- 变分自编码器与传统编码器:比较、应用与发展历程
- 传统自编码器(AE)
- 基本原理
- 应用
- 发展起源
- 变分自编码器(VAE)
- 基本原理
- 应用
- 发展起源
- 结论
变分自编码器与传统编码器:比较、应用与发展历程
在深度学习和机器学习的广阔领域中,自编码器(AE)和变分自编码器(VAE)是两种重要的神经网络架构,它们在数据压缩、特征学习和生成模型等方面有着广泛的应用。本篇博客将详细探讨这两种网络的关系、各自可以解决的问题以及它们的起源和发展。
传统自编码器(AE)
基本原理
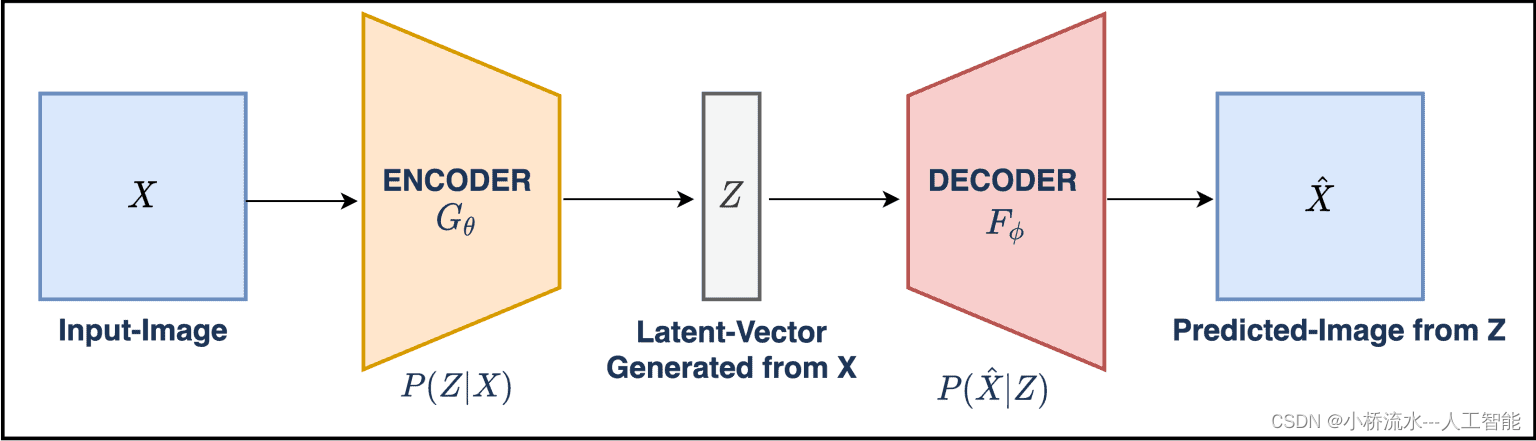
自编码器是一种无监督的神经网络,它学习一种将输入数据压缩成较低维空间的编码,然后再重构出原始数据的过程。其基本结构包括两部分:编码器(Encoder)和解码器(Decoder)。编码器负责将输入数据映射到一个隐藏的内部表示(即编码),解码器则从这个编码重构出原始输入数据。
应用
- 数据去噪:通过训练自编码器从带噪声的数据中重构出干净的数据。
- 降维:类似于PCA,自编码器可用于数据降维和特征提取。
- 预训练:自编码器的编码部分可以用于深度神经网络的预训练,特别是在标签数据稀缺的情况下。
发展起源
自编码器的概念可以追溯到1980s的连接主义学派,最初被用作一种有效的数据压缩工具,随后在深度学习的发展中被广泛用于无监督学习的特征学习。
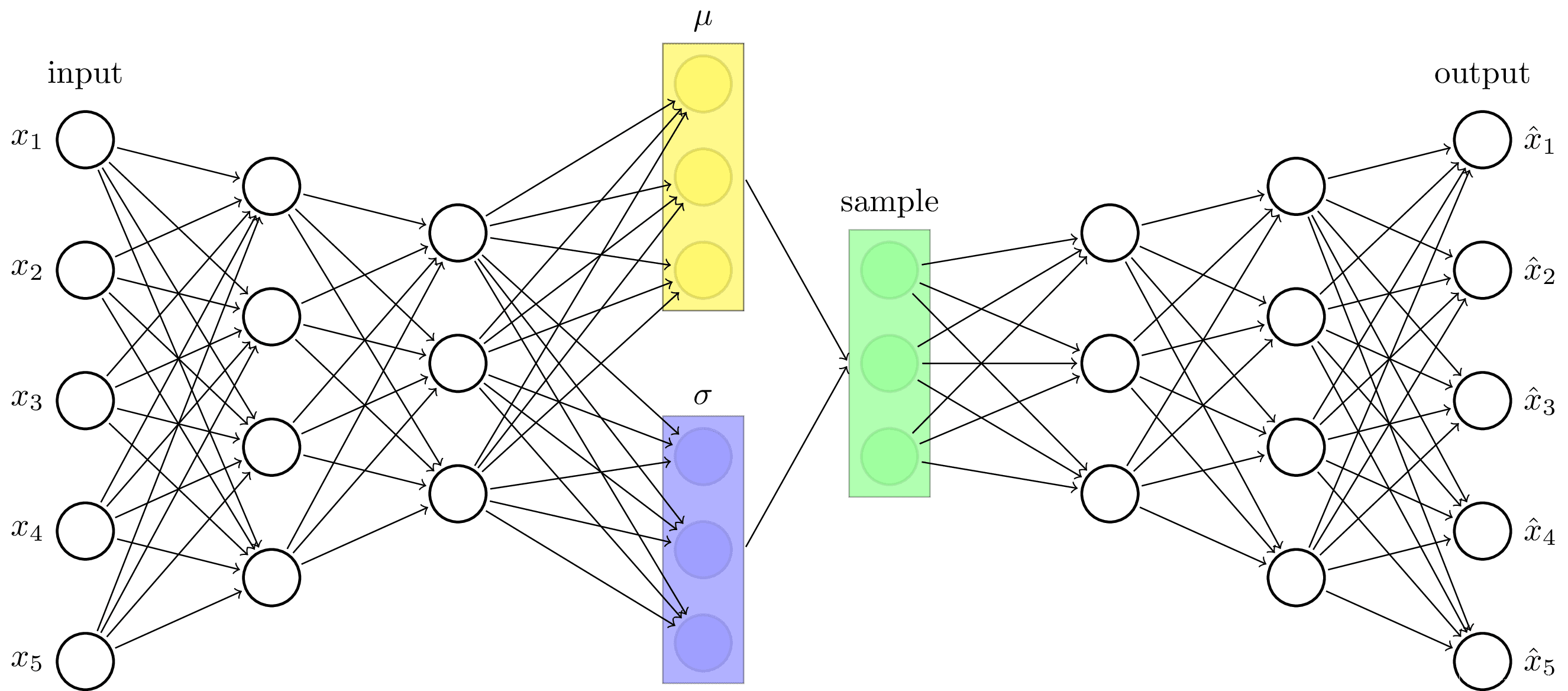
