算法思路介绍:
1. 数据准备阶段:
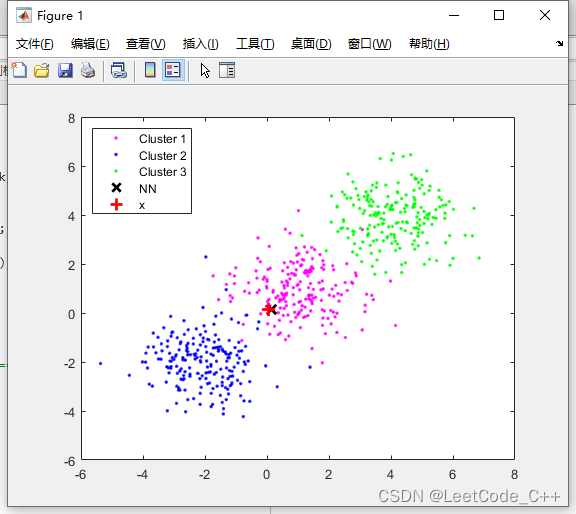
生成一个合成数据集 `X`,其中包含三个簇,每个簇分布在不同的区域。
定义聚类层数 `L` 和每个层次的子集数量 `l`。
2. 聚类阶段:
使用K均值聚类算法将初始数据集 `X` 分成 `l` 个簇。
对于每个簇,计算其中心点 `Mp` 和最大半径 `Rp`,以及每个点到中心点的距离 `D`。
对每个簇,存储其数据点 `Xp`,中心点 `Mp` 和半径 `Rp`。
3. 树搜索阶段:
选择一个待判定的样本 `x`。
初始化一个阈值 `B` 为正无穷,当前层数 `CurL` 为 1,以及节点指针 `p` 为 0。
进入主循环,直到所有节点都被搜索完毕:
在每一轮中,从当前节点的子节点中选择一个最有可能的节点,计算其与待判定样本的距离。
如果当前节点是叶子节点:
检查是否有更近的邻居点,更新最近邻距离 `B` 和最近邻点 `Xnn`。
如果当前节点不是叶子节点:
进入下一层,继续搜索。
4. 输出结果:
输出最近邻点 `Xnn` 和其索引。
主要步骤:
数据准备阶段:
1. 生成合成数据集 `X`。
2. 定义聚类层数 `L` 和每个层次的子集数量 `l`。
聚类阶段:
1. 对数据集进行 K 均值聚类。
2. 存储每个簇的数据点、中心点和半径。
树搜索阶段:
1. 初始化参数,如待判定样本 `x`、阈值 `B`、当前层数 `CurL` 和节点指针 `p`。
2. 在循环中,从当前节点的子节点中选择一个最有可能的节点。
3. 如果当前节点是叶子节点,则检查是否有更近的邻居点。
4. 如果当前节点不是叶子节点,则进入下一层继续搜索。
输出结果:
输出最近邻点 `Xnn` 和其索引。
部分代码(完整代码在最后):
% ---进行树搜索---
tic
x=randn(1,2);%待判样本
B=inf;CurL=1;p=0;TT=1;
while TT==1 %步骤2
Xcurp=cell(1);
CurTable=cell(l,1);
CurPinT=zeros(l,1);
Dx=zeros(l,1);
RpCur=zeros(l,1);
%当前节点的直接后继放入目录表
for i=1:l
CurTable(i,1)=Xp(i+p*l,1);
CurPinT(i)=i+p*l;
Dx(i)=norm(x-Mp(i+p*l,:))^2;
RpCur(i)=Rp(i+p*l);
end
while 1 %步骤3
[rowT,colT]=size(CurTable);
for i=1:rowT
if Dx(i)>B+RpCur(i)+eps%从目录表中去掉当前节点p
CurTable(i,:)=[];
CurPinT(i)=[];
Dx(i)=[];
RpCur(i)=[];
break;
end
end
[CurRowT,CurColT]=size(CurTable);
if CurRowT==0
CurL=CurL-1;p=floor((p-1)/3);
if CurL==0
TT=0; break;
else
%转步骤3
end
elseif CurRowT>0
[Dxx,Dxind]=sort(Dx,'ascend');
p1=CurPinT(Dxind(1));
p=p1;
%从当前目录表去掉p1
for j=1:CurRowT
if CurPinT(j)==p1
Xcurp(1,1)=CurTable(j,1);
CurTable(j,:)=[];
CurPinT(j)=[];
CurD=Dx(j);%记录D(x,Mp)
Dx(j)=[];
RpCur(j)=[];
break;
end
end
if CurL==L
XcurpMat=cell2mat(Xcurp);
[CurpRow,CurpCol]=size(XcurpMat);
CurpMean=Mp(p,:);
for k=1:CurpRow
Dxi=norm((XcurpMat(k,:)-CurpMean))^2;
if CurD>Dxi+B+eps
else
Dxxi=norm((x-XcurpMat(k,:)))^2;
if Dxxi<B+eps
B=Dxxi;Xnn=XcurpMat(k,:);
end
end
end
else
CurL=CurL+1;
break;
end
end
end
end
B,Xnn,NN=find(X(:,1)==Xnn(1))
time1=toc结果展示: