Elastichsearch是一种高度可扩展的开源全文搜索和分析引擎,可以用来实现快速、高效的数据检索。
-
集群规划与部署:首先需要根据业务需求规划Elastichsearch集群的节点数量和角色(如主节点、副本节点、协调节点等)。在部署时,应考虑集群的高可用性和可扩展性,确保节点之间的网络通信畅通无阻。
-
数据分片与复制:Elastichsearch通过数据分片实现水平扩展,通过复制实现数据的可靠性和高可用性。运维人员需要合理设置分片数和副本的数量,以优化查询性能和数据恢复的可靠性。
-
资源监控:监控集群的资源使用情况,如CPU、内存、磁盘I/O等,以确保集群资源不会被过度占用,避免出现性能瓶颈。
-
索引管理:定期对索引进行优化和管理,包括合并索引分片、删除不再使用的索引等,以保持集群的高效运行。
-
配置管理:合理配置Elastichsearch的各项参数,以适应不同的业务需求和优化性能。同时,应定期检查配置文件,确保配置的安全性和正确性。
-
备份与恢复:定期对Elastichsearch集群进行备份,以防止数据丢失。同时,掌握数据恢复的方法,以便在数据损坏或丢失时能够迅速恢复。
-
安全维护:加强对Elastichsearch集群的安全管理,包括使用HTTPS、用户认证、权限控制等,防止数据泄露和未授权访问。
-
日志管理:收集和分析Elastichsearch的日志信息,以便及时发现和解决问题。
-
性能调优:根据业务需求和集群运行情况,不断调整和优化Elastichsearch的配置和集群架构,以提高查询效率和系统性能。
-
集群升级和迁移:当Elastichsearch版本更新或硬件升级时,需要进行集群的升级和迁移操作,确保业务的中断时间最短。
针对索引:
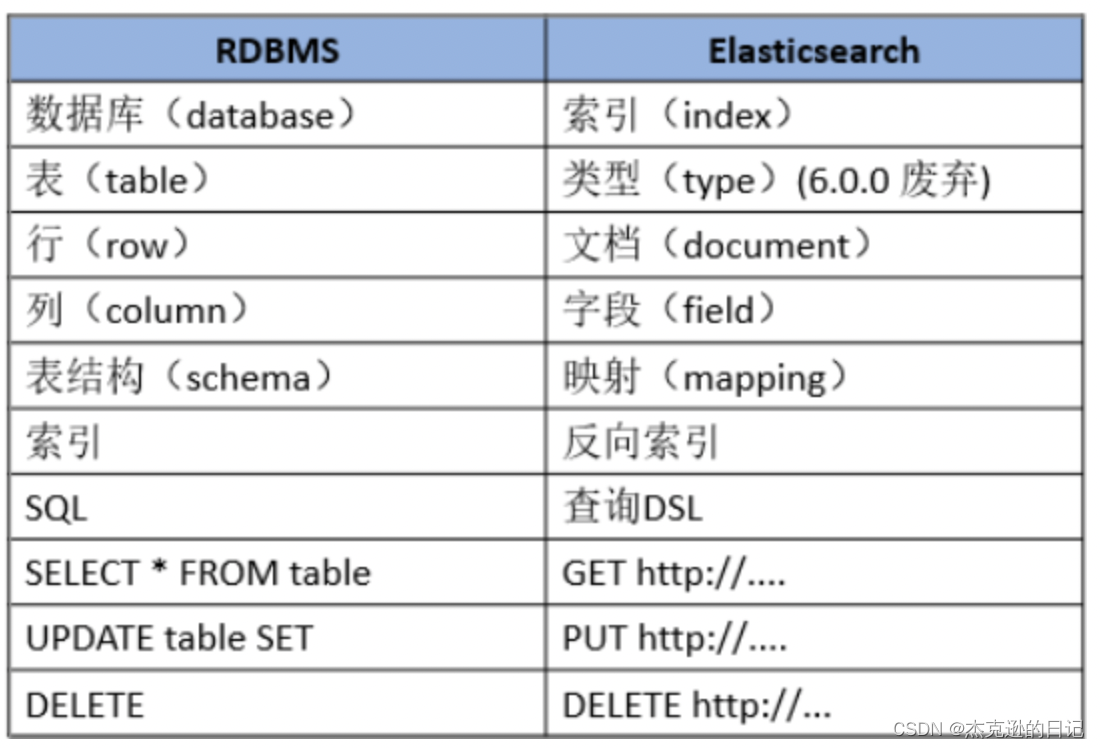
Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。索引作动词时,指索引数据、或对数据进行索引。Type 类型:指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
Document 文档:
被索引的一条数据,索引的基本信息单元,以JSON格式来表示。一个文档是一个可被索引的基础信息单元。
Shard 分片:
在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上(分片数创建索引时指定,创建后不可改了。备份数可以随时改)。索引分片,ElasticSearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。分片的好处
(1)允许我们水平切分/扩展容量
(2)可在多个分片上进行分布式的、并行的操作,提高系统的性能和吞吐量。
Replication 备份: 一个分片可以有多个备份(副本)。备份的好处:
- 高可用扩展搜索的并发能力、吞吐量。
- 搜索可以在所有的副本上并行运行。
primary shard:
主分片,每个文档都存储在一个分片中,当你存储一个文档的时候,系统会首先存储在主分片中,然后会复制到不同的副本中。默认情况下,一个索引有5个主分片。你可以在事先制定分片的数量,当分片一旦建立,分片的数量则不能修改。
replica shard:
副本分片,每一个分片有零个或多个副本。副本主要是主分片的复制,其中有两个目的:
- 增加高可用性:当主分片失败的时候,可以从副本分片中选择一个作为主分片。
- 提高性能:当查询的时候可以到主分片或者副本分片中进行查询。默认情况下,一个主分配有一个副本,但副本的数量可以在后面动态的配置增加。副本必须部署在不同的节点上,不能部署在和主分片相同的节点上。
erm索引词:在elasticsearch中索引词(term)是一个能够被索引的精确值。foo,Foo几个单词是不相同的索引词。索引词(term)是可以通过term查询进行准确搜索。
