❀线性回归算法
- 📒1. 引言
- 📒2. 线性回归的基本原理
- 🎉回归方程
- 🎉最小化误差
- 🎉线性回归的假设条件
- 📒3. 线性回归算法的实现
- 📒4. 线性回归算法的特征工程
- 📒5. 线性回归模型评估与优化
- 📒5. 总结与展望
📒1. 引言
线性回归算法是一种在机器学习中广泛应用的预测性分析方法。其核心概念在于建立因变量(或称为目标变量、响应变量)与自变量(或称为特征、预测变量)之间的线性关系模型。简单来说,线性回归试图通过找到一条最佳的直线(在二维空间中)或一个超平面(在高维空间中),来最小化预测值与实际值之间的误差

在机器学习中,线性回归的重要性体现在其简洁性、可解释性以及广泛的适用性上。由于其模型形式简单,计算效率高,且能够提供直观的结果解释(即每个特征对目标变量的影响程度),因此在实际应用中备受青睐。
本文将带你一起探索线性回归算法的基本原理、应用场景以及如何使用Python实现它。

📒2. 线性回归的基本原理
🎉回归方程
线性回归是一种简单但功能强大的预测建模技术。它的核心思想是通过拟合一条直线(在二维空间中)或一个超平面(在多维空间中)来最小化预测值与实际值之间的误差。以下是线性回归算法原理的详细解释:
线性回归的数学模型可以表示为一个回归方程,其形式如下:
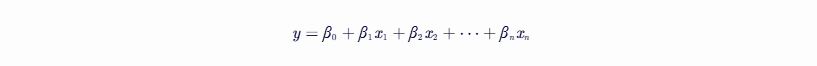
y = w0 + w1*x1 + w2*x2 + ... + wn*xn
- y是因变量(或称为目标变量、响应变量)
- x1 - > xn是自变量(或称为特征、预测变量)
- w0 - > wn是回归系数(或称为权重),它们决定了每个自变量对因变量的影响程度
- w0是截距项,表示当所有自变量都为零时因变量的值
线性回归的任务就是找到一组最佳的回归系数,使得预测值与实际值之间的误差最小
🎉最小化误差
为了找到最优的回归系数,我们需要一个准则来衡量预测值与实际值之间的误差。在线性回归中,我们通常使用均方误差(Mean Squared Error, MSE)作为误差准则。均方误差是所有样本的预测值与实际值之差的平方的平均值
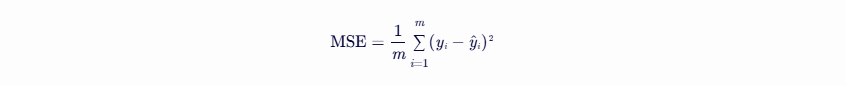
- m 是样本数量。
- y i 是第 i 个样本的实际值。
- y^ i 是第 i 个样本的预测值,它是通过将 x i 代入回归方程得到的。
我们的目标是找到一组回归系数使得均方误差最小
🎉线性回归的假设条件
- 线性关系: 自变量和因变量之间存在线性关系。这是线性回归模型的基本假设。
- 误差项的正态分布: 误差项(即实际值与预测值之差)服从均值为零的正态分布。这意味着误差项是随机的,并且没有固定的偏差。
- 独立性: 观测值(或称为样本)之间是独立的,即一个观测值的变化不会影响其他观测值。
同方差性:误差项的方差在所有观测值中都是相同的,即误差项的分布是稳定的。
这些假设条件确保了线性回归模型的准确性和可靠性。然而,在实际应用中,这些假设条件可能并不总是完全满足。因此,在使用线性回归模型时,我们需要对数据进行适当的检查和预处理,以确保模型的有效性
📒3. 线性回归算法的实现
介绍了这么多我们来一个简单的示例代码:
线性回归算法代码示例(伪代码)(Python)
# 导入必要的库
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
# 准备数据
# 假设我们有一个简单的数据集
X = np.array([[1], [2], [3], [4], [5]]).astype(np.float32) # 特征
y = np.array([2, 4, 6, 8, 10]).astype(np.float32) # 目标变量
# 划分数据集为训练集和测试集(这里简单起见,我们不划分)
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 实例化线性回归模型
model = LinearRegression()
# 使用训练数据拟合模型
# 由于这里我们没有划分数据集,所以我们直接使用全部数据来训练
model.fit(X, y)
# 进行预测
# 假设我们有一些新的数据点想要预测
X_new = np.array([[6], [7]]).astype(np.float32)
y_pred = model.predict(X_new)
