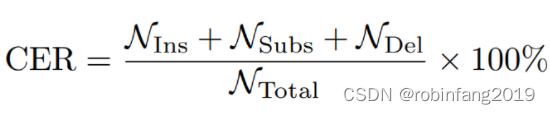题目
DeepETPicker: Fast and accurate 3D particle picking for cryo-electron tomography using weakly supervised deep learning
发表期刊: Nature Communications
发表时间:2024.02 Accepted
作者:Guole Liu, Tongxin Niu 中科院自动化所、中科院生物物理所
论文地址:https://www.nature.com/articles/s41467-024-46041-0?fromPaywallRec=false
源码地址:https://github.com/cbmi-group/DeepETPicker
Abstract
为了原位解析生物大分子的三维结构,通常需要从冷冻电子断层图中挑选大量颗粒。为了解决以往自动颗粒挑选算法的技术限制,本文开发了DeepETPicker深度学习模型,用于快速且准确地从冷冻电子断层图中挑选颗粒。训练只需要少量简化的标签作为弱监督,来减轻手动标注的负担。简化的标签和定制的轻量级模型架构以及和加速池相结合,可以显著提高性能。在模拟和真实断层图上进行测试时,本文方法通过实现了最高的整体精度和速度,超过了最先进的竞争方法,这转化为挑选颗粒的更高真实性和坐标精度,以及最终重建图的更高分辨率。本文方法开源,提供用户友好的界面,支持原位冷冻电子断层扫描。
简介
先介绍了cryoET和STA,以及颗粒挑选问题。
介绍存在的困难和挑战。
介绍现有方法,包括传统方法和深度学习方法。
为了挑选用于冷冻电子断层扫描的 3D 粒子,传统方法和基于深度神经网络 (DNN) 的方法均已开发出来。在传统方法中,模板匹配 ™ 和高斯差分 (DoG) 被广泛采用。在TM中,与要处理的断层图像最匹配的预定义模板的位置和方向是通过最大化它们的互相关性来确定的。然而,TM有一些局限性,包括对预定义模板的强烈依赖、需要手动调整互相关阈值以及低信噪比下的高误报率。 DoG 使用带通滤波器来去除高频和低频分量来拾取粒子。然而,它会不区分类别地选择颗粒,其性能在很大程度上取决于针对不同数据集的高斯滤波器的调整。
近年来,基于深度神经网络(DNN)的方法已成为冷冻电子断层扫描(cryo-ET)中3D粒子挑选的先进方法。例如,Faster-RCNN被用于在断层扫描图中逐层自动定位和识别不同结构,但未充分利用相邻层之间的3D信息。为推动3D粒子挑选算法的发展,SHREC挑战赛开发了模拟冷冻电子断层扫描数据集来评估不同粒子挑选方法的性能。结果显示,深度学习方法比传统方法(如TM)在处理速度、定位和分类性能上都优越。在SHREC2019挑战赛中,DeepFinder表现最佳,它使用3D-UNet生成分割体素图并通过均值漂移聚类算法确定粒子位置。在SHREC2020和SHREC2021挑战赛中,MC-DS-Net在分类性能上表现最佳,但其模型参数多,对硬件要求高,且需要真实全掩码进行训练,这在实际应用中通常不可得。相反,DeepFinder使用球形掩码进行近似,对中大尺寸的分子表现良好,但对小粒子的表现不如真实掩码。
考虑到真实冷冻电子断层扫描数据比SHREC挑战赛中的模拟数据更复杂,这些方法的性能需要在真实实验数据上进一步验证。总体而言,尽管开发了各种自动化粒子挑选方法,但其实际应用仍然有限,主要原因在于挑选精度、处理速度以及学习方法的手动标注成本等方面的限制。
为解决这些问题,我们开发了一种新的深度学习方法DeepETPicker,它能快速准确地从冷冻电子断层扫描图中挑选3D粒子,且训练成本低。该方法采用3D-ResUNet分割模型为backbone,通过弱监督和简化标签进行训练,以减少手动标注成本。通过对生成的分割mask进行快速后处理,得到单个颗粒的质心。为了提高DeepETPicker对小的大分子颗粒的定位性能,在3D-ResUNet模型的架构中加入了协调卷积和多尺度图像金字塔输入。为了解决实践中通常缺乏真正的大分子颗粒mask的问题,测试了不同类型的简化弱标签作为替代。为了消除边缘体素分割精度差的影响,提出了一种基于空间overlap的分割策略。为了最大限度提高速度,采用定制的轻量级模型和基于GPU加速的池化后处理。
在SHREC2020/2021模拟数据集上测试时,DeepETPicker在定位和分类方面实现了最高的整体处理速度和性能。另外在四个真实数据集(EMPAIR-10045,10651,10499,11125)上进一步验证了性能。
Result
DeepETPicker 概述
使用 DeepETPicker 从断层扫描图中挑选 3D 粒子的整体工作流程(图 1)包括训练阶段(图 1a–d)和推理阶段(图 1e–i)。
由于内存限制,断层扫描图通常太大,无法直接加载到 DNN 分割模型中进行训练。因此,它被分割成立方体体积,通常称为子断层图(图 1a, c, e)。
