一、前言
RAG(检索增强生成)应用最具挑战性的方面之一是如何处理复杂文档的内容,例如 PDF 文档中的图像和表格,因为这些内容不像传统文本那样容易解析和检索。前面我们有介绍过如何使用 LlamaIndex 提供的 LlamaParse 技术解析复杂PDF文档(文档中包含图片和表格)LlamaParse 技术整体来看,对于PDF文档常规文本的提取还是比较准确的,但对于表格内容的处理,检索准确率依然还存在比较大的空间,是否还有其它更好的方案来解决呢,今天我们来继续介绍几种与嵌入式表格相关的 RAG 策略,剖析文档解析和检索的技术细节,同时提供一些代码示例以便大家更好地理解其原理。此外,本文还将分析和比较这些策略的优缺点。
在正式开始之前,为了让新关注的小伙伴更全面地理解和应用RAG技术,我把之前写过的一些 RAG 技术相关的文章按照从基础到高级的顺序梳理了一个目录指引,方便大家循序渐进地快速了解 RAG 的精髓。
1.1、RAG 技术发展趋势:
《RAG 2.0》:RAG 技术迎来2.0时代!这篇文章介绍了新一代企业级AI系统RAG 2.0,它通过端到端优化语言模型和检索器,全面提升了传统RAG系统的性能,并在多个领域取得了突破性进展。想了解RAG技术的最新发展方向?这篇文章不容错过!
1.2、RAG 核心原理和关键技术:
《智能模型新篇章:RAG + Fine-Tuning 混合增强策略》
如何让大模型既博学又专精?这篇文章深入探讨了如何结合RAG和微调技术,让语言模型在特定领域表现更出色,并详细介绍了两种混合增强策略:RAFT 和 RoG,为构建更强大的AI系统提供了新的思路。
《RelayAttention:让大型语言模型更高效地处理长提示符》
大模型处理长文本效率低?这篇文章介绍了一种名为 RelayAttention 的全新注意力机制,它通过减少内存访问冗余,显著提升了大模型处理长文本的效率,让AI更“快”一步。
1.3、RAG 技术应用和实践:
《RankLLM:RAG架构下通过重排序实现精准信息检索》
如何让RAG系统找到最精准的答案?这篇文章介绍了一种基于大型语言模型的重排序方法 RankLLM,无需训练数据即可提升信息检索的精度,为构建高效RAG系统提供了新的思路。
《高级RAG检索中的五种查询重写策略》
如何让大模型更好地理解用户的提问?这篇文章介绍了五种查询重写策略(包括子问题查询、HyDE 查询转换、Query2doc、回溯提示和迭代检索生成),帮助你优化RAG系统中的信息检索过程,让AI更“懂”你。
《spRAG:一个处理密集非结构化文本复杂检索的 RAG 框架》
面对海量文本,如何精准定位关键信息?这篇文章介绍了专门处理密集非结构化文本的RAG框架 spRAG,它采用 AutoContext 和 RSE 技术,显著提升了处理复杂查询的准确性。
《LlamaParse:RAG中高效解析复杂PDF的最佳选择》
PDF文档解析难题如何解决?这篇文章介绍了高效的PDF解析技术 LlamaParse,它能够轻松处理复杂PDF文档(包含文本、图像和表格)的检索和上下文理解难题,并与LlamaIndex框架无缝集成,让信息提取更轻松。
1.4、特定领域RAG应用:
《RAFT:让大型语言模型更擅长特定领域的 RAG 任务》
如何让大模型在特定领域更专业?这篇文章介绍了一种名为 RAFT 的微调技术,它将RAG与特定领域的微调相结合,让大模型在特定领域的应用中表现更出色。
《特定领域 RAG 新突破:LlamaPack 实现 RAFT 论文方法》
想轻松创建特定领域RAG数据集?这篇文章介绍了如何使用 LlamaIndex 和 LlamaPack 来实现 RAFT 论文中的方法,简化数据集创建过程,让特定领域RAG应用开发更便捷。
《RAGFlow:基于OCR和文档解析的下一代 RAG 引擎》
想体验功能强大的开源RAG引擎?这篇文章介绍了 RAGFlow,它基于深度文档理解技术,支持多种格式的文档处理,并提供可视化界面和人工干预功能,为构建高效RAG系统提供了新的选择。
二、解析和检索嵌入式表格
解析 PDF 文件中的嵌入式表格一直是一项非常有挑战的技术。这是因为 PDF 文件中的表格可能使用不同的编码和字体,甚至可能以图像的形式存在,需要 OCR(光学字符识别)技术才能识别。此外,PDF 文件中的表格具有复杂的格式和布局,包括合并单元格、嵌套表格和多列布局,这使得表格数据的识别和提取变得复杂。复杂的表格结构、跨越多页的表格和不一致性进一步增加了解析的难度。
在正确解析表格内容后,RAG 应用还需要根据解析的内容理解表格,包括表格中每个字段的含义和结构以及整个表格所代表的整体含义。只有这样,应用才能根据用户的查询检索相应的表格内容,使 LLM(大语言模型)能够更好地回答用户问题。
2.1、闭源大模型PDF解析能力评估
我们前面介绍的很多种 RAG 解决方案主要还是面对一些私有化部署的场景,因为数据隐私要求,只能考虑开源大模型的情况,为了有效解决大模型上下文窗口及数据实时性的问题,考虑结合了 RAG 增强检索来实现外挂一些文档进行语义检索,但也有很多情况其实不需要私有化,只要不涉及安全问题和数据隐私问题,加之最近大模型的价格下调,一些闭源大模型本身能力很增强了不少,使用成本相对去年降低了很少,我们不妨先来看看这些主流大模型对于PDF文档的解析和检索能力如何:
本次主要使用论文《Attention Is All You Need》在GPT-4o、Gemini 1.5 Flash、Gemini 1.5 Pro、KimiChat、智谱清言、天工AI、文心一言、豆包AI、零一万物(万知)上进行了测试,除了Gemini 1.5 Flash、豆包AI、文心一言3.5没给出正确答案外,其余的模型基本上都能给出正确答案,说明大模型对于复杂PDF文档确实做了一些精细化的加工处理。

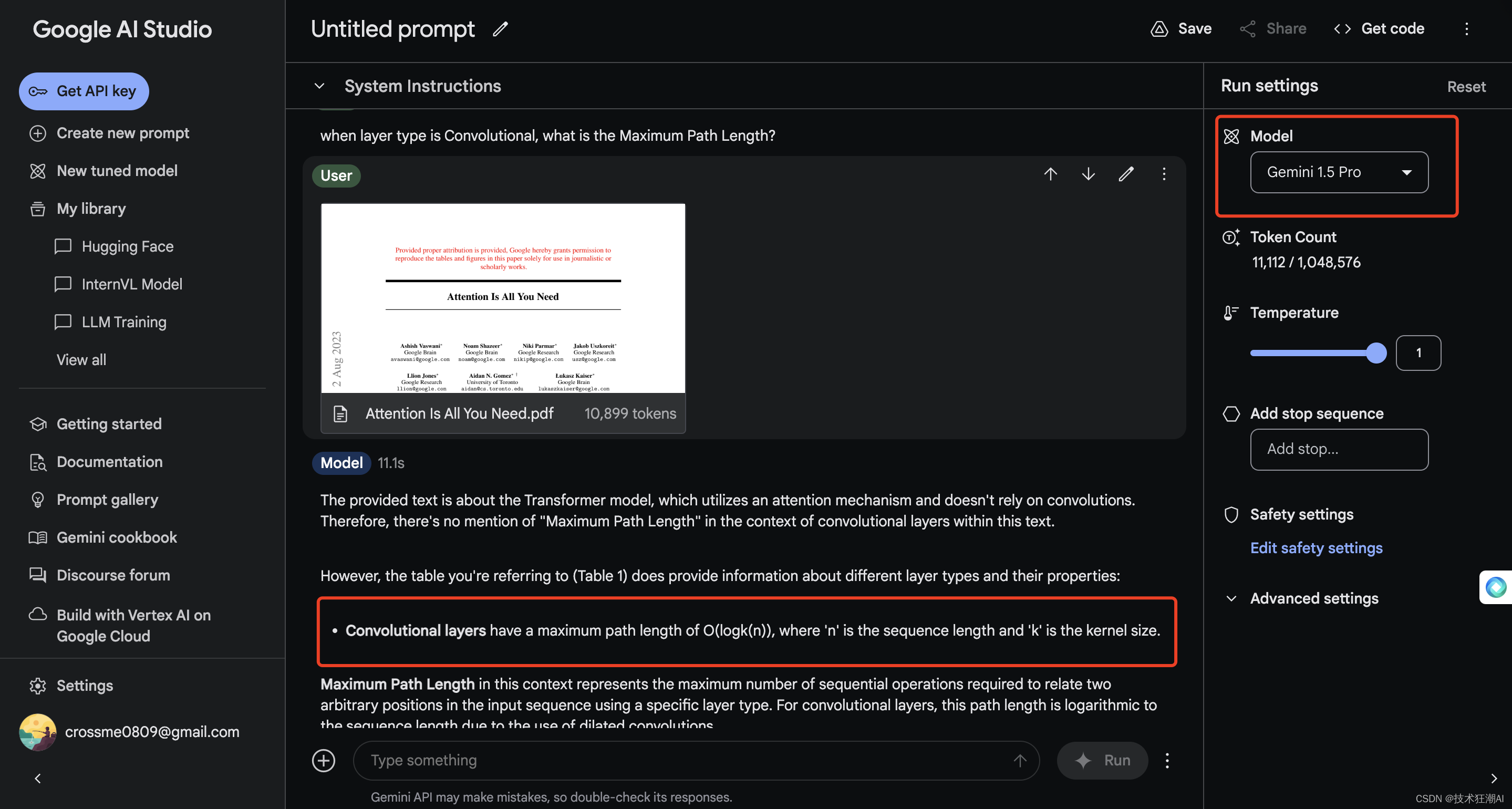
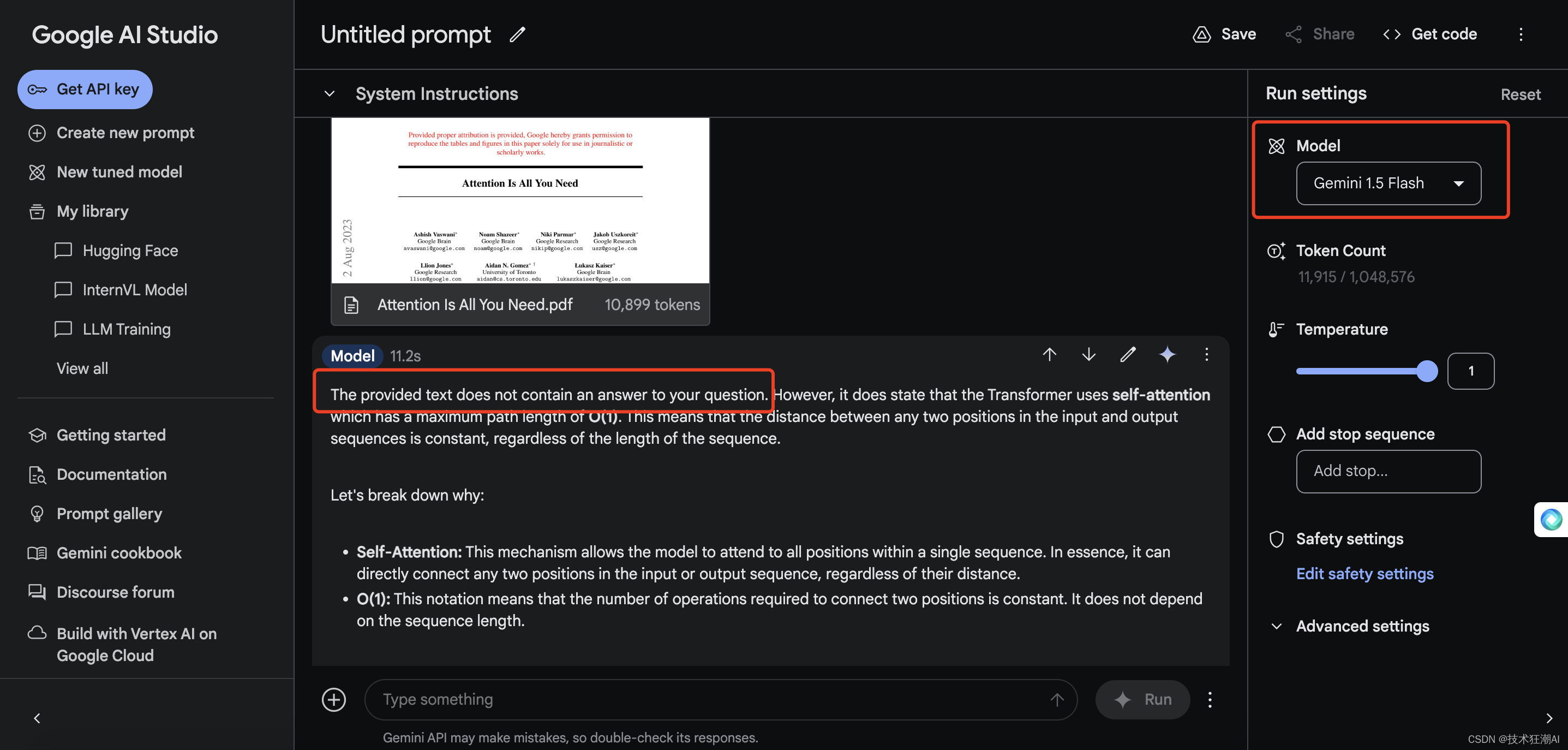
