目录
1 缺省参数
1.1 全缺省
1.2 半缺省
注意
1.3 应用
2 函数重载
函数重载的概念
1、参数类型不同
2、参数个数不同
3、参数类型顺序不同
3 引用
3.1 引用概念
3.2 引用特性
3.3 常引用
3.4 使用场景
3.5 传值、传引用效率比较
3.6 引用和指针的区别
1 缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
void Func(int a = 0)
{
cout << a << endl;
}
int main()
{
Func();
// 没有传参时,使用参数的默认值
Func(10);
// 传参时,使用指定的实参
return 0;
}
缺省参数也就是默认参数。就像这样,默认输出a=0
如果有多个参数,可以后面的不赋值,但是不能跳跃的传参。也就是说不能前一个不传而后面的传。
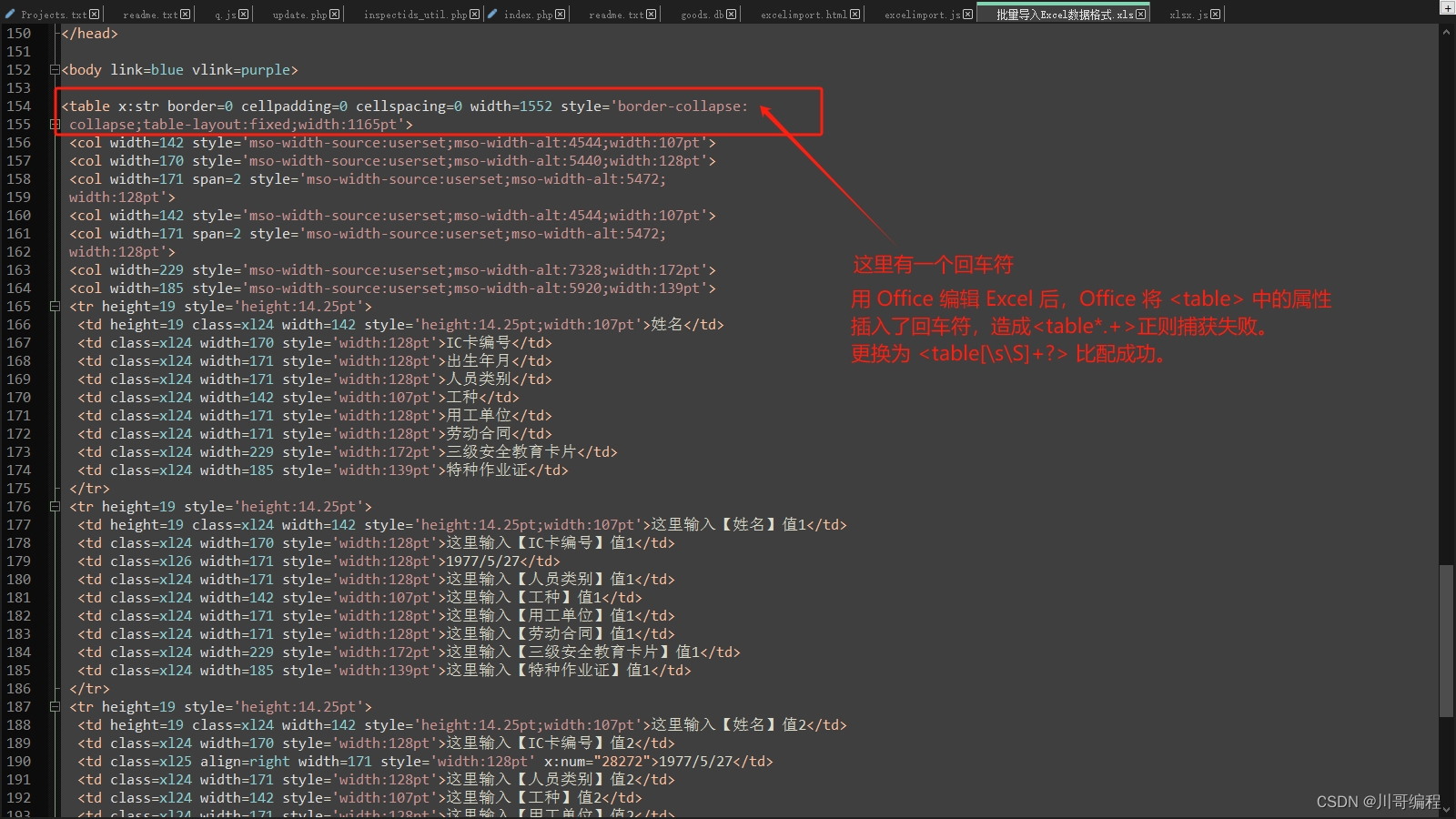
1.1 全缺省
void Func(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}1.2 半缺省
void Func(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main()
{
Func(5, 10, 20); // 5 10 20
Func(5, 6); // 5 6 20
Func(5); // 5 10 20
}注意
- 半缺省参数必须从右往左依次来给出,不能间隔着给
- 缺省参数不能在函数声明和定义中同时出现,参数要在声明中给。
//a.h void Func(int a = 10); // a.cpp void Func(int a = 20) { }如果声明与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值。
-
缺省值必须是常量或者全局变量
-
C语言不支持(编译器不支持)
1.3 应用
栈的空间开辟。我们以前实现的时候是把他写死了,在初始化的时候malloc。但是空间不够我们就需要扩容。如果我们已知一个地方要插入100个数据,另一个地方要插入4个数据,而初始化malloc了4个数据的空间,这样我们就只能扩容。那么要如何改进呢?可以用缺省参数。
struct Stack
{
int* a;
int size;
int capacity;
};
void StackInit(struct Stack* ps, int n = 4);
void StackPush(struct Stack* ps, int x);
int main()
{
struct Stack st1;
// 1、确定要插入100个数据
StackInit(&st1, 100);
// 2、只插入10个数据
struct Stack st2;
StackInit(&st2, 10);
// 3、不知道要插入多少个
struct Stack st3;
StackInit(&st3);
return 0;
}缺省参数非常好用,我们后面还会多次见到。
2 函数重载
函数重载的概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
