相关问题:
1.为什么Redis能够如此快速地进行数据存储和检索?
2.Redis作为内存数据库,其内存存储有什么优势吗?
3.Redis的网络模型有何特点,如何帮助提升性能?
一、问题回答
-
Redis使用了内存数据结构,例如字符串、哈希表、列表、集合、有序集合等,这些数据结构在内存中操作速度很快,有助于Redis的高性能。
-
Redis采用单线程模型,避免了多线程的线程切换和同步开销,提高了处理速度。
-
Redis使用了非阻塞I/O,可以在一个线程中处理多个客户端请求,提高了并发处理能力。
-
Redis支持多种持久化方式,包括RDB快照和AOF日志,可以根据需要选择合适的持久化方式,同时保证数据安全和性能。
-
Redis主要是基于内存操作,避免了频繁的磁盘IO操作,从而提高了读写性能。
二、redis的数据类型
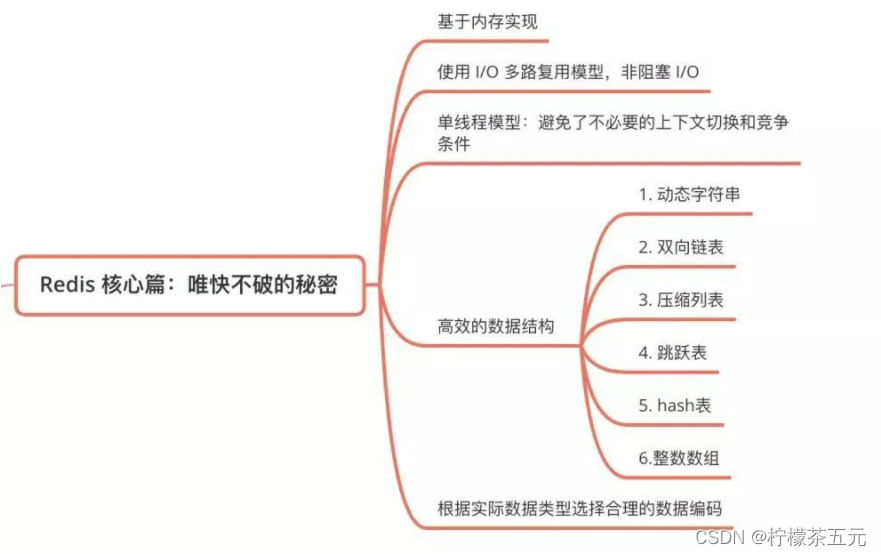
1.String:主要用来存储字符串,底层基于动态字符串SDS实现,其通过动态调整长度节省内存。
场景:分布式锁session、分布式锁。 指令:set, hget, setnx, set ex
2.hash:类似于map,底层采用两种方式,当数据量较少并且元素占用内存少(小整数或短字符串时)采用ziplist(压缩列)。
场景:实现购物车 指令:hset, hgetall, hdel
3.list:有序可重复集合,当数据量少并且元素占用内存少,用ziplist,反之用quicklist(快速列表),节省内存。
【ziplist: 连续内存空间,通过紧凑的存储来节省空间。 quicklist:基于ziplist和链表,节省内存,高效增删】
场景:栈(LPush+Lpop) \ 队列(Lpush + Lpop) \ 发布订阅
4.set:元素不可重复,当数据量少且元素为整,用intset(整数集合),反之用hashtable(哈希表)。
【intset:有序数组,紧凑空间。 hashtable:基于dict(字典)实现,采用拉链表解决。】
场景:抽奖(srandmember) \点赞收藏关注(sadd) \共同关注(sinter)\可能认识的人(sdiff)
5.zset(sorted set):有序不可重复,数据量少用ziplist,反之skiplist(跳表)+dict(字典)。
【skiplist:有序链表配上多级索引,通过多级索引位置的跳转实现快速查找元素,按分值排序。】
场景:排行榜(zrange\zreverange\zunionscore)
6.bitmap:位图。
场景: 月打卡、月活跃、布隆过滤器
7.stream:参考kafka设计的消息队列,支持持久化,适合小基数的消息队列场景。
三、Reactor模型
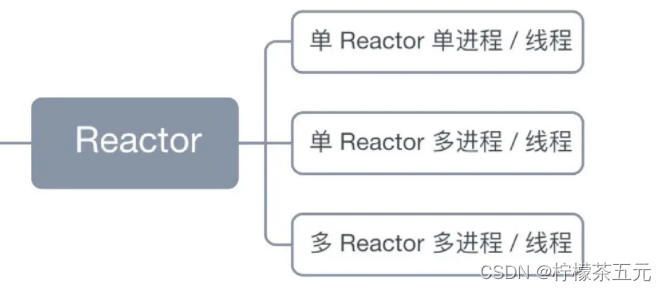
Reactor 模式也叫 Dispatcher 模式,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
1.单线程模式:一个线程负责多个事件处理,当连接数过多时会造成性能瓶颈,适合连接数少,复杂度低的场景。
2.多线程模式(单线程、工作线程池):在单线程的基础上,将业务处理部分交给了线程池提高并发能力,需要注意线程安全。
3.主从多线程模式:将整体拆分为主、从Reactor
- 主:负责监听连接事件,将事件分发给从Reactor去处理。
- 从:负责与客户端读写操作,充分利用多核CPU,提升并发。
四、IO多路复用
一种同步IO模型,允许单线程去同时监听多个文件描述符,一旦文件描述符就绪就会通知程序处理。【多个请求复用了一个进程,这就是多路复用】
select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
- select:基于数组实现,每次调用都进行遍历,最大连接有上限。
- poll:基于链表实现,无最大连接上限。
- epoll:通过哈希表实现,通过事件通知,当IO事件就绪,系统注册的回调函数就被调用,无上限。【epoll 支持两种事件触发模式,分别是边缘触发(edge-triggered,ET)和水平触发(level-triggered,LT)】
注:(以下摘自:这次答应我,一举拿下 I/O 多路复用!)
