目录
- 1.AlexNet
- 2.VGG
- 3.GoogleNet
- 4.ResNet
- 5.MobileNet
1.AlexNet
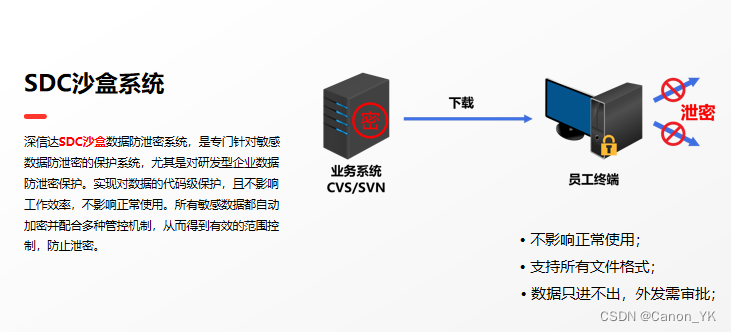
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络。
- 首次利用 GPU 进行网络加速训练。
- 使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
- 使用了 LRN 局部响应归一化。
- 在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合
2.VGG
VGG在2014年由牛津大学著名研究组VGG (Visual Geometry Group) 提出,斩获该年ImageNet竞 中 Localization Task (定位 任务) 第一名 和 Classification Task (分类任务) 第二名。
- 通过连续小的卷积核堆叠形成大的卷积核的效果
通过堆叠两个3x3的卷积核替代5x5的卷积核,堆叠三个3x3的卷积核替代7x7的卷积核。感受野不变,参数减小。
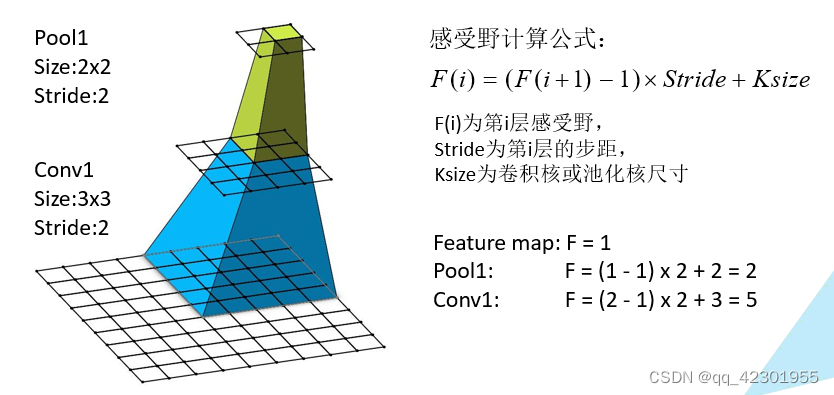
3.GoogleNet
GoogLeNet在2014年由Google团队提出,斩获当年ImageNet竞 中Classification Task (分类任务) 第一名。
- 开始使用1X1卷积核:可以升维降维,减小输入图片面积,增加图片深度
- 使用卷积核可以代替全连接的好处:输入层图片尺寸可变,这样用合适的卷积核就可以替代全连接
- GoogleNet引入了Inception模块,该模块将不同尺寸的卷积核(1x1、3x3、5x5)和最大池化操作组合在一起,以并行的方式提取不同尺度的特征
- 辅助分类器:在网络中添加了辅助分类器,这有助于梯度的传播,避免梯度消失问题,并提供额外的训练信号以增强模型的稳定性和性能
4.ResNet
ResNet在2015年由微软实验室提出,斩获当年ImageNet竞 中 分类任务第一名,目标检测第一名。获得COCO数据集中目标 检测第一名,图像分割第一名。
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch Normalization加速训练(丢弃dropout)
残差网络(ResNet)之所以不会对信息造成损失,主要是因为它引入了残差学习的概念和残差连接(Shortcut Connection)的设计。以下是几个关键点,解释了为什么ResNet不会对信息造成损失:
