- RAPTOR Recursive Abstractive Processing for Tree-Organized Retrieval
- ICLR 2024 Stanford
- https://arxiv.org/pdf/2401.18059
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)是一种创建新的检索增强型语言模型,它通过嵌入、聚类和摘要文本模块来构建一个从底层到高层具有不同摘要层的树状结构。这种方法允許模型在推理时从这棵树中检索信息,实现跨文本的不同抽象层的整合。RAPTOR的相关性创新在于它构建了文本摘要的方法,以不同尺度检索上下文的能力,并在多个任务上展示超越传统检索增强语言模型的性能。
研究问题
当前问题:在传统的 RAG 中,系统通常会依赖于检索短文本块。但当处理需要理解长篇上下文的文档时,简单的将文档切割或仅处理其上下文显然不够,在非连续文档、跨文档主题和分散型主题内容时效果不佳。
研究动机:RAPTOR本意是针对目前基于分块的向量检索限制了对上下文的整体信息获取与理解,从而采用了一种构造“从下至上不同级别的摘要树“的优化方法(试想下,很多问题是需要对整个甚至多个文档知识进行理解后才能回答,仅有top_K的分块是不够的?)。
研究内容
研究内容:递归抽象处理树组织检索(Recursive Abstractive Processing for Tree Organized Retrieval)是一种全新且强大的技术,用于以全面的方式对大型语言模型(LLM)进行索引和检索。它采用自下而上的方法,通过对文本段(块)进行聚类和总结,形成一个层级的树状结构。
