包括,Python连接数据库到模拟电商数据库,到sql场景查询
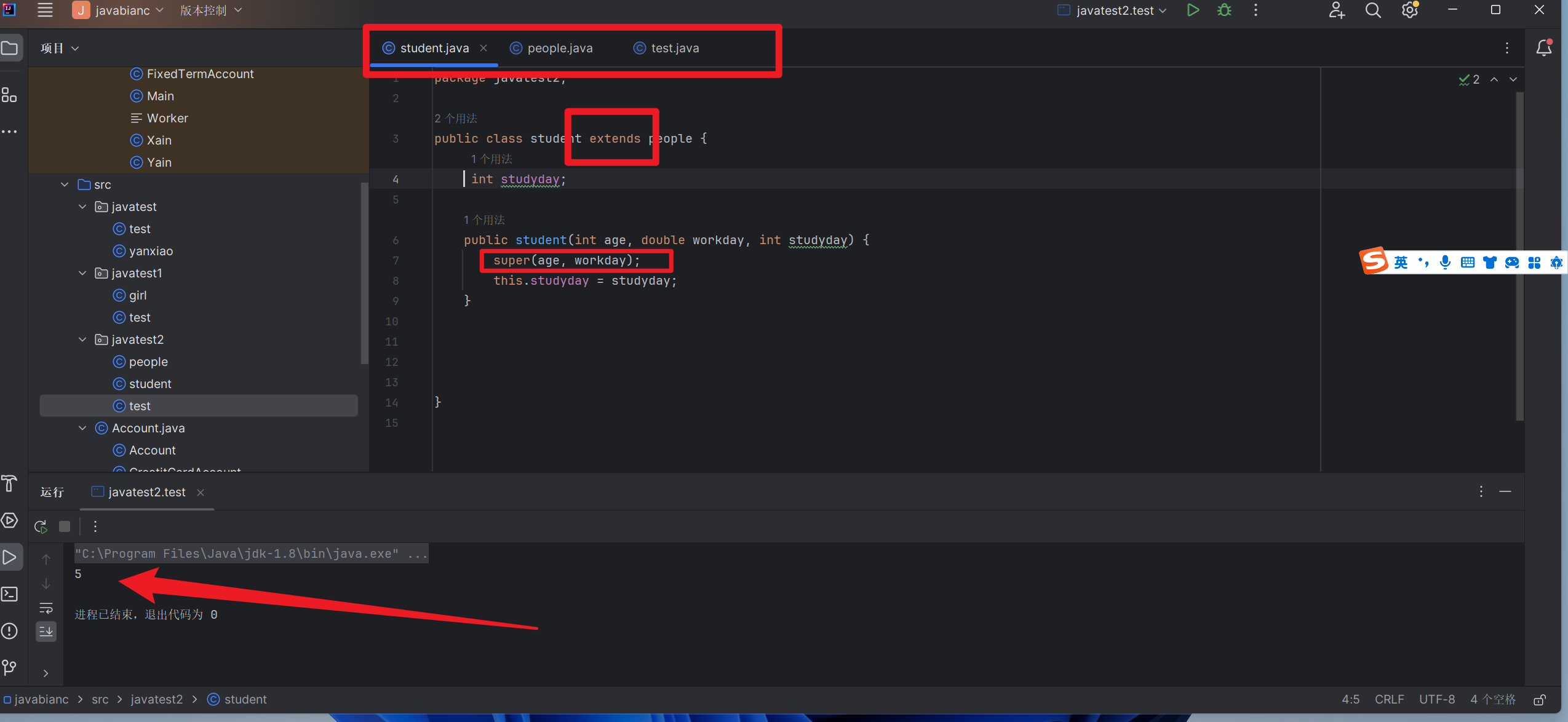
1,Python连接SQL数据库
以下是使用Python连接MySQL数据库并进行操作的示例代码:
import random
import time
import pymysql
# 定义名字数据
xing = ["王", "李", "张", "刘", "陈", "杨", "黄", "赵", "吴", "周"]
ming = ["伟", "芳", "娜", "敏", "静", "丽", "强", "磊", "军", "洋"]
# 连接数据库
conn = pymysql.connect(
host="192.168.1.80",
user="admin",
password="123",
database="management_systems",
charset="utf8"
)
cursor = conn.cursor()
# 生成随机生日
a1 = (1980, 1, 1, 0, 0, 0, 0, 0, 0)
a2 = (2000, 12, 31, 23, 59, 59, 0, 0, 0)
start = time.mktime(a1)
end = time.mktime(a2)
# 插入学生数据
for i in range(1, 37):
for j in range(1, 51):
random_xing = random.randint(0, len(xing) - 1)
random_ming = random.randint(0, len(ming) - 1)
t = random.randint(start, end)
date_t = time.localtime(t)
birthday = time.strftime("%Y-%m-%d", date_t)
sql = f"INSERT INTO student(class_id, student_name, student_birthday, sex) VALUES ({i}, '{xing[random_xing]}{ming[random_ming]}', '{birthday}', {random.randint(0, 1)})"
cursor.execute(sql)
conn.commit()
# 查询数据
sql = """
SELECT
s.class_id,
c.class_name,
s.student_name,
s.student_birthday,
s.sex
FROM
student s
JOIN
class c
ON
s.class_id = c.class_id
WHERE
s.student_birthday > '1990-01-01'
ORDER BY
s.class_id, s.student_birthday;
"""
cursor.execute(sql)
result = cursor.fetchall()
for row in result:
print(row)
# 关闭连接
cursor.close()
conn.close()
2,模拟数据库
假设我们有一个偏真实的电商数据库,其中包括以下几张主要数据表:
- users:用户信息表
- products:产品信息表
- orders:订单表
- order_items:订单详情表
- reviews:产品评论表
以下是这些表的结构和部分复杂的SQL操作示例:
数据表结构
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE products (
product_id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(100) NOT NULL,
category VARCHAR(50),
price DECIMAL(10, 2),
stock INT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT,
order_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
total_amount DECIMAL(10, 2),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE order_items (
order_item_id INT AUTO_INCREMENT PRIMARY KEY,
order_id INT,
product_id INT,
quantity INT,
price DECIMAL(10, 2),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
CREATE TABLE reviews (
review_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT,
user_id INT,
rating INT CHECK (rating BETWEEN 1 AND 5),
comment TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (product_id) REFERENCES products(product_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
插入数据
import pymysql
import random
import time
# 连接数据库
conn = pymysql.connect(
host="192.168.1.80",
user="admin",
password="123",
database="ecommerce",
charset="utf8"
)
cursor = conn.cursor()
# 插入用户数据
users = [("user1", "user1@example.com"), ("user2", "user2@example.com")]
for user in users:
sql = f"INSERT INTO users(username, email) VALUES ('{user[0]}', '{user[1]}')"
cursor.execute(sql)
# 插入产品数据
products = [("Product1", "Category1", 100.00, 10), ("Product2", "Category2", 200.00, 20)]
for product in products:
sql = f"INSERT INTO products(product_name, category, price, stock) VALUES ('{product[0]}', '{product[1]}', {product[2]}, {product[3]})"
cursor.execute(sql)
conn.commit()
# 插入订单和订单详情数据
order_data = [(1, '2024-01-01', 300.00), (2, '2024-01-02', 400.00)]
order_items_data = [(1, 1, 2, 100.00), (1, 2, 1, 200.00), (2, 1, 3, 300.00)]
for order in order_data:
sql = f"INSERT INTO orders(user_id, order_date, total_amount) VALUES ({order[0]}, '{order[1]}', {order[2]})"
cursor.execute(sql)
for item in order_items_data:
sql = f"INSERT INTO order_items(order_id, product_id, quantity, price) VALUES ({item[0]}, {item[1]}, {item[2]}, {item[3]})"
cursor.execute(sql)
conn.commit()
# 插入评论数据
reviews = [(1, 1, 5, "Excellent product!"), (2, 2, 4, "Very good.")]
for review in reviews:
sql = f"INSERT INTO reviews(product_id, user_id, rating, comment) VALUES ({review[0]}, {review[1]}, {review[2]}, '{review[3]}')"
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
3,复杂查询示例
-- 查询每个用户的订单总金额及订单数量
SELECT
u.user_id,
u.username,
COUNT(o.order_id) AS order_count,
SUM(o.total_amount) AS total_spent
FROM
users u
LEFT JOIN
orders o
ON
u.user_id = o.user_id
GROUP BY
u.user_id, u.username;
-- 查询每个产品的平均评分及评论数量
SELECT
p.product_id,
p.product_name,
AVG(r.rating) AS average_rating,
COUNT(r.review_id) AS review_count
FROM
products p
LEFT JOIN
reviews r
ON
p.product_id = r.product_id
GROUP BY
p.product_id, p.product_name;
-- 查询订单详情,包含订单信息、用户信息及产品信息
SELECT
o.order_id,
u.username,
o.order_date,
p.product_name,
oi.quantity,
oi.price
FROM
orders o
JOIN
users u
ON
o.user_id = u.user_id
JOIN
order_items oi
ON
o.order_id = oi.order_id
JOIN
products p
ON
oi.product_id = p.product_id;
-- 查询每个用户在每个类别上的花费总金额
SELECT
u.user_id,
u.username,
p.category,
SUM(oi.price * oi.quantity) AS total_spent
FROM
users u
JOIN
orders o
ON
u.user_id = o.user_id
JOIN
order_items oi
ON
o.order_id = oi.order_id
JOIN
products p
ON
oi.product_id = p.product_id
GROUP BY
u.user_id, u.username, p.category;
-- 查询在2024年每个月的销售总额和销售量
SELECT
YEAR(o.order_date) AS year,
MONTH(o.order_date) AS month,
SUM(oi.price * oi.quantity) AS total_sales,
SUM(oi.quantity) AS total_quantity
FROM
orders o
JOIN
order_items oi
ON
o.order_id = oi.order_id
WHERE
YEAR(o.order_date) = 2024
GROUP BY
YEAR(o.order_date), MONTH(o.order_date);
通过这些示例,您可以看到如何使用Python连接数据库,生成和插入随机数据,以及进行复杂的SQL查询。
(交个朋友/技术接单/ai办公/性价比资源,注明来意)