1、KerasNLP简介
KerasNLP是一个与TensorFlow深度集成的库,旨在简化NLP(自然语言处理)任务的建模过程。它提供了一系列高级API,用于预处理文本数据、构建序列模型和执行常见的NLP任务,如情感分析、命名实体识别和机器翻译等。
通过KerasNLP,开发者可以轻松地构建和训练复杂的NLP系统,而无需深入理解底层实现的复杂性。KerasNLP提供了清晰、简洁的API设计,使开发者可以快速上手。例如,只需几行代码,就可以进行分词、词汇嵌入(Word Embeddings)、句子编码等操作。
KerasNLP基于TensorFlow,因此可以充分利用GPU和TPU加速计算,为大规模NLP任务提供高性能支持。库中的每个组件都是模块化的,允许开发者根据需要自由组合和扩展。
KerasNLP是一个功能强大、易于使用的NLP库,为开发者提供了一种高效、灵活的方式来处理NLP任务。
1.1 KerasNLP的主要应用场景
KerasNLP在多个自然语言处理(NLP)应用场景中表现出色,主要包括但不限于以下方面:
- 文本分类:利用KerasNLP可以快速构建和优化文本分类模型,如情感分析、新闻主题分类等。这些模型可以识别文本中的关键信息,并将其归类到预定义的类别中。
- 机器翻译:KerasNLP具有强大的序列模型构建能力,因此可以作为搭建神经网络机器翻译系统的基础。通过训练模型,可以实现源语言到目标语言的自动翻译。
- 问答系统:在对话式AI开发中,KerasNLP可以帮助提取关键信息并生成准确的响应。这包括从文本中提取关键信息以回答问题,或者生成与问题相关的自然语言回答。
- 命名实体识别:KerasNLP可以识别文本中的专有名词、人名、地名等命名实体,并将其分类到预定义的类别中。这对于信息抽取、知识图谱构建等任务非常有用。
- 语音识别:虽然KerasNLP主要关注NLP任务,但它也可以与语音识别技术结合使用。例如,可以使用KerasNLP对语音转文字后的文本进行进一步处理和分析。
- 推荐系统:虽然Keras本身不直接针对推荐系统,但结合NLP技术,KerasNLP可以用于构建基于文本内容的推荐系统。通过分析用户的文本偏好和行为,可以生成个性化的推荐内容。
- 时间序列分析:虽然这不是KerasNLP的专长领域,但由于其底层支持TensorFlow,因此也可以用于处理和分析时间序列数据,如股票价格预测、天气预测等。
1.2 KerasNLP的优点和缺点
KerasNLP是一个专注于自然语言处理(NLP)任务的库,其基于Keras框架,并与TensorFlow等深度学习框架紧密集成。以下是KerasNLP的一些优点和缺点:
优点:
- 简单易用:KerasNLP继承了Keras简洁、直观的API设计,使得开发者可以快速上手,并高效构建NLP模型。无需深入了解底层实现的复杂性,即可进行分词、词汇嵌入、句子编码等操作。
- 基于TensorFlow:KerasNLP基于TensorFlow框架,因此可以充分利用GPU和TPU加速计算,为大规模NLP任务提供高性能支持。同时,TensorFlow的广泛支持和丰富的生态系统也为KerasNLP提供了强大的后盾。
- 丰富的NLP工具:KerasNLP提供了丰富的NLP工具,包括预训练的词嵌入模型、文本分类模型、序列生成模型等,使得开发者可以快速地构建和训练NLP应用。
- 模块化设计:KerasNLP的组件采用模块化设计,允许开发者根据需要自由组合和扩展。这种灵活性使得KerasNLP能够适应各种复杂的NLP任务。
- 强大的社区支持:由于KerasNLP基于Keras和TensorFlow等广泛使用的框架,因此它拥有庞大的用户社区。这意味着开发者可以通过社区获取支持、分享经验和解决问题,从而更高效地学习和使用KerasNLP。
缺点:
- 灵活性相对较低:虽然KerasNLP提供了简洁易用的API和丰富的NLP工具,但这也可能导致其在某些方面缺乏灵活性。对于一些特殊的NLP任务或需求,可能需要开发者自行编写代码或寻找其他解决方案。
- 学习曲线可能较陡峭:虽然KerasNLP的API设计相对简洁直观,但对于初学者来说,学习和理解NLP任务和深度学习模型的基本原理可能需要一定的时间和努力。
