【旧文更新】基于FPGA的Verilog HDL自动售货机
文章目录
- 关于旧文新发
- FPGA
- Cortex-M架构SysTick系统定时器阻塞和非阻塞延时
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
- 大小端转换
- 什么是大端和小端
- 数据传输中的大小端
- 总结
- 大小端转换函数
- 附录:关于旧文新发
关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则:

FPGA
左边9个拨动开关是10元商品的选择器,右边9个拨动开关是15元商品的选择器,需要什么商品就上拨开关,然后商品的总钱数会显示在左边两个数码管上(例如我上拨左边2个,右边1个,数码管就应该显示为210+115=35)
左边两个按键分别为进钱5元,进钱10元,按按几下,就是进了几次对应的钱,然后将总钱数显示在中间的数码管上
右边两个按键分别为确定出货和清零,当按下确定建时,如果进钞总数大于商品所需钱数,就将剩余的钱数显示在左边的数码管上,中间数码管置零,如果钱不够,就进行LED灯的闪烁警告。
当按清零按键时,就将所有数码管置零。
代码如下:
module TCD1206(C5,C10,F,S10,S15,Y5);
//程序开始的顶层文件名和总变量
input C5, C10, F; //定义输入
output S10, S15, Y5; //定义输出
reg S10, S15, Y5; //定义寄存器类型的三种输出变量
wire s10_enable,s15_enable,s20_enable; //定义线型使能信号变量
reg [3:0] s_count; //定义6位RS计数器变量
parameter s_end = 'h5, //赋值RS使能信号的结束值
s20_begin = 'h4,
s15_begin = 'h3, //SH结束值
s10_begin = 'h2; //SH开始值 占空比1/10 周期1ms
assign s10_enable = ((s_count>=s10_begin));
//赋值RS使能信号范围
assign s15_enable = ((s_count>=s15_begin));
//赋值SH使能信号范围
assign s20_enable = ((s_count>=s20_begin));
//赋值 CR1、CR2使能信号范围
//RS信号产生部分
always@(posedge C5 or posedge C10)
//always语句块 CLK和RST上升沿有效
begin //语句块开始
if (C10) s_count<=s_count+1'b1+1'b1; //当RST信号变为高电平时 6位计数器置0
else if (s_count>=s_end -1 ) s_count <= 3'h0;
//当计数器超过最大值-1时 计数器清零
else s_count<=s_count+1'b1;
//其他范围内计数器加一位二进制的1
end //结束语句块
always@(posedge F)
begin
if (!F) S10<=1'b0,S15<=1'b0;
else if (s20_enable) Y5<= 1'b1,S15<=1'b0,s_count<=1'b0;
else if (s15_enable) S15<= 1'b1 ,s_count<=1'b0;
else if (s10_enable) S10<= 1'b1 ,s_count<=1'b0;
//当RS使能信号高电平时RS信号置1
else S10<=1'b0,S15<=1'b0,Y5<= 1'b0; //其他时候RS为0
end
endmodule //程序结束
Cortex-M架构SysTick系统定时器阻塞和非阻塞延时
首先是最常用的阻塞延时
void delay_ms(unsigned int ms)
{
SysTick->LOAD = 50000000/1000-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
while(ms--)
{
while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
}
SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
void delay_us(unsigned int us)
{
SysTick->LOAD = 50000000/1000/1000-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
while(us--)
{
while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
}
SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
