如何建设高效的数据模型体系,使数据易用,避免重复建设和数据不一致性,保证数据的规范性;如何提供高效易用的数据开发工具;如何做好数据质量保障;如何有效管理和控制日益增长的存储和计算消耗;如何保证数据服务的稳定,保证其性能;如何设计有效的数据产品高效赋能于外部客户和内部员工;这些都对大数据提出了更多复杂要求。
大数据的服务的服务体系主要分为数据采集,数据计算,数据服务和数据应用四大层次。
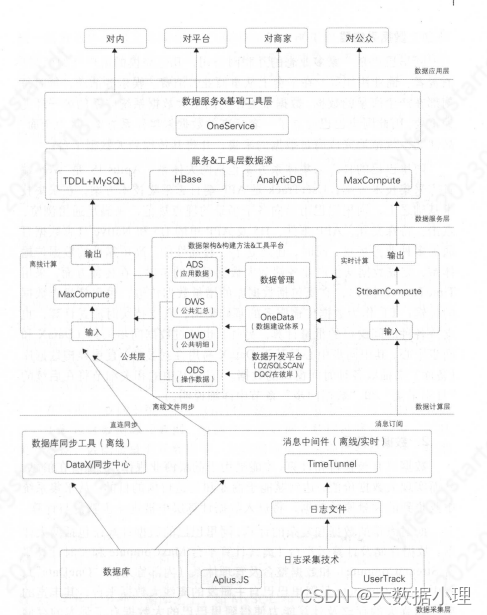
一个大数据交付项目的链路:
售前捕获商机,签订合同
业务分析师进行需求分析,业务分析
架构师进行架构,建模
高级数据标签开发,算法及pyspark
数据开发进行盘点,指标开发
业务分析或数开进行数据可视化
售后提供支持
运维及治理
数据采集
数据采集有埋点(其中埋点可分为埋点采集和无埋点采集),无埋点,爬虫(python,java)获得或者从业务库拉取。
pv:页面浏览量; uv:独立访客数
spu: 一类型商品 sku:最细商品
埋点的话就是借助埋点采集数据,在需要检测用户行为的地方加上一段代码,我们可以称之为capture模式,通过在客户端/服务端埋下确定的点采集数据上云,这种方式准确性与稳定性高,适合监控和分析,一般埋点往往有很多业务属性,方便对事件上进行业务属性拆解和下钻分析,可以较好从业务逻辑切入行为分析,帮助理解业务思路。
缺点:埋点缺点是跨部门的协作沟通;埋点不能回溯历史数据;埋点数量有限,许多用户行为数据可能缺失影响数据分析效率。
埋点适用场景:核心数据;需要长期监控和存储;业务属性丰富;数据稳定准确
一个完整的埋点方案需要具备四个要素:确定事件与变量;明确事件触发时机,规范命名,明确优先级。
无埋点不是不需要打代码,而是前端自动采集全部事件并上报所有的数据,无埋点使用record模式,只需要首次使用时加载一段SDK代码,即可全量实时的采集数据。埋点使用capture模式。
缺点:无埋点的缺点是部分业务维度无法采集;无法实现滑动;数据准确性受到开发框架,开发规范等影响。
无埋点适用场景:业务属性弱,交互属性强;数据使用周期短不需要长期监控;突发问题快速及时分析
数据计算
数据计算有阿里的dataworks,dataphin,华为云,腾讯云及自研计算平台进行数据计算。在其中进行计算(hive,spark,shell,pyspark)和数据整合管理(onedata)
加工链路(数据矩阵)
ods->stg->std->dim->dwd->dws->ads->mysql
然后进行可视化(帆软,tableau,datav,quickbi,python或自研可视化工具),用户画像,推荐系统,人群圈选,机器学习
数据服务
数据终点站mysql或宽表(Hbase,mogodb),也可将其放入云数据库(RDS)探后通过接口对外提供查询服务。
数据应用
搜索,推荐,广告,政企,金融,文娱,电商,保险,地产及工业信息化等等
数据同步
数据同步是采集后的数据进行上云,也叫数据集成,数据源来自不同系统库,可能有mysql,oracle,db2.sftp,ftp.等
ODBC/JDBC 等规定了统一规范的标准接口,不同的数据库基于这套标准接口提供规范的驱动,支持完全相同的函数调用和 SQL 实现或者封装实现。
同步包括全量同步(数据量较少),增量同步(数据量大),新增及变化同步(原来同步数据会发生变化)
数据建模
传统关系型数据库是ER模型,关系模型即范式
大数据要求维度建模,防止冗余
传统OLTP,大数据OLAP
面对爆炸式增长的数据,如何建设高效的数据模型和体系,避免重复建设和数据不一致性,保证数据的规范性, 一直是大数据系统建设不断追求的方向。OneData 即进行数据整合及管理的方法体系和工具。在这一体系下,构建统一 、规范、可共享的全域数据体系,避免数据的冗余和重复建设,规避数据烟囱和不一致性,充分发挥在大数据海量、多样性方面的独特优势。借助统一化数据整合及管理的方法体系,构建数据公共层,可以帮助相似的大数据项目快速落地实现。
数据仓库定义:数据仓库是一个面向主题的,集成的,非易失的且随时间变化的集合。
数据仓库是一个中央存储库,里面集中存储了某一个专一主题或功能区域的数据。
数据仓库不是数据的终点而是做准备,包括清洗,转义,重组,合并,拆分,统计
数据仓库-》数据中台-》数据湖(湖仓一体)