参考资料:活用pandas库
1、简介
借助“分割-应用-组合”(split-apply-combine)模式,分组操作可以有效地聚合、转换和过滤数据。
分割:基于键,把要处理的数据分割为小片段。
应用:分别处理每个数据片段。
组合:把处理结果组合成新的数据集。
该模式的强大在于,可以将原始数据分割成独立的片段分别进行处理。pandas的groupby工作方式与sql语言的group by相同。
2、聚合
聚合也称“汇总”(summarization),是指某种形式的数据归约。
(1)基本的单变量分组聚合
# 导入库
import pandas as pd
# 加载Gapminder数据集
df=pd.read_csv(r"...\data\gapminder.tsv",sep='\t')
# 计算每年平均预期寿命
avg_life_exp_by_year=df.groupby('year').lifeExp.mean()
print(avg_life_exp_by_year)
针对上面的例子,可以认为groupby语句创建了一个子集,里面含有各列的唯一值(或者列的唯一对)。
(2)pandas内置的聚合方法
| pandas方法 | numpy/scipy函数 | 说明 |
|---|---|---|
| count | np.count_nonezero | 频率统计(不包含NaN值) |
| size | 频率统计(包含NaN值) | |
| mean | np.mean | 求平均值 |
| std | np.std | 样本标准差 |
| min | np.min | 最小值 |
| quantile(q=0.25) | np.percentile(q=0.25) | 下四分位数 |
| quantile(q=0.50) | np.percentile(q=0.50) | 中位数 |
| quantile(q=0.75) | np.percentile(q=0.75) | 上四分位数 |
| max | np.max | 最大值 |
| sum | np.sum | 求和 |
| var | np.var | 无偏方差 |
| sem | scipy.stats.sem | 平均数标准误 |
| describe | scipy.stats.describe | 计数、平均数、标准差、25%、50%、75%分位数、最大值 |
| first | 返回第一行 | |
| last | 返回最后一行 | |
| nth | 返回第n行(python从0开始计数) |
# 根据所在的洲分组,针对每个组对预期寿命做汇总统计
continent_describe=df.groupby('continent').lifeExp.describe()
print(continent_describe)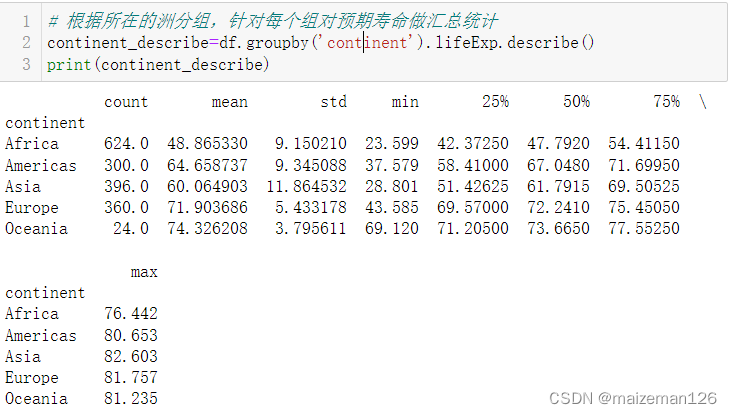
(3)聚合函数
除了直接调用聚合方法,还可以调用agg方法或aggregate方法,传入想用的聚合函数。使用agg或aggregate时,需要使用上表中numpy/scipy函数。
# 导入numpy库
import numpy as np
# 计算各洲的平均预期寿命
# 使用np.mean函数
cont_le_agg=df.groupby('continent').lifeExp.agg(np.mean)
print(cont_le_agg)
# agg和aggregate功能相同
cont_le_agg2=df.groupby('continent')['lifeExp'].aggregate(np.mean)
print(cont_le_agg2)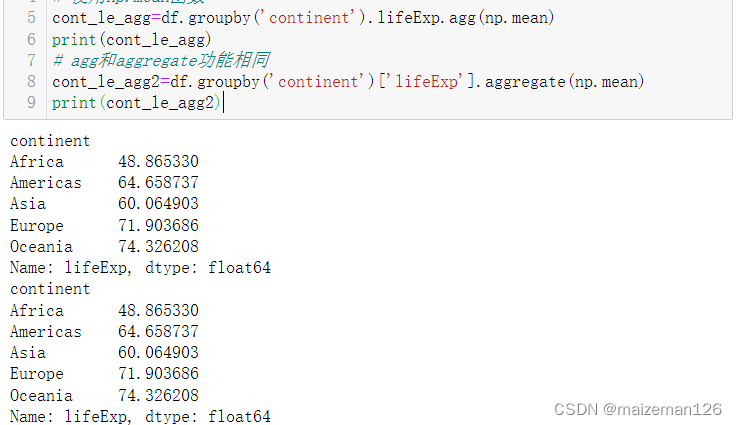
# 自定义函数的聚合
# 创建自定义函数
def my_mean_diff(values,diff_value):
"""
计算平均值和diff_value之差
"""
n=len(values)
sum=0
for value in values:
sum+=value
mean=sum/n
return (mean-diff_value)
# 计算全球平均预期寿命的平均值
global_mean=df.lifeExp.mean()
print(global_mean)
# 还有多个参数的自定义聚合函数
agg_mean_diff=df.groupby('continent').lifeExp.\
agg(my_mean_diff,diff_value=global_mean)
print(agg_mean_diff)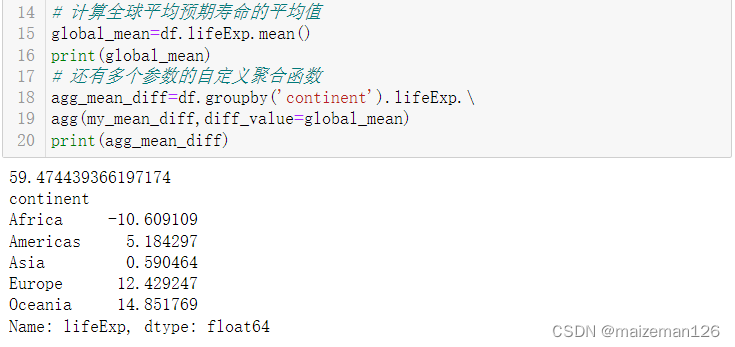
(4)同时传入多个函数
如果想同时计算多个聚合函数,可以先把他们全部放入一个python列表,然后把整个列表传入agg或aggregate中。这里所用函数仍然是上表中的sumpy/scipy函数。
# 按洲计算lifeExp的非零个数、平均值和标准差
gdf=df.groupby('continent').lifeExp.agg([np.count_nonzero,np.mean,np.std])
print(gdf)
(5)在agg/aggregate中使用字典
对于分组的DataFrame指定的dict时,键是DataFrame的列,值是聚合计算使用的函数。这种方法允许对一个或多个变量进行分组,对不同列同时使用不同的聚合函数。
可以在groupby之后把一个dict传入Series中,直接做汇总统计并将其返回,dict的键是新的列名,这与把dict传入分组的DataFrame时的行为不同,不建议使用。
# 对DataFrame使用字典聚合不同列
# 对于每一年,计算平均值lifeExp、中位数pop和中位数gdfPercap
gdf_dict=df.groupby('year').agg({
"lifeExp":"mean",
"pop":"median",
"gdpPercap":"median"})
print(gdf_dict)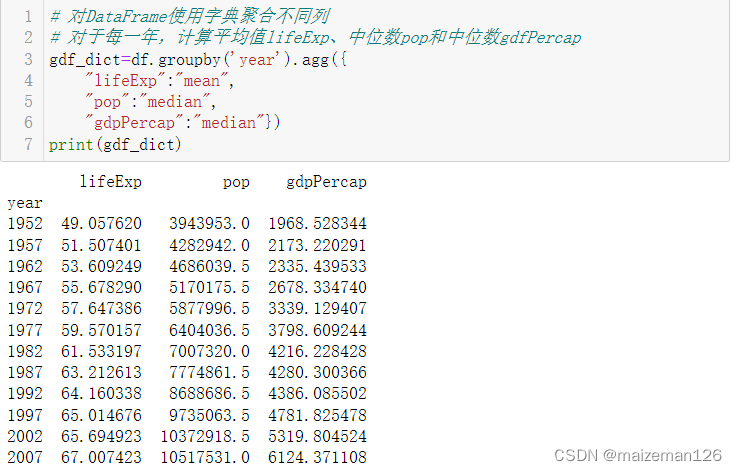
gdf=df.groupby('year')['lifeExp'].\
agg([np.count_nonzero,np.mean,np.std]).\
rename(columns={'count_nonzero':'count',
'mean':'avg',
'std':'std_dev'}).\
reset_index() # 返回一个普通DataFrame
print(gdf)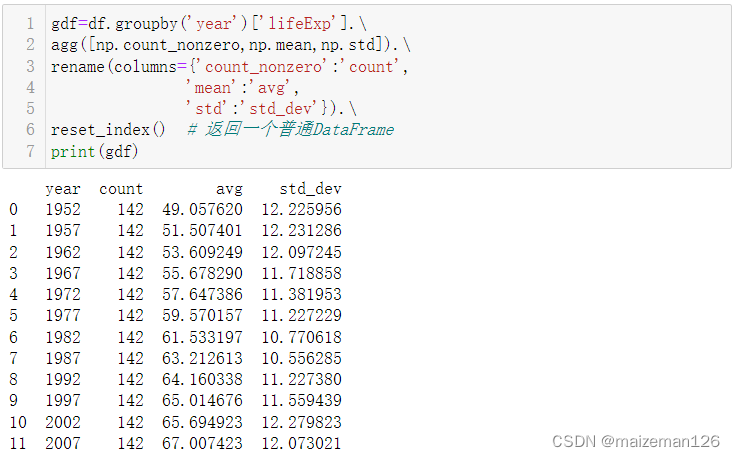


![【Qt秘籍】[003]-Qt环境变量配置-磨刀不误砍柴工](https://img-blog.csdnimg.cn/direct/babf7d71000e496b8fd90a1774d167c7.png)
![Collection(一)[集合体系]](https://img-blog.csdnimg.cn/direct/dc23da5d084542078c11deb736e79ef9.png)


![nginx源码阅读理解 [持续更新,建议关注]](https://img-blog.csdnimg.cn/direct/198598e14fe64f45b6ca5222c58bb8e8.png)