以上,我们简单了解了一下互联网一些闭源的大模型对于PDF文档中的表格解析和检索的能力后,接下来我们继续今天的主题讨论一下在开源大模型尚不具备这种复杂文档处理能力或者模型太多,成本过高的情况下,如何使用 RAG 增强检索来实现这个目标。
幸运的是,LlamaIndex 为解析和检索表格提供了方便实用的功能,使开发人员能够更轻松地应对这些挑战。下面,我们将介绍几种结合 LlamaIndex 处理嵌入式表格的 RAG 策略。
三、Nougat 策略
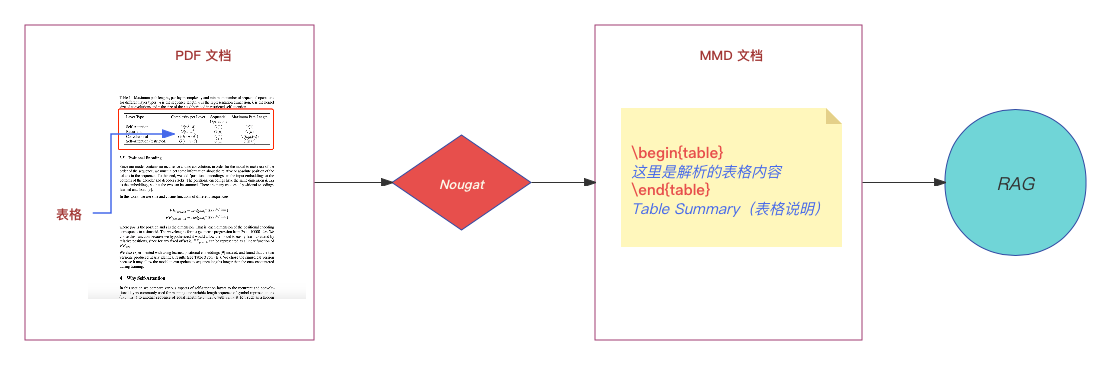
第一种策略是使用 Nougat 等工具进行端到端文档识别,以解析 PDF 文档并将表格内容转换为结构化文本数据,然后将其应用于常规的 RAG 流程(索引、存储、检索)。
3.1、Nougat 简介
Nougat 是 Meta 开发的一种自然语言处理(NLP)工具包,旨在简化多语言文本数据的处理和分析。它提供了丰富的功能,包括文本预处理、词嵌入和特征提取。Nougat 可以轻松解析 PDF 格式的学术文档,提取数学公式和表格,并将它们转换为结构化数据,以便进行后续的处理和分析。
安装 Nougat 非常简单,只需使用 pip 即可:
pip install nougata-ocr安装完成后,可以使用 Nougat 的命令行工具来解析 PDF 文档:
nougat path/to/file.pdf -o output_directory -m 0.1.0-base --no-skipping关于 Nougat 解析文档命令的相关参数说明:
- path/to/file.pdf:要解析的 PDF 文件的路径。
- -o output_directory:用于存储解析后的文本数据的输出目录。解析后的文件采用 mmd 格式,这是一种类似于 Mathpix Markdown 语法的轻量级标记语言。
- -m 0.1.0-base:指定要使用的模型名称。该模型将在第一次使用时下载。
- --no-skipping:一个选项,用于不跳过解析错误。
注意:建议在 GPU 机器上执行 Nougat 命令,因为它在 CPU 机器上可能非常慢。下载的模型将存储在 ~/.cache/torch/pub/nougat-0.1.0-base 目录中,大小约为 1.4GB。
这里我们使用 Nougat 解析了 AI 领域的著名论文《Attention is All You Need》。解析后,我们将原始表格与解析后的表格数据进行了比较。以下是一个表格的比较示例:

解析后的表格数据如下:
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \\ \hline Self-Attention & \(O(n^{2}\cdot d)\) & \(O(1)\) & \(O(1)\) \\ Recurrent & \(O(n\cdot d^{2})\) & \(O(n)\) & \(O(n)\) \\ Convolutional & \(O(k\cdot n\cdot