- 依赖外部框架:KerasNLP基于Keras和TensorFlow等外部框架,因此可能需要安装和配置这些框架才能使用KerasNLP。这可能会增加一些额外的复杂性和开销。
- 更新速度可能较慢:由于NLP领域的研究和进展非常迅速,新的算法和技术不断涌现。然而,由于KerasNLP需要基于Keras和TensorFlow等框架进行开发和维护,因此其更新速度可能相对较慢,无法及时跟进最新的NLP技术和算法。
2、KerasNLP的使用方法
2.1内容梗概
本文将通过情感分析的例子,展示六个不同复杂度的模块化方法:
- 使用预训练分类器进行推理
这一步是最简单的,直接使用已有的预训练模型进行推理,无需进行任何修改或训练。只需要加载预训练好的模型,并传入待分析的文本即可获取情感倾向。
-
微调预训练的主干模型
在这一步中,我们将加载一个预训练的主干模型(如BERT、Transformer等),并在一个特定任务(如情感分析)的数据集上进行微调。微调意味着我们保留模型的大部分权重,但会更新一部分权重以适应新任务。 -
使用用户控制的预处理进行微调
在微调模型时,预处理步骤(如文本清洗、分词、词汇嵌入等)通常对模型性能有很大影响。在这一步中,我们将展示如何自定义预处理步骤,并在微调模型时应用这些步骤。 -
微调自定义模型
在这一步中,我们将从头开始构建一个自定义的模型结构(基于现有的模型架构,但可能包含一些自定义层或连接),并在情感分析数据集上进行微调。 -
预训练主干模型
在某些情况下,我们可能需要从头开始训练一个全新的模型,而不是使用预训练的模型。在这一步中,我们将展示如何预训练一个主干模型,使其能够在各种NLP任务上具有良好的泛化能力。 -
从头开始构建和训练自己的Transformer模型
这是最复杂的一步,我们将从头开始设计并训练一个完整的Transformer模型。这包括定义模型的架构、编写自定义层、实现训练循环等。这一步需要深厚的NLP和深度学习知识,但也会带来最大的灵活性和定制性。
通过本文,读者可以逐步了解如何从简单的模型使用开始,逐步深入到模型的自定义和训练,以及最终构建自己的NLP模型。每一步都展示了如何利用KerasNLP(或其他NLP库)的模块化特性,使得NLP任务的开发更加高效和灵活。
2.2 安装和导入
!pip install -q --upgrade keras-nlp
!pip install -q --upgrade keras # Upgrade to Keras 3.
import os
os.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"
import keras_nlp
import keras
# Use mixed precision to speed up all training in this guide.
keras.mixed_precision.set_global_policy("mixed_float16")
2.3API 快速入门
我们最高级的API是keras_nlp.models。这些符号涵盖了将字符串转换为标记、将标记转换为密集特征,以及将密集特征转换为特定任务输出的完整用户流程。对于每种XX架构(例如,Bert),我们提供以下模块:
分词器 (Tokenizer): keras_nlp.models.XXTokenizer
作用:将字符串转换为标记ID的序列。
为什么它很重要:字符串的原始字节维度太高,不适合作为特征使用,因此我们首先将它们映射到少量的标记上,例如将"The quick brown fox"转换为[“the”, “qu”, “##ick”, “br”, “##own”, “fox”]。
继承自:keras.layers.Layer。
预处理器 (Preprocessor): keras_nlp.models.XXPreprocessor
作用:从分词开始,将字符串转换为被主干模型消费的预处理张量字典。
为什么它很重要:每个模型都使用特殊的标记和额外的张量来理解输入,例如分隔输入段和识别填充标记。将每个序列填充到相同的长度可以提高计算效率。
包含:XXTokenizer。
继承自:keras.layers.Layer。