50000000表示工作频率
分频后即可得到不同的延时时间
以此类推
那么 不用两个嵌套while循环 也可以写成:
void delay_ms(unsigned int ms)
{
SysTick->LOAD = 50000000/1000*ms-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
void delay_us(unsigned int us)
{
SysTick->LOAD = 50000000/1000/1000*us-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
但是这种写法有个弊端
那就是输入ms后,最大定时不得超过计数值,也就是不能超过LOAD的最大值,否则溢出以后,则无法正常工作
而LOAD如果最大是32位 也就是4294967295
晶振为50M的话 50M的计数值为1s 4294967295计数值约为85s
固最大定时时间为85s
但用嵌套while的话 最大可以支持定时4294967295*85s
如果采用非阻塞的话 直接改写第二种方法就好了:
void delay_ms(unsigned int ms)
{
SysTick->LOAD = 50000000/1000*ms-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
//while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
//SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
void delay_us(unsigned int us)
{
SysTick->LOAD = 50000000/1000/1000*us-1; // Count from 255 to 0 (256 cycles) 载入计数值 定时器从这个值开始计数
SysTick->VAL = 0; // Clear current value as well as count flag 清空计数值到达0后的标记
SysTick->CTRL = 5; // Enable SysTick timer with processor clock 使能26MHz的系统定时器
//while ((SysTick->CTRL & 0x00010000)==0);// Wait until count flag is set 等待
//SysTick->CTRL = 0; // Disable SysTick 关闭系统定时器
}
将等待和关闭定时器语句去掉
在使用时加上判断即可变为阻塞:
delay_ms(500);
while ((SysTick->CTRL & 0x00010000)==0);
SysTick->CTRL = 0;
在非阻塞状态下 可以提交定时器后 去做别的事情 然后再来等待
不过这样又有一个弊端 那就是定时器会自动重载 可能做别的事情以后 定时器跑过了 然后就要等85s才能停下
故可以通过内部定时器来进行非阻塞延时函数的编写
基本上每个mcu的内部定时器都可以配置自动重载等功能 网上资料很多 这里就不再阐述了
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
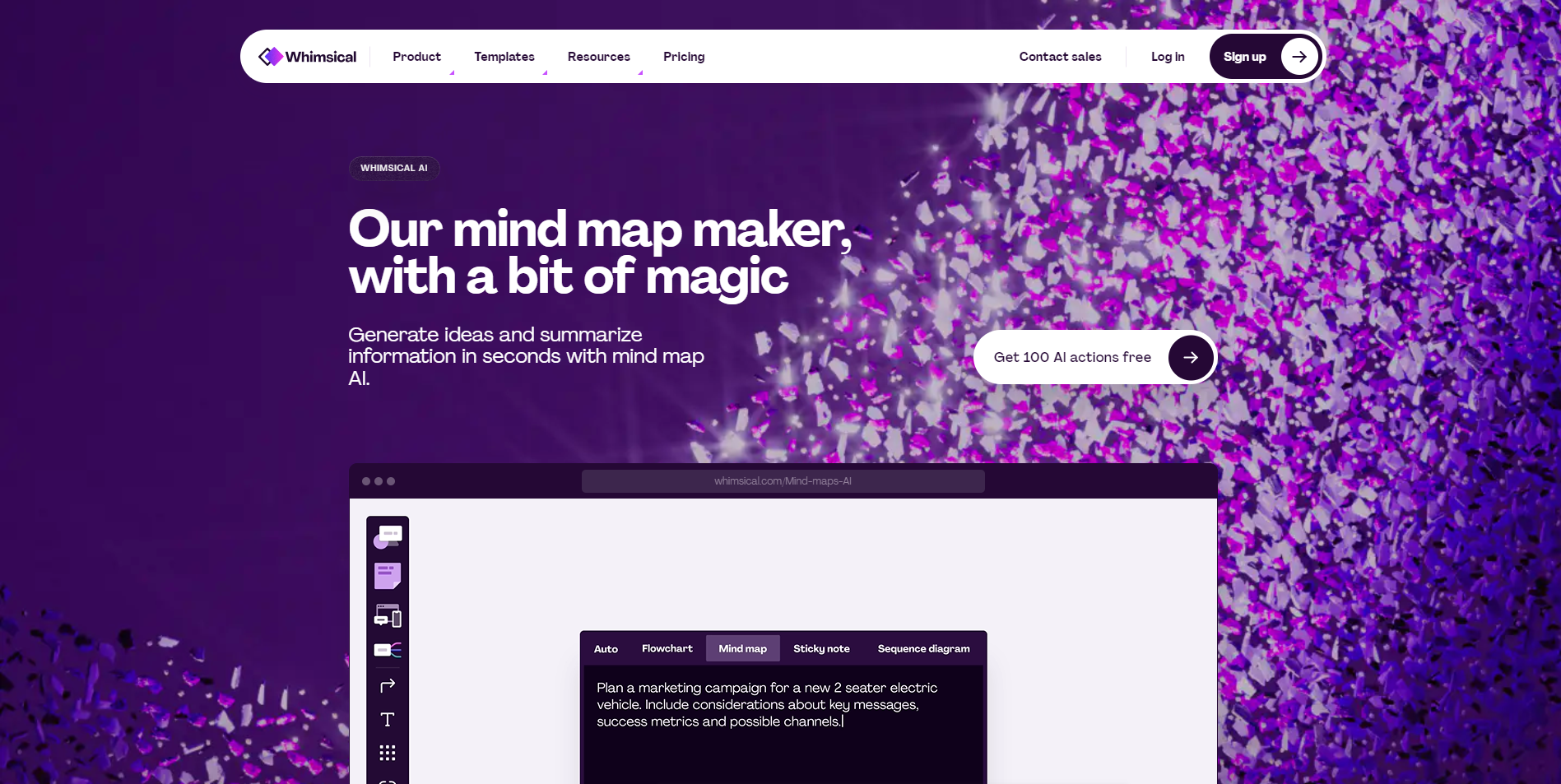
压缩Packed-ASCII字符串
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}
附录:关于旧文新发
为何要进行旧文新发?
因为我在2023年博客之星评选中发现 有的人转载、抄袭他人文章 稍微改动几下也能作为高质量文章入选
所以我将把我的旧文重新发一次 然后也这样做
2023年博客之星规则:
- 自2023年1月1日起算起,平均每周创作过至少一篇高质量且非付费专栏的原创文章即可入围。由于博客之星是年度评选,所以统计时间一直截止到2023年12月17日。
- 高质量博文为80分以上原创博文,质量分查询地址:
https://www.csdn.net/qc - 入围条件补充说明:当前的入围状态为动态,一旦未达到每周平均创作过至少一篇高质量且非付费专栏的原创文章入围资格将会跳出入围资格,若当前还未入围者通过后期创作也可入围,当下并非最终结果。


![[leetcode hot150]第二百三十六题,二叉树的最近公共祖先](https://img-blog.csdnimg.cn/direct/2426ff478b5b4dad8b639a88bbf68263.png)







![BUUCTF [GUET-CTF2019]zips 1](https://img-blog.csdnimg.cn/img_convert/b294954725b8b05cc6bf840c4bd36115.png)