d^{2})\) & \(O(1)\) & \(O(log_{k}(n))\) \\ Self-Attention (restricted) & \(O(r\cdot n\cdot d)\) & \(O(1)\) & \(O(n/r)\) \\ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. \(n\) is the sequence length, \(d\) is the representation dimension, \(k\) is the kernel size of convolutions and \(r\) the size of the neighborhood in restricted self-attention.解析后的表格数据包含在 \begin{table} 和 \end{table} 标签中。表格的每一行用 \\ 分隔,每一列用 & 分隔。\end{table} 标签后面的文本是对表格的说明。
3.2、使用 LlamaIndex 检索表格数据
一旦理解了表格的解析格式,就可以编写代码来提取这些信息。下面我们用 Python 正则来提取表格中的内容:
import re
mmd_path = "attention_is_all_you_need.mmd"
# 打开并读取文件内容
with open(mmd_path, "r") as file:
content = file.read()
# 使用正则表达式匹配表格内容和表格后的行
pattern = r"\\begin{table}(.*?)\\end{table}\n(.*?)\n"
matches = re.findall(pattern, content, re.DOTALL)
tables = []
# 添加匹配结果
for match in matches:
tables.append(f"{match[0]}{match[1]}")我们使用正则表达式来匹配表格内容和表格后面的行。 match[0] 包含表格内容,match[1] 包含表格后面的文本。然后将匹配结果保存到 tables 列表中。
接下来,就可以使用 LlamaIndex 对解析后的表格数据进行索引和检索。以下是一个示例:
from llama_index.core import VectorStoreIndex
from llama_index.core.schema import TextNode
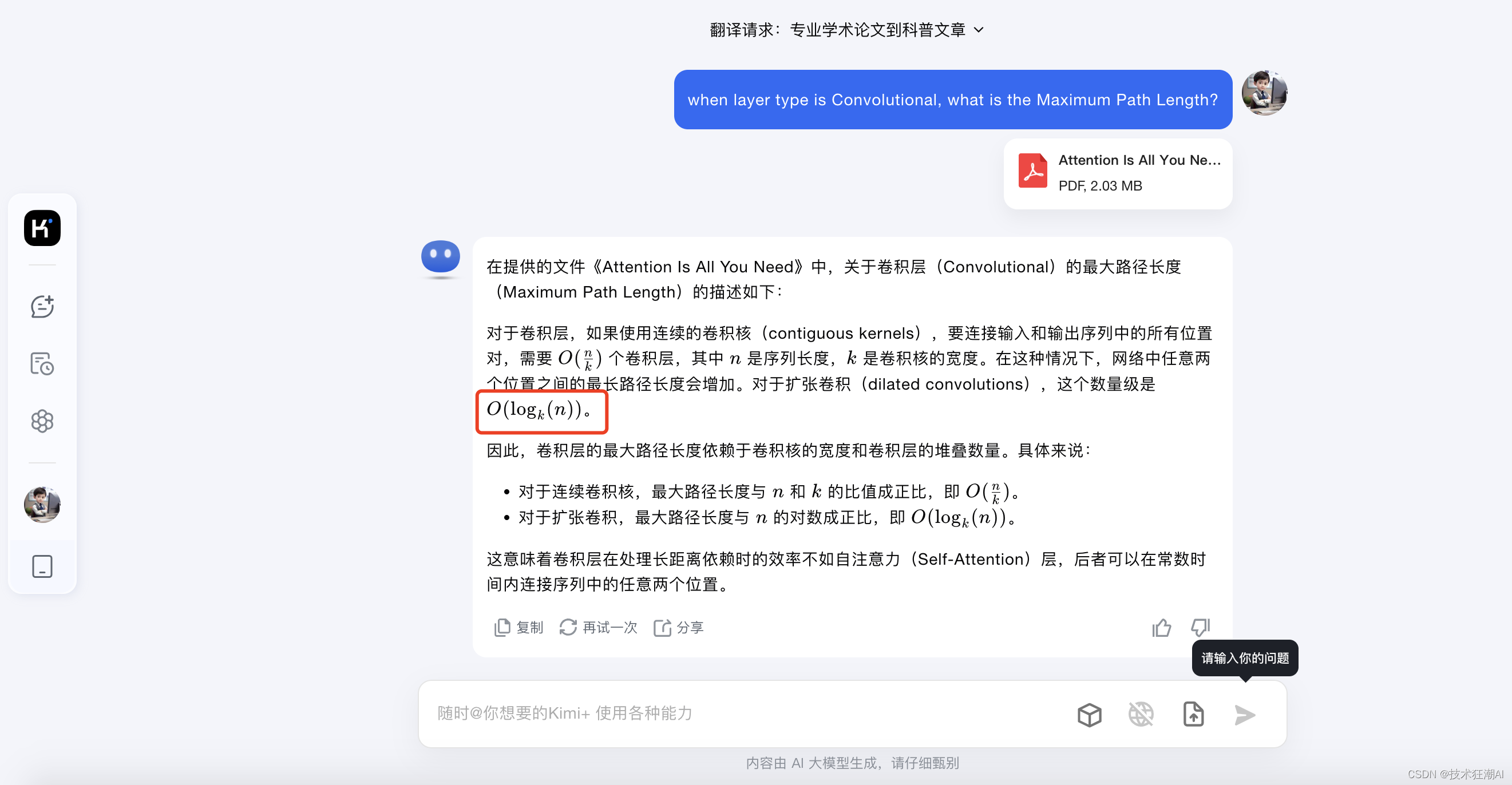
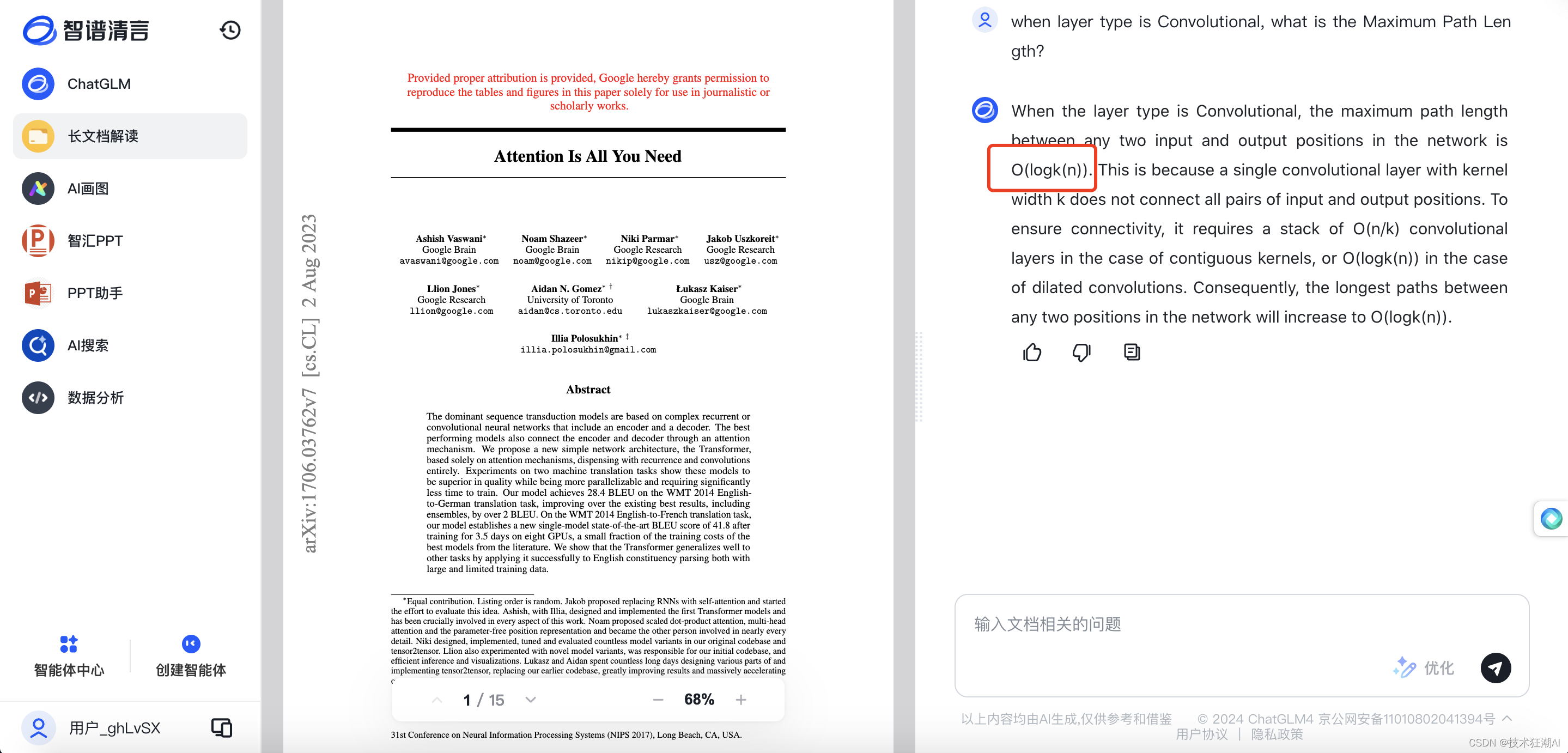
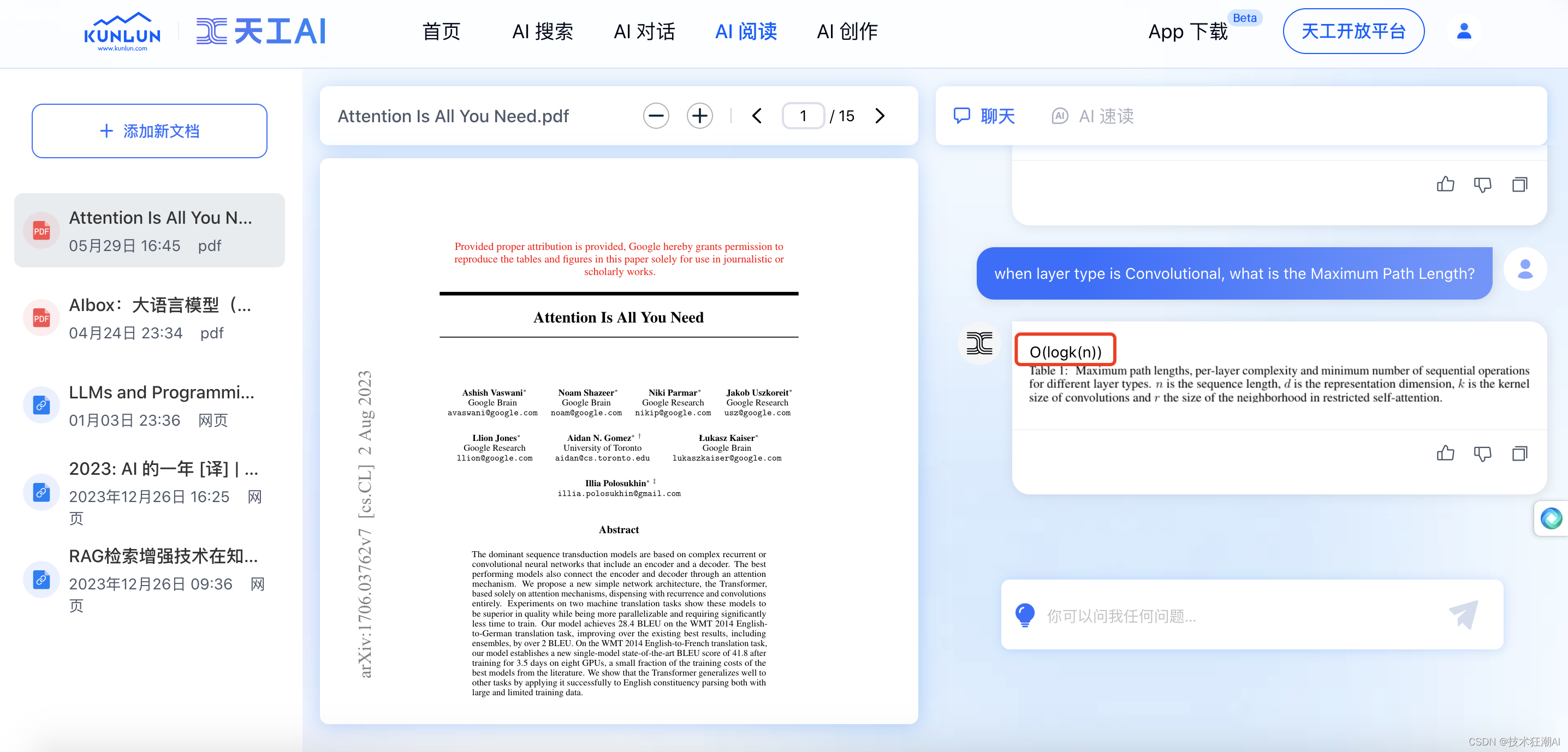
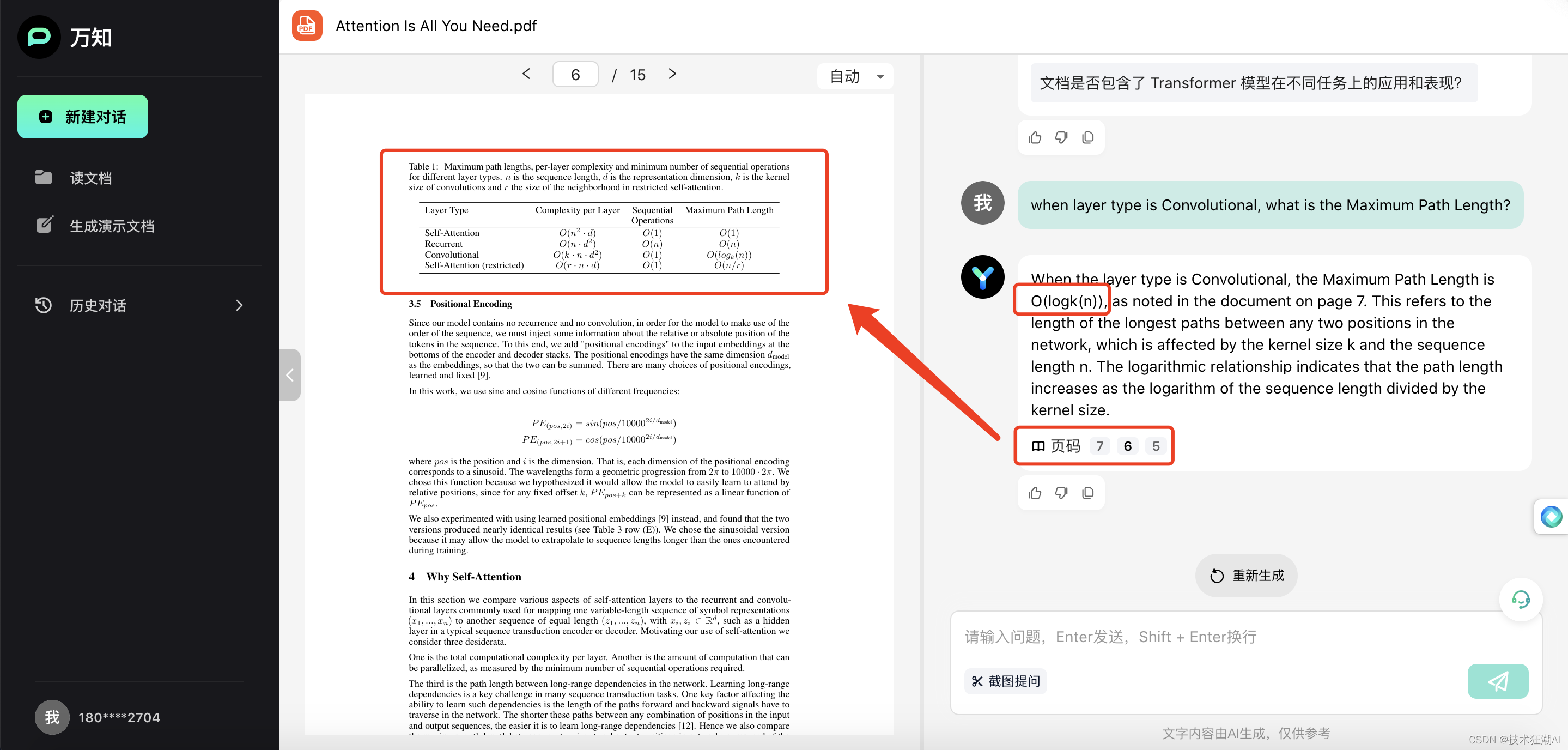
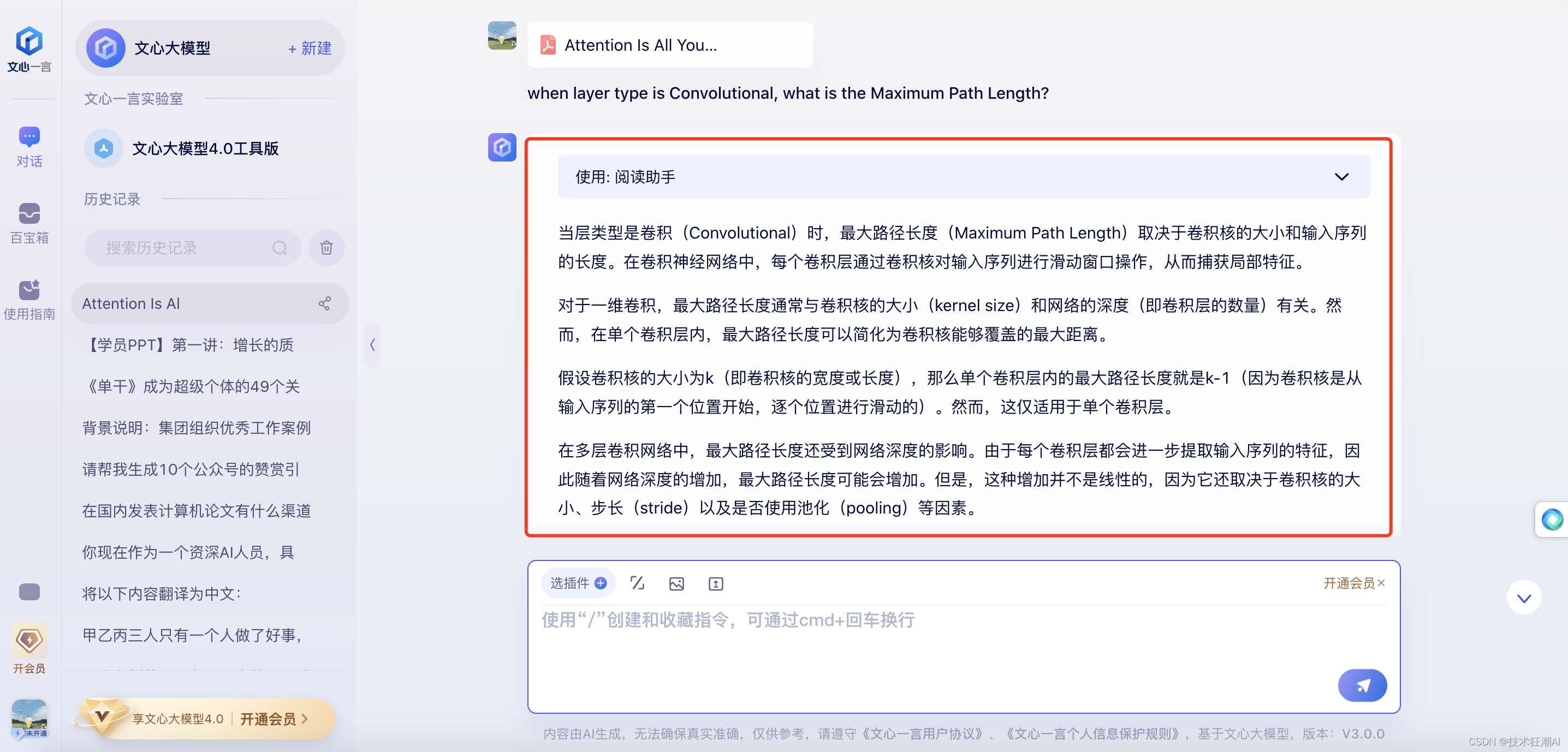