注意:这里的"XX"应替换为具体的模型架构名称,如"Bert"或"Transformer"等。
主干模型 (Backbone): keras_nlp.models.XXBackbone
作用:将预处理后的张量转换为密集特征。它不直接处理字符串,需要先调用预处理器。
为什么它很重要:主干模型将输入的标记提炼为密集特征,这些特征可以在下游任务中使用。通常,主干模型会在一个语言建模任务上使用大量无标签数据进行预训练。将这种信息转移到新任务上是现代NLP的重大突破。
继承自:keras.Model。
任务模型 (Task): 例如,keras_nlp.models.XXClassifier
作用:将字符串转换为特定任务的输出(例如,分类概率)。
为什么它很重要:任务模型结合了字符串预处理、主干模型和特定任务的层,以解决诸如句子分类、标记分类或文本生成等问题。这些额外的层必须在有标签的数据上进行微调。
包含:XXBackbone 和 XXPreprocessor。
继承自:keras.Model。
注意:这里的"XX"应替换为具体的模型架构名称,如"Bert"或"Transformer"等。在实际应用中,你会看到类似keras_nlp.models.BertBackbone和keras_nlp.models.BertClassifier这样的具体类名。
以下是BertClassifier的模块化层次结构(所有关系都是组合性的):
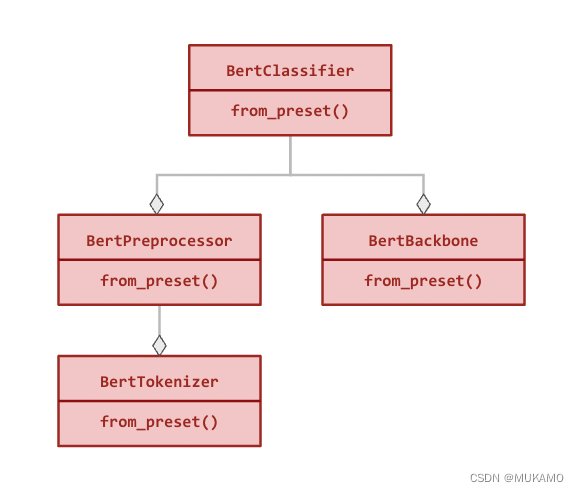
所有的模块都可以独立使用,并且除了标准构造函数外,还提供了from_preset()方法,该方法用于使用预设的架构和权重来实例化类(参见以下示例)。
2.4 数据准备
我们将使用一个运行中的例子,即IMDB电影评论的情感分析任务。在这个任务中,我们使用文本预测评论是否正面(标签 = 1)或负面(标签 = 0)。
我们使用keras.utils.text_dataset_from_directory来加载数据,它利用了功能强大的tf.data.Dataset格式来处理样本。
!curl -O https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
!tar -xf aclImdb_v1.tar.gz
!# Remove unsupervised examples
!rm -r aclImdb/train/unsup
BATCH_SIZE = 16
imdb_train = keras.utils.text_dataset_from_directory(
"aclImdb/train",
batch_size=BATCH_SIZE,
)
imdb_test = keras.utils.text_dataset_from_directory(
"aclImdb/test",
batch_size=BATCH_SIZE,
)
# Inspect first review
# Format is (review text tensor, label tensor)
print(imdb_train.unbatch().take(1).get_single_element())
3、使用预训练分类器进行推理
在KerasNLP中,最高层次的模块是任务(Task)。一个任务是一个keras.Model,它由(通常是预训练的)主干模型(backbone model)和特定于任务的层组成。下面是一个使用keras_nlp.models.BertClassifier的示例。
注意:输出是每个类别的对数几率(logits,即未归一化的概率)(例如,[0, 0] 表示正类有50%的可能性)。在二元分类中,输出是[负类, 正类]。
classifier = keras_nlp.models.BertClassifier.from_preset("bert_tiny_en_uncased_sst2")
# Note: batched inputs expected so must wrap string in iterable
classifier.predict(["I love modular workflows in keras-nlp!"])