# 评估模型性能(由于我们没有测试集,这里只是展示如何计算指标)
# 假设我们有一个y_test来评估
# y_test = np.array([12, 14]).astype(np.float32)
# mse = mean_squared_error(y_test, y_pred)
# r2 = r2_score(y_test, y_pred)
# 输出预测结果和模型系数
print("Predictions:", y_pred)
print("Model coefficients:", model.coef_) # 输出斜率
print("Model intercept:", model.intercept_) # 输出截距
# 如果你有测试集,可以取消注释并计算MSE和R²
# print("Mean Squared Error:", mse)
# print("R2 score:", r2)
- LinearRegression(): 这是sklearn库中线性回归模型的构造函数。它不需要任何参数,但会初始化一个线性回归模型对象。
- model.fit(X, y): 这是用来训练模型的函数。它将特征矩阵X和目标变量y作为输入,并计算最佳拟合的回归系数。
- model.predict(X_new): 这个函数用来对新的数据点X_new进行预测。它返回预测的目标变量值。
- model.coef_: 这是一个属性,存储了模型拟合后的回归系数(斜率)。
- model.intercept_: 这是一个属性,存储了模型拟合后的截距项。
- train_test_split(X, y, test_size=0.2, random_state=42): 这个函数用来将数据集划分为训练集和测试集。test_size参数指定了测试集的比例,random_state参数用来设置随机数生成器的种子以确保结果的可重复性。
- mean_squared_error(y_test, y_pred): 这是一个函数,用来计算均方误差(MSE),它是预测值与实际值之差的平方的平均值。
- r2_score(y_test, y_pred): 这是一个函数,用来计算决定系数(R²),它表示模型对数据的拟合程度。R²值越接近1,说明模型拟合得越好。
📒4. 线性回归算法的特征工程
特征工程在机器学习项目中扮演着至关重要的角色,特别是对于线性回归模型来说。良好的特征工程能够显著提升模型的预测性能,使模型更好地捕捉数据中的潜在关系。
重要性:提高模型准确性,减少过拟合,提升模型可解释性,降低计算成本
常用的特征工程技术
- 特征选择: 过滤法,包装法,嵌入法
- 特征缩放: 标准化,归一化,最大绝对值缩放
- 多项式特征生成
示例
假设我们有一个关于房价预测的数据集,其中包含以下特征:房屋面积(area)、卧室数量(bedrooms)、离市中心的距离(distance)和房屋年龄(age)。
特征选择:
首先,我们可以使用相关性分析来确定哪些特征与目标变量(房价)高度相关。例如,我们可能会发现房屋面积和卧室数量与房价高度相关,而离市中心的距离和房屋年龄与房价的相关性较弱。在这种情况下,我们可以选择只保留房屋面积和卧室数量作为特征
特征缩放:
在选择了特征之后,我们可以对它们进行缩放以改善模型的性能。由于房屋面积和卧室数量的尺度可能不同(例如,面积可能是以平方米为单位,而卧室数量是以整数为单位),我们可以使用标准化或归一化来缩放这些特征
代码示例(伪代码)(Python):from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaled_features = scaler.fit_transform(X[['area', 'bedrooms']])
多项式特征生成:
如果我们怀疑房屋面积和卧室数量与房价之间存在非线性关系,我们可以创建这些特征的多项式组合作为新的特征。例如,我们可以创建area^2、area * bedrooms等作为新的特征
代码示例(伪代码)(Python):from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(degree=2, include_bias=False) poly_features = poly.fit_transform(scaled_features)
模型训练与评估:
使用缩放和多项式特征生成后的数据集来训练线性回归模型,并评估其性能。如果模型性能得到显著改善,则说明特征工程是有效的
代码示例(伪代码)(Python):
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
model = LinearRegression()
model.fit(poly_features, y) # 假设y是目标变量(房价)
# 预测和评估...
y_pred = model.predict(poly_features)
mse = mean_squared_error(y, y_pred)
print(f"Mean Squared Error: {mse}")
我们可以展示如何应用特征选择、特征缩放和多项式特征生成等特征工程技术来改善线性回归模型的性能
📒5. 线性回归模型评估与优化
评估线性回归模型性能的几种常用方法:
- 均方误差: 均方误差是预测值与实际值之间差异的平方的平均值。MSE越小,模型性能越好
- 均方根误差: RMSE是MSE的平方根,它与原始数据有相同的尺度,使得误差更容易解释
- 决定系数R² 或 R方值: R²表示模型对数据的拟合程度。其值范围在0到1之间,越接近1表示模型拟合得越好
- 可视化评估: 通过绘制实际值与预测值的散点图或残差图,可以直观地评估模型的性能。残差图显示了每个数据点的预测误差,有助于识别异常值或模型可能存在的问题
优化线性回归模型性能的几种常用方法:
- 特征选择与特征工程: 通过特征选择和特征工程帮助我们提高模型对新数据的预测准确性
- 交叉验证: 使用交叉验证(如K折交叉验证)来评估模型在不同数据集上的性能,并选择最优的模型参数。这有助于减少过拟合,提高模型的泛化能力。
- 标准化: 将特征值转换为均值为0、标准差为1的分布。这有助于模型更好地处理不同尺度的特征。
- 特征缩放: 将特征值缩放到相似的范围,这有助于梯度下降算法更快地收敛。常见的特征缩放方法包括最小-最大缩放和Z-score标准化。
📒5. 总结与展望
线性回归在各个领域都有广泛的应用,包括但不限于:
- 房价预测:根据房屋的面积、位置、房龄等因素预测房价
- 销售预测:根据历史销售数据、广告投入、促销活动等因素预测未来销售额
- 股票价格预测:根据历史股价、公司财务状况、市场新闻等因素预测股票价格
- 生物医学:预测疾病风险、药物反应等

线性回归算法的局限性
- 输出范围限制: 线性回归模型的输出范围是连续的实数,这限制了它在处理分类问题中的应用,因为分类问题通常涉及离散的类别输出
- 对异常值敏感: 线性回归模型对异常值非常敏感。即使只有一个离群点,也可能对模型的拟合产生较大影响,从而影响预测的准确性
- 只能处理单个自变量: 一元线性回归模型只能处理一个自变量,无法处理多个自变量之间的相互影响关系。这在实际问题中可能会限制其应用
未来展望
- 非线性关系的处理: 随着算法研究的深入,未来的线性回归算法可能会结合其他技术(如神经网络、多项式回归等)来处理非线性关系,从而提高模型的适应性和预测准确性
- 多变量处理能力的增强: 为了满足实际问题中处理多个自变量的需求,未来的线性回归算法可能会发展出更加复杂和灵活的模型结构,如多元线性回归、逐步回归等。
- 与深度学习的融合: 深度学习在处理复杂数据方面表现出了强大的能力。未来的线性回归算法可能会与深度学习技术相结合,以更好地处理高维、非线性、非结构化的数据。
在学习线性回归算法的旅程即将结束时,我们不难发现其作为一种基础且强大的机器学习技术,在数据分析、预测建模和科学研究等领域扮演着举足轻重的角色。线性回归算法以其简洁性、易解释性和高效性赢得了广泛的应用。最后,我想说,学习线性回归算法是一次非常有价值的经历。它让我们领略了机器学习的魅力,也为我们未来的学习和研究奠定了坚实的基础。在未来的学习和工作中,我将继续深入探索机器学习的奥秘,并努力将所学知识应用到实际问题中去