question = "when layer type is Convolutional, what is the Maximum Path Length?"
print(f"question: {question}")
nodes = [TextNode(text=t) for t in tables]
vector_index = VectorStoreIndex(nodes)
query_engine = vector_index.as_query_engine(similarity_top_k=2)
response = query_engine.query(question)
print(f"answer: {response}")
print("Source nodes: ")
for node in response.source_nodes:
print(f"
node text: {node.text}")我们首先将 tables 列表中的表格内容转换为 TextNode 对象。 然后,使用 VectorStoreIndex 将 TextNode 对象转换为索引。 最后,使用 query 方法检索问题的答案。
RAG 检索结果如下:
question: when layer type is Convolutional, what is the Maximum Path Length?
answer: The Maximum Path Length for the Convolutional layer type is \(O(log_{k}(n))\).
Source nodes:
node text:
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \\ \hline Self-Attention & \(O(n^{2}\cdot d)\) & \(O(1)\) & \(O(1)\) \\ Recurrent & \(O(n\cdot d^{2})\) & \(O(n)\) & \(O(n)\) \\ Convolutional & \(O(k\cdot n\cdot d^{2})\) & \(O(1)\) & \(O(log_{k}(n))\) \\ Self-Attention (restricted) & \(O(r\cdot n\cdot d)\) & \(O(1)\) & \(O(n/r)\) \\ \hline \hline \end{tabular}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. \(n\) is the sequence length, \(d\) is the representation dimension, \(k\) is the kernel size of convolutions and \(r\) the size of the neighborhood in restricted self-attention.
node text:
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \\ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \\ \hline ByteNet [18] & 23.75 & & & \\ Deep-Att + PosUnk [39] & & 39.2 & & \(1.0\cdot 10^{20}\) \\ GNMT + RL [38] & 24.6 & 39.92 & \(2.3\cdot 10^{19}\) & \(1.4\cdot 10^{20}\) \\ ConvS2S [9] & 25.16 & 40.46 & \(9.6\cdot 10^{18}\) & \(1.5\cdot 10^{20}\) \\ MoE [32] & 26.03 & 40.56 & \(2.0\cdot 10^{19}\) & \(1.2\cdot 10^{20}\) \\ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & \(8.0\cdot 10^{20}\) \\ GNMT + RL Ensemble [38] & 26.30 & 41.16 & \(1.8\cdot 10^{20}\) & \(1.1\cdot 10^{21}\) \\ ConvS2S Ensemble [9] & 26.36 & **41.29** & \(7.7\cdot 10^{19}\) & \(1.2\cdot 10^{21}\) \\ \hline Transformer (base model) & 27.3 & 38.1 & & \(\mathbf{3.3\cdot 10^{18}}\) \\ Transformer (big) & **28.4** & **41.8** & & \(2.3\cdot 10^{19}\) \\ \hline \hline \end{tabular}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.根据我们提的问题,RAG 结果是 O(log_{k}(n)),这与原始表格中的内容相匹配(见下图)。此外,可以看出,在 RAG 过程中,检索到的文档信息包括表 1 和表 2,其中表 1 是我们问题的答案来源。

3.3、优点和缺点
Nougat 这种方法有以下优点和缺点:
优点
- 完美支持解析学术论文文档(对于解析并处理学术论文PDF比较有优势)。
- 解析结果清晰易懂,易于处理。
缺点
- Nougat 是在学术论文上训练的,因此它在解析学术论文文档方面表现出色,但在其他类型的 PDF 文档上可能表现不佳。
- 对英文文档的支持更好;对其他语言的支持有限。
- 需要 GPU 机器进行解析加速。
四、基于 UnstructuredIO 的解决方案
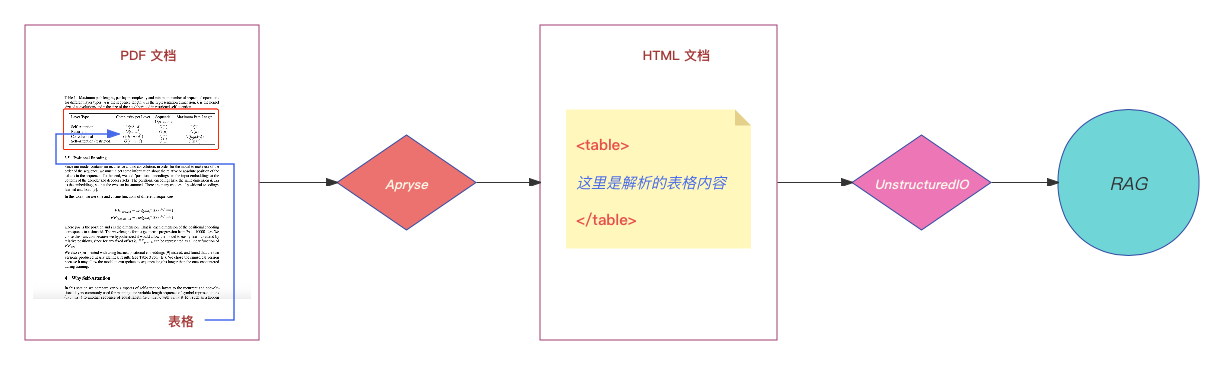
这个解决方案的核心是先将 PDF 文件转换为 HTML 文件,再利用 UnstructuredIO 解析 HTML 文件。由于 LlamaIndex 已经集成了 UnstructuredIO,因此可以很方便地使用 RAG 流程来处理 HTML 文件,包括索引、存储和检索等操作。
为什么要转换为 HTML 文件呢?因为 PDF 文件中的表格内容难以直接识别,而 HTML 文件通常使用表格标签来表示表格,这使得解析和提取表格数据变得更加容易。值得一提的是,在 LlamaIndex 中集成 UnstructuredIO 时,只实现了对 HTML 文件的解析。这可能是因为解析 HTML 文件相对简单,而解析 PDF 文件则需要借助第三方模型和工具,实现起来更加复杂。
4.1、PDF 文件转换为 HTML 文件
在开源社区,有很多工具可以将 PDF 文件转换为 HTML 文件。其中一个比较知名的工具是 pdf2htmlEX。然而,经过测试发现,pdf2htmlEX 解析后的 HTML 文件中,表格内容并不是用表格标签来表示的,而是使用 div 标签(如下所示)。这导致我们无法使用 UnstructuredIO 来解析表格内容,因此需要借助其他工具来完成 PDF 文件的转换。

这里推荐使用 WebViewer 文档工具,它提供了丰富的文档编辑功能,包括我们需要的 PDF 到 HTML 转换功能。WebViewer 还提供了适用于各种编程语言的 SDK 包,方便集成到不同的项目中。接下来,我们将演示如何使用 Python 调用 WebViewer 将 PDF 文件转换为 HTML 文件。
首先,我们需要在 WebViewer 官网注册账号,并获取试用密钥,这个密钥在使用 SDK 包时需要用到。
然后,通过 pip 安装 SDK 包:
pip install apryse-sdk --extra-index-url=https://pypi.apryse.com还需要下载 SDK 包对应的结构化输出模块包(下载地址见文末)。下载完成后,解压缩该包,并将解压后的文件夹放到项目的根目录下,文件夹命名为 Lib。
以下是示例代码:
from apryse_sdk import *
# 使用 PDFNet.Initialize 函数初始化 SDK 包,并传入注册时获取的试用密钥。
PDFNet.Initialize("your_trial_key")
file_name = "demo"
input_filename = f"{file_name}.pdf"
output_dir = "output"
# 使用 PDFNet.AddResourceSearchPath 添加解压后的结构化输出模块包的路径。
PDFNet.AddResourceSearchPath("./Lib")
# 使用 HTMLOutputOptions 设置 HTML 输出选项。
# 这里设置的是将 HTML 输出集成到一个完整的页面中。
htmlOutputOptions = HTMLOutputOptions()
htmlOutputOptions.SetContentReflowSetting(HTMLOutputOptions.e_reflow_full)
# 使用 Convert.ToHtml 转换 PDF 文件,转换后的 HTML 文件保存在输出目录中。
Convert.ToHtml(input_filename, f"{output_dir}/{file_name}.html", htmlOutputOptions)转换完成后,我们可以看到表格内容已经用表格标签来表示了。更多关于使用 WebViewer 将 PDF 文件转换为 HTML 文件的信息,请参考文末链接。
4.2、HTML 文件处理
现在我们有了 HTML 文件,就可以使用 LlamaIndex 中集成的 UnstructuredIO 解析功能来解析表格内容了。以下是一个代码示例:
import os
import pickle
from pathlib import Path
from llama_index.readers.file import FlatReader
from llama_index.core.node_parser import UnstructuredElementNodeParser
reader = FlatReader()
demo_file = reader.load_data(Path("demo.html"))
node_parser = UnstructuredElementNodeParser()
pkl_file = "demo.pkl"
if not os.path.exists(pkl_file):
raw_nodes = node_parser.get_nodes_from_documents(demo_file)
pickle.dump(raw_nodes, open(pkl_file, "wb"))
else:
raw_nodes = pickle.load(open(pkl_file, "rb"))
base_nodes, node_mappings = node_parser.get_base_nodes_and_mappings(raw_nodes)解析 HTML 文件后,我们会得到纯文本节点和包含表格的节点。接下来,我们将使用一个介绍 Qwen-VL 多模态模型的 HTML 页面作为测试数据,该页面包含多个表格。我们先来看看解析后的表格内容:
from llama_index.core.schema import IndexNode, TextNode
# 从解析后的节点数据中找到包含表格的节点,IndexNode 表示包含表格的节点
example_index_nodes = [b for b in base_nodes if isinstance(b, IndexNode)]
# 使用 example_index_nodes[1] 检索第二个表格的数据
example_index_node = example_index_nodes[1]
# 打印出表格内容、索引 ID 和映射的节点内容
print(
f"\n--------\n{example_index_node.get_content(metadata_mode='all')}\n--------\n"
)
print(f"\n--------\nIndex ID: {example_index_node.index_id}\n--------\n")
print(
f"\n--------\n{node_mappings[example_index_node.index_id].get_content()}\n--------\n"
)打印出的节点信息如下所示:
# Table fields
--------
col_schema: Column: Model
Type: string
Summary: Names of the AI models compared
...other columns...
filename: Qwen-VL.html
extension: .html
# Summary of the table
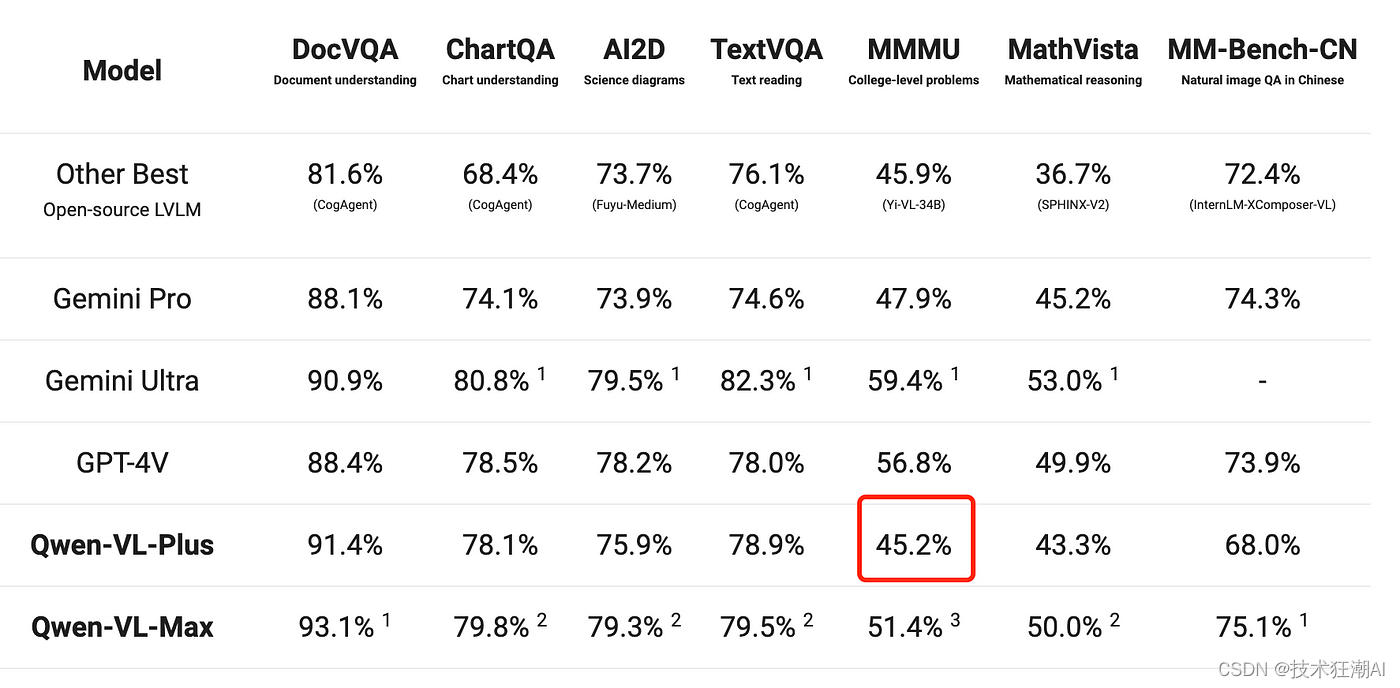
Comparison of performance metrics for different AI models across various tasks such as DocVQA, ChartQA, AI2D, TextVQA, MMMU, MathVista, and MM-Bench-CN.,
with the following table title:
AI Model Performance Comparison,
with the following columns:
- Model: Names of the AI models compared
...other columns...