所有任务都有一个from_preset方法,该方法使用预设的预处理、架构和权重来构造一个keras.Model实例。这意味着我们可以传递任何被keras.Model接受的原始字符串格式,并获得特定于我们任务的输出。
这个特定的预设是一个在sst2(另一个电影评论情感分析任务,这次来自Rotten Tomatoes)上微调过的"bert_tiny_uncased_en"主干模型。我们为了演示目的使用了小型架构,但为了达到最佳性能,建议使用更大的模型。对于BertClassifier可用的所有特定于任务的预设,请查看我们的keras.io模型页面。
现在让我们在IMDB数据集上评估我们的分类器。你会注意到我们不需要在这里调用keras.Model.compile。所有像BertClassifier这样的任务模型都带有编译的默认设置,这意味着我们可以直接调用keras.Model.evaluate。当然,你总是可以像平常一样调用compile来覆盖这些默认设置(例如,添加新的指标)。
下面的输出是[损失, 准确率]。
classifier.evaluate(imdb_test)
4、微调预训练的BERT主干模型
当我们的任务有特定的标记文本可用时,微调一个自定义的分类器可以提高性能。如果我们想要预测IMDB评论的情感倾向,使用IMDB数据应该比使用Rotten Tomatoes数据表现得更好!而且,对于许多任务来说,可能没有相关的预训练模型可用(例如,分类客户评论)。
微调的工作流程几乎与上述相同,除了我们请求仅针对主干模型的预设,而不是整个分类器的预设。当传入一个主干预设时,任务模型会随机初始化所有特定于任务的层,以准备进行训练。对于BertClassifier可用的所有主干预设,请查看我们的keras.io模型页面。
要训练你的分类器,就像使用任何其他keras.Model一样,使用keras.Model.fit。就像我们在推理示例中一样,我们可以依赖任务的编译默认值,并跳过keras.Model.compile。由于包含了预处理步骤,我们再次直接传入原始数据。
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased",
num_classes=2,
)
classifier.fit(
imdb_train,
validation_data=imdb_test,
epochs=1,
)
在这里,即使IMDB数据集比sst2小得多,但仅通过一个训练周期,我们就看到了验证准确率的大幅提升(从0.78提高到0.87)。
5、用户控制预处理的微调
用户控制预处理的微调(Fine tuning with user-controlled preprocessing)是指在微调预训练模型时,用户能够根据自己的需求和数据特性来控制数据预处理步骤。这通常包括文本清洗、分词、标记化(tokenization)、填充(padding)、截断(truncation)等步骤,以确保输入数据符合模型的要求,并优化模型在新任务上的性能。
通过用户控制预处理,可以确保预处理步骤与任务的特定需求相匹配,避免不必要的信息丢失或引入噪声,从而提高模型在特定任务上的准确性和泛化能力。此外,用户还可以根据数据的特点和模型的性能进行迭代和优化,以找到最佳的预处理策略。
对于某些高级训练场景,用户可能更希望直接控制预处理步骤。对于大型数据集,可以在训练前对数据进行预处理并将其保存到磁盘,或者使用tf.data.experimental.service的单独工作池进行预处理。在其他情况下,需要自定义预处理来处理输入。
通过在任务模型的构造函数中传递preprocessor=None,可以跳过自动预处理,或者传递一个自定义的BertPreprocessor。
从相同预设中分离预处理
每个模型架构都有一个与之平行的预处理器层(Layer),该层有自己的from_preset构造函数。为这个层使用相同的预设将返回与任务相匹配的预处理器。
在这个工作流程中,我们使用tf.data.Dataset.cache()在三个训练周期中训练模型,这会在拟合开始前计算一次预处理并将结果缓存。
注意:即使在运行Jax或PyTorch后端时,我们也可以使用tf.data进行预处理。在训练过程中,输入数据集会自动转换为后端原生张量类型。事实上,鉴于tf.data在运行预处理方面的效率,在所有后端上这都是一个良好的做法。
import tensorflow as tf
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=512,
)
# Apply the preprocessor to every sample of train and test data using `map()`.
# [`tf.data.AUTOTUNE`](https://www.tensorflow.org/api_docs/python/tf/data/AUTOTUNE) and `prefetch()` are options to tune performance, see
# https://www.tensorflow.org/guide/data_performance for details.
# Note: only call `cache()` if you training data fits in CPU memory!
imdb_train_cached = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_cached = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_tiny_en_uncased", preprocessor=None, num_classes=2
)
classifier.fit(
imdb_train_cached,
validation_data=imdb_test_cached,
epochs=3,
经过三个训练周期后,我们的验证准确率仅提高到0.88。这既是因为我们的数据集较小,也是因为我们的模型。为了超过90%的准确率,可以尝试使用更大的预设,如"bert_base_en_uncased"。对于BertClassifier可用的所有主干预设,请查看我们的keras.io模型页面。
自定义预处理
在需要自定义预处理的情况下,我们提供了直接访问Tokenizer类的功能,该类将原始字符串映射为标记(tokens)。Tokenizer类还提供了一个from_preset()构造函数,用于获取与预训练相匹配的词汇表。
注意:BertTokenizer默认情况下不会填充序列,因此输出是参差不齐的(每个序列的长度不同)。下面的MultiSegmentPacker用于将这些参差不齐的序列填充为密集的张量类型(例如tf.Tensor或torch.Tensor)。
tokenizer = keras_nlp.models.BertTokenizer.from_preset("bert_tiny_en_uncased")
tokenizer(["I love modular workflows!", "Libraries over frameworks!"])
# Write your own packer or use one of our `Layers`
packer = keras_nlp.layers.MultiSegmentPacker(
start_value=tokenizer.cls_token_id,
end_value=tokenizer.sep_token_id,
# Note: This cannot be longer than the preset's `sequence_length`, and there
# is no check for a custom preprocessor!
sequence_length=64,
)
# This function that takes a text sample `x` and its
# corresponding label `y` as input and converts the
# text into a format suitable for input into a BERT model.
def preprocessor(x, y):
token_ids, segment_ids = packer(tokenizer(x))
x = {
"token_ids": token_ids,
"segment_ids": segment_ids,
"padding_mask": token_ids != 0,
}
return x, y
imdb_train_preprocessed = imdb_train.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
imdb_test_preprocessed = imdb_test.map(preprocessor, tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
# Preprocessed example
print(imdb_train_preprocessed.unbatch().take(1).get_single_element())
6、使用自定义模型进行微调
使用自定义模型进行微调(Fine tuning with a custom model)是指在深度学习或机器学习任务中,使用用户自定义的模型架构进行微调操作。微调通常是在一个预训练模型(如BERT、GPT等)的基础上进行,但也可以应用于任何自定义构建的模型。
微调意味着在已存在的模型权重基础上,针对特定的任务或数据集进行训练,以调整模型的参数,从而提高模型在目标任务上的性能。当使用自定义模型进行微调时,用户可以根据自己的需求和数据特性设计模型架构,并在预训练的基础上进一步训练模型,以适应特定的任务需求。
这种方法的优点在于可以利用预训练模型中的知识和特征,同时又能根据具体任务进行灵活调整,以实现更好的性能。然而,这也要求用户具有一定的深度学习知识和经验,以设计有效的模型架构和微调策略。
对于更高级的应用,可能没有一个合适的任务模型可用。在这种情况下,我们提供了直接访问基础模型(backbone Model)的接口,基础模型有自己的from_preset构造函数,并且可以与自定义层(Layers)组合使用。详细的示例可以在我们的迁移学习指南中找到。
基础模型不包括自动预处理,但可以与匹配的预处理器配对使用,如之前工作流程中所示,使用相同的预设。
在这个工作流程中,我们尝试冻结基础模型,并添加两个可训练的Transformer层以适应新的输入。
注意:我们可以忽略关于pooled_dense层的梯度警告,因为我们使用的是BERT的序列输出。这意味着我们可能并不直接对BERT模型中的pooled_dense层(通常是用于分类任务的池化层)进行训练,而是将输出传递给其他层进行进一步处理。在这种情况下,不需要计算该层的梯度。
preprocessor = keras_nlp.models.BertPreprocessor.from_preset("bert_tiny_en_uncased")
backbone = keras_nlp.models.BertBackbone.from_preset("bert_tiny_en_uncased")
imdb_train_preprocessed = (
imdb_train.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
