问题:
命令行出现CUDA_VISIBLE_DEVICES=0 python trainer.py这种命令
这是Linux可以的,但是Windows不行。
解决方案:
这条命令的含义是指定某个GPU来运行程序,我们可以在程序开头添加指定GPU的代码,效果是一样的:
import os
os.environ["CUDA_VISIBLE_DEVICES"]='0'
或者在程序外部cmd命令行里执行以下命令,设置临时变量:
set CUDA_VISIBLE_DEVICES=0
或者直接添加到环境变量,同时记得删除原命令的CUDA_VISIBLE_DEVICES=0
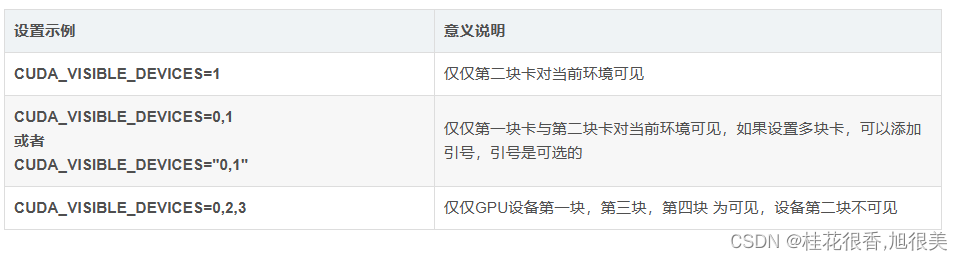
GPU卡号编码规则:
当主机有多个GPU设备时,设置CUDA_VISIBLE_DEVICES 环境变量可以改变CUDA程序所能使用的GPU设备。假如主机中有4块GPU设备,那么这些GPU设备的默认编号为[0,1,2,3],在默认情况下,编号为0的显卡为第一块卡。多卡设置规则如下:
备注规则:
CUDA应用运行时,CUDA将遍历当前可见的设备,并从零开始为可见设备编号。
第一种情况,卡1设置为主卡,但CUDA遍历时会设置为可见编号0。
最后一种情况,设备0,2,3将显示为设备0,1,2。
如果将字符串的顺序更改为“2,3,0”,则设备2,3,0将分别被设置为0,1,2。
如果为CUDA_VISIBLE_DEVICES 设置了不存在的设备,所有实际设备将被隐藏,CUDA 应用将无法使用GPU设备;如果设备序列是存在和不存在设备的混合,那么不存在设备前的所有存在设备将被重新编号,不存在设备之后的所有设备将被屏蔽。
当前可见的(重新编号后的)设备可使用CUDA 程序来查看,代码如下:
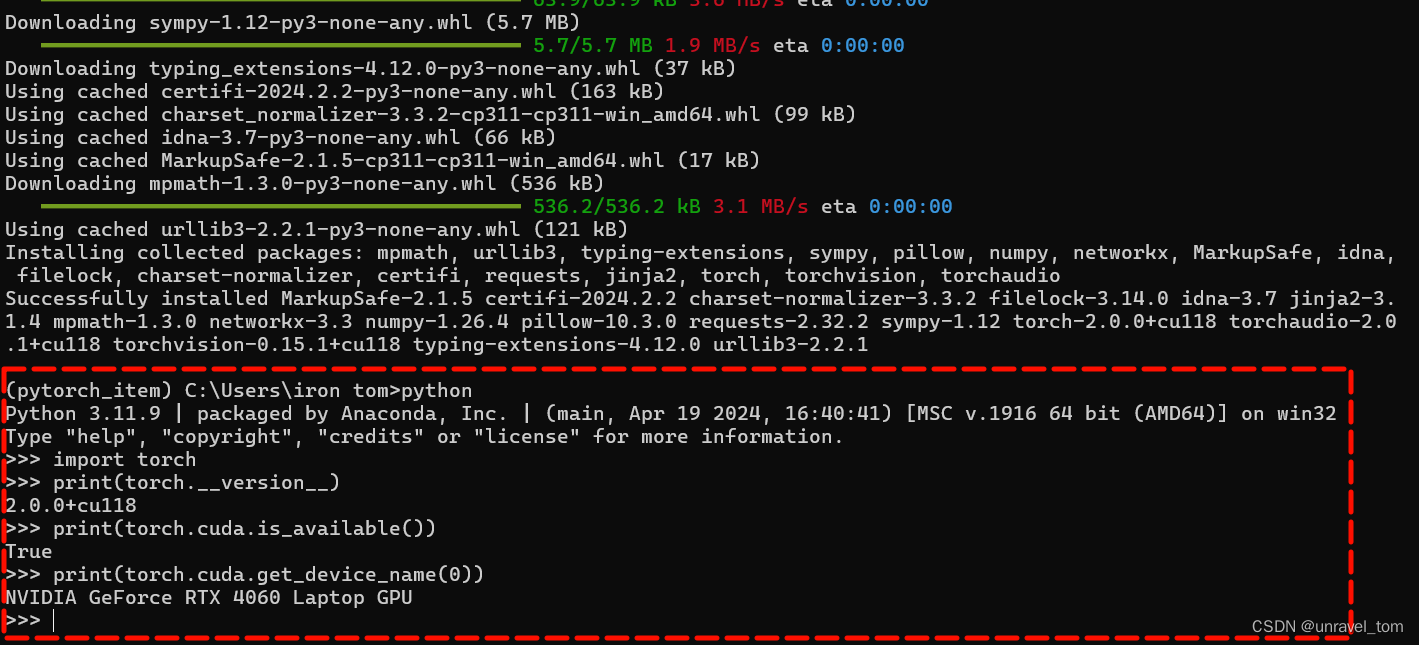
import torch
print(torch.cuda.current_device())
1. 临时设置
1.1 命令提前设置环境变量
#Linux: 后面的值为要使用的GPU编号,正常的话是从0开始
export CUDA_VISIBLE_DEVICES=0
#windows:
set CUDA_VISIBLE_DEVICES=0
1.2 Python代码中设置环境变量
import os
# 仅设置一块可见
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 设置多块可见
os.environ['CUDA_VISIBLE_DEVICES'] = '0,2,3'
1.3 命令行前指定
# 以下方法linux可用, windows 需要提前设置环境变量
CUDA_VISIBLE_DEVICES=0 python some-app.py
2. 永久设置
2.1 linux
通过编辑 ~/.bashrc 文件来永久设置,系统启动时将加载 ~/.bashrc 文件,达到自动设置的目的。
export CUDA_VISIBLE_DEVICES=1,2,3
然后通过 如下命令刷新环境变量
. ~/.bashrc