--------
# Table node ID
--------
Index ID: 41edc9a6-30ed-44cf-967e-685f7dfce8df
--------
# Table data in mapping
--------
Comparison of performance metrics for different AI models across various tasks such as DocVQA, Chart
QA, AI2D, TextVQA, MMMU, MathVista, and MM-Bench-CN.,
with the following table title:
AI Model Performance Comparison,
with the following columns:
- Model: Names of the AI models compared
...other columns...
# Table content in Markdown format
|Model|DocVQA|ChartQA|AI2D|TextVQA|MMMU|MathVista|MM-Bench-CN|
|---|---|---|---|---|---|---|---|
|Other Best Open-source LVLM|81.6% (CogAgent)|68.4% (CogAgent)|73.7% (Fuyu-Medium)|76.1% (CogAgent)|45.9% (Yi-VL-34B)|36.7% (SPHINX-V2)|72.4% (InternLM-XComposer-VL)|
|Gemini Pro|88.1%|74.1%|73.9%|74.6%|47.9%|45.2%|74.3%|
|Gemini Ultra|90.9%|80.8% 1|79.5% 1|82.3% 1|59.4% 1|53.0% 1|-|
|GPT-4V|88.4%|78.5%|78.2%|78.0%|56.8%|49.9%|73.9%|
|Qwen-VL-Plus|91.4%|78.1%|75.9%|78.9%|45.2%|43.3%|68.0%|
|Qwen-VL-Max|93.1% 1|79.8% 2|79.3% 2|79.5% 2|51.4% 3|51.0% 2|75.1% 1|
--------从打印结果可以看出,LlamaIndex 已经总结了表格的每个字段和整个表格,并将表格内容转换成了 Markdown 格式。
接下来,我们将使用 LlamaIndex 的递归检索器来检索表格内容。以下是示例代码:
from llama_index.core import VectorStoreIndex
from llama_index.core.retrievers import RecursiveRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
# 使用 VectorStoreIndex 将解析后的节点数据转换成索引
vector_index = VectorStoreIndex(base_nodes)
# 使用索引构建检索器和查询引擎,设置 similarity_top_k 为 1,表示只返回最相似的结果
vector_retriever = vector_index.as_retriever(similarity_top_k=1)
vector_query_engine = vector_index.as_query_engine(similarity_top_k=1)
# 使用 RecursiveRetriever 构建递归检索器,传入检索器和节点映射信息,然后构建查询引擎
recursive_retriever = RecursiveRetriever(
"vector",
retriever_dict={"vector": vector_retriever},
node_dict=node_mappings,
verbose=True,
)
query_engine = RetrieverQueryEngine.from_args(recursive_retriever)
question = "在各种任务中比较不同AI模型的性能指标。任务“MMMU”中模型“Qwen-VL-Plus”的性能指标是什么?告诉我确切的数字。"
# 使用查询引擎检索问题的答案
response = query_engine.query(question)
# 打印答案
print(f"answer: {str(response)}")
# 显示结果
Retrieving with query id None: In the comparison of performance metrics for different AI models across various tasks. What is the performance metric of the model 'Qwen-VL-Plus' in task 'MMMU'? Tell me the exact number.
Retrieved node with id, entering: 41edc9a6-30ed-44cf-967e-685f7dfce8df
Retrieving with query id 41edc9a6-30ed-44cf-967e-685f7dfce8df: In the comparison of performance metrics for different AI models across various tasks. What is the performance metric of the model 'Qwen-VL-Plus' in task 'MMMU'? Tell me the exact number.
answer: The performance metric of the model 'Qwen-VL-Plus' in the task 'MMMU' is 45.2%.程序运行后,会显示递归检索的调试信息。根据这些信息,我们可以看到表格内容是根据问题检索的,并返回了正确答案:45.2%。这与原始表格数据一致,表明结果正确。
注意: 如果调试信息中没有显示节点 ID,则表示无法根据问题检索到表格内容。这时,最终答案可能不正确,这可能是因为用户的问题与表格的摘要信息不匹配。此时,可以尝试调整问题,然后重新检索。
4.3、准确性验证
前面我们只验证了表格中一个单元格的内容。现在,我们来验证表格中所有单元格的内容,以便粗略估计该方案的准确率。以下是代码示例:
models = [
"Other BestOpen-source LVLM",
"Gemini Pro",
"Gemini Ultra",
"GPT-4V",
"Qwen-VL-Plus",
"Qwen-VL-Max",
]
metrics = ["DocVQA", "ChartQA", "AI2D", "TextVQA", "MMMU", "MathVista", "MM-Bench-CN"]
# 构建 42 个问题,每个问题都询问表格中不同 AI 模型在各种任务上的性能指标
questions = []
for model in models:
for metric in metrics:
questions.append(
f"在比较不同任务中不同AI模型的性能指标时。任务“{metric}”中模型“{model}”的性能指标是什么?告诉我确切的数字。"
)
actual_metrics = [
81.6, 68.4, 73.7, 76.1, 45.9, 36.7, 72.4,
88.1, 74.1, 73.9, 74.6, 47.9, 45.2, 74.3,
90.9, 80.8, 75.9, 82.3, 59.4, 53, 0,
88.4, 78.5, 78.2, 78, 56.8, 49.9, 73.9,
91.4, 78.1, 75.9, 78.9, 45.2, 43.3, 68,
93.1, 79.8, 79.3, 79.5, 51.4, 51, 75.1,
]
actual_answers = dict(zip(questions, actual_metrics))
result = {}
for q in questions:
# 使用查询引擎检索这些问题的答案
response = query_engine.query(q)
answer = str(response
)
result[q] = str(actual_answers[q]) in answer
print(f"question: {q}\nresponse: {answer}\nactual:{actual_answers[q]}\nresult:{result[q]}\n\n")
# 将检索结果与实际性能指标进行比较,并计算准确率
correct = sum(result.values())
total = len(result)
print(f"Percentage of True values: {correct / total * 100}%")计算结果如下:
Retrieving with query id None: In comparison of performance metrics for different AI models across various tasks. What is the performance metric of the model 'Other BestOpen-source LVLM' in task 'DocVQA'? Tell me the exact number.
Retrieved node with id, entering: 41edc9a6-30ed-44cf-967e-685f7dfce8df
Retrieving with query id 41edc9a6-30ed-44cf-967e-685f7dfce8df: In comparison of performance metrics for different AI models across various tasks. What is the performance metric of the model 'Other BestOpen-source LVLM' in task 'DocVQA'? Tell me the exact number.
question: In the comparison of performance metrics for different AI models across various tasks. What is the performance metric of the model 'Other BestOpen-source LVLM' in task 'DocVQA'? Tell me the exact number.
response: 81.6%
actual:81.6
result:True
...other questions...
