HTTP与HTTPS的介绍

HTTP(Hypertext Transfer Protocol,超文本传输协议)和HTTPS(Hypertext Transfer Protocol Secure,超文本传输安全协议)都是用于在Web上传输数据的协议,但它们之间存在一些重要的差异,特别是在安全性和加密方面。
- HTTP:是不安全的,传输的数据都是未加密的明文。这意味着在传输过程中,任何在路径上的设备都可以读取或篡改数据。
- HTTPS:是安全的,通过传输加密和身份认证保证了传输过程的安全性。HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS协议负责数据的加密和解密,以及服务器身份验证和消息完整性检查。
- HTTP:不需要证书和密钥。
- HTTPS:使用SSL/TLS协议进行通信时,服务器需要提供一个证书来证明其身份。这个证书是由一个受信任的证书颁发机构(CA)签发的。同时,服务器和客户端还会协商一个会话密钥,用于后续通信的加密和解密。
HTTP协议
认识URL
我们平时说的网址就是URL:
https://mp.csdn.net/mp_blog/creation/editor/139219562?spm=1001.2014.3001.4503但是现在几乎都是更加安全的HTTPS协议。
- https://就是协议方案名。//用于协议与域名的分隔符
- mp.csdn.net就是服务器地址,也就是域名,一般通过应用层协议DNS进行域名解析成我们的IP地址。
- 还有省略的端口号,HTTP:通常默认使用80端口,HTTPS:通常默认使用443端口。
- /mp_blog/creation/editor/139219562表示的就是后端Linux服务器上的路径,但是最前面的/并不一定表示的是根目录,而是web根目录。/同时也作为域名和路径的分隔符。
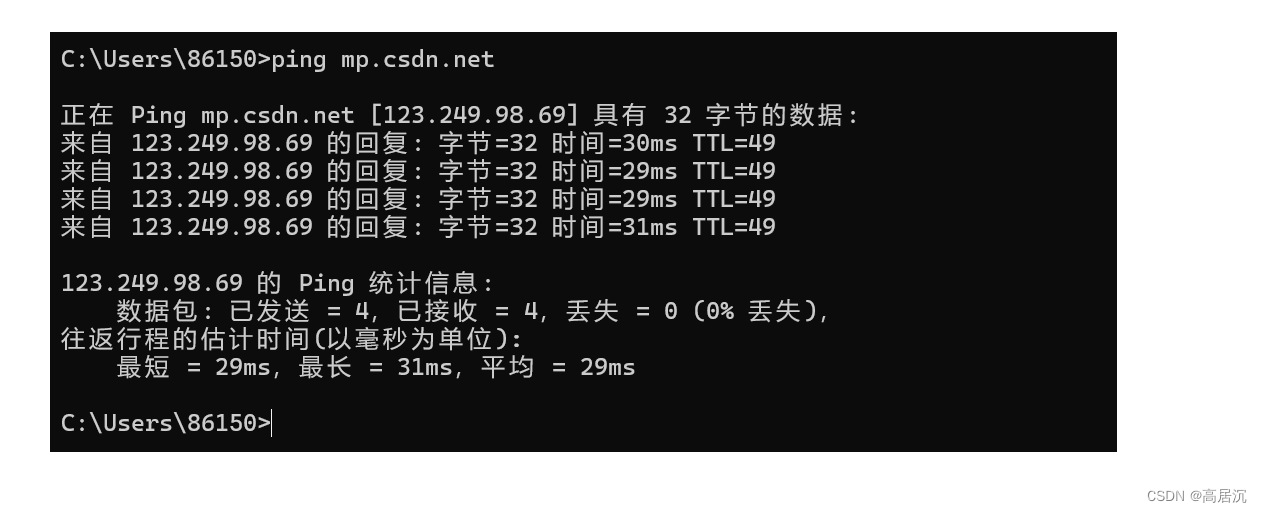
- ?spm=1001.2014.3001.4503这里?隔开,后面spm表示的是参数名,后面一串是参数的内容。如果有多组参数就用&符号作为参数间隔。
URL的编码与解码
因为我们的URL中是含有特殊的分割字符的,如:/?等这样的字符,所以URL中不能随意的出现类似于这种特殊字符,如果某个参数中需要带有这样的字符,就必须先对这些字符进行转义。
转移规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格
HTTP协议的内容
HTTP请求协议内容
POST /index.html HTTP/1.1
Host: www.example.com
Content-Length: 15
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Referer: http://www.example.com/index.html
Accept-Encoding: gzip, deflate, sdch, br
Accept-Language: en-US,en;q=0.8
Cookie: name=value; name2=value2
username=alice&password=secret第一行是请求行内容。
请求行包含三个主要部分:HTTP方法、请求资源的URL和HTTP协议版本。
第二行开始到空行是请求头。
请求头包含一系列的字段,每个字段都包含一个名字和一个值,它们之间用冒号(
:)分隔。空行后面的内容就是请求体。
请求体不是每个HTTP请求都必需的,它通常用于POST和PUT等请求中,以发送数据给服务器。请求体的格式取决于
Content-Type头字段的值。而当前请求体是一个表单数据,它包含了用户名(username)和密码(password)两个字段。每一行的数据结尾用\r\n作为换行
请求资源的URL
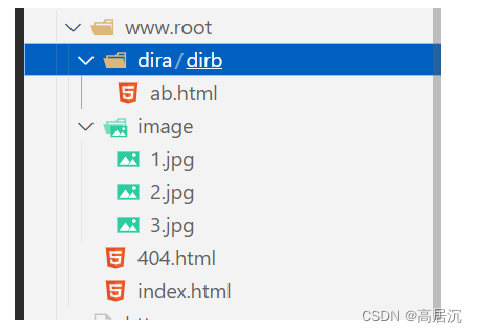
当我们通过访问http协议资源时,是通过IP和端口port与请求URL来访问服务器指定路径下的资源的,我服务器运行起来其实就是一个进程,而该进程并不一定是在根目录下执行的,而我们服务器一般会创建一个主文件夹,其中存放有我们所需要访问的资源数据,而该主文件夹就是web根目录,所以当服务端接收到客户端访问的URL时就可以进行路径解析,然后到指定web下的路径中读取资源内容并返回。
HTTP响应协议内容
HTTP/1.1 200 OK
Content-Type: text/html; charset=utf-8
Content-Length: 1234
Server: Apache/2.4.41 (Unix)
Date: Mon, 21 Oct 2023 13:12:00 GMT
<html>
<head>
<title>Welcome</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>第一行是状态行内容。
状态行包含三个主要部分:HTTP协议版本、状态码以及状态消息。
第二行开始到空行是响应头。
响应头包含一系列的字段,每个字段都包含一个名字和一个值,它们之间用冒号(
:)分隔。空行后面的内容就是响应体。
响应体是服务器返回给客户端的实际数据。它可能包含HTML、XML、JSON、纯文本、图片、视频等多种类型的数据。响应体的内容和格式由
Content-Type头字段决定。其实准确说响应体的内容就是客户端访问服务器指定路径下的文件信息。每一行的数据结尾用\r\n作为换行
请求协议解析代码
请求和响应代码是源自同一个头文件Http_protocol.hpp中:
#pragma once
#include "socket.h"
#include <sstream>
#include <fstream>
const string http_sep = "\r\n";
const string wwwroot = "./www.root"; // 这就是url下的根目录/
const string homepage = "index.html"; // 访问根目录下的默认文件
class HttpRequest
{
bool Get_line(string &request, string &ret) // 实现读取每一行数据的功能
{
int pos = request.find(http_sep);
if (pos == string::npos)