1、参数类型不同
编译器会自动匹配我们用的是哪个函数。同一作用域,可以同名,但要满足重载规则。不同作用域,可以同名。
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
return 0;
}2、参数个数不同
// 2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
int main()
{
f();
f(10);
return 0;
}3、参数类型顺序不同
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main()
{
f(10, 'a');
f('a', 10);
return 0;
}
如下:swap函数是否构成重载关系?
namespace bit1
{
void Swap(int* pa, int* pb)
{
cout << "交换" << end1;
}
}
namespace bit2
{
void Swap(int* px, int* py)
{
cout << "交换" << end1;
}
}
using namespace bit1;
using namespace bit2;- 答案是不构成。因为这里只是展开了两个命名空间,并不能说他们就在同一个作用域内。
返回值不同,不构成重载!
3 引用
3.1 引用概念
引用 不是新定义一个变量,而 是给已存在变量取了一个别名 ,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
- 类型& 引用变量名(对象名) = 引用实体;
void TestRef()
{
int a = 10;
int& ra = a;//<====定义引用类型
printf("%p\n", &a);
printf("%p\n", &ra);
}改变ra的值,a的值也会改变。ra是a的别名。
- 注意:引用类型必须和引用实体是同种类型的
以前我们写swap函数的时候,需要再调用的时候传入地址,这里我们学习了引用,就可以用这种方法:传入别名。
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}3.2 引用特性
1. 引用在定义时必须初始化
- 不能一上来就定义一个别名,int &ra; 必须先定义a
2. 一个变量可以有多个引用3. 引用一旦引用一个实体,再不能引用其他实体int x = 0; int& y = x; int z = 0; y = z;请问以上代码中,y=z这一步操作是y变成z的别名,还是z赋值给y?
- 是z赋值给y。
3.3 常引用
1.权限的平移
int x = 0; int& y = x;2. 权限的放大Ⅰ
const int x = 0; int& y = x;这样写就会扩大权限,x只是可读,而y可读可写。这样写不行。
- 所以要写成: const int& y = x
权限的放大Ⅱ
const int m = 0; const int* p1 = &m; int* p2 = p1;
- m只读,const修饰的是*p1,所以p1可以修改,而*p1不可以修改。这个时候把p1的地址拷贝给p2,*p2就可以修改了,权限放大了!