imdb_test_preprocessed = (
imdb_test.map(preprocessor, tf.data.AUTOTUNE).cache().prefetch(tf.data.AUTOTUNE)
)
backbone.trainable = False
inputs = backbone.input
sequence = backbone(inputs)["sequence_output"]
for _ in range(2):
sequence = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=512,
dropout=0.1,
)(sequence)
# Use [CLS] token output to classify
outputs = keras.layers.Dense(2)(sequence[:, backbone.cls_token_index, :])
model = keras.Model(inputs, outputs)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.summary()
model.fit(
imdb_train_preprocessed,
validation_data=imdb_test_preprocessed,
epochs=3,
)
尽管这个模型只有我们BertClassifier模型可训练参数的10%,但它仍然达到了合理的准确率。每个训练步骤所花费的时间大约只有BertClassifier模型的1/3,即使考虑到缓存预处理的时间。
7、预训练基础模型(Pretraining a backbone model)
在深度学习和机器学习的上下文中,预训练基础模型通常指的是在一个大规模数据集上预先训练一个模型的部分或全部,以便在后续的特定任务或数据集上进行微调(fine-tuning)。基础模型通常指的是一个模型的主要组成部分,如卷积神经网络(CNN)中的特征提取层或Transformer模型中的编码器部分。
预训练基础模型的主要目的是利用在大规模数据集上学到的通用特征,这些特征可以捕获数据中的底层结构和模式。通过在后续的特定任务上进行微调,模型可以学习到针对该任务的特定特征,从而在不需要大量标注数据的情况下实现良好的性能。
预训练基础模型在迁移学习(transfer learning)和领域适应(domain adaptation)等场景中特别有用,因为它们可以帮助模型更快地适应新的任务和数据集,同时减少过拟合的风险。
您是否拥有与训练流行的基础模型(如BERT、RoBERTa或GPT2)所用数据集大小相近的、您所在领域的大规模无标签数据集?如果有,那么您可能会从针对自己基础模型的特定领域预训练中受益。
NLP模型通常会在语言建模任务上进行预训练,根据输入句子中的可见单词来预测被掩盖的单词。例如,给定输入“The fox [MASK] over the [MASK] dog”,模型可能会被要求预测出[“jumped”, “lazy”]。然后,该模型的较低层会被打包为基础模型,与新任务的层进行组合。
KerasNLP库提供了无需预设即可从头开始训练的SoTA基础模型和分词器(tokenizers)。
在这个工作流程中,我们使用IMDB评论文本预训练了一个BERT基础模型。我们跳过了“下一句预测”(NSP)损失,因为它给数据处理增加了显著的复杂性,并且像RoBERTa这样的后续模型已经弃用了它。有关如何复制原始论文的详细步骤,请参阅我们的端到端Transformer预训练。
具体来说,BERT(Bidirectional Encoder Representations from Transformers)是一个基于Transformer的预训练语言表示模型,它包含两个主要的预训练任务:Masked Language Modeling(MLM)和Next Sentence Prediction(NSP)。其中,MLM是通过在输入语句中随机选择一些单词并将它们替换成掩码(如[MASK]),然后让模型预测这些掩码的正确词语来训练模型对上下文的理解能力。而NSP则是通过随机选择两个句子A和B,并将它们组合成一个输入序列,然后让模型判断B是否是A的下一句来训练模型对句子间关系的理解能力。然而,后续的研究(RoBERTa)发现,NSP任务对于模型性能的提升并不明显,因此在预训练过程中可以省略。
在预训练BERT或类似模型时,通常需要使用大量的无标签语料库,这些语料库可以包含数十亿甚至更多的单词。预训练完成后,模型可以在特定的NLP任务上进行微调,以适应不同的应用场景。
关于KerasNLP库,它提供了许多用于自然语言处理的先进模型和工具,包括用于构建和训练模型的API、用于处理文本数据的分词器和嵌入层等。这些工具可以帮助研究人员和开发人员更轻松地构建和训练NLP模型。
# All BERT `en` models have the same vocabulary, so reuse preprocessor from
# "bert_tiny_en_uncased"
preprocessor = keras_nlp.models.BertPreprocessor.from_preset(
"bert_tiny_en_uncased",
sequence_length=256,
)
packer = preprocessor.packer
tokenizer = preprocessor.tokenizer
# keras.Layer to replace some input tokens with the "[MASK]" token
masker = keras_nlp.layers.MaskedLMMaskGenerator(
vocabulary_size=tokenizer.vocabulary_size(),
mask_selection_rate=0.25,
mask_selection_length=64,
mask_token_id=tokenizer.token_to_id("[MASK]"),
unselectable_token_ids=[
tokenizer.token_to_id(x) for x in ["[CLS]", "[PAD]", "[SEP]"]
],
)
def preprocess(inputs, label):
inputs = preprocessor(inputs)
masked_inputs = masker(inputs["token_ids"])