return false;
ret = request.substr(0, pos);
request.erase(0, pos + http_sep.size());
return true;
}
public:
HttpRequest()
: _req_blank(http_sep), _targetpath(wwwroot)
{
}
void Parse_reqline() // 分析请求行,并根据url确定路径_targetpath
{
//_method _url _http_version
stringstream ss(_req_line);
ss >> _method >> _url >> _http_version; // 以空格作为分隔符一次放到三个string流中
// 路径解析
if (_url == "/")
{
_targetpath += "/" + homepage;
}
else // 粗略处理
{
_targetpath += _url;
}
}
void Parse_suffix() // 解析url下的指定文件类型即后缀
{
//_targetpath: www.root/image/1.jpg
int pos = _targetpath.rfind('.');
if (pos == string::npos)
_suffix = "未知类型";
else
_suffix = _targetpath.substr(pos);
}
void parse() // 报文分析
{
// 1.分析请求行,同时提取url路径
Parse_reqline();
// 2.解析url下的指定文件类型即后缀
Parse_suffix();
}
string Get_filecontent_func(string path) // 读取指定路径下的数据
{
ifstream in(path, ios::binary); // 按照二进制方式来读取
if (!in.is_open())
return "";
string ret;
// a.读取一般非二进制数据的方法
// string line;
// while (getline(in, line))
// {
// ret += line;
// }
// getline不能拿来读取二进制文件
// 1.换行符问题 2.编码问题 3.性能问题
// b.读取二进制数据
in.seekg(0, in.end); // 文件流偏移到结尾数
int file_size = in.tellg(); // 读取文件大小
in.seekg(0, in.beg); // 回到文件开头指向
ret.resize(file_size);
in.read((char *)ret.c_str(), file_size);
in.close();
return ret;
}
string Get_filecontent()
{
return Get_filecontent_func(_targetpath);
}
string Get_404()
{
return Get_filecontent_func("www.root/404.html");
}
void Deserialize(string &request) // 反序列化
{
Get_line(request, _req_line);
string line;
while (1)
{
bool ok = Get_line(request, line);
if (ok && line.empty()) // 读到空行,即报头解析完毕
{
_req_content = request; // 空行后面就是实际内容
break;
}
else if (ok && !line.empty()) // 读取报头数据
{
_req_header.push_back(line);
}
else
break;
}
}
string Url()
{
return _url;
}
string Path()
{
return _targetpath;
}
string Suffix()
{
return _suffix;
}
void my_debug()
{
cout << "------------------------------------" << endl;
cout << "_req_line-> " << _req_line << endl;
for (auto s : _req_header)
{
cout << "_req_header-> " << s << endl;
}
cout << "_req_blank-> " << _req_blank << endl;
cout << "_req_content-> " << _req_content << endl;
cout << "------------------------------------" << endl;
}
private:
// 报文字段
string _req_line; // 请求行(请求方法,url,http版本)
vector<string> _req_header; // 请求报头
string _req_blank; // 空行(区分请求报头和有效载荷的,载荷长度就在报头中解析得到)
string _req_content; // 有效载荷
private: // 解析请求行字段
//_method _url _http_version
string _method;
string _url;
string _http_version;
string _targetpath; // url指定路径
string _suffix; // 通过url确定访问的文件后缀
};响应协议包装代码
const string blank_sep = " ";
const string line_sep = "\r\n";
class HttpRsponse
{
public:
HttpRsponse()
: _http_version("Http/1.0"), _status_code(200), _statuscode_desc("OK"), _rsp_blank(line_sep)
{}
void Set_statuscode(int code)
{
_status_code = code;
}
void Set_statuscode_desc(string s)