Percentage of True values: 66.66666666666666%在验证了表格中所有单元格的内容后,我们发现准确率为 66.67%。说明这种方法在检索表格内容时并不一定是 100% 准确率,但与现有方法相比,该准确率已经相对较高了。
4.4、优点和缺点
该方案的优缺点如下:
优点
- 无需使用 OCR 技术。
- 无需使用 GPU 服务器转换 PDF 文件。
缺点
- 需要使用第三方工具将 PDF 文件转换为 HTML 文件。
- 用户问题必须与表格的摘要信息相匹配才能检索到正确结果。
五、基于 GPT4o 的解决方案
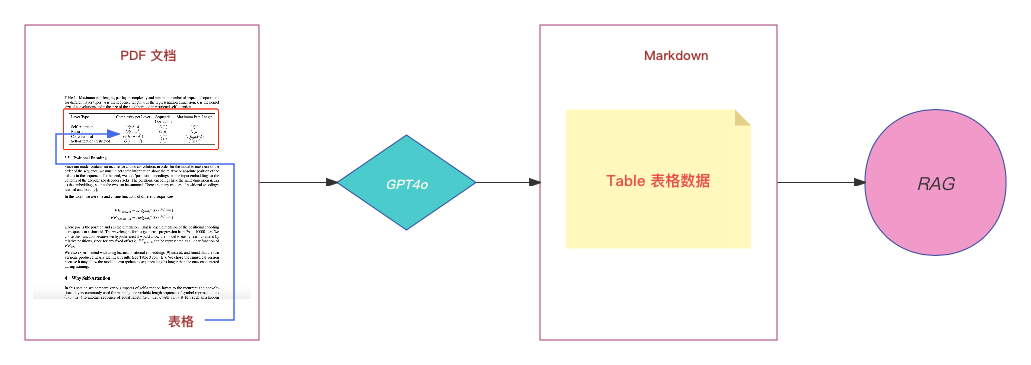
为了处理表格内容,我们可以采用 OpenAI 最新的模型 GPT4o。GPT4o 在图像识别能力方面有了显著提升,能够轻松识别先前 GPT4 模型无法识别的内容。我们可以利用 LlamaIndex 的 LlamaParse 工具,该工具已经集成了 GPT4o,可以将 PDF 文件转换为 Markdown 格式,以便进行 RAG (Retrieval-Augmented Generation,检索增强生成) 检索。
首先,您需要在 LlamaCloud 上注册一个帐户并创建一个 API 密钥,在后续的代码示例中会用到。
接下来,使用 pip 安装 LlamaParse:
pip install llama-parse然后,我们可以使用 LlamaParse 将 PDF 文件转换为 Markdown 格式。以下是代码示例:
from llama_parse import LlamaParse
# 创建一个LlamaParse对象,传入OpenAIAPIKey和注册后获得的LlamaParseAPIKey。
parser_gpt4o = LlamaParse(
result_type="markdown",
api_key="<llama_parse_api_key>",
gpt4o_mode=True,
gpt4o_api_key="<openai_api_key>"
)
pdf_file = "demo.pdf"
pkl_file = "demo.pkl"
if not os.path.exists(pkl_file):
# 将PDF文件转换为Markdown格式内容
documents_gpt4o = parser_gpt4o.load_data(pdf_file)
# 转换后的Markdown内容将保存在demo. pkl文件中
pickle.dump(documents_gpt4o, open(pkl_file, "wb"))
else:
# 将转换后的Markdown内容保存到documents_gpt4o变量中
documents_gpt4o = pickle.load(open(pkl_file, "rb"))一旦程序执行完毕,LlamaParse会将整个PDF文件转换成Markdown格式,我们来看一下转换后的Markdown中的表格内容:
| Model | DocVQA | ChartQA | AI2D | TextVQA | MMMU | MathVista | MM-Bench-CN |
|----------------|--------|---------|-------|---------|-------|-----------|-------------|
| Other Best Open-source LLM | 81.6% (Capypage) | 68.4% (Capypage) | 73.7% (Capypage) | 74.3% (Capypage) | 76.1% (Capypage) | 45.9% (Capypage) | 36.7% (Capypage) | 72.4% (Capypage) |
| Gemini Pro | 88.1% | 74.1% | 73.9% | 74.6% | 47.9% | 45.2% | 74.3% |
| Gemini Ultra | 90.9% | 80.8% | 75.9% | 82.3% | 59.4% | 53.0% | 75.1% |
| GPT-4V | 88.8% | 78.4% | 75.9% | 80.9% | 53.9% | 51.0% | 75.1% |
| Qwen-VL-Plus | 88.2% | 78.1% | 75.9% | 80.9% | 45.2% | 51.0% | 75.1% |
| Qwen-VL-Max | 79.8% | 79.8% | 79.3% | 79.2% | 51.4% | 51.0% | 75.1% |接下来,我们将使用 LlamaIndex 对转换后的 Markdown 内容进行索引和检索。以下是代码示例:
def get_nodes(docs):
"""Split docs into nodes, by separator."""
nodes = []
for doc in docs:
doc_chunks = doc.text.split("\n---\n")
for doc_chunk in doc_chunks:
node = TextNode(
text=doc_chunk,
metadata=deepcopy(doc.metadata),
)
nodes.append(node)
return nodes
nodes = get_nodes(documents_gpt4o)
vector_index = VectorStoreIndex(nodes)
query_engine = vector_index.as_query_engine(similarity_top_k=2)
question = "在比较不同任务中不同AI模型的性能指标。任务“MMMU”中模型“Qwen-VL-Plus”的性能指标是什么?告诉我确切的数字。"
response = query_engine.query(question)
print(f"answer: {str(response)}")在解析 PDF 文件时,LlamaParse 会在 Markdown 内容中添加像 "---" 这样的分页符标签。我们可以利用这些标签将 Markdown 内容分割成多个节点,并将这些节点转换为 TextNode 对象,然后再进行标准的索引和检索流程。
我们将通过验证表格中每个单元格的内容来验证GPT4o解决方案的准确性。代码可以参考前面的示例代码,计算结果如下:
Percentage of True values: 47.61904761904761%经过验证,该解决方案的准确率为 47.62%。与 UnstructuredIO 解决方案相比,这种方法的准确率相对较低。
5.1、优点和缺点
优点
- 可以直接解析 PDF 文件,无需转换为其他格式。
- 可以解析文件中的文本和图像内容。
缺点
- LlamaParse 虽然提供了一定的免费使用额度,但如果使用量较大,则需要付费。
- 使用多模态模型 (Multimodal Models) 解析 PDF 文件的准确率仍有待提升,需要进一步优化。
六、总结
本文介绍了三种从 PDF 文件中解析表格内容的解决方案:Nougat 解决方案、UnstructuredIO 解决方案和 GPT4o 解决方案。每种方案都各有优缺点,目前还没有一种方案能够完美地满足所有需求。基于现有最优的方案建议考虑:
表格解析:我们用了一个叫做Nougat的工具来处理表格(属于类别d)。测试结果表明,Nougat在检测表格方面比处理非结构化数据(类别c)更出色。而且,Nougat还能够很好地提取表格的标题,这让我们能够方便地将表格和它们的标题联系起来。
文档摘要索引结构:我们把小文本块的内容设置为表格摘要,而大文本块的内容则是表格的LaTeX格式和表格标题的文本格式。我们用了一个多向量检索器来实现这种索引结构。
表格摘要生成:我们把表格和它的标题发送给一个大型语言模型(LLM),让它为我们生成摘要。
这种方法的好处在于,它不仅能高效地解析表格,还能全面考虑表格摘要和表格之间的联系。另外,它不需要使用多模态的大型语言模型,从而节省了成本。
参考资料
[1] LlamaIndex:https://www.llamaindex.ai/
[2] Nougat:https://facebookresearch.github.io/nougat/
[3] Mathpix Markdown:https://github.com/Mathpix/mathpix-markdown-it
[4] Attention is All You Need:https://arxiv.org/pdf/1706.03762.pdf
[5] UnstructuredIO:https://github.com/Unstructured-IO/unstructured
[6] Webviewer:https://apryse.com/
[7] Mac OS Structured Output:https://docs.apryse.com/downloads/StructuredOutputMac.zip
[8] Convert PDF to HTML:https://docs.apryse.com/documentation/mac/guides/features/conversion/convert-pdf-to-html/