnx增加
y = []
for i in range(self.nl):
t1 = self.one2one_cv2[i](x[i])
t2 = self.one2one_cv3[i](x[i])
y.append(t1)
y.append(t2)
return y
增加保存onnx代码:
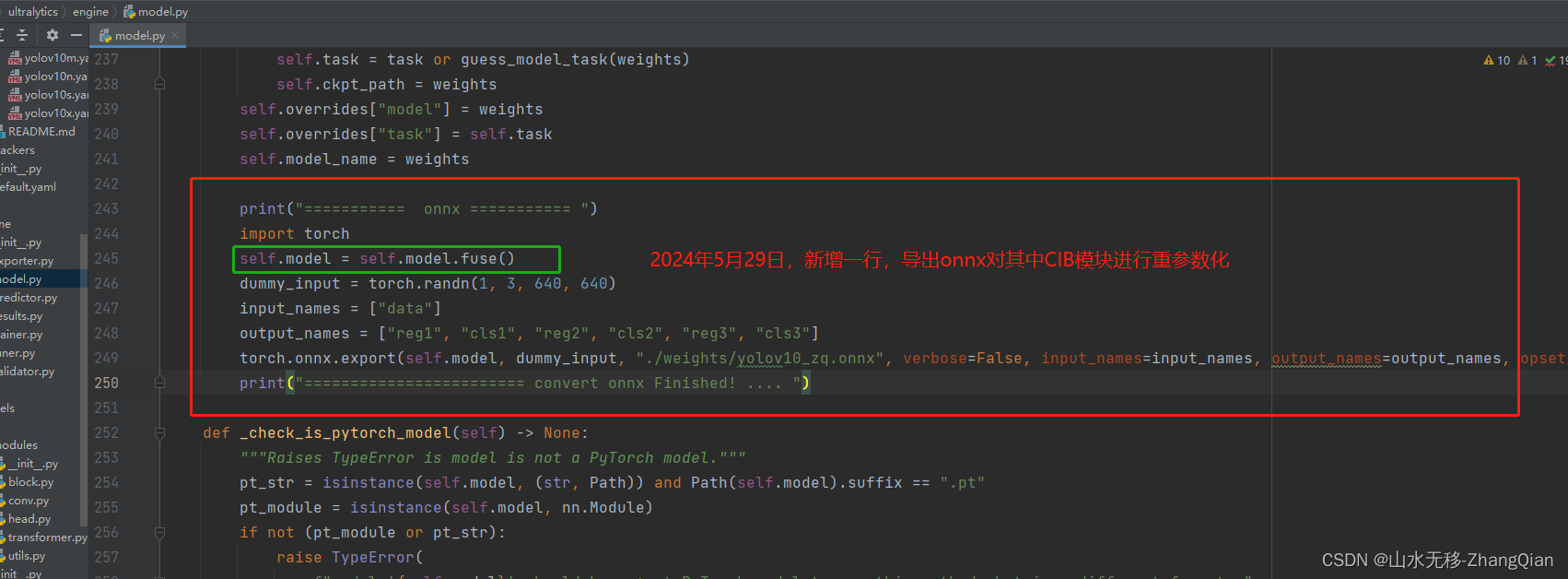
print("=========== onnx =========== ")
import torch
self.model = self.model.fuse()
dummy_input = torch.randn(1, 3, 640, 640)
input_names = ["data"]
output_names = ["reg1", "cls1", "reg2", "cls2", "reg3", "cls3"]