# Split the masking layer outputs into a (features, labels, and weights)
# tuple that we can use with keras.Model.fit().
features = {
"token_ids": masked_inputs["token_ids"],
"segment_ids": inputs["segment_ids"],
"padding_mask": inputs["padding_mask"],
"mask_positions": masked_inputs["mask_positions"],
}
labels = masked_inputs["mask_ids"]
weights = masked_inputs["mask_weights"]
return features, labels, weights
pretrain_ds = imdb_train.map(preprocess, num_parallel_calls=tf.data.AUTOTUNE).prefetch(
tf.data.AUTOTUNE
)
pretrain_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
# Tokens with ID 103 are "masked"
print(pretrain_ds.unbatch().take(1).get_single_element())
预训练模型
# BERT backbone
backbone = keras_nlp.models.BertBackbone(
vocabulary_size=tokenizer.vocabulary_size(),
num_layers=2,
num_heads=2,
hidden_dim=128,
intermediate_dim=512,
)
# Language modeling head
mlm_head = keras_nlp.layers.MaskedLMHead(
token_embedding=backbone.token_embedding,
)
inputs = {
"token_ids": keras.Input(shape=(None,), dtype=tf.int32, name="token_ids"),
"segment_ids": keras.Input(shape=(None,), dtype=tf.int32, name="segment_ids"),
"padding_mask": keras.Input(shape=(None,), dtype=tf.int32, name="padding_mask"),
"mask_positions": keras.Input(shape=(None,), dtype=tf.int32, name="mask_positions"),
}
# Encoded token sequence
sequence = backbone(inputs)["sequence_output"]
# Predict an output word for each masked input token.
# We use the input token embedding to project from our encoded vectors to
# vocabulary logits, which has been shown to improve training efficiency.
outputs = mlm_head(sequence, mask_positions=inputs["mask_positions"])
# Define and compile our pretraining model.
pretraining_model = keras.Model(inputs, outputs)
pretraining_model.summary()
pretraining_model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(learning_rate=5e-4),
weighted_metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
# Pretrain on IMDB dataset
pretraining_model.fit(
pretrain_ds,
validation_data=pretrain_val_ds,
epochs=3, # Increase to 6 for higher accuracy
)
8、从零开始构建和训练自己的Transformer模型
从IMDB数据构建和训练你自己的Transformer
想要实现一个新颖的Transformer架构吗?KerasNLP库提供了用于构建我们模型API中SoTA(State-of-the-Art)架构的所有底层模块。这包括keras_nlp.tokenizers API,它允许你使用WordPieceTokenizer、BytePairTokenizer或SentencePieceTokenizer来训练你自己的子词分词器。
在这个工作流程中,我们将在IMDB数据上训练一个自定义的分词器,并设计一个具有自定义Transformer架构的基础模型。为了简化,我们将直接在分类任务上进行训练。对更多细节感兴趣吗?我们在keras.io上撰写了关于预训练和微调自定义Transformer的完整指南。
从IMDB数据训练自定义词汇
这意味着你将从IMDB的电影评论数据集中提取文本,并使用上述提到的分词器之一(如WordPieceTokenizer)来训练一个自定义的词汇表。这个词汇表将用于将原始文本转换为模型可以理解的数字序列,这是处理自然语言数据的重要步骤。一旦你有了自定义的分词器和词汇表,你就可以开始构建你的Transformer模型了。
vocab = keras_nlp.tokenizers.compute_word_piece_vocabulary(
imdb_train.map(lambda x, y: x),