论文效果:在使用时,RAPTOR能够从这棵树中检索信息,有效整合长篇文档中的信息,覆盖不同的抽象层次。通过实验发现这种递归摘要的检索方式在多个任务上都优于传统的检索增强方法。特别是在需要复杂推理的问答任务上,结合RAPTOR和GPT-4的使用将QuALITY基准测试的性能提高了20%。
研究方法
RAPTOR基于向量Embeddings递归地对文本块进行聚类,并生成这些聚类的文本摘要,从下向上构建树。聚集在一起的节点是兄弟姐妹;父节点包含该集群的文本摘要。具体的方法如下:
- 文本分割
- 文本向量表示
- 文本聚类
- 文本摘要
- 创建树节点
- 递归分聚类以及摘要
- 文档检索
文本切割
将检索语料库拆分为100个tokens的短的连续的chunk,类似于传统方法
保持句子完整,即使超过100个tokens,以保持连贯性
文本向量表示
嵌入文本块使用SBERT获得密集的向量表示
SBERT——一个基于BERT的编码器(multi-qa-mpnet-base-cos-v1)对这些文本进行向量化。这些块及其相应的SBERT向量形成了RAPTOR树结构的叶节点。
文本聚类
- 采用软聚类使用高斯混合模型和UMAP降维
- 更改UMAP参数以识别全局和本地集群
- 采用贝叶斯信息准则进行模型选择,确定最优聚类数量
论文聚类方法是使用软聚类(soft clustering),其中节点可以属于多个聚类,而不需要固定数量的聚类。
高斯混合模型(GMMs):GMMs假设数据点是从几个高斯分布的混合中生成的。给定N个文本段的集合,每个文本段表示为一个维密集向量嵌入,文本向量x给定其在第k个高斯分布中的可能性为:
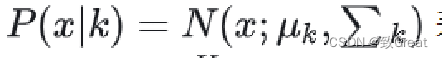
总概率分布是一个加权组合
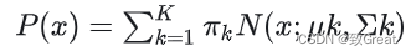
UMAP:Uniform Manifold Approximation and Projection (UMAP),一种用于降维的流形学习技术。向量的高维性对传统GMMs构成挑战,因为距离度量在高维空间中用于测量相似性时可能表现不佳。为了缓解这一点,本文使用了Uniform Manifold Approximation and Projection (UMAP),一种用于降维的流形学习技术。UMAP中的最近邻参数n_neighbors决定了保留局部和全局结构之间的平衡,作者用算法变化n_neighbors来创建一个层次化的聚类结构:它首先识别全局聚类,然后在这些全局聚类中进行局部聚类。
贝叶斯信息准则(BIC)
如果局部聚类的组合上下文超过了摘要模型的token阈值,本文的算法会在聚类内递归应用聚类,确保上下文保持在token阈值内。为了确定最优聚类数量,该算法使用贝叶斯信息准则(BIC)进行模型选择。
BIC不仅惩罚模型复杂性,还奖励拟合优度(goodness of fit)。
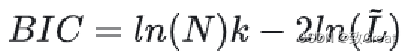