2.2 windows
添加到环境变量,同时记得删除原命令的CUDA_VISIBLE_DEVICES=0
3. 使用torch.cuda接口
import torch
#当前可见的(重新编号后的)设备可使用如下代码来查看
print(torch.cuda.current_device())
torch.cuda.set_device(0)
#或者 使用pytorch的并行GPU接口
net = torch.nn.DataParallel(model, device_ids=[0])
#确定GPU的个数
count = torch.cuda.device_count()
#决策使用哪个设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#把一个模型放到GPU上
device = torch.device("cuda:0")
model.to(device)
4. 使用torch.nn.DataParallel
多卡数据并行一般使用torch.nn.DataParallel
torch.nn.DataParallel(model,device_ids)
'''
使用的GPU一定是编号连续的
其中model是需要运行的模型,device_ids指定部署模型的显卡,数据类型是list/device。
device_ids中的第一个GPU(即device_ids[0])和model.cuda()或torch.cuda.set_device()中的第一个GPU序号应保持一致,否则会报错
举例:
'''
torch.nn.DataParallel(model, device_ids=device_ids)
torch.nn.DataParallel(modul, device_ids=[x1,x2,x3,x4,x5,x6,x7])
torch.nn.DataParallel(model,device_ids = range(torch.cuda.device_count()) )
此外如果两者的第一个GPU序号都不是0,比如设置为:
'''
如下代码,程序可以在GPU2和GPU3上正常运行。
device_ids的默认值是使用可见的GPU,不设置model.cuda()或torch.cuda.set_device()等效于设置了model.cuda(0)
'''
model=torch.nn.DataParallel(model,device_ids=[2,3])
model.cuda(2)
#模型绑定GPU代码
model = model.cuda()
device_ids = [0, 1]
model = torch.nn.DataParallel(model, device_ids=device_ids)
参考:
【疑难杂症】‘CUDA_VISIBLE_DEVICES‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。
CUDA 指定设备的方法,CUDA_VISIBLE_DEVICES 设置当前pytorch程序使用那些GPU设备