{
_statuscode_desc = s;
}
string Serialize(const string &httpheader, const string &content)
{
// 1.添加状态行数据、报头数据、换行、正文
_status_line = _http_version + blank_sep + to_string(_status_code) + blank_sep + _statuscode_desc + line_sep;
string rsp_content = _status_line + httpheader + line_sep + "\r\n" + content;
return rsp_content;
}
~HttpRsponse() {}
private:
string _status_line; // 状态行(响应行)
vector<string> _rsp_header; // 响应报头
string _rsp_blank; // 空行
string _rsp_content; // 正文
private:
//_http_version _status_code _statuscode_desc
string _http_version; // 版本
int _status_code; // 状态码
string _statuscode_desc; // 状态码描述
};请求方法get/post
请求协议资源中的第一行请求行内容的第一个字段就是请求方法,而我们最常用的请求方法就是get/post方法。get通常用来获取资源,但是也可以上传资源;而post通常用来上传资源。一般不写提交方法时,默认都是get方法。
我们通过表单来认识get与post方法:
创建表单并使用get方法
<html>
<meta charset="UTF-8"> <!-- 正确的汉字编码 -->
<!-- <form action="dira/dirb/ab.html" method="post"> -->
<!-- 表单内容会被提交并跳转到action,action指定了某个服务器脚本(子进程)来处理被提交表单 -->
<form action="dira/dirb/ab.html" method="get">
First name:<br>
<input type="text" name="my_name" value="aaaaaa"> <!-- text指的是文本,右边给的是缺省值 -->
<br>
Last name:<br>
<input type="password" name="my_password" value="">
<br><br>
<input type="submit" value="登录">
</form>
</html>

可以发现使用get方法时,在表单中填入的数据并登录以后,数据都通过?衔接回显到url上了
使用post方法

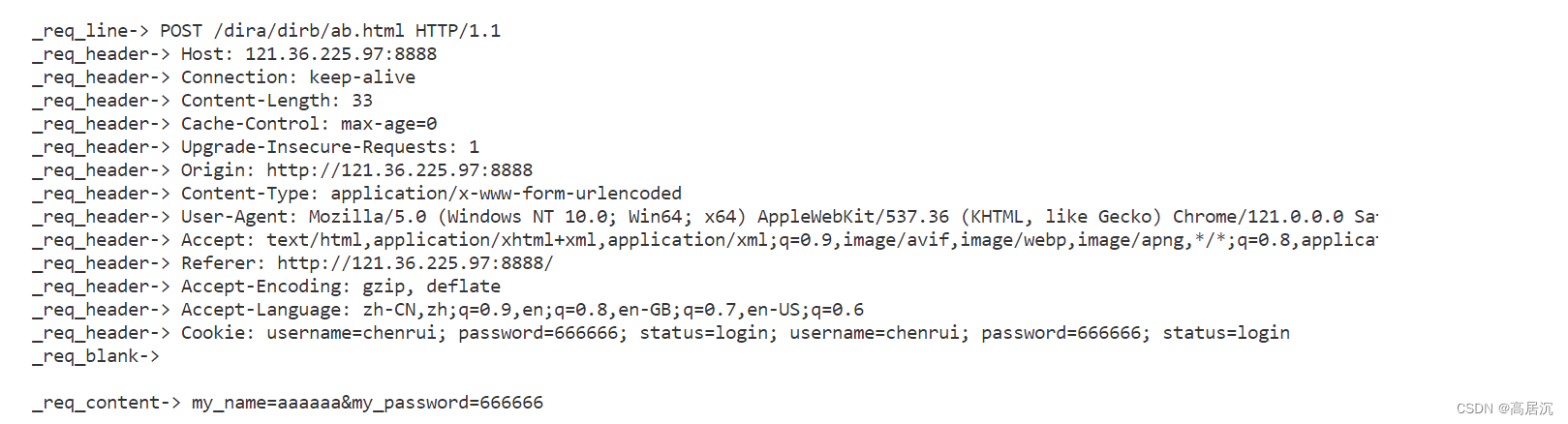
不难发现,post方法并没有将表单数据回显到url中,而是将数据回显到请求协议内容中的正文字段。所以正常情况下一个请求 默认情况下是没有正文的,除非用post传参,正文就可以有内容。
get/post总结
- get通过url传参;post通过请求正文传参
- get传参到url时会受到字节个数的限制;而post传参到正文中无字节的限制
- get私密性更差,会将参数直接传递到url上,可以直接看到;而post方法相对好一点,会将参数传递到正文,但是通过请求协议的数据抓包也可以查看到。
状态码
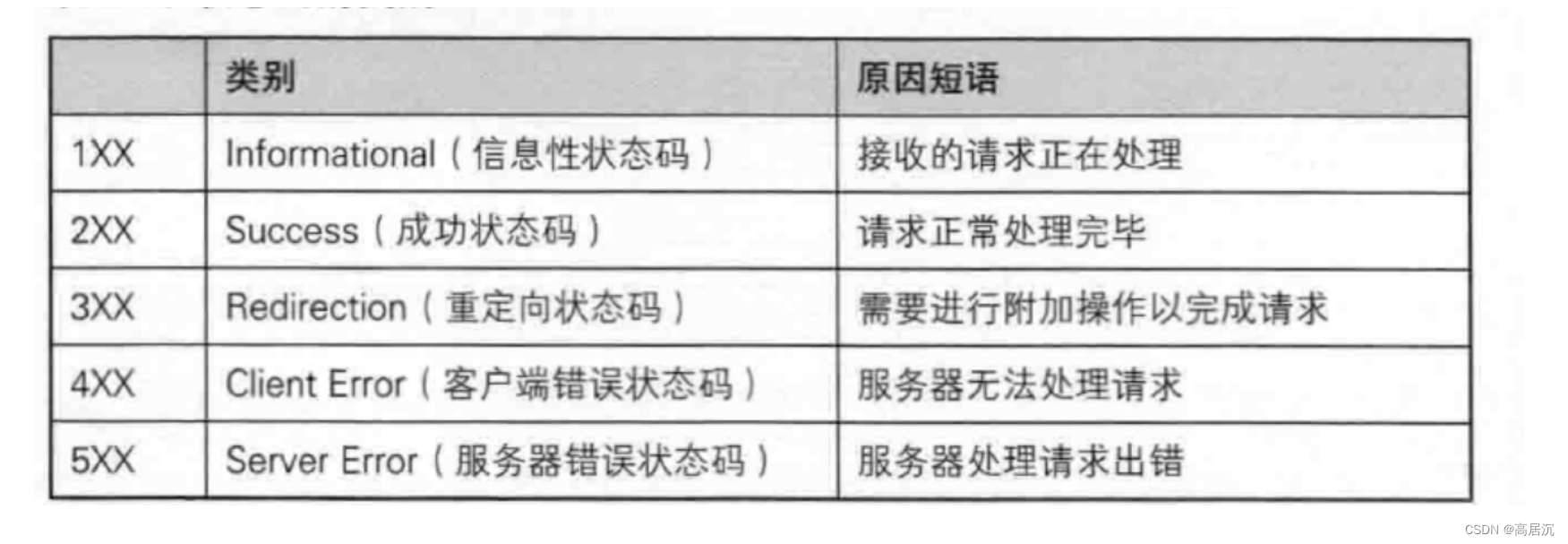
例如典型的状态码404:打开文件失败,文件不存在。状态码200:请求正常处理……
所以当我们接收到请求内容时,服务端可以根据客户端访问的数据来进行返回对应的状态码和状态码描述。
307状态码
当我们将状态码设置为307时,此时就代表着进行临时重定向,是通过响应报头location的值来确定具体重定向到哪个新的网址。也就是进行网页跳转。类似于在进入一个全新的网站时会优先跳转到登录界面、摇一摇转其他软件……
301状态码
而301状态码是永久重定向。我们要知道网页中是存在很多链接的,例如我们进入csdn中,有写博客功能,刷知识点,浏览大佬的博客……其实都是一个界面上打包好的一个个链接,点进去就会跳转到一个新的界面。这其实就有点像一个多叉树的结构。例如当我们搜索引擎获取网页时,该网页与很多的url相对应,但是如果我们的网页过期了,那么返回301时location就会更新链接,也就是搜索引擎不在用老的链接了,而是新的链接。
协议字段cookie
Http是无连接且无状态的。也就是说客户端访问服务器的时候是没有记录的,也就是不会保存你的个人登录信息,相当于每次切换网页都要重新进行登录。这其实就是因为每个人的登录信息不同,所对应的权限使用功能也不同,例如VIP用户和非VIP用户的区别,所以就有了cookie字段用来记录个人登录信息。
全过程就是:当浏览器获取登录页面时需要在表单上输入用户名和密码,然后就会将输入的数据信息回显到请求协议的正文字段(post方法),服务端就可以通过解析请求协议的字段拿到用户信息,然后将用户的信息保存到set-cookie字段并保存到后端数据库中,此时就能够记录当前用户。
而且浏览器(客户端)也会自动保存个人信息到请求协议中的cookie字段,浏览器保存cookie有文件级和内存级两种保存方式,一般都是采用文件级的方式进行保存。
但是一般cookie字段信息太过于暴露,所以就有session字段,session是一个结构体,其中保存了cookie里的信息,并且是一组键值对的数据,sessionid-session的字段,sessionid就是表示着具体的session字段信息,sessionid就是一串数字。而且一个服务器上会存在大量的登录用户,所以就需要管理session结构体:
#include <iostream>
#include <string>
#include <unordered_map>
#include <memory>
using namespace std;
// 先描述
class Session
{
public:
Session(const string &username, const string &password, const int &status)
{}
private:
string _username;
string _password;
int _status;
};
// 类对象作为成员一般可以设成智能指针
using Session_ptr = unique_ptr<Session>;
// 再组织
class Session_manage
{
string Generate_id(const string &username, const int &status)
{}
public:
string Addsession(const string &username, const string &password, const int &status) // 返回sessionid
{}
void Delsession(const string &id)
{}
void Chgsession(const string &id)
{}
bool Searchsession(const string &id)
{}
private:
// sessionid Session_ptr
unordered_map<string, Session_ptr> _sessions;
};
服务端响应字段代码
#include "Tcpserver.hpp"
#include "Http_protocol.hpp"
// Http协议(无连接,无状态)
string Suffixtotype(const string &suffix) // 通过后缀确定文件类型
{
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".png")
return "application/x-png";
else if (suffix == ".jpg")
return "image/jpeg";
else
return "no-entering";
}
string Codetodesc(int code) // 状态码转换成对应的状态码描述
{
switch (code)
{
case 200:
return "OK";
case 301:
return "Move permanently";
case 302:
return "Redirect";
case 307:
return "Temporary Redirect";
case 403:
return "Forbidden";
case 404:
return "Not Found";
case 504:
return "Bad Gateway";
default:
return "unknow";
}
}
string deal(string &s) // 服务端处理客户端信息
{
// !!!对收到的客户端数据信息做解析并打包返回
HttpRequest req;
// 1.反序列化(就是隔离请求行,请求报头,有效载荷)
req.Deserialize(s);
// 2.解析请求行内容并提取url路径
req.parse();
cout<<req.Url()<<endl;
// 3.在URL目录下读取数据客户端访问想要的信息
string content = req.Get_filecontent();
// 4.构建响应
HttpRsponse rsp;
if (content.empty()) // 如果读取的文件数据为空
{
content = req.Get_404();
rsp.Set_statuscode(404);
rsp.Set_statuscode_desc(Codetodesc(404));
}
string httpheader = "Content-Length: " + to_string(content.size()) + "\r\n"
+ "Content-Type: " + Suffixtotype(req.Suffix()) + "\r\n"
+ "Location: https://www.baidu.com/"+"\r\n";
//当识别到状态码为307,则表明是临时重定向到location下的网址,浏览器此时提取location字段后发生二次请求
//307一般用来临时页面跳转,例如软件界面的广告
//301是永久性重定向移动,请求资源已被永久的移动到新的url,浏览器会自动定向到新的url
//a.http无状态-cookie(用来保存客户的登录信息,登陆之后,浏览器自动填充cookie)
//b.还有一种方式是将session(保存客户端登录信息)与sessionid(随机数)构成映射,所以就直接返回sessionid给客户端
string cookie_name="Set-Cookie: username=chenrui\r\n";
string cookie_passeord="Set-Cookie: password=666666\r\n";
string cookie_status="Set-Cookie: status=login\r\n";
httpheader+=cookie_name+cookie_passeord+cookie_status;
string rsp_content = rsp.Serialize(httpheader, content);
req.my_debug(); // 打印客户端信息
return rsp_content;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{
cout << "格式错误\n正确格式:" << argv[0] << " port"
<< endl;
}
uint16_t port = atoi(argv[1]);
// tcp_server tsv(port);
unique_ptr<Tcp_server> tsv(new Tcp_server(port, deal)); // 创建套接字,且绑定并监听
tsv->loop(); // accept等待客户端套接字连接
}
socket代码tcp
#pragma once
#include <iostream>
#include <cstdint>
#include <string>
#include<vector>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <thread>
#include <functional>
#include <memory>