vocabulary_size=20_000,
lowercase=True,
strip_accents=True,
reserved_tokens=["[PAD]", "[START]", "[END]", "[MASK]", "[UNK]"],
)
tokenizer = keras_nlp.tokenizers.WordPieceTokenizer(
vocabulary=vocab,
lowercase=True,
strip_accents=True,
oov_token="[UNK]",
)
使用自定义分词器预处理数据
这个步骤涉及使用你之前训练或定义的自定义分词器来将原始文本数据转换为模型可以理解的格式。分词器会将文本拆分为较小的单元(如单词、子词或字符),并为每个单元分配一个唯一的标识符(如ID或索引)。这样,模型就可以接收这些标识符序列作为输入,并输出对应的预测或结果。
在预处理阶段,除了分词之外,还可能包括其他步骤,如文本清洗(去除HTML标签、特殊字符、停用词等)、大小写转换、文本截断或填充等,以确保数据格式符合模型的要求。
使用自定义分词器进行预处理可以提高模型在特定任务上的性能,因为分词器可以根据你的数据和任务进行定制和优化。
packer = keras_nlp.layers.StartEndPacker(
start_value=tokenizer.token_to_id("[START]"),
end_value=tokenizer.token_to_id("[END]"),
pad_value=tokenizer.token_to_id("[PAD]"),
sequence_length=512,
)
def preprocess(x, y):
token_ids = packer(tokenizer(x))
return token_ids, y
imdb_preproc_train_ds = imdb_train.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
imdb_preproc_val_ds = imdb_test.map(
preprocess, num_parallel_calls=tf.data.AUTOTUNE
).prefetch(tf.data.AUTOTUNE)
print(imdb_preproc_train_ds.unbatch().take(1).get_single_element())
设计一个微型Transformer
在设计一个微型Transformer时,我们旨在创建一个结构简洁但功能强大的模型,以便在资源受限的环境中(如移动设备或边缘设备)进行有效部署。以下是设计微型Transformer的一些关键考虑因素:
- 模型深度与宽度:微型Transformer通常具有较浅的层数和较窄的隐藏层维度,以减少参数量和计算复杂度。可以通过调整编码器和解码器堆叠的层数、隐藏层的大小以及自注意力机制中的头数来平衡模型的表达能力和计算资源需求。
- 自注意力机制:自注意力机制是Transformer模型的核心组件之一,它允许模型捕获输入序列中的依赖关系。在微型Transformer中,可以考虑使用简化的自注意力机制,如局部自注意力(local self-attention)或基于相对位置的自注意力(relative position-based self-attention),以减少计算量和内存占用。
- 位置编码:由于Transformer模型是基于自注意力的,它无法直接捕获输入序列中的位置信息。因此,需要通过位置编码(positional encoding)将位置信息注入到模型中。在微型Transformer中,可以使用简化的位置编码方法,如绝对位置编码或正弦/余弦位置编码的简化版本。
- 前馈网络:Transformer模型中的前馈网络(feed-forward network)用于增强模型的非线性表示能力。在微型Transformer中,可以通过减少前馈网络的层数、隐藏层维度和激活函数的选择来简化其结构。
- 轻量级优化:为了进一步提高微型Transformer的效率和性能,可以采用一些轻量级优化技术,如剪枝(pruning)、量化(quantization)和蒸馏(distillation)。这些技术可以帮助减少模型的参数量和计算复杂度,同时保持较好的性能。
通过综合考虑以上因素,可以设计出一个既具有强大表达能力又能在资源受限环境中高效运行的微型Transformer模型。这样的模型可以广泛应用于各种自然语言处理任务,如文本分类、机器翻译和问答系统等。
token_id_input = keras.Input(
shape=(None,),
dtype="int32",
name="token_ids",
)
outputs = keras_nlp.layers.TokenAndPositionEmbedding(
vocabulary_size=len(vocab),
sequence_length=packer.sequence_length,
embedding_dim=64,
)(token_id_input)
outputs = keras_nlp.layers.TransformerEncoder(
num_heads=2,
intermediate_dim=128,
dropout=0.1,
)(outputs)
# Use "[START]" token to classify
outputs = keras.layers.Dense(2)(outputs[:, 0, :])
model = keras.Model(
inputs=token_id_input,
outputs=outputs,
)
model.summary()
直接在分类目标上训练Transformer
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.AdamW(5e-5),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
jit_compile=True,
)
model.fit(
imdb_preproc_train_ds,
validation_data=imdb_preproc_val_ds,
epochs=3,
)