在训练阶段,给定一个输入子断层图,调整 DeepETPicker 的 DNN 分割模型参数,以最小化其输出与输入子断层图的体素级别标注标签定义的真实值之间的差异。通常,实验断层扫描图中超过 90% 的体素是背景体素,而大分子粒子在体积中的比例非常小。为更好地分割感兴趣的粒子并避免过度分割背景,在训练阶段提取以单个粒子为中心的子断层图。这一策略确保所有标注的粒子都被使用,并且每个体积至少包含一个粒子。
在推理阶段,每个断层扫描图按特定步幅和 N×N×N 的子断层图大小进行扫描(图 1e)。训练好的 DeepETPicker 用于处理未见过的子断层图,以生成单个粒子的体素级别掩码。然后进行基于 GPU 加速的池化后处理操作,以直接和快速识别粒子中心(图 1h)。在本研究中,DeepETPicker 的训练和推理均在一台 Nvidia GeForce GTX 2080Ti GPU 上进行。

DeepETPicker 具有友好的GUI,集成了多个功能,包括预处理输入tomogram,手动标注颗粒,可视化标注颗粒,生成弱标签,配置参数等。可视化结果可以通过滤波和直方图均衡操作进行调整。用户可以标记颗粒中心或删除错误标签。同一层析图中不同类别的颗粒可以同时被标记。标记颗粒的坐标可以导出成不同格式的文件。
在模拟断层图中实现了最佳整体性能
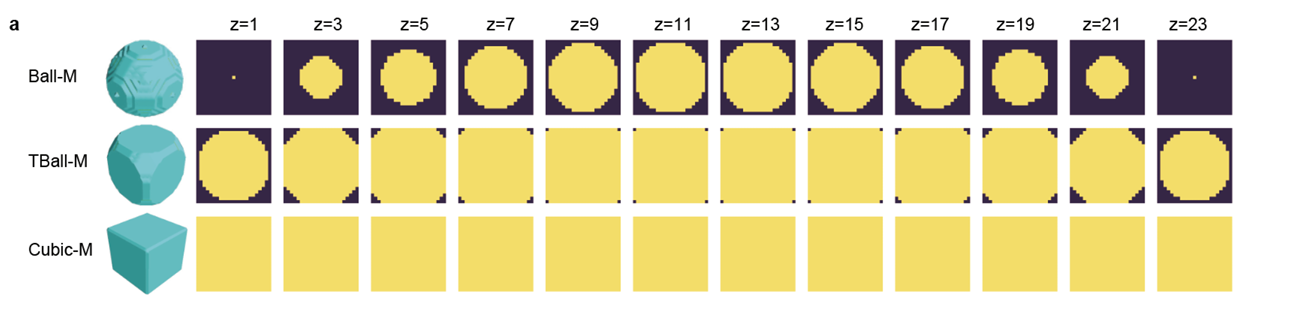
在层析图信噪比很低的情况下,人工标注很难生成大分子颗粒的完整分割mask。为了简化手工标注过程,以手工标注的颗粒中心为中心,生成了三种简化mask。对于每种简化mask其直径可以通过不同方式设置(图2和补充表2)。对于SHREC2021 ,简化mask的直径可以设置为和其对应的真实mask的大小成正比,也可以设置成恒定值。使用等直径的简化mask作为训练标签,避免了类不平衡的问题,简化了损失函数的选择。
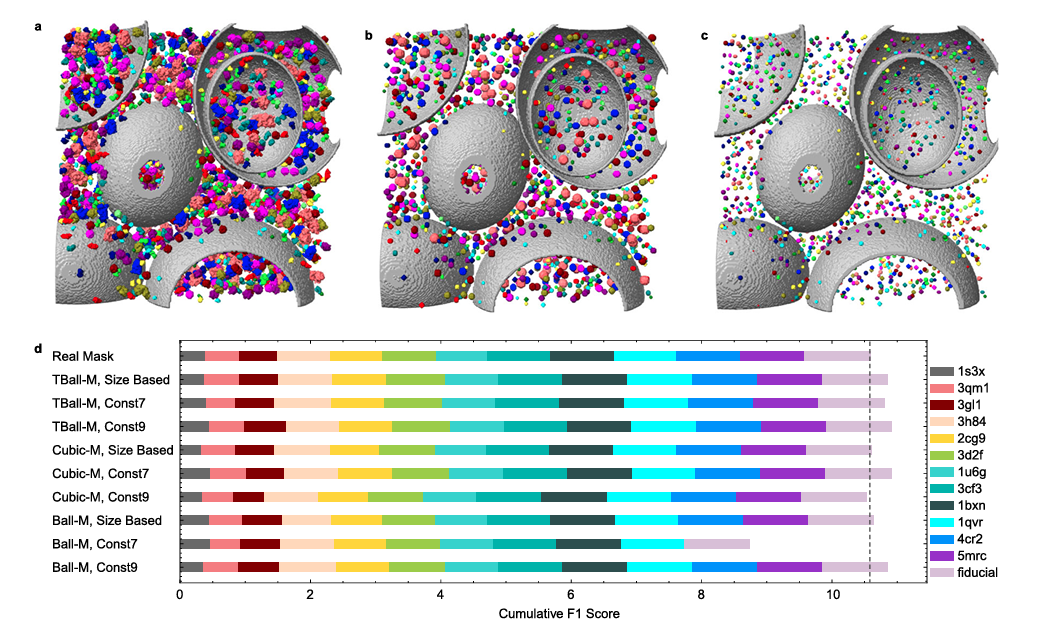
和Cubic-M、Ball-M mask相比,TBall-M 掩码提供更稳定且一致的定位和分类性能(图2d 补充表3 补充方法A.10)。此外,TBall-M 训练的3D-ResUNet 模型的平均F1分数在绝对量级上比真实mask训练的模型高2%,这可能是因为其提供了噪声标签,提高了训练模型在未见过的数据集上的泛化能力。有趣的是,以不同方式设置直径的 TBall-M mask 具有几乎相同的定位和分类性能,由于具有恒定直径的简化mask在实践中更方便设置,因此本文其余部分的结果都是使用直径 d=7 恒定的 TBall-M mask 获得的。
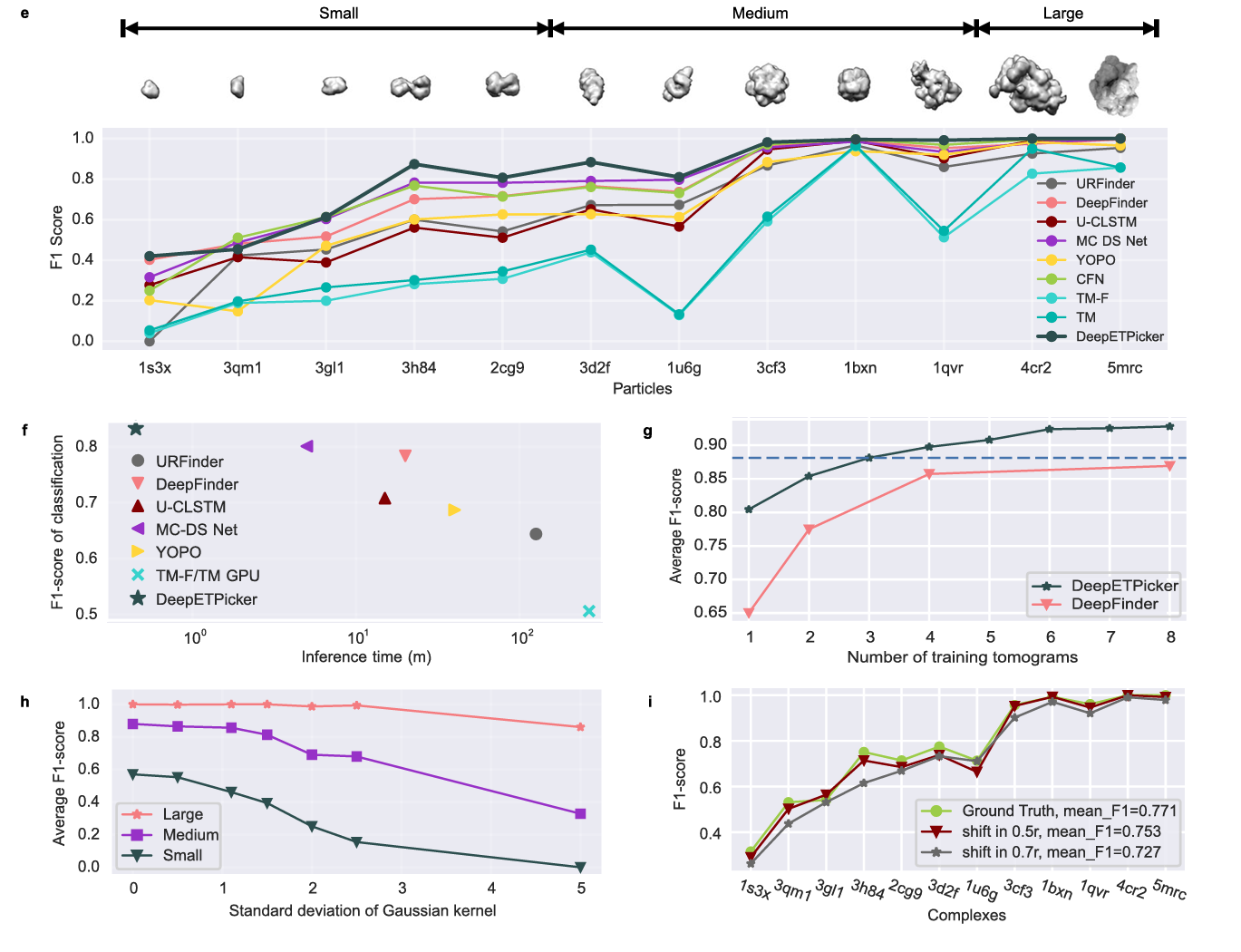
精确的颗粒中心定位对于子断层图平均很重要。和SHREC2021挑战赛中报告的其他方法相比,本文方法在TP/FP/FN/AD/precision/recall/F1这些指标上达到了最好的整体表现。对于包含各种大分子颗粒的断层图像,对这些颗粒的准确分类至关重要,特别是对于具有相似分子量或相似几何形状的不同颗粒。DeepETPicker在所有12类中的10种大分子颗粒上取得了最高的F1分数。分类F1值随着分子量的增加而增加,表明分子量较大的大分子颗粒更容易挑选,大概是因为在同一断层图中更多的体素被较大的颗粒占据。
在SHREC2021挑战中,MC-DS-Net实现了最佳分类F1分数和最短推理时间。而DeepETPicker实现了其推理时间的1/10,并实现了更好的性能。SHREC2020上本文方法也有类似的提升表现。
定制的轻量级高效的3D-ResUNet架构以及GPU加速的基于池化的后处理方法,是影响DeepETPicker性能的关键。
用于训练的标注数据量对基于DNN的模型的挑选性能有重大影响。和DeepFinder相比,DeepETPicker需要更少的训练数据即可在SHREC2020数据集上达到相同水平的性能(图2g)。当不同尺寸颗粒的分类F1和所使用的的训练断层图数量相对应时,对于小颗粒DeepETPicker显示出比DeepFinder更明显的分类性能优势。
我们还评估了不同颗粒大小和不同噪声水平下的颗粒挑选性能。我们在SHREC2021数据集上添加不同级别的高斯噪声,并评估噪声水平对不同大小颗粒的挑选性能的影响。随着SNR的降低,F1分类性能也会较低(图2h),颗粒越小,在较低SNR水平下的分类F1下降越大。
在极低信噪比的断层图中标记断层图像中的颗粒中心不可避免地会引入偏差。例如,我们计算了手动挑选的颗粒坐标和EMPAIR-10499细化后获得的颗粒坐标之间的欧氏距离,发现80%的颗粒距中心小于0.52r(r是颗粒半径),90%小于0.625r。为了更好地检查手工标注偏差对颗粒拾取结果的影响,我们向SHREC2021数据集的颗粒中心随机添加0.5r-0.7r的偏差。我们发现随机位移对DeepETPicker在不同大小的颗粒拾取性能上影响很小(图2i)。这表明本文方法对于手工标记引起的定位偏差具有良好的鲁棒性。
在DeepETPicker上进行消融实验,以3D-UNet作为baseline,来验证对3D-ResUNet架构进行的不同定制的贡献。结果发现添加残差连接将分类的平均F1提高了2%,添加坐标卷积和图像金字塔有效地提高了针对小颗粒的分类分数。数据增强大幅提高了模型的定位和分类性能。相邻局部最大值中较小颗粒的重复数据删除操作将F1提高了1%,重叠平铺策略将定位和分类的F1分别提高了5%和4%,表明其在推理阶段的重要性。
在真实断层图中挑选纯化颗粒方面实现了最佳整体性能
数据集:EMPIAR-10045,EMPIAR-10651。
对于 EMPIAR-10045,我们使用 DeepETPicker、crYOLO、DeepFinder和 TM 挑选80S核糖体颗粒,通过计算挑选颗粒的交集和差集,以成对的方式检查这些方法挑选的相同和不同的颗粒(图3a)。

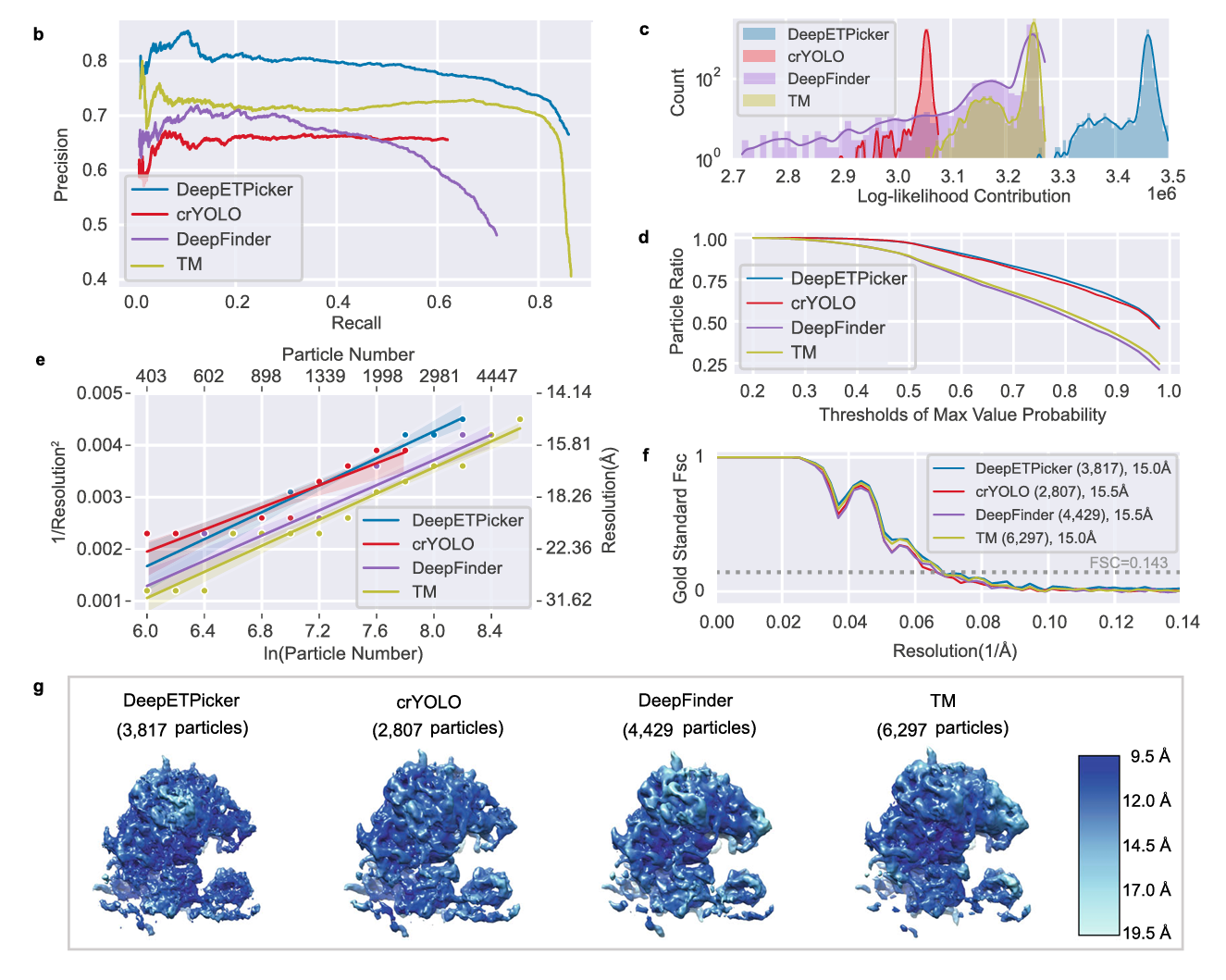
手动标注用于评估自动颗粒拾取方法和专家手动挑选颗粒的匹配程度。通过精度和召回率指标对四种方法进行比较。在固定recall下,DeepETPicker实现了最高的精度。此外,DeepETPicker和TM的最大召回率远高于DeepFInder和cryolo。当TM的召回率达到最大值时其精度急剧下降,表明挑选了更多的假阳性颗粒。
根据后续的子断层平均的结果进一步检验这些方法挑选颗粒的真实性和坐标精度。为了进行客观比较,在随后的对齐和分类过程中不进行颗粒筛选。在3D分类中只设置一个类,并根据RELION中3D分类方法的平移和方向参数进行3D自动细化。然后,绘制颗粒数量与相应计算的对数似然贡献的关系(图3c)。我们发现 DeepETPicker 拾取的颗粒的对数似然贡献的总体范围始终高于其他三种方法。同样的观察结果也适用于颗粒的并集和差集。另外还计算了颗粒的累计比率,绘制比率和阈值的关系图(图3d)。DeepETPicker 和 crYOLO 的累计比率曲线彼此接近,但明显优于 DeepFinder和TM。总体而言,较高的对数似然性和较好的最大值概览累计统计表明DeepETPicker拾取的颗粒更加真实和准确。
基于全局分辨率、局部分辨率和B因子测量的拾取颗粒的评估和基于对数似然分布和最大值概览的累计统计的评估一致(图3e-g)。
从不同颗粒数据集构建的map具有相似的全局分辨率,但是局部分辨率和RH图不同。假设这是因为不同方法挑选的不同颗粒的真实性和坐标精度存在差异。于是对差异集中的颗粒进行子断层平均,然后计算它们的全局分辨率。我们发现由DeepETPicker而不是由其他方法挑选的颗粒会产生正确的重建图,其全局分辨率和RH分辨率一致,表明了这些被拾取但被其他方法遗漏的颗粒是真阳性,其真实性和这些方法拾取的真阳性相似。而由DeepFinder和TM拾取而没有被本文方法拾取的颗粒产生了不正确的重建图,其全局分辨率比RH分辨率差得多,表明这些颗粒大多是误报。因此,虽然deepfinder和TM挑选的附加颗粒提高了half maps的SNR,并对具有改进的全局分辨率的FSC曲线做出了积极贡献,但它们没有对RH图和局部分辨率有积极贡献。
为了进一步验证不同方法拾取不同形状颗粒的性能,我们选择了EMIAR-10651中的T20S蛋白酶体,其形状为圆柱形。按照和上述分析相同的方案,再次证实了DeepETPicker可以挑选出其他方法遗漏的真阳性颗粒。
为了进一步检查这一观察是否正确,通过精度和召回率指标对不同方法的颗粒拾取结果和手动注释进行了比较。总体而言,DeepETPicker和TM实现了可比的性能,比DeepFinder稍好,比crYOLO好很多。此外还执行了子断层图平均进一步检查拾取颗粒的真实性和坐标精度。结果表明DeepETPicker得到的全局分辨率和局部分辨率都更好,显示了更多的结构细节。
在从真实断层图中原位颗粒挑选方面实现了最佳的整体性能
数据集:EMPIAR10499
和之前的实验步骤相似。
在从真实断层图中原位挑选较小颗粒方面实现了最佳的整体性能
数据集:EMPIAR-11125(分子量562kDa)
和之前的实验步骤相似。
讨论
总体而言,DeepETPicker在模拟和真实cryoET数据集上都优于最先进的竞争方法。结果证明了其在高分辨率原位cryoET研究中的应用潜力。后续研究中我们计划将颗粒取向参数加入到框架中,这将为后续的子断层图平均步骤提供有价值的信息。此外,计划进一步优化算法对小颗粒的分类性能。
方法
三种简化的标签
- Cubic masks
- Ball masks
- Truncated-Ball masks

这里的c是颗粒的类别。
给定断层图中的颗粒直径应在7-25像素之内。如果颗粒直径远大于25则可以使用适当的缩放操作。
这些简化的mask可以视为一类弱监督标签。实验表明这些简化标签训练的模型可以有效地分割断层图像中感兴趣的颗粒。
三维分割模型结构

模型采用编码器-解码器架构。具体来说,2D-ResNet中的残差连接思想被合并到3D-UNet中,以更好地从断层图像中提取特征。3D-ResUNet架构的编码器中有三个下采样层,解码器中有三个上采样层。解码器中使用三维转置卷积来对特征图进行上采样。使用 ELU 作为激活函数来加速训练过程的收敛。为了改善颗粒的定位,将协调卷积和图像金字塔输入合并到3D-ResUNet中,该网络将每个子断层图的体素作为输入,并分别为每个体素目标输出n个概率分数(n-1类以及背景)。协调卷积将输入图的空间上下文合并到卷积滤波器中,而图像金字塔输入保留不同分辨率级别的输入图像的特征。
模型训练和验证的配置
训练集数据增强:随机裁剪、镜像变换、小于5%的弹性变形、缩放以及随机旋转。
优化器:AdamW
多类别的Dice loss
广义的F1-score,加了个α超参数来更加重视模型召回率。
后处理:均值池化非极大值抑制(MP-NMS)和重叠块(OT)
提出的MP-NMS由多次均值池化迭代和一次非极大值抑制组成,在二值图上作为初始输入执行。图1h显示了应用与40×40像素带下的二值图像的MP-NMS实例。每次MP操作之后,mask边缘的体素都会被拉近背景的体素值,随着MP迭代次数的增加,mask的所有体素都会更新。最后二值mask被转换成soft mask。体素距离背景越远则值越大。每个局部最大值都可以被视为候选颗粒中心,局部最大值越大,是颗粒中心的概览越高。MP-NMS可以区分部分重叠的多个颗粒的中心,只要它们具有可区分的特征。和DeepFInder中用mean-shift聚类算法相比,MP-NMS使用GPU加速时会快很多。
为了消除子断层图像中边缘体素分割精度差的负面影响,在inference阶段使用了OT策略。图1h为例,假设蓝色框标记的图像是模型的输出,则在推理阶段仅考虑黄色框标记的中心区域来消除边缘像素分割不良。红色框的大小是使用pad_size超参数确定的。
为了减少背景干扰并避免颗粒检测期间的重复,执行了两个进一步的后处理操作。首先移除低于阈值的局部最大值;其次如果两个局部最大值之间的最小欧氏距离低于特定阈值,则丢弃较小的局部最大值。
评价指标
precision,recall,F1
对于真实数据:B-factor,全局分辨率,局部分辨率,log-likelihood distribution,maximum value probablility
具有较高对数似然和最大值概览的颗粒数量越多,表明颗粒挑选的坐标精度越好,真实性越好。