变分自编码器(VAE)
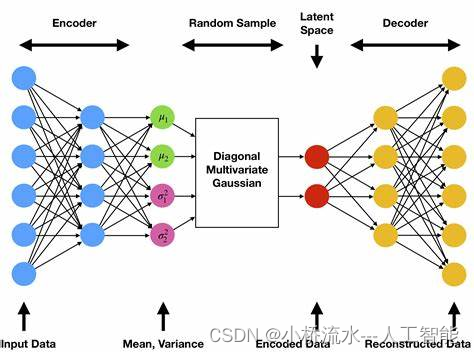
基本原理
变分自编码器是自编码器的一种扩展,它在自编码器的基础上引入了概率生成模型的思想。与传统自编码器不同的是,VAE的编码器输出的不是一个具体的编码,而是编码的分布参数(通常是均值和方差)。解码器则从这个分布中抽样生成编码,再重构输入数据。这种结构使得VAE不仅能够进行有效的编码和解码,还能生成与训练数据类似的新数据。
应用
- 生成模型:VAE可以生成新的、与训练数据类似的样本,例如人脸、文字等。
- 半监督学习:由于其生成模型的性质,VAE可以在标签数据极少的情况下进行有效的学习。
- 风格迁移:在图像和文本领域,VAE能够学习到内容和风格的分离,实现风格迁移。
发展起源
变分自编码器的概念是在2013年由Kingma和Welling在论文《Auto-Encoding Variational Bayes》中首次提出。它结合了深度学习和贝叶斯推理的方法,迅速成为生成模型领域的热门研究方向。
结论
传统自编码器和变分自编码器虽然在结构上有相似之处,但它们在应用和潜在功能上有着本质的不同。 传统自编码器主要用于特征提取和数据重构,而变分自编码器则在生成新的数据样本方面展现出了卓越的性能。理解这两种模型的不同将有助于选择合适的模型解决特定的问题,无论是在实际应用还是科研中。希望本篇博客能帮助您更深入地理解这两种网络的功能和应用,为您的学习和研究提供指导。