text文本:是一段普通的非结构化文字,通常,文本会被分析称一个个的索引词,存储在elasticsearch的索引库中,为了让文本能够进行搜索,文本字段需要事先进行分析;当对文本中的关键词进行查询的时候,搜索引擎应该根据搜索条件搜索出原文本。
analysis:分析是将文本转换为索引词的过程,分析的结果依赖于分词器,比如: FOO BAR, Foo-Bar, foo bar这几个单词有可能会被分析成相同的索引词foo和bar,这些索引词存储在elasticsearch的索引库中。当用 FoO:bAR进行全文搜索的时候,搜索引擎根据匹配计算也能在索引库中搜索出之前的内容。这就是elasticsearch的搜索分析。
routing路由:当存储一个文档的时候,他会存储在一个唯一的主分片中,具体哪个分片是通过散列值的进行选择。默认情况下,这个值是由文档的id生成。如果文档有一个指定的父文档,从父文档ID中生成,该值可以在存储文档的时候进行修改。
type类型:在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组相同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台 并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
template:索引可使用预定义的模板进行创建,这个模板称作Index templatElasticSearch。模板设置包括settings和mappings。
mapping:映射像关系数据库中的表结构,每一个索引都有一个映射,它定义了索引中的每一个字段类型,以及一个索引范围内的设置。一个映射可以事先被定义,或者在第一次存储文档的时候自动识别。
field:一个文档中包含零个或者多个字段,字段可以是一个简单的值(例如字符串、整数、日期),也可以是一个数组或对象的嵌套结构。字段类似于关系数据库中的表中的列。每个字段都对应一个字段类型,例如整数、字符串、对象等。字段还可以指定如何分析该字段的值。
source field:默认情况下,你的原文档将被存储在_source这个字段中,当你查询的时候也是返回这个字段。这允许您可以从搜索结果中访问原始的对象,这个对象返回一个精确的json字符串,这个对象不显示索引分析后的其他任何数据。
id:一个文件的唯一标识,如果在存库的时候没有提供id,系统会自动生成一个id,文档的index/type/id必须是唯一的。
recovery:代表数据恢复或叫数据重新分布,ElasticSearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
River:代表ElasticSearch的一个数据源,也是其它存储方式(如:数据库)同步数据到ElasticSearch的一个方法。它是以插件方式存在的一个ElasticSearch服务,通过读取river中的数据并把它索引到ElasticSearch中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
gateway:代表ElasticSearch索引的持久化存储方式,ElasticSearch默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个ElasticSearch集群关闭再重新启动时就会从gateway中读取索引数据。ElasticSearch支持多种类型的gateway,有本地文件系统(默认), 分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表ElasticSearch的自动发现节点机制,ElasticSearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表ElasticSearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
对比RDBMS (关系型数据库管理系统)