- 只需要改为const int* p2 = p1;即可。
注意:如果后面加一个int p = x; 这样写是可以的,因为这只是把x拷贝给p,不存在权限放大问题。
3.权限的缩小Ⅰ
int x = 0; const int& y = x;
- x可读可写,y只读,这样写可以。
权限的缩小Ⅱ
int* p3 = &x; const int* p4 = p3;
- 起了别名以后,在别名身上修改,它本身也会跟着改变。因为地址都一样
- 权限只能缩小,不能放大!
这样可以吗?
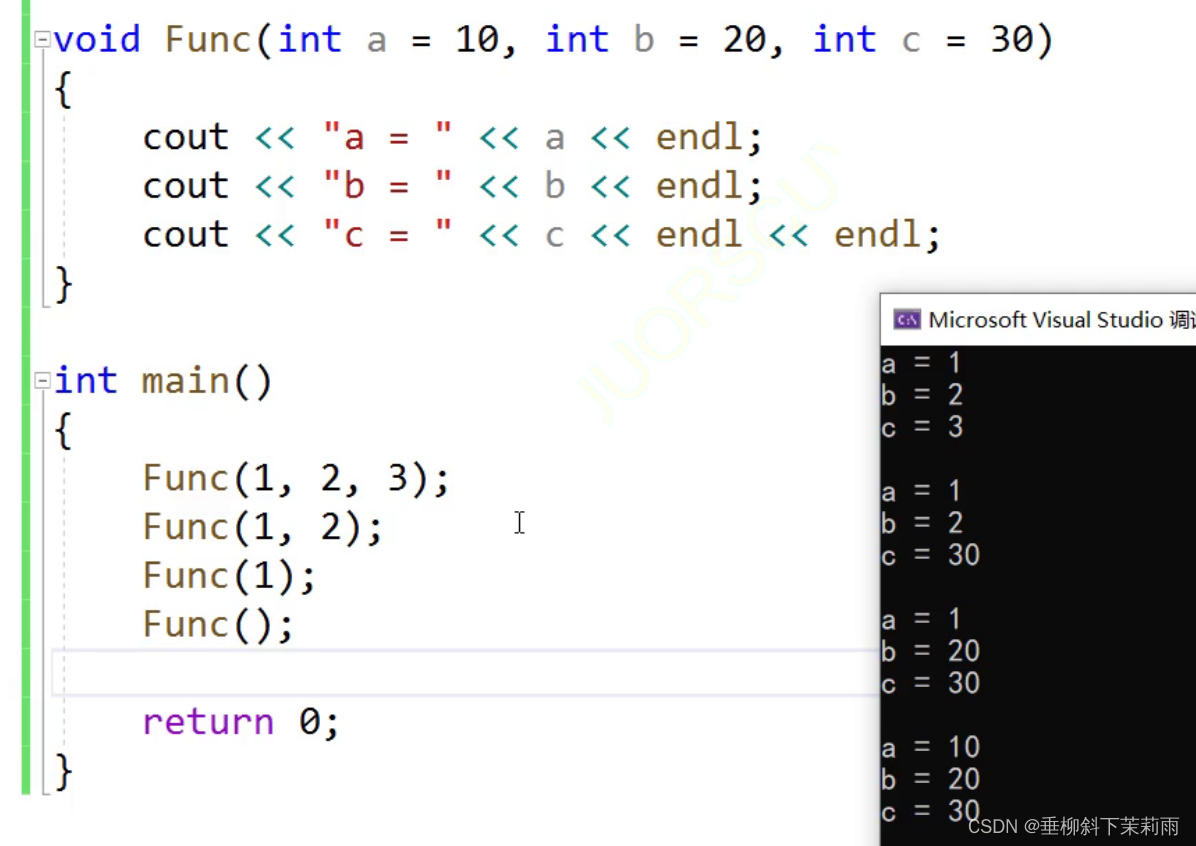
double d = 12.34;
//类型转换
int i = d;
int& r = d;不可以,int& r = d; 这里相当于创建了一个临时变量,而临时变量具有常性,如果只int&,就会放大权限,所以必须在前面加一个const。
那么哪些地方还会产生临时变量呢?