给定GMM的BIC是 ,其中N 是文本段(或数据点)的数量,k 是模型参数的数量,L 是模型的似然函数的最大化值。在GMM的上下文中,参数数量k是输入向量的维度和聚类数量的函数。
文本摘要
使用LLM来总结每个簇(cluster)中所有chunks
生成捕获关键信息的简明摘要
实验中使用gpt-3.5-turbo来生成摘要。
尽管摘要模型通常产生可靠的摘要,但是会有大约4%的摘要包含轻微的幻觉。这些幻觉没有传播到父节点,并且对问答任务没有可辨别的影响。
创建节点
聚类块+相应的摘要=新的树节点,生成的总结构成了树的节点,高层次的节点提供了更抽象的概括。
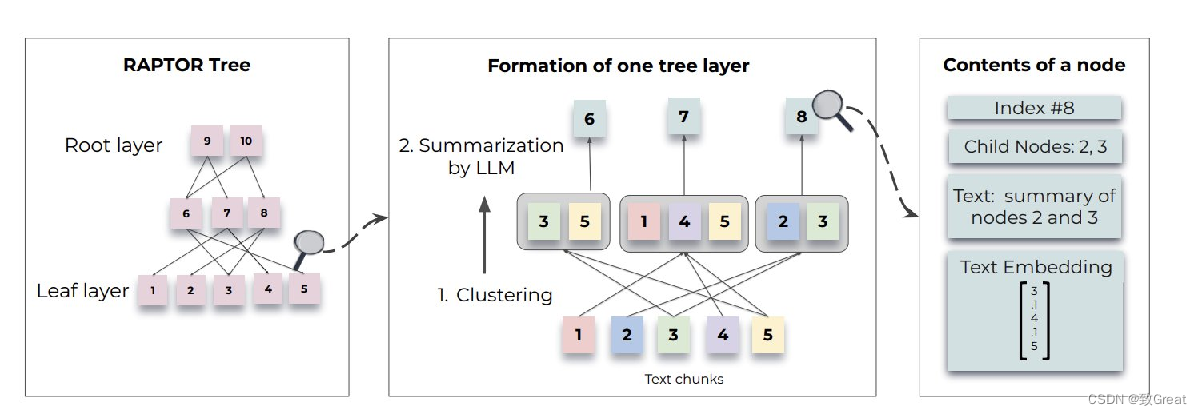
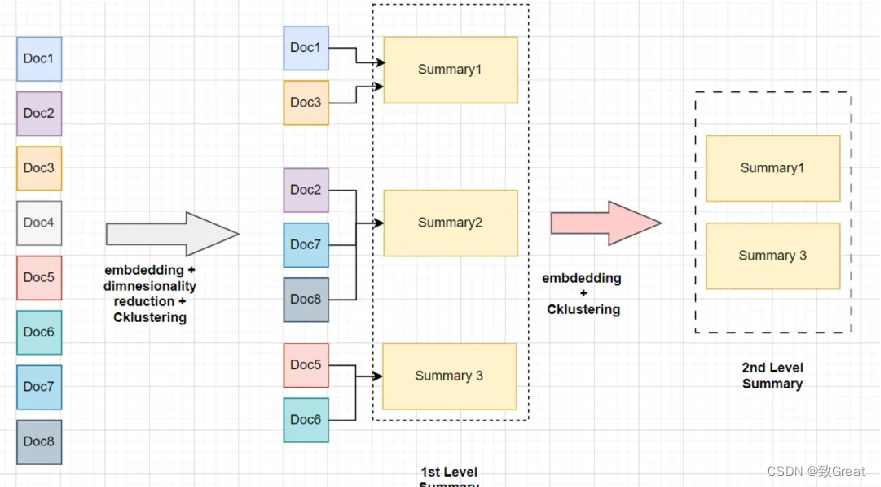
递归分聚类以及摘要
重复 steps 2-5: 重新嵌入摘要,集群节点,生成更高级别的摘要
从下向上形成多层树
直到聚类不可行
检索方法
两种方法:树遍历(自上而下一层一层)或折叠树(扁平视图)
对于每一个,计算查询和节点之间的余弦相似度,以找到最相关的
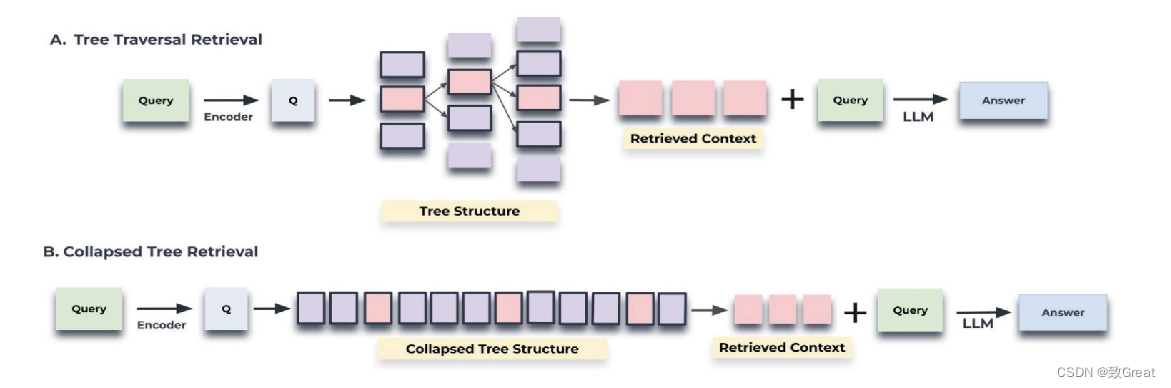
树遍历和折叠树检索机制的示意图。树遍历从树的根层开始,并基于与查询向量的余弦相似性检索顶部k(在这里,是top-1)个节点。在每个层级,它从上一层的top-k的子节点中检索top-k个节点。折叠树将树折叠为单个层级,并基于与查询向量的余弦相似性检索节点,直到达到阈值标记数为止。折叠树方法通过同时考虑树中的所有节点,提供了一种更简单的寻找相关信息的方式,这种方法将多层树压缩为单一层,使所有节点处于同一层级进行比较