using namespace std;
#define default_backlog 5
// 设计模式:模版方法类
class my_socket // 抽象类
{
public:
virtual void Creat_socket() = 0; // 纯虚函数,必须重写
virtual void Bind(int port) = 0;
virtual void Listen(int backlog) = 0;
virtual my_socket *Accept(string &ip, uint16_t &port) = 0;
virtual void Connect(string ip, uint16_t port) = 0;
virtual int Get_sockfd() = 0;
virtual void Close() = 0;
virtual void Recv(string &ret, int len) = 0;
virtual void Send(string s) = 0;
public:
void tcpserver_socket(uint16_t port, int backlog = default_backlog)
{
Creat_socket();
Bind(port);
Listen(backlog);
// 因为服务会返回的执行accept获取连接,所以选择分离
}
void tcpclient_socket(string ip, uint16_t port)
{
Creat_socket();
Connect(ip, port);
}
};
class tcp_socket : public my_socket // 继承并重写虚函数
{
public:
tcp_socket()
{
}
tcp_socket(int sockfd)
: _sockfd(sockfd)
{
}
virtual void Creat_socket()
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
cerr << "创建套接字失败" << endl;
exit(-1);
}
}
virtual void Bind(int port)
{
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_port = htons(port);
local.sin_addr.s_addr = INADDR_ANY;
int n = bind(_sockfd, (sockaddr *)&local, sizeof(local));
if (n < 0)
{
cerr << "绑定套接字失败" << endl;
exit(-1);
}
}
virtual void Listen(int backlog)
{
int n = listen(_sockfd, backlog);
if (n == -1)
{
cerr << "监听套接字失败" << endl;
exit(-1);
}
}
virtual my_socket *Accept(string &ip, uint16_t &port)
{
while (1)
{
struct sockaddr_in client;
socklen_t len = sizeof(client);
int newsockfd = accept(_sockfd, (sockaddr *)&client, &len); // 监听套接字不关闭,可以用来接收多个客户端的连接
if (newsockfd < 0)
{
cerr << "获取连接失败" << endl;
}
port = ntohs(client.sin_port);
char buffer[64];
inet_ntop(AF_INET, &client.sin_addr, buffer, sizeof(buffer)); // 1.网络转本机 2.4字节ip转字符串ip
ip = buffer;
if (newsockfd < 0)
{
cerr << "接收套接字失败" << endl;
}
else
cout << "接收套接字成功" << endl;
return new tcp_socket(newsockfd);
}
}
virtual void Connect(string ip, uint16_t port)
{
struct sockaddr_in server;
server.sin_family = AF_INET; // socket inet(ip) 协议家族,绑定网络通信的信息
server.sin_port = htons(port); // 将主机端口号转成网络
// server.sin_addr.s_addr = inet_addr(ip.c_str()); // 转成网络序列的四字节ip
inet_pton(AF_INET, ip.c_str(), &server.sin_addr); // 转成网络序列的四字节ip
int n = connect(_sockfd, (sockaddr *)&server, sizeof(server)); // 自动bind
if (n != 0)
{
cerr << "连接失败" << endl;
exit(-1);
}
else
cout << "连接成功" << endl;
}
virtual int Get_sockfd()
{
return _sockfd;
}
virtual void Close()
{
if (_sockfd > 0)
close(_sockfd);
}
virtual void Recv(string &ret, int len)
{
char stream_buffer[len];
int n = recv(_sockfd, stream_buffer, len - 1, 0);
if (n > 0)
{
stream_buffer[n] = 0;
ret += stream_buffer; // ret在读取之前可能还有内容残留
}
else
{
exit(0);
}
}
virtual void Send(string s)
{
send(_sockfd, s.c_str(), s.size(), 0);
}
private:
int _sockfd;
};
HTTPS协议
HTTPS 也是⼀个应⽤层协议. 是在 HTTP 协议的基础上引⼊了⼀个加密层.
加密就是把 明文 (要传输的信息)进行一系列变换,生产密文。解密就是把密文再进行一系列变换, 还原成明文在这个加密和解密的过程中, 往往需要⼀个或者多个中间的数据, 辅助进行这个过程, 这样的数据称为密钥。
为什么要进行加密
http的内容是明文传输的,明文数据会经过路由器、wifi热点、通信服务运营商、代理服务器等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息且不被双方察觉,这就是中间人攻击,所以才需要对信息进行加密。
加密方式
对称加密
对称加密采⽤单钥密码系统的加密方法,同⼀个密钥可以同时用作信息的加密和解密,这种加密方法称为对称加密,也称为单密钥加密,也就是加密和解密的密钥相同。
特点:算法公开、计算量小、加密速度快、加密效率高
非对称加密
非对称加密需要两个密钥来进行加密和解密,这两个密钥分别是公开密钥(public key,简称公钥)和私有密钥private key,简称私钥)。可以公钥加密私钥解密或者私钥加密公钥解密。
特点:算法强度复杂、安全性依赖于算法与密钥但是由于其算法复杂,而使得加密解密速度没有对称加密解密的速度快。
数据摘要(数据指纹)
数字指纹(数据摘要),其基本原理是利⽤单向散列函数(Hash函数)对信息进⾏运算,生成⼀串固定长度的数字摘要。数字指纹并不是⼀种加密机制,但可以⽤来判断数据有没有被篡改。也就是用来对比经过网络传输前后的数据,从而判断数据是否改变。
和加密算法的区别:摘要严格意义不是加密,因为没有解密,只不过从摘要很难反推原信息,通常用来进行数据对比。
数字签名
数据摘要经过加密,就得到了数字指纹。