残差连接:ResNet中的残差连接允许网络中的信息直接从较早的层传递到后面的层。这种设计确保了即使在深层网络中,信息也能有效地流动,不会在传播过程中丢失。
恒等映射:在残差模块中,如果增加的层仅仅是恒等映射(即输入直接传递到输出),那么网络的性能至少和浅层网络一样好。这意味着即使增加额外的层,也不会损害网络的性能。
梯度流动:残差连接使得梯度可以直接从输出层流向输入层,避免了深层网络中常见的梯度消失问题。这有助于网络在训练过程中有效地学习,并保持信息的完整性。
特征重用:通过残差连接,前面的层可以重用已经学习到的特征,而不需要重新学习。这有助于网络在深层结构中保持特征的丰富性和多样性。
网络退化问题解决:在传统的深度网络中,随着网络深度的增加,性能往往会饱和甚至下降,这被称为网络退化问题。ResNet通过残差学习解决了这个问题,使得网络可以有效地增加深度而不损失性能。
信息融合:ResNet允许不同层的特征图在残差连接处进行融合,这有助于整合不同层次的信息,提高网络的表示能力。
灵活性:ResNet的设计允许网络根据需要学习残差函数,这意味着网络可以灵活地调整其行为,以适应不同的数据和任务。
实验验证:ResNet在多个数据集和任务上的表现证明了其有效性。实验结果表明,ResNet可以训练更深的网络,同时保持或提高性能,这表明信息在网络中的传递是有效的。
总之,ResNet的设计哲学和残差连接机制确保了信息可以在深层网络中有效地流动和利用,从而避免了信息损失,使得网络能够从增加的深度中受益。
ResNeXt:在ResNet基础上对通道分组训练,既可以减少参数量,又可以提高准确率。
注意:分组训练仅对residual结构深度大于等于3有优化效果。
5.MobileNet
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入 式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降 低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%, 但模型参数只有VGG的1/32)
- Depthwise Convolution(大大减少运算量和参数数量)
- 增加超参数α、β控制通道数和图片尺寸
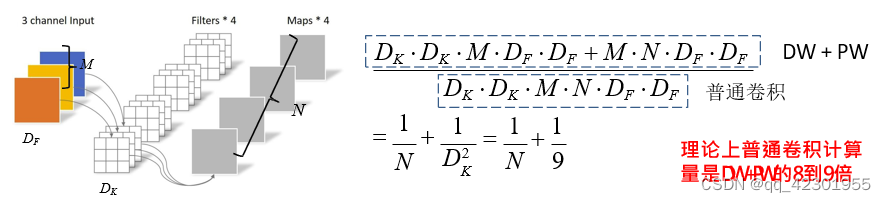
MobileNet v2网络是由google团队在2018年提出的,相比MobileNet V1网 络,准确率更高,模型更小。特点如下:
- mobileNetV2: Inverted Residual(倒残差结构)
- Liner Bottlenecks (部分网络去掉了激活函数)
在 MobileNetV2 架构中,“Linear bottlenecks” 是指网络中的一系列层,它们由深度可分离卷积(depthwise separable convolution)组成,用于在特征提取的同时减少计算量。这种结构通常包括以下几个步骤:
深度卷积(Depthwise Convolution):对输入通道进行卷积,每个输入通道通过各自独立的滤波器进行卷积运算。
逐点卷积(Pointwise Convolution):在深度卷积的输出上应用1x1的卷积,以组合通道并减少通道数量,达到降维的目的。
在 MobileNetV2 中,“Linear bottlenecks” 结构通常不使用激活函数,特别是在逐点卷积之后。这是因为:
降维目的:逐点卷积的主要目的是减少通道数,而不是引入非线性,因此在降维步骤之后通常不使用激活函数。
计算效率:避免在每个卷积层之后都使用激活函数可以减少计算量,这对于移动和嵌入式设备上的设计尤为重要。
MobileNetV2 在网络的某些部分使用了 ReLU6 激活函数,原因包括:
输出限制:ReLU6 激活函数将输出限制在 0 到 6 之间,这有助于防止梯度消失问题,并为后续层提供更稳定的输入。
网络设计:MobileNetV2 的设计者可能发现在特定位置使用 ReLU6 激活函数能够提高模型性能或稳定性。
特定层的需求:在网络的某些层,如特征混合层(feature mixing layers)或最终的分类层,使用激活函数可能有助于改善模型的表示能力。
实验结果:ReLU6 激活函数的选择可能是基于实验结果,设计者可能发现它在 MobileNetV2 的特定架构中能够提供更好的性能。ReLU激活函数对低位特征信息造成大量丢失。
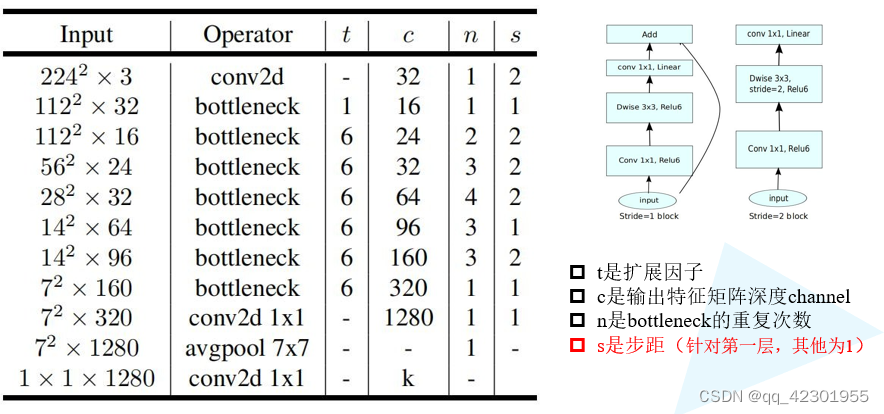
MobileNetV2的网络结构:
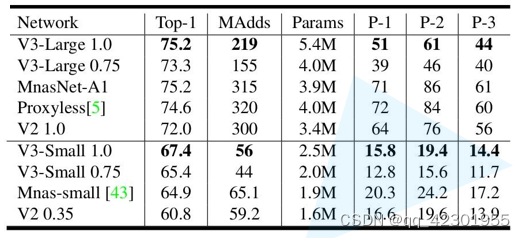
MobileNetV2在分类和图像识别领域的效果:
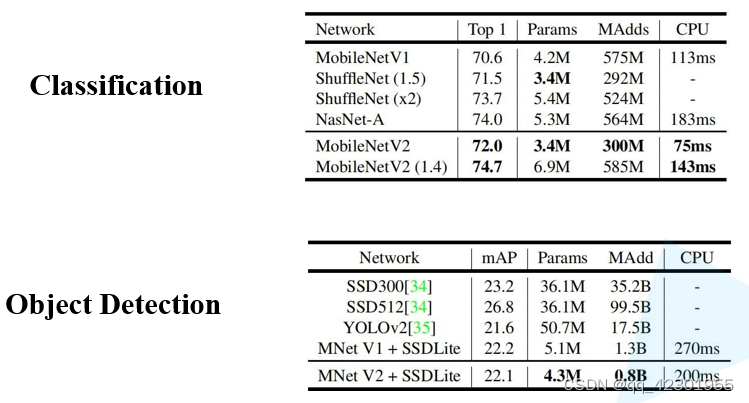
(Top-1表示模型预测的前1个最高概率的准确率,Params表示参数,MAdds表示运算量,CPU表示一张图片的训练时间,P-1表示在Google手机设别Phone-1上的运行时间)
MobileNetV3比V2更准确高效,特点如下:
- 优化了bottleneck
- 使用NAS搜索参数
- 重新设计耗时层结构
V3效果如下: