文章目录
- Incomplete Multimodal Learning for Visual Acuity Prediction After Cataract Surgery Using Masked Self-Attention
- 摘要
- 方法
- 实验结果
Incomplete Multimodal Learning for Visual Acuity Prediction After Cataract Surgery Using Masked Self-Attention
摘要
论文提出了一种新颖的框架,利用掩码自注意力机制来预测白内障手术后的视力情况。
该方法使用术前图像和患者人口统计数据作为输入,利用多模态信息,这与现有仅依赖单一模态数据的方法不同。
该方法还针对不完整的多模态数据问题,采用注意力掩码机制来提高鲁棒性。
该框架首先使用高效的Transformer提取每个模态的特征,然后利用注意力融合网络结合多模态信息。
该方法在1960名白内障手术患者的数据集上进行了评估
代码地址
方法
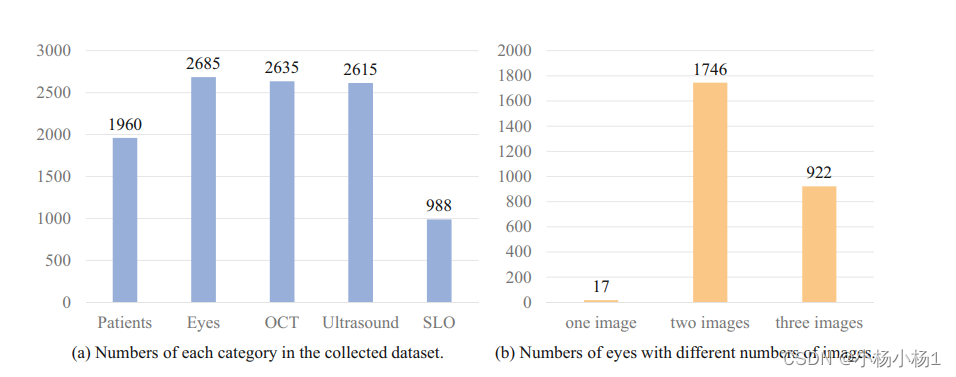
收集的数据集包含1960名患者的信息,涉及3种图像模态:光学相干断层扫描(OCT)、扫描激光眼底检查(SLO)。
数据集中包含完整的多模态图像的样本数量仅占三分之一。也就是说,大部分样本只有部分图像模态信息。
具有两种图像模态的样本数量最多,表示大部分患者数据包含两种成像技术的信息。
数据集中单模态样本(只有一种图像模态)和多模态样本(两种及以上图像模态)的数量比例相当
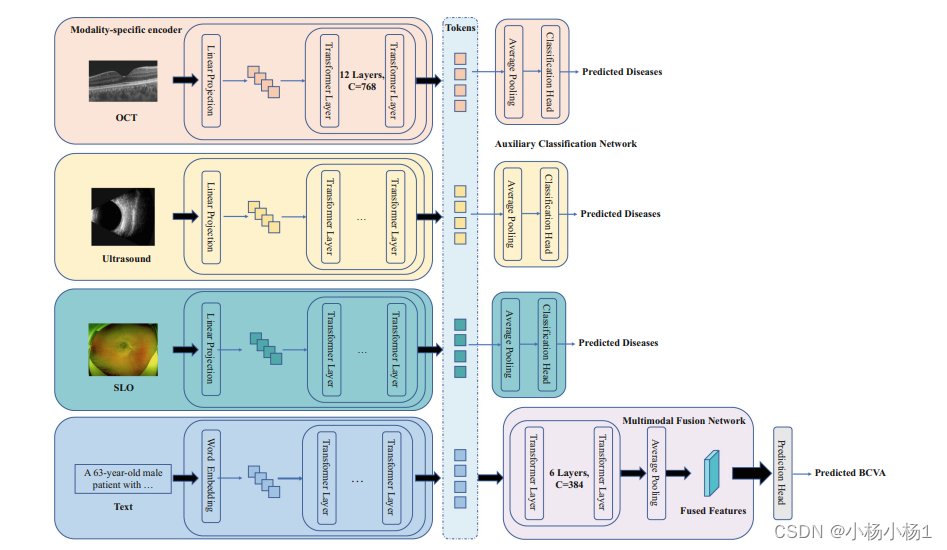
该框架包含两个主要组件:
- 模态特定编码器(Modality-specific Encoders)
- 多模态融合网络(Multimodal Fusion Network)
模态特定编码器使用标准的多头自注意力机制(Multi-head Self-Attention)提取每个模态(OCT、SLO等)的特征。
多模态融合网络则采用了掩码多头自注意力机制(Masked Multi-head Self-Attention)。这种机制可以有效处理不完整的多模态输入数据。
多模态融合网络以所有模态的特征(tokens)作为输入,结合跨模态信息。
每个辅助分类网络(Auxiliary Classification Network)仅接收单一模态的特征作为输入,用于预测特定任务指标。
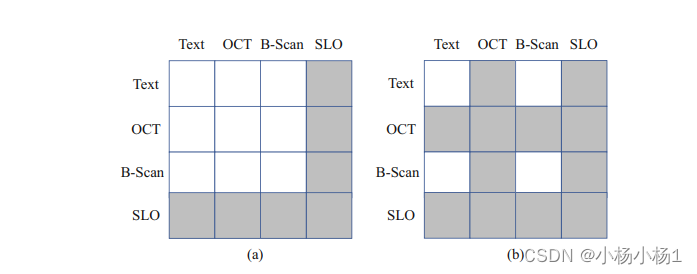 (a)展示了仅SLO模态缺失的情况,注意力掩码中相应的SLO部分被设置为0。
(a)展示了仅SLO模态缺失的情况,注意力掩码中相应的SLO部分被设置为0。
(b)展示了OCT和SLO两种模态都缺失的情况,相应的位置被设置为负无穷大。
这种注意力掩码机制确保了多模态融合网络能够专注于可用的模态信息,提高了对不完整输入的适应性
实验结果
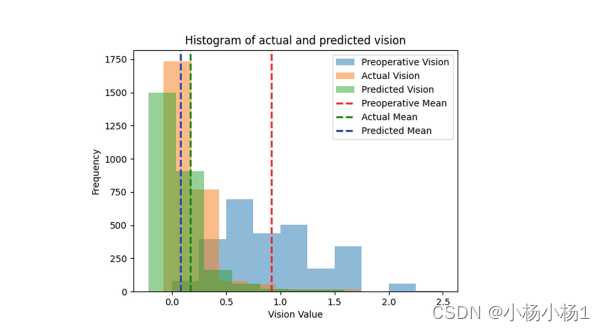
图中展示了三种视力分布:
- 手术前视力(Preoperative)
- 预测视力(Predictive)
- 手术后实际视力(Actual vision)