int x = 0,y = 1;
int& r2 = x + y;
这里也会产生临时变量,具有常性,所以一定要在前面加const。
3.4 使用场景
1、做参数
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}2、做返回值
int& Count()
{
static int n = 0;
n++;
// ...
return n;
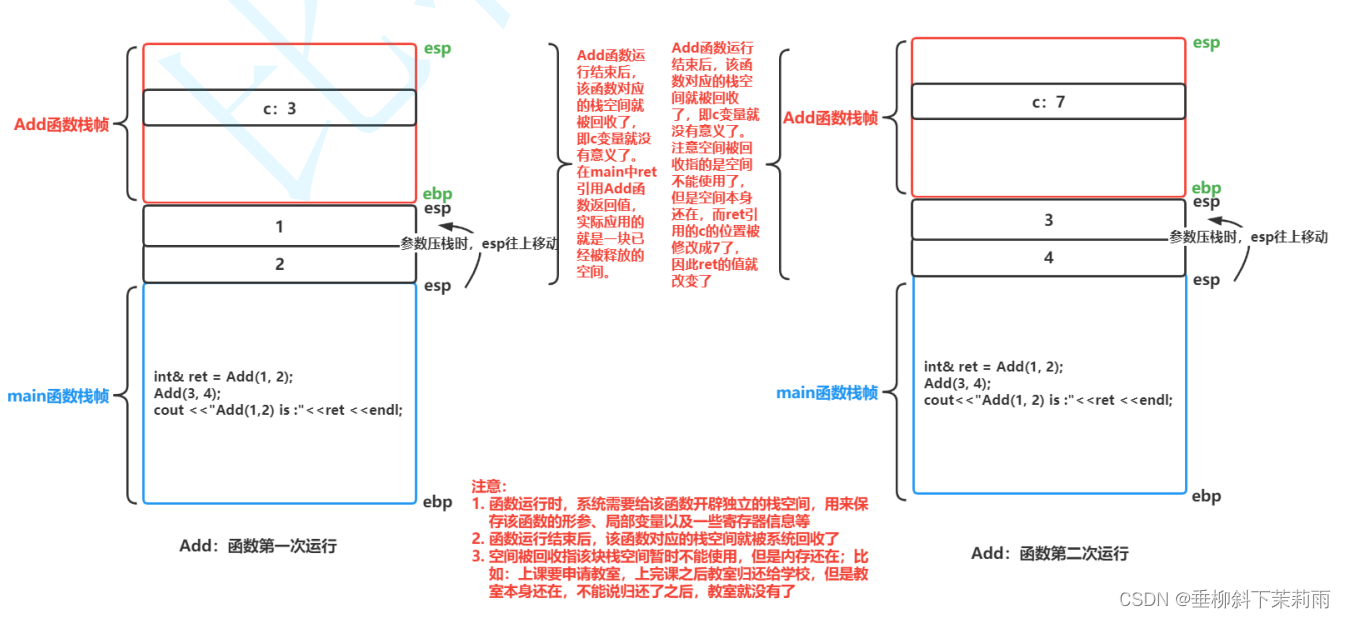
}下面的代码输出什么?
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(3, 4);
cout << "Add(1, 2) is :"<< ret <<endl;
return 0;
}
3.5 传值、传引用效率比较
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
#include <time.h>
struct A{ int a[10000]; };
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
3.6 引用和指针的区别
- 引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
- 指针会创建一个空间,用来存实体的地址。
- 实际是有空间的,因为引用是按照指针方式来实现的。

- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
int* ptr = NULL;
int& r = *ptr;- 这个难道不是引用ptr解引用吗?ptr是空啊,为什么不报错?
原因是这个时候本质上并没有解引用,只有在cout<<r<<endl;的时候,才会解引用。
int a = 0;
int& b = a;
cout << sizeof(b) << endl; // 4
cout << sizeof(int&) << endl; // 4- 需要注意的是,引用不能代替指针,在链表中,引用不能改变指向,所以不能替代。