torch.onnx.export(self.model, dummy_input, "./weights/yolov10_zq.onnx", verbose=False, input_names=input_names, output_names=output_names, opset_version=11)
print("======================== convert onnx Finished! .... ")
修改完以上两个地方,运行推理脚本(运行会报错,但不影响onnx文件的生成)。
from ultralytics import YOLOv10
# 推理
model = YOLOv10(r'./weigths/yolov10n.pt')
results = model(task='detect', mode='predict', source='./test.jpg', line_width=3, show=True, save=True, device='cpu')
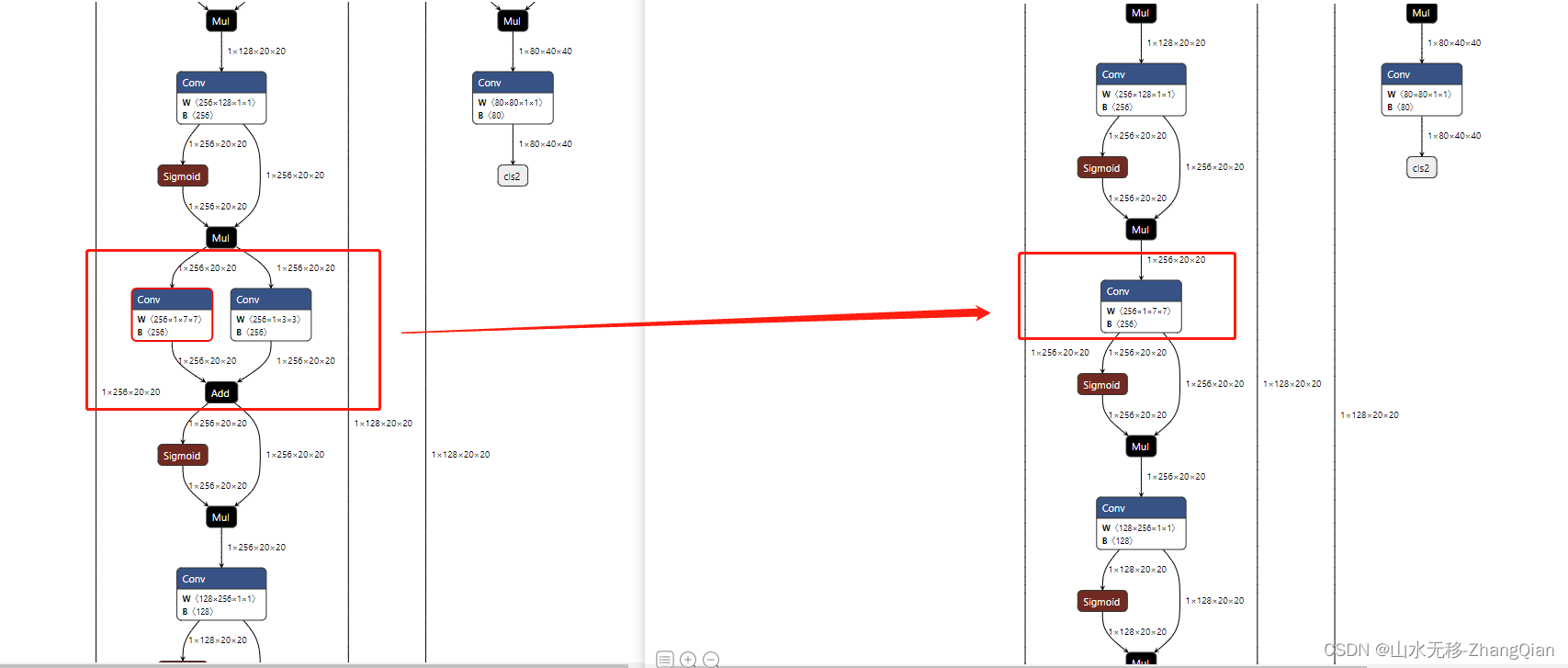
增加这一行后,对其中C2fCIB模块进行重参数化(这也是文章中一个点)



