文章目录
- 前言
- 什么是分布式系统
- 主从模式
- 实现Redis主从模式
- 主从模式原理
- nagle 算法
- 拓扑结构
- 主从模式实现的过程
- psync
- 实时复制
前言
Redis 作为在内存中操作数据的服务器系统,每时都会接收成千上万的请求,如果我们的业务只在单个服务器上面部署了 Redis,那么这个 Redis 服务器很可能会因为过多的业务处理而导致服务器挂掉,而这个单独的 Redis 服务器如果挂掉的话,那么所有关于 Redis 修改和查询的操作都无法正常进行。所以为了解决这个问题,我们引入了分布式系统这个概念。
什么是分布式系统
分布式系统由一组独立的计算机组成,这些计算机在地域上可能分散在世界各地,但通过网络连接形成一个统一的系统。这个系统具有多种通用的物理和逻辑资源,并能动态地分配任务。分散的物理和逻辑资源通过计算机网络实现信息交换。
分布式系统的主要特点:
- 分布性:整个系统的功能分散到各个计算机(节点)上实现,因此具有数据处理的分布性。
- 自治性:系统中的各个节点都包含自己的处理器与内存,地位上彼此平等,无主次之分,既能自治工作,也能通过网络来共享信息,协调处理任务。
- 并行性:一个大的任务可以分成若干个小任务,分发到不同的主机上运行。
- 全局性:系统中必须存在一个单一的、全局的进程通信机制,使得任意一个进程都能与其他进程相互通信,并且不区分本地通信与远程通信。
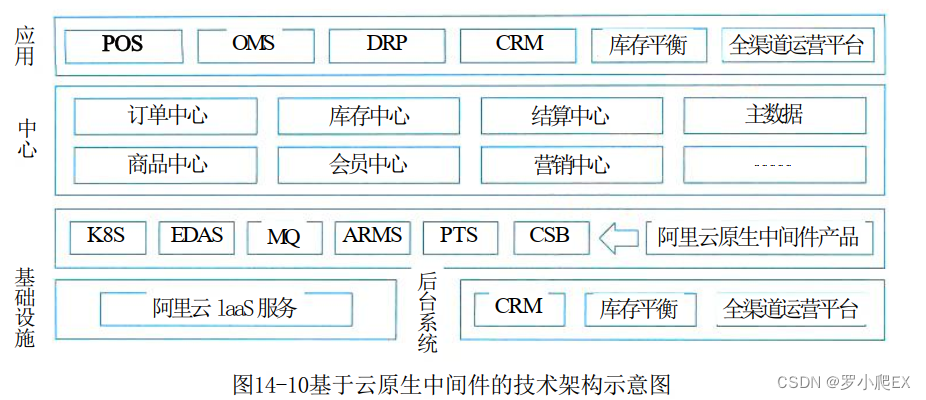
Redis 实现分布式主要有三种方式:主从模式、主从模式+哨兵模式和集群模式。这篇文章主要介绍主从模式。
主从模式
Redis 主从模式是在众多个 Redis 节点中,既有主节点又有从节点,主节点可以进行写操作也可以进行读操作,而从节点则只能进行读操作。当主节点中的数据修改了之后,从节点中的数据也会跟着变化,保持与主节点的数据一致。
当用户进行写操作的时候,这个操作只会在主节点中进行,然后将修改之后的数据同步到从节点中,而用户进行读操作的时候,则可以在主节点和从节点中的任何一个节点中进行,这样就使得每个 Redis 服务器的读操作的压力大大降低了。虽然写操作还是在一台服务器上的,但是 Redis 操作最多的还是读操作,相较于服务器承受的读操作的压力,写操作的压力还是可以承受的。
如果 Redis 从节点的服务器挂掉了,影响不大,因为其他的从节点和主节点还可以进行读操作,只是说服务器的压力可能大一点,而如果 Redis 主节点的服务器挂掉了,那么影响还是比较大的,因为只有主节点才可以进行写操作,主节点挂掉了就意味着无法修改数据了,但是暂时的读操作还是可以的,这个主节点挂掉的情况是有解决方式的,后面再为大家介绍。

实现Redis主从模式
按理来说,配置 Redis 主从模式应该是每个 Redis 节点在不同的主机上的,但是因为我这里资源有限,所以就在一个主机上为大家模拟出多个 Redis 节点的 Redis 主从模式的情况。
那么在一个主机上如何实现多个 Redis 节点的情况呢?Redis 服务器默认使用的端口号是 6379,我们只需要再添加几个除 6379 之外的其他端口作为 Redis 服务器使用的端口号就可以了。而修改 Redis 启动的端口号就需要在 Redis 的配置文件中进行配置:
首先我们需要将三个 redis 服务器的工作目录进行区分,防止工作目录重复而导致的 RDB 文件或者 AOF 文件重复,再而导致某一个 Redis 服务器无法正常启动。
首先准备三个配置文件来作为三个 Redis 服务器启动的配置文件:
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# cp redis1.conf redis2.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# cp redis1.conf redis3.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# ll
total 344
drwxrws--- 2 redis redis 4096 May 1 16:49 ./
drwxr-xr-x 118 root root 4096 Apr 27 06:31 ../
-rw-r----- 1 root redis 85843 May 1 16:48 redis1.conf
-rw-r----- 1 root redis 85843 May 1 16:49 redis2.conf