实验在QASPER数据集的20个story上测试了这两种方法(详见图3),树折叠方法表现更佳
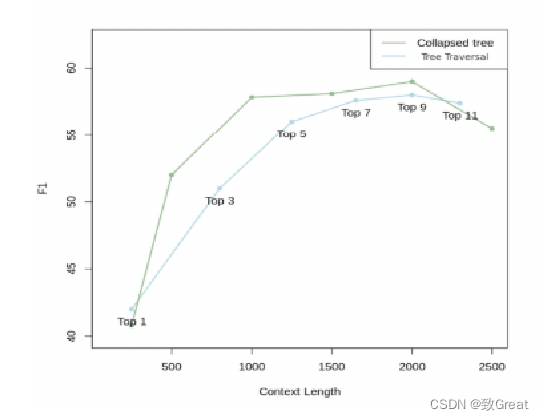
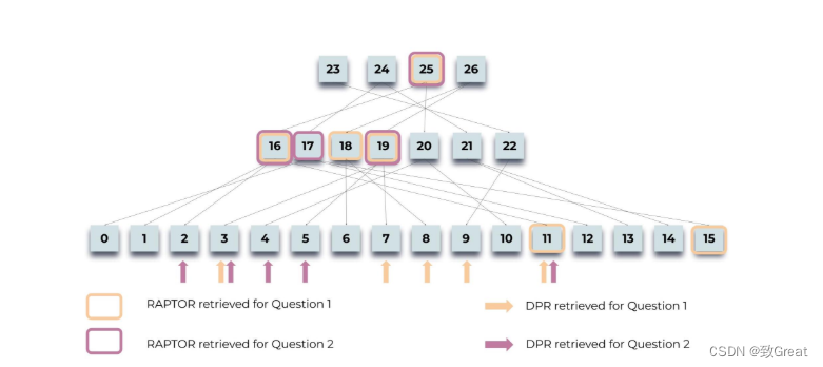
查询过程:展示RAPTOR如何检索关于灰姑娘故事的两个问题的信息:“故事的中心主题是什么?”和“灰姑娘是如何找到一个幸福结局的?”。突出显示的节点表示RAPTOR的选择,而箭头指向DPR的叶子节点。值得注意的是,RAPTOR的上下文通常包含由DPR检索的信息,直接或在较高层的摘要中。
实验结果
RAPTOR的性能通过三个问答数据集进行评估:NarrativeQA、QASPER和QuALITY。
- NarrativeQA包含基于书籍全文和电影剧本的问答对,要求对整个叙事有全面理解。
- QASPER涵盖1,585篇NLP论文中的5,049个问题,探索全文中嵌入的信息。
- QuALITY包含多项选择问题,每个问题都有约5,000个token的上下文段落,评估在中等长度文档上的检索系统性能。
各数据集使用标准的BLEU、ROUGE、METEOR和F1评估指标,并在QuALITY的HARD子集上报告准确率,该子集包含大多数人类注释者在限时设置中回答错误的问题。
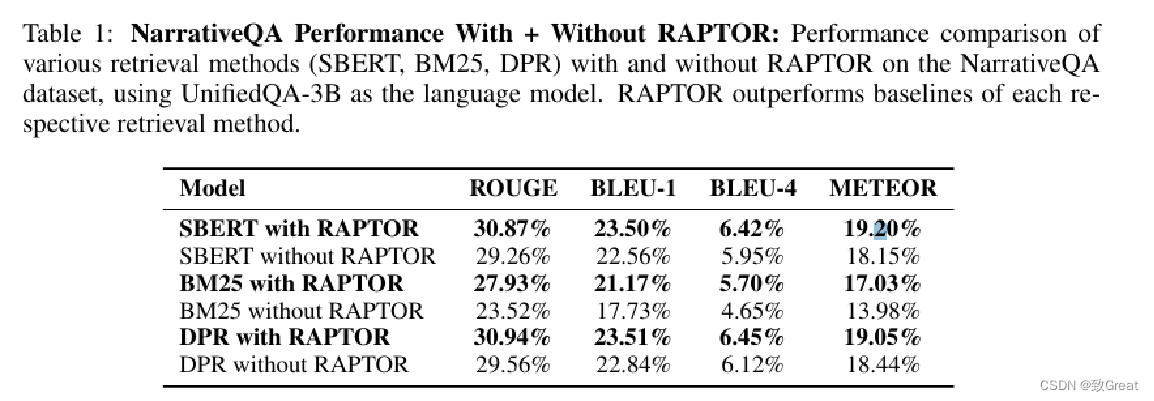
实验结果表明,当RAPTOR与任何检索器结合使用时,在所有数据集上始终优于各自的检索器。
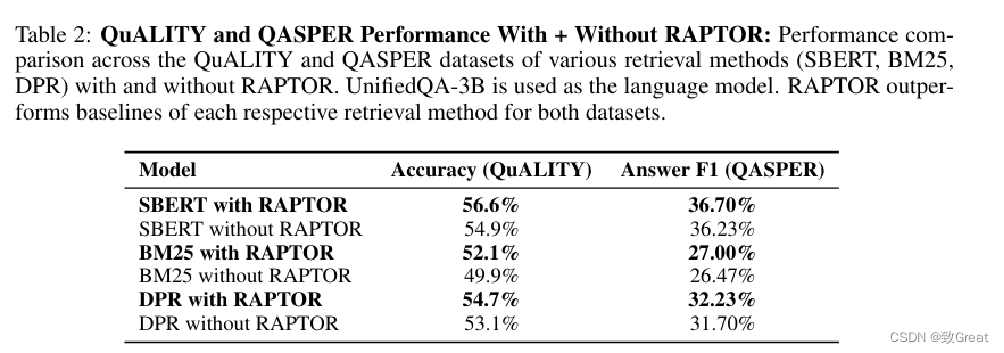
QASPER 数据集上基于不同语言模型(GPT-3、GPT-4、UnifiedQA 3B)及多种检索方法的 F-1 分数对比分析。
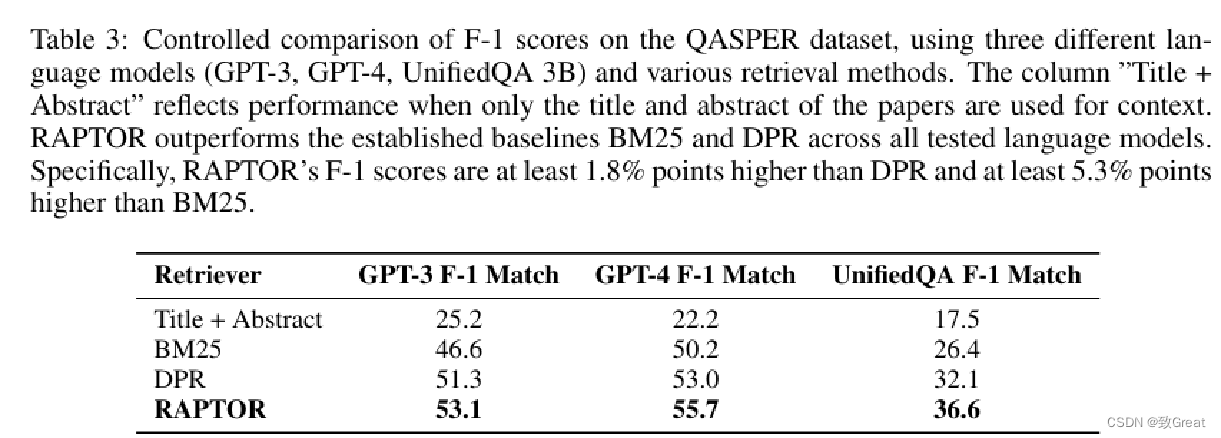
表 4: 在 QuALITY 开发数据集上,针对两种不同的语言模型(GPT-3、UnifiedQA 3B)使用不同检索方法的准确性对比。RAPTOR 在准确度上至少领先传统方法 BM25 和 DPR 2.0%。
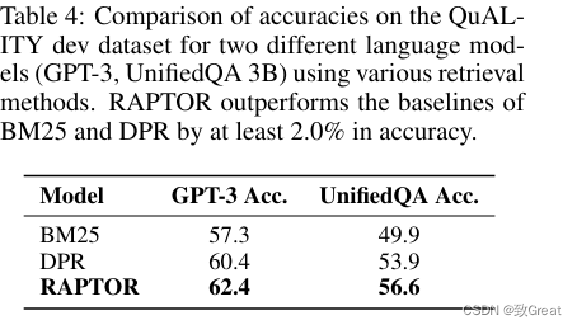
表 5: 在 QASPER 数据集上,各模型 F-1 匹配得分的对比结果。

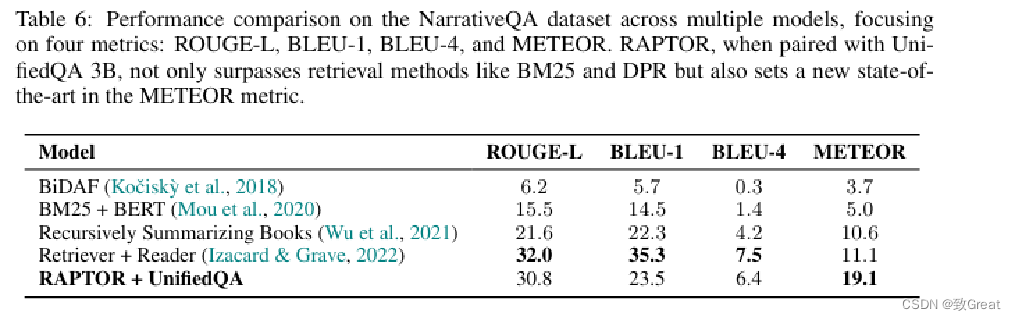
RAPTOR 与 UnifiedQA 3B 搭配使用时,不仅超越了 BM25 和 DPR 等检索方法,还在 METEOR 指标中创下了新的最高水平
在需要复杂推理的问答任务上,结合RAPTOR和GPT-4的使用将QuALITY基准测试的性能提高了20%。
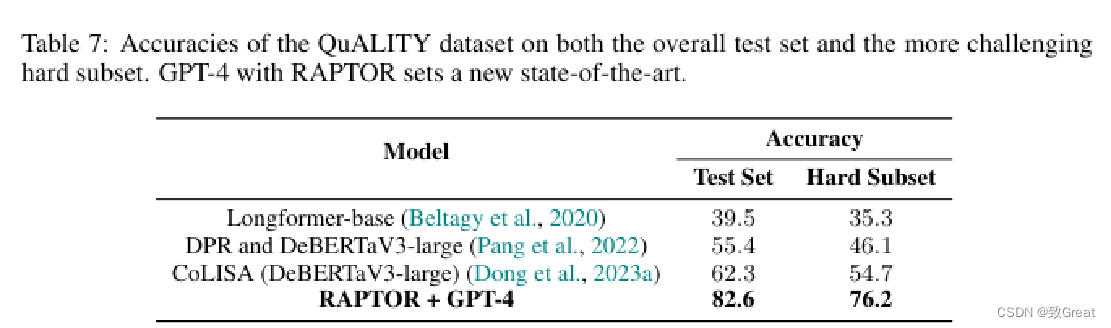
表 8:RAPTOR 在 QuALITY 数据集中查询 Story 1 的不同树层时的性能。列表示不同的起点(最高层),行表示查询的不同层数。

检索效率
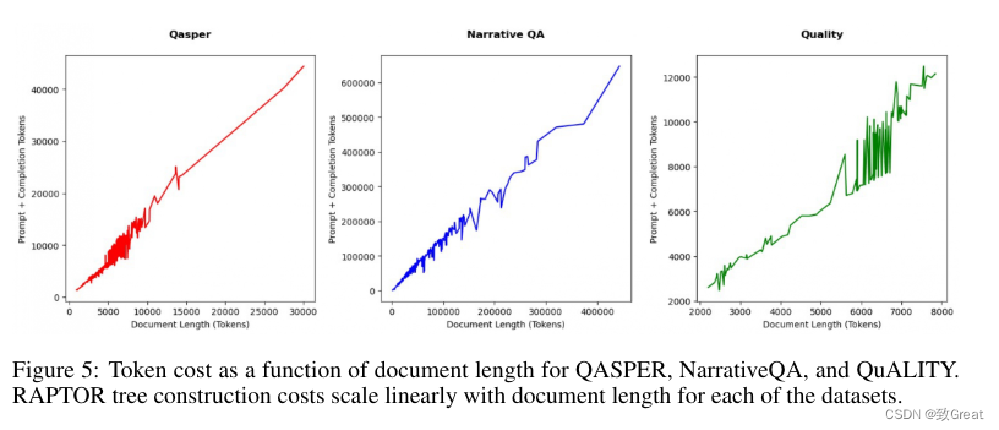
Token成本是 QASPER、NarrativeQA 和 QuALITY 文档长度的函数。
RAPTOR 树构建成本与每个数据集的文档长度成线性比例。
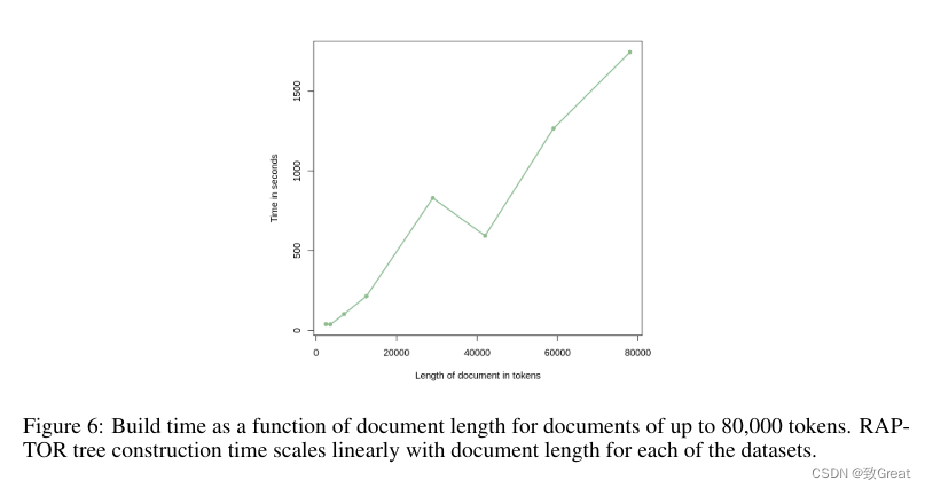
对于最多包含 80,000 个Tokens的文档,构建时间是文档长度的函数。对于每个数据集,RAPTOR 树的构建时间与文档长度成线性比例
聚类实验
表 9 显示了消融研究的结果。该消融研究的结果清楚地表明,与基于新近度的树方法相比,使用 RAPTOR 的聚类机制可以提高准确率。这一发现证实了我们的假设,即 RAPTOR 中的聚类策略在捕获同类内容进行总结方面更有效,从而提高了整体检索性能。

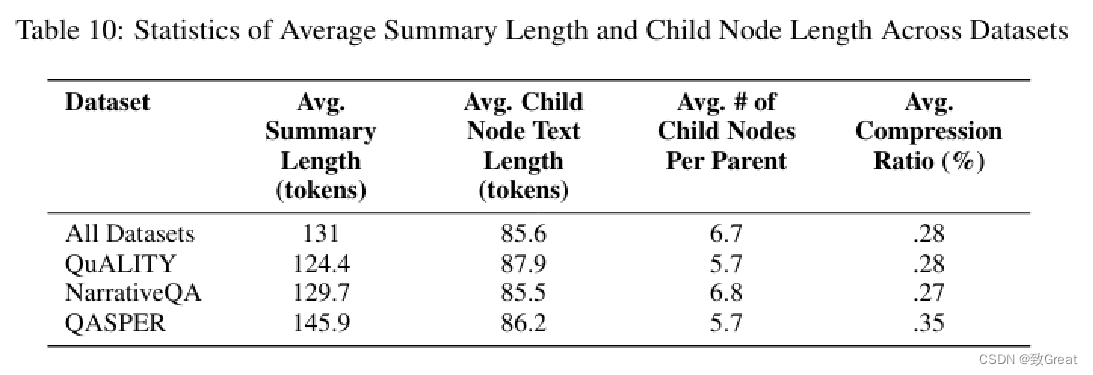
数据集统计和压缩率
表明压缩率为 72%。平均摘要长度为 131 个标记,平均子节点长度为 86 个标记。
摘要提示

RAPTOR方案的优点
- 在不同层次的多个级别上构建了语义表示并实施嵌入,提高了检索的召回能力
- 可以有效且高效的回答不同层次的问题,有的问题在低阶节点解决,有的则由高阶节点来完成
- 适合需要多个文档的理解才能回答的输入问题,因此对于综合性的问题有更好的支持
参考资料
- https://luxiangdong.com/2024/02/07/kym/
- https://developer.volcengine.com/articles/7370376932045062195
- https://mp.weixin.qq.com/s/KqJt4-Yhab5chi8YJglMiw