重参数化前后模型的变化
3 yolov10 onnx 测试效果
pytorch效果

onnx效果

4 时耗
模型输入640x640,检测类别80类
tensorRT 时耗(显卡 Tesla V100、cuda_11.0)
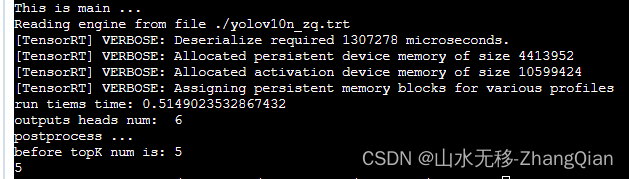
rk3588时耗

本示例用的是yolov10n,模型计算量6.7G,看到这个时耗觉得可能是有操作切换到CPU上进行计算的,查了rknn转换模型日志确实是有操作切换到CPU上进行的,对应的是模型中 PSA 模块计算 Attention 这部分操作。
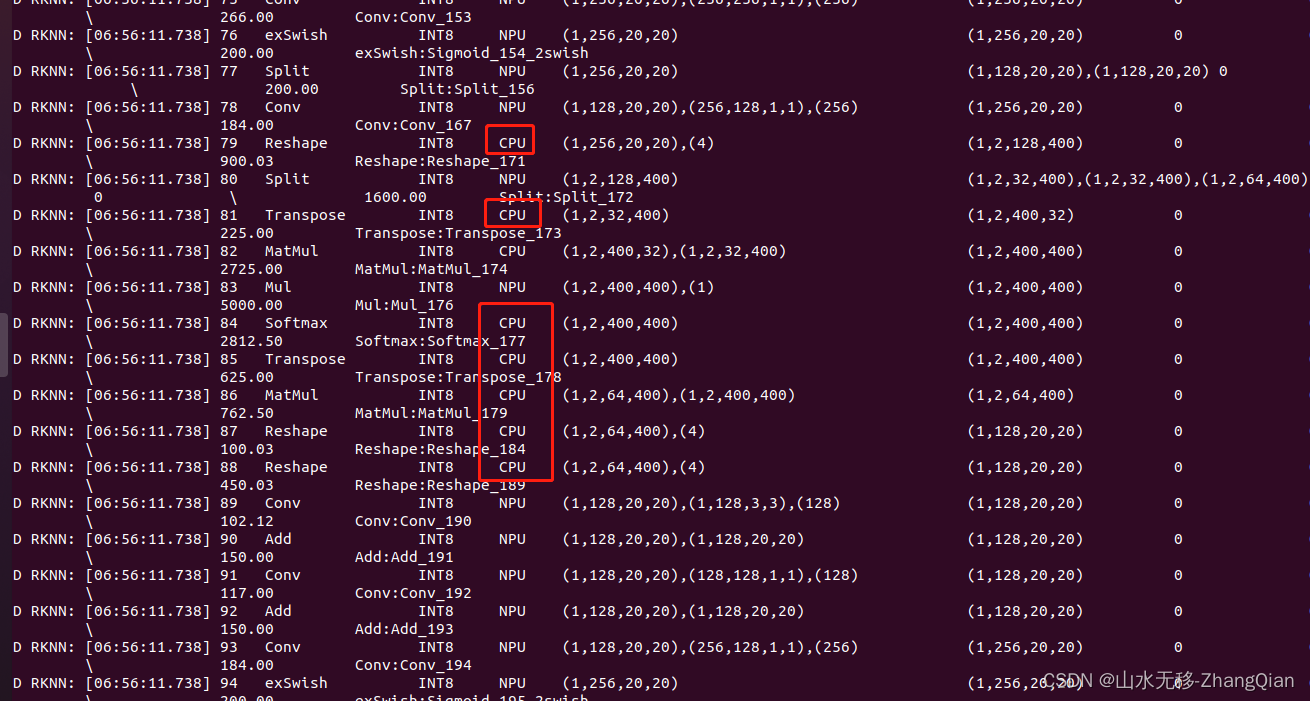
5 rknn 板端C++部署
C++完整部署代码和模型示例参考







![[leetcode hot150]第二百三十六题,二叉树的最近公共祖先](https://img-blog.csdnimg.cn/direct/2426ff478b5b4dad8b639a88bbf68263.png)