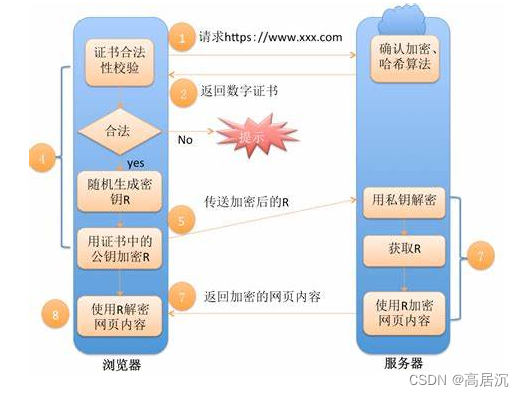
HTTPS的工作过程
HTTPS想要达到的效果就是,通信双方在数据跨网络传输的时候不会造成数据的泄露。
需要了解,对称加密是使用同一个公钥,但是加密速度快效率高;非对称加密是一个公钥一个私钥,但是使用复杂效率低。所以就有了一些方案的出现:
- 对称加密。采用一个公钥进行加密,服务器在第一次传送对称密钥时,此时中间人同样也可以拿到该密钥,所以数据会暴露出去。
- 非对称机密。服务端进行传输公钥时,中间人也能拿到公钥,虽然服务端公钥加密传输数据是安全的,但是此时服务端私钥加密传输数据,而客户端与中间人都可以用公钥解密,
- 非对称加密+非对称加密。此时虽然看起来没什么大问题,但是传输效率很低。
- 非对称加密+对称加密。服务端向客户端传送非对称密钥的公钥,此时客户端也有一份,然后客户端此时动态的生成对称密钥,通过非对称公钥进行加密传送给服务端,此时服务端有非对称私钥,可以解密获取对称密钥,此后客户端与服务端就可以通过对称密钥进行通信。核心即非对称密钥加密对称密钥。
但是以上2、3、4情况的安全并不是真正的安全,其实也是存在漏洞的。当非对称传输时,服务端将一个密钥给客户端时,假如中间人一开始就介入的话,中间人就会先拿到该密钥,此时中间人自己也生成一组非对称密钥,然后将自己的密钥传给客户端,此时客户端生成对称密钥并通过非对称密钥进行加密传送给服务端时,中间人抢先一步拿到数据,用自己的密钥解密,并在通过原来服务端传来的密钥加密并回显给服务端。此时中间人就拿到了对称密钥,就能够将数据解密。这其实就是数据不一致,即服务端发来的密钥并不是客户端收到的密钥,从而无法判断公钥的合法性。此时就引入了证书,即CA认证:
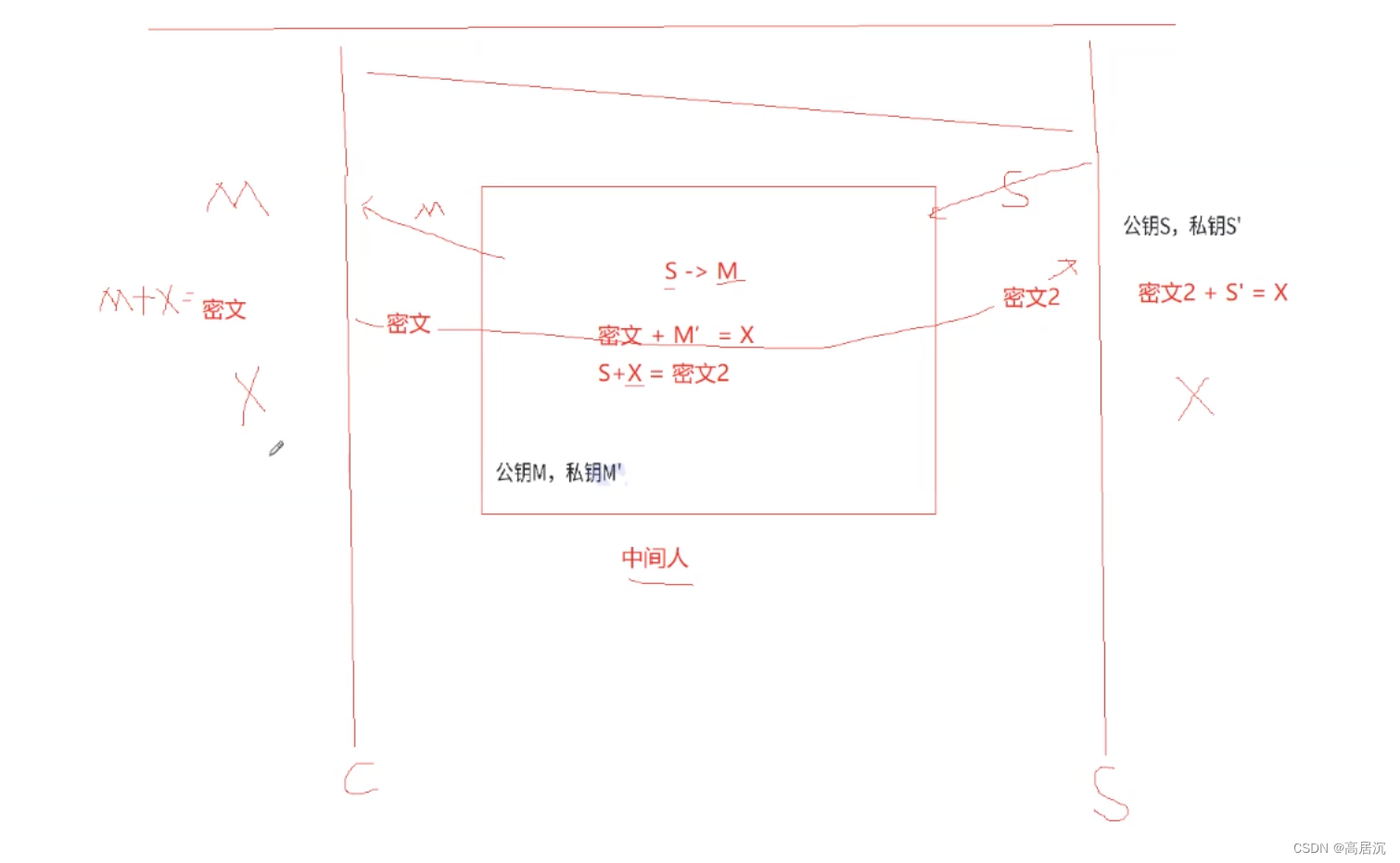
CA认证
服务端在使用HTTPS前,需要向CA机构申领⼀份数字证书,数字证书里含有证书申请者信息、公钥信息等。服务器把证书传输给浏览器,浏览器从证书⾥获取公钥就行了。证书就如⾝份证,证明服务端公钥的权威性。
生成证书的全过程
某企业服务器运转前先申请证书,而在此之前需要先生成一组非对称密钥,将私钥自己保留,公钥和域名等企业相关信息打包生成.csr文件发送给CA机构,CA机构会对信息进行审核,如果审核通过以后会将明文信息(即有效时间、域名、申请者、公钥……)填充进证书并返回给企业,此时服务器就不用将非对称密钥单独传送过去了,直接把证书传过去就OK了。
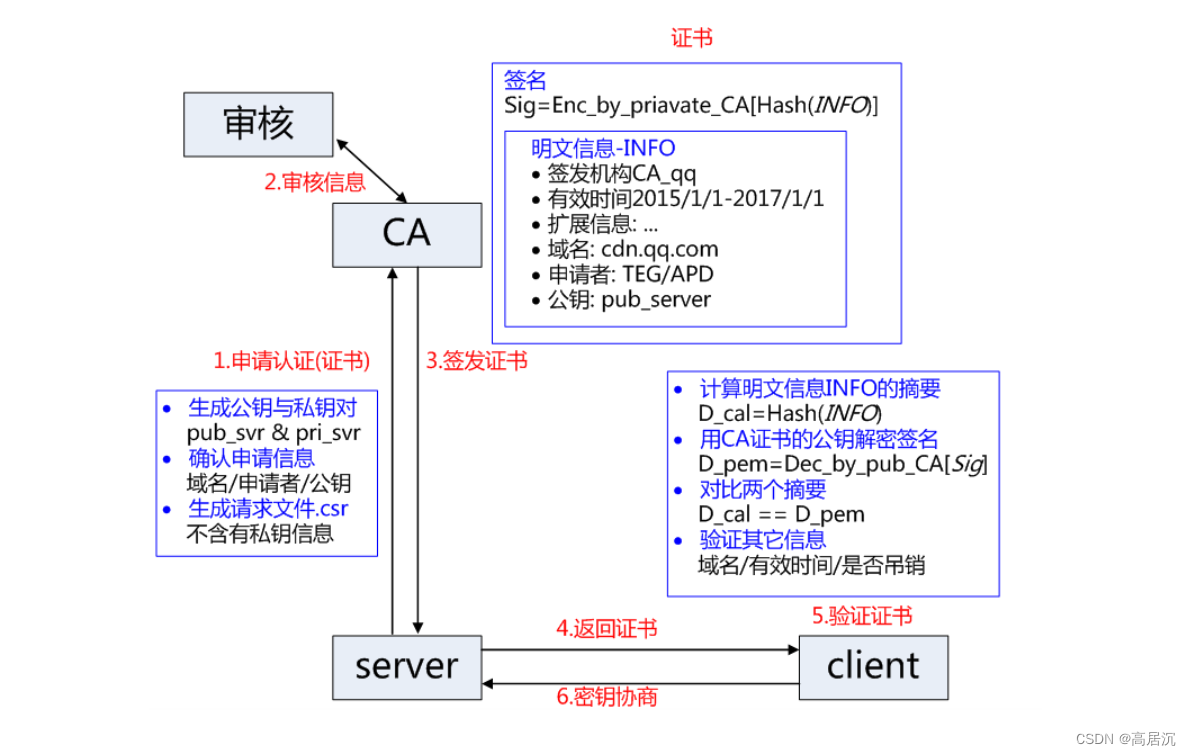
但是证书的内容都是明文,那将证书传送的过程能保证安全???
:当CA机构验证申请者信息通过了以后就会生成证书,而生成完整的证书时,会先将传来的明文信息通过哈希散列形成数据指纹,然后将数据指纹通过CA的私钥(CA机构会为申请者生成一组非对称密钥)形成签名,最后将签名和明文信息一起发送给企业服务器。而想要验证CA证书是否一致的问题就可以通过明文信息散列成散列值,将签名通过公钥(计算机浏览器内置CA公钥)解密形成散列值,进行对比。
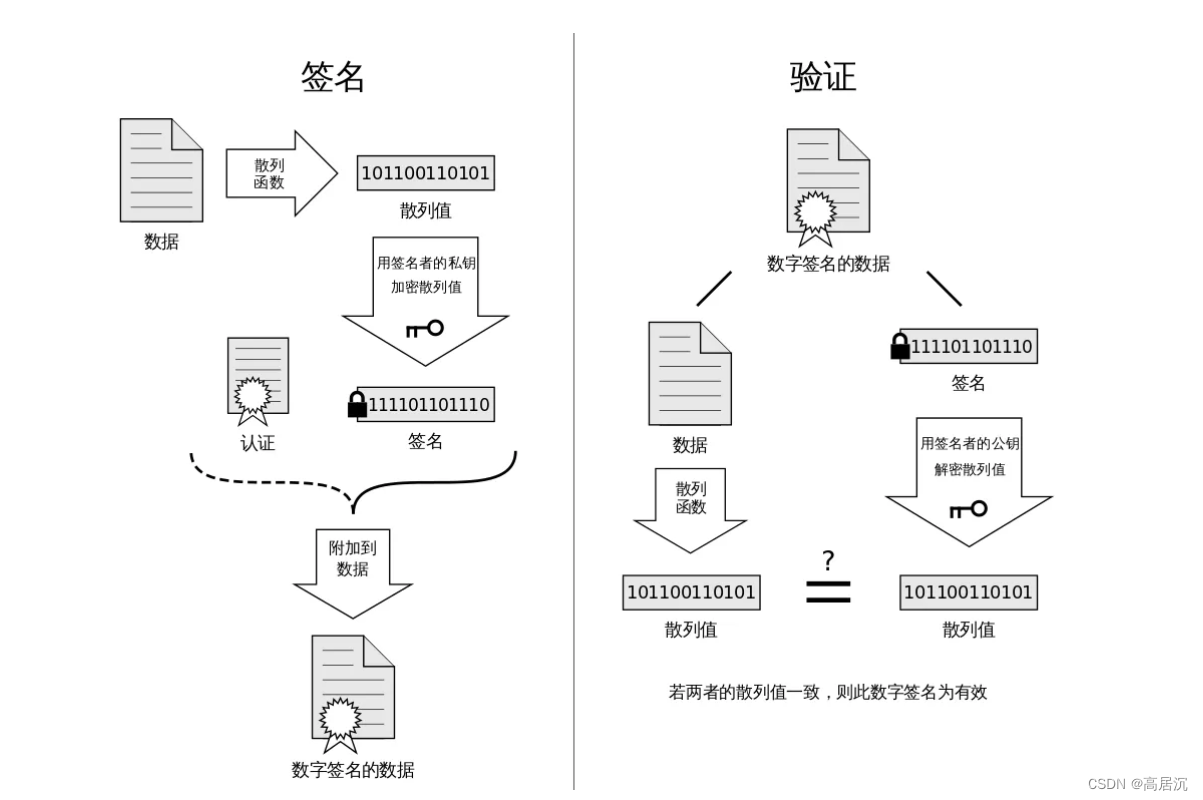
所以说https的工作过程其实就是浏览器内置CA权威机构公钥+生成证书(server的公钥)+非对称加密&&对称加密。