1.poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
2.epoll 通过两个方面,很好解决了 select/poll 的问题。
- epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过
epoll_ctl()函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。 - epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用
epoll_wait()函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。

五、持久化机制
1.RDB 就是 Redis DataBase 的缩写,中文名为快照/内存快照,RDB持久化是把当前进程数据生成快照保存到磁盘上的过程,由于是某一时刻的快照,那么快照中的值要早于或者等于内存中的值。【自动触发 和 手动触发】
2.Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL),例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。 【而AOF日志采用写后日志,即先写内存,后写日志。 】
- RDB:通过快照进行持久化,通过快照触发条件将内存中的数据写到rdb文件中。
- AOF:一种接近实时的方式,通过执行命令都写到AOF中。
很少使用RDB,因为它容易丢失数据,通常会采用AOF,但AOF持久化速度慢,故混合使用。
RDB全量持久化 + AOF增量持久化
- 若数据不敏感,可不开启持久化
- 数据比较重要且允许几分钟数据丢失用RDB
- 作为内存数据,建议都开启,优先从AOF中进行数据恢复,因为它数据更完整。
详细了解:Redis进阶 - 持久化:RDB和AOF机制详解 | Java 全栈知识体系
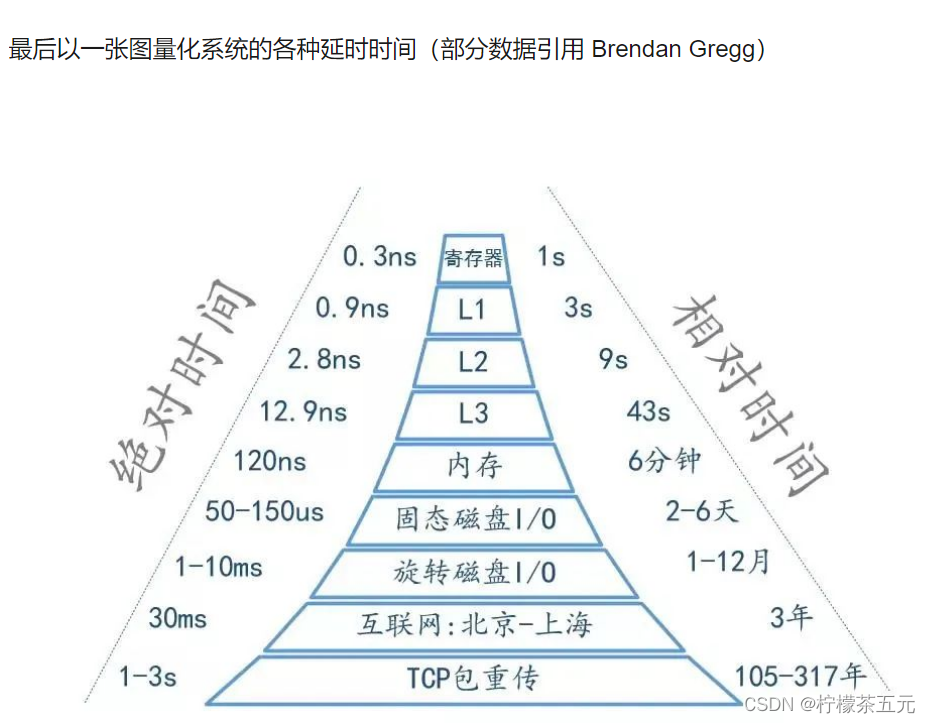
六、基于内存操作
内存直接由 CPU 控制,也就是 CPU 内部集成的内存控制器,所以说内存是直接与 CPU 对接,享受与 CPU 通信的最优带宽。Redis 将数据存储在内存中,读写操作不会因为磁盘的 IO 速度限制。