XPath
什么是XPath
XPath(XML Path Language)是一种用于在XML文档中定位和选择节点的语言。它是W3C(World Wide Web Consortium)定义的一种标准查询语言,广泛用于解析和操作XML文档。
安装配置
安装lxml:
pip install lxml
使用lxml:
from lxml import etree
XPath常用规则
XPath使用路径表达式来描述节点的位置和关系。以下是XPath的一些常用规则:
| 语法 | 说明 |
|---|---|
| nodeName | 选取此节点的所有子节点 |
| / | 从当前节点选择直接子节点 |
| // | 从当前节点选择子孙节点 |
| . | 当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 获取属性 |
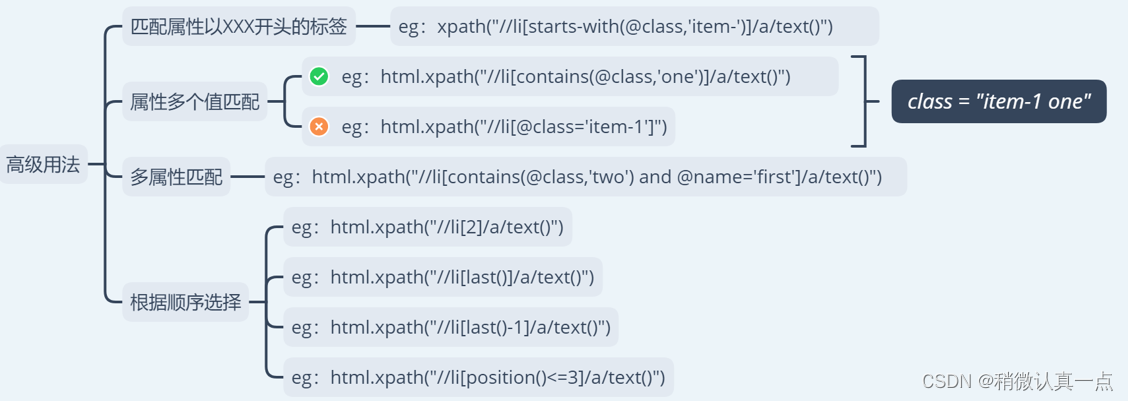
高级用法说明:
-
选择特定节点类型:
-
node():匹配任何节点。 -
text():匹配文本节点。 -
element:匹配元素节点。 -
@attribute:匹配属性节点。
-
-
属性选择:
-
[@属性名]:匹配具有特定属性的节点。 -
[@属性名=值]:匹配属性值等于给定值的节点。
-
-
位置选择:
-
[位置]:选择在指定位置的节点。 -
[last()]:选择最后一个节点。 -
[position()<n]:选择前 n 个位置的节点。
-
案例说明:
快速入门
在当前项目下创建一个index.html,如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <div class="aa">hello world</div> <div class="bb">hello python</div> </body> </html>
完整代码示例如下:
p = pathlib.Path("index.html")
# 网页初始化
html = etree.HTML(p.read_text(encoding="utf-8")) # type: lxml.etree._Element
# 打印类型
# print(type(html))
# 获取指定节点
# print(html.xpath("body"))
# 获取当前节点
# print(html.xpath("."))
# 获取当前节点下的直接子节点
# print(html.xpath("./body"))
# 获取当前节点下的子孙节点
# print(html.xpath("//div"))
# 获取当前节点的父节点
# div = html.xpath("./body/div")[0] #type: lxml.etree._Element
# print(div.xpath(".."))
# 根据属性获取
# print(html.xpath("//div[@class='aa']"))
# 获取属性的值
# print(html.xpath("//div/@class"))
# 注意:元素顺序下标从1开始
# print(html.xpath("//div[1]/@class"))
# 获取文本信息
# print(html.xpath("//div[1]/text()"))
# print(html.xpath("//div[1]")[0].text)
浏览器XPath工具
打开Chrome浏览器,按F12打开开发者工具,找到console输入XPath语法指令查找网页内容。
参考地址:乐百川 - 简书
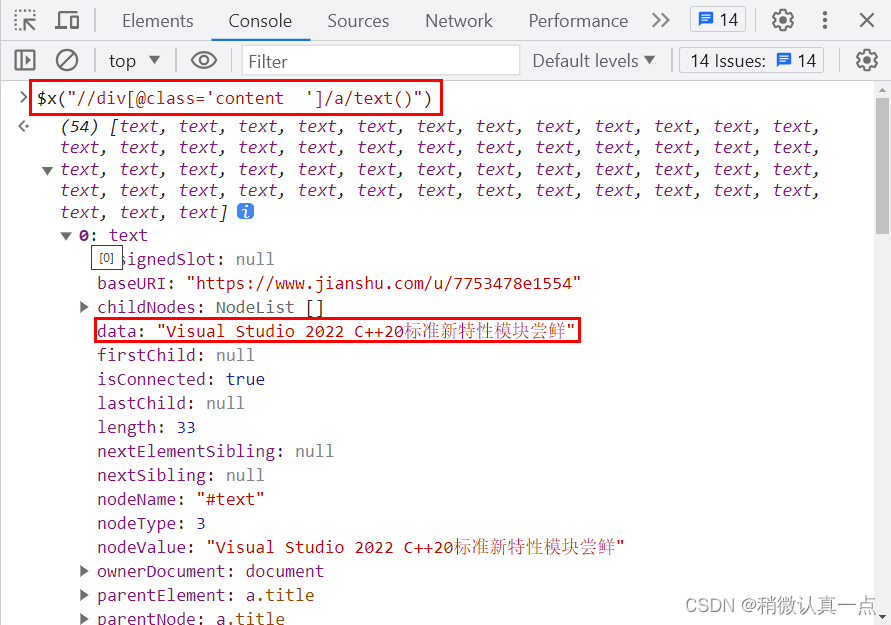
示例要求:通过浏览器的XPath工具搜索上述网页中的文章标题信息。
-
方式一:直接通过@class获取
$x("//div[@class='content ']/a/text()")
-
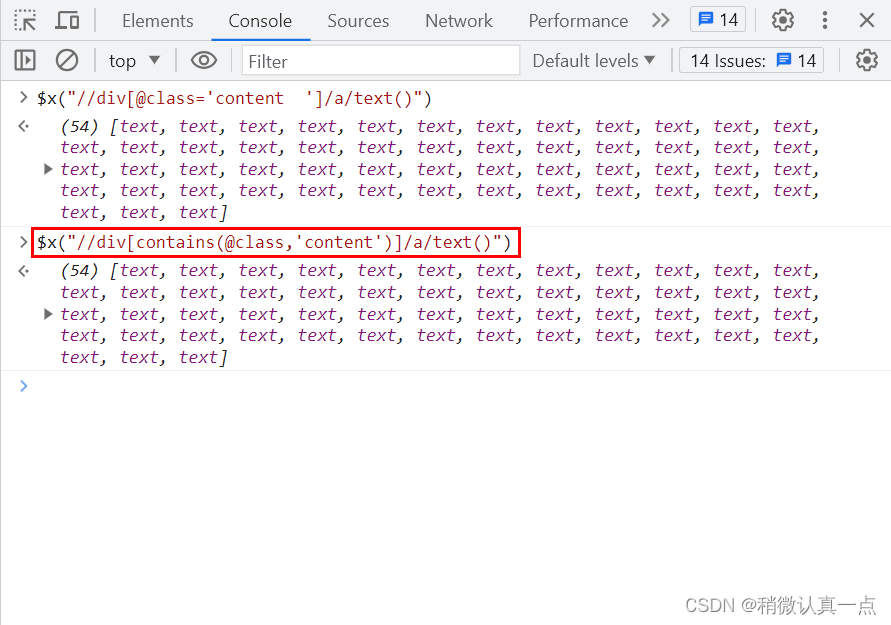
方式二:通过contains函数方式匹配@class属性的值
$x("//div[contains(@class,'content')]/a/text()")
requests_html
什么是requests_html
requests_html是一个Python库,用于从Web页面中提取数据。它提供了对HTML内容的解析和处理功能,使您可以轻松地从网页中提取文本、链接、图像和其他元素。
requests_html库建立在另一个流行的Python库requests之上,并使用了lxml来解析HTML。它提供了一种简单而灵活的方法来发送HTTP请求并解析响应中的HTML内容。
使用requests_html,可以发送GET或POST请求,从HTML响应中提取元素,执行JavaScript渲染,处理表单提交,模拟用户与网页的交互等等。它还支持基于CSS选择器和XPath表达式的元素选择,方便地定位和提取特定的网页元素。
安装与配置
pip install requests-html
快速入门
使用requests_html模块获取页面中的所有绝对链接的示例代码:
# 创建一个会话
session = requests_html.HTMLSession()
# 起送GET请求并获取页面内容
resp = session.get("https://www.igdcc.com/shouji/katong/") # type: requests_html.HTMLResponse
# 渲染JavaScript
resp.html.render()
# 获取页面中所有的绝对链接
lst = list(resp.html.absolute_links)
print(lst)
因为是第一次使用render函数,需要安装chromium,这里需要花费一定的时间,请耐心等待。

在上述示例中,response.html.absolute_links会返回一个包含页面中所有绝对链接的集合(Set)。可以使用for循环遍历并打印其中的链接。
图片下载
urllib.request.urlretrieve函数是Python标准库中urllib.request模块提供的一个方法,用于从指定的URL下载文件并保存到本地。
下面是urllib.request.urlretrieve()函数的完整参数说明:
-
url:必需,要下载的文件的URL地址。 -
filename:必需,保存文件的本地路径和文件名。如果未指定此参数,则会将文件保存到临时目录中,返回保存的临时文件名。 -
reporthook:可选,一个回调函数,用于显示下载进度。可以是一个自定义的回调函数,格式为reporthook(count, blockSize, totalSize),其中count表示已经下载的数据块数量,blockSize表示每个数据块的大小,totalSize表示要下载的文件的总大小。默认情况下,不会显示下载进度。 -
data:可选,要发送的额外数据。可以是一个字节流(str或bytes类型)或者一个文件对象。如果指定了此参数,urlretrieve()函数会使用POST请求发送数据。 -
headers:可选,一个字典类型,表示发送请求时的头部信息。 -
origin_req_host:可选,字符串类型,表示原始请求的主机名。用于在重定向时设置 Referer 头部。默认情况下,origin_req_host为None。 -
unverifiable:可选,布尔值,表示请求是否可验证。如果设置为True,则会跳过某些HTTPS验证步骤。默认值为False。
注意:
urllib.request.urlretrieve()函数的执行会阻塞当前线程,直到下载完成。
入门案例:
参考地址:卡通4K手机壁纸_高清卡通手机桌面图片_极品桌面
可先通过浏览器的XPath工具方式定位元素具体地址,如下:
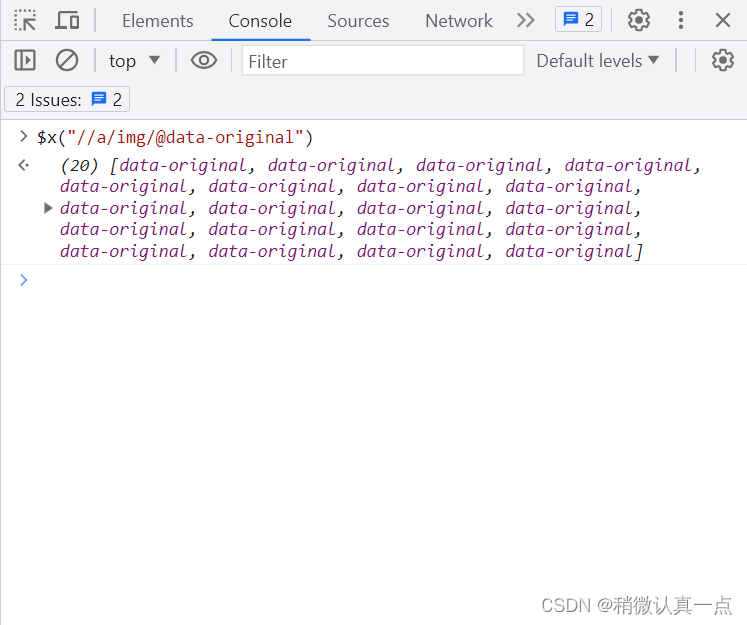
基本代码:
# 通过xpath获取页面中满足条件的图片
urls = resp.html.xpath("""//a/img/@data-original""")
for url in urls:
print(f"正在下载【"+url+"】,请稍等...")
urllib.request.urlretrieve(url,f"images/{uuid.uuid4()}.jpg")
调用urllib.request.urlretrieve()函数时,可以通过提供一个回调函数来显示下载进度。如下所示:
def show(count, blockSize, totalSize):
"""
回调函数用于显示下载进度
:param count: 已经下载的数据块数量
:param blockSize: 每个数据块的大小
:param totalSize: 要下载的文件的总大小
:return:
"""
percent = round((count * blockSize / totalSize),1) * 100
print(f"正在下载: {percent}%")
time.sleep(0.1)
# 通过xpath获取页面中满足条件的图片
urls = resp.html.xpath("""//a/img/@data-original""")
for url in urls:
print(f"正在下载【"+url+"】,请稍等...")
urllib.request.urlretrieve(url,f"images/{uuid.uuid4()}.jpg",show)