-rw-r----- 1 root redis 85843 May 1 16:49 redis3.conf
-rw-r----- 1 root redis 85846 May 1 16:47 redis.conf
修改配置文件中的使用端口号,这里主节点默认使用 6379 端口号:
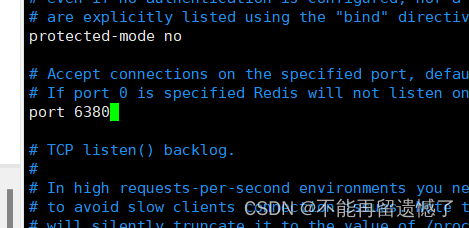
当修改完端口号之后还需要 daemonize 配置,按照后台进程的方式来运行:


然后启动 Redis 服务的时候通过执行配置文件 redis-server 配置文件路径 的方式来启动:
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# service redis-server stop
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# ps aux | grep redis
root 513119 0.0 0.1 6480 2416 pts/0 S+ 17:04 0:00 grep --color=auto redis
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis1.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis2.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis3.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# ps aux | grep redis
root 513138 0.0 0.3 67212 5980 ? Ssl 17:05 0:00 redis-server 0.0.0.0:6379
root 513144 0.1 0.3 67212 5824 ? Ssl 17:05 0:00 redis-server 0.0.0.0:6380
root 513150 0.0 0.3 67212 5952 ? Ssl 17:05 0:00 redis-server 0.0.0.0:6381
root 513156 0.0 0.1 6480 2320 pts/0 S+ 17:05 0:00 grep --color=auto redis
这就说明有三个 Redis 服务启动了,然后我们通过 redis-cli -p 端口号 来进入 Redis 客户端:
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-cli -p 6379
127.0.0.1:6379>
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-cli -p 6380
127.0.0.1:6380>
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-cli -p 6381
127.0.0.1:6381>
当修改完上面配置之后,只是保证了在一个主机上可以启动多个 Redis
服务器,要想这几个 Redis 服务器构成主从关系,有三种方式可以实现:
- 在配置项中添加
slaveof {masterHost} {masterPort}随Redis启动生效 - 在 redis-server 启动命令时加入
--slaveof {masterHost} {masterPort}生效 - 进入 Redis 客户端之后,使用
slaveof {masterHost} {masterPort}命令生效
这里只为大家演示第一种。第一种配置方式,这个主从关系只要配置文件中不修改,redis 服务启动的时候就会自动配置主从关系,而二三种则是临时的,每次启动的时候都需要指定。
主节点是不用修改的,只需要让从节点知道它的从节点是谁就可以了。
在从节点的配置文件中添加下面的配置项:
slaveof 127.0.0.1 6379
这样就构成了:6379 的 Redis 节点为主节点,而 6380 和 6381 Redis 节点为 6379 节点的从节点了。
然后我们需要重新启动 Redis 服务:
这里关闭 Redis 服务也是有讲究的。如果我们前面用的是 redis-server start 启动的 Redis 服务,那么就需要使用 kill -9 进程ID 来关闭服务;如果前面使用的是 service redis-server start 启动的 Redis 服务,则需要使用 service redis-server stop 来关闭服务。如果这时我们使用 kill 命令来关闭进程的话,redis 服务会自动启动。
前面我们使用的是 redis-server 配置文件路径 启动的,所以需要使用 kill 命令来关闭服务:
当关闭服务之后,我们重新启动 redis 服务:
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis1.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis2.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# redis-server redis3.conf
root@iZ2ze5bzkbeuwwqowjzo27Z:/etc/redis# ps aux | grep redis
root 513280 0.0 0.3 69772 6576 ? Ssl 17:27 0:00 redis-server 0.0.0.0:6379
root 513286 0.1 0.3 80016 6636 ? Ssl 17:27 0:00 redis-server 0.0.0.0:6380
root 513294 0.0 0.3 67212 5872 ? Ssl 17:27 0:00 redis-server 0.0.0.0:6381
root 513300 0.0 0.1 6480 2332 pts/0 S+ 17:27 0:00 grep --color=auto redis
进入各个 Redis 客户端:

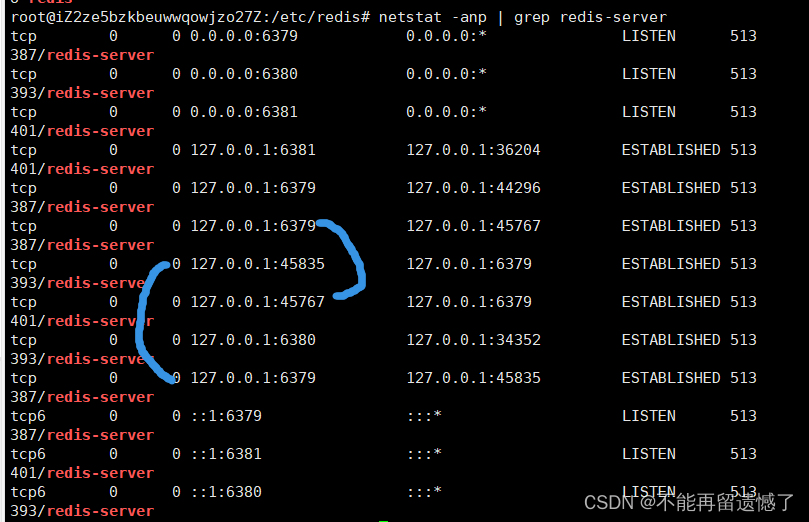
当配置文件中指定主从关系之后,对应的 redis 服务启动的时候,主节点和对应的从节点之间就会建立 tcp 长连接:
然后我们尝试在主节点中修改和查询数据:

可以看到主节点中可以修改和查询数据,然后再看从节点:
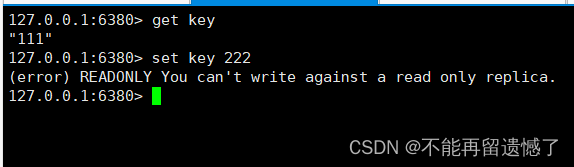
当在主节点进行写操作的时候,会将修改之后的数据同步到从节点中,从节点中可以进行读操作,而不允许进行写操作。
然后我们可以在 redis 客户端中使用 info replication 来查看主从关系相关的信息:
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=1563,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=1563,lag=1
master_replid:89b3e379796165cc3064cfa0d6057200a8f2da06
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1563
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1563
- role:指明当前节点是主节点(master)还是从节点(slave)
- connected_slaves:如果当前节点是主节点的话,该选项表示主节点有多少个从节点
- slaven:第n个从节点的信息。包括ip、port、状态(state)、相对于主节点中数据的偏移量(offset)和延迟(lag)单位可以是秒、字节数和命令数等
- master_replid:这是主节点的复制ID,用于在从节点中唯一标识主节点。在故障转移时,这个ID对于从节点找到新的主节点非常重要。
- master_replid2:这是一个旧的复制ID,通常用于故障转移后的日志追踪。当主节点切换时,master_replid会更新为新的主节点的ID,而master_replid2会保存旧的ID。
- master_repl_offset:这是主节点当前的复制偏移量,表示主节点已经写入的数据量(以字节为单位)。
- second_repl_offset:这通常与Redis集群中的从从复制(replication of replication)有关,-1表示未启用。
- repl_backlog_active:这是一个标志,表示复制backlog(用于部分重同步)是否正在被使用。
- repl_backlog_size:这是复制backlog的大小(以字节为单位)。backlog用于在从节点与主节点之间的连接短暂断开时,支持从节点重新同步而不需要进行全量同步。
- repl_backlog_first_byte_offset 和 repl_backlog_histlen:这两个值提供了关于复制backlog中数据的详细信息。first_byte_offset是backlog中第一个字节的偏移量,而histlen是backlog中当前存储的数据的长度。
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:1787
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:89b3e379796165cc3064cfa0d6057200a8f2da06
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1787
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1787
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:1815
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:89b3e379796165cc3064cfa0d6057200a8f2da06
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1815
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1815
- role:slave:表示当前Redis实例是从节点。
- master_host 和 master_port:表示从节点正在连接到哪个主节点的IP地址和端口号。
- master_link_status:up:表示从节点与主节点的连接状态是活动的(up)。
- master_last_io_seconds_ago:2:表示从节点最后一次与主节点进行I/O操作的时间(以秒为单位)。这里的2秒表示最近的一次I/O操作发生在2秒前。
- master_sync_in_progress:0:表示当前没有正在进行的全量同步操作。
- slave_repl_offset:1787:从节点复制主节点的数据的当前偏移量,以字节为单位。
- slave_priority:100:从节点的优先级,用于在Redis Sentinel配置中自动故障转移时选择新的主节点。值越高,优先级越高。
- slave_read_only:1:表示从节点是只读的。这是从节点的默认设置,以确保数据一致性。0表示当前从节点可以进行写操作。
- connected_slaves:0:表示当前从节点没有连接其他从节点(即它不是任何从节点的主节点)。
- master_replid 和 master_replid2:与主节点的复制ID相关的字段。
- master_repl_offset:主节点当前的复制偏移量,以字节为单位。
- second_repl_offset:与从从复制(replication of replication)相关的字段,但在此场景中为-1,表示没有启用从从复制。
- repl_backlog_active、repl_backlog_size、repl_backlog_first_byte_offset 和 repl_backlog_histlen:这些字段与复制backlog有关,用于在从节点与主节点之间的连接短暂断开时支持部分重同步。
slave no one 是一个可以直接在从节点的 redis 客户端使用的命令。这个命令用来断开当前的主从复制关系。当从节点断开和主节点之间的关系之后,这个从节点就不属于其他节点了,并且当前节点已经存在的数据还会保留不会丢弃,只是后续主节点中的数据再修改的话,该节点中的数据就不会发生修改了。slave no one 命令只是临时性的,下次再启动 redis 服务的时候,还是会根据配置文件中的关系进行初始化。

如果我将上面的主从关系改为了:

就表示 6380 节点既是 6379 的从节点,又是 6381 的主节点。但是实际上 6380 节点还是从节点,它只是作为 6381 同步数据的来源,6380 节点还是不能进行写数据操作的。
主从模式原理
nagle 算法
主从模式中,主节点和从节点之间通过网络进行传输(tcp),在这个过程中运用了 nagle 算法。
nagle 算法主要用于预防小分组的产生,进而减少网络拥塞。在网络通信中,小分组(即较小的数据包)可能会频繁地发送,每个小分组都需要占据网络带宽和路由器缓存空间,并且由于TCP要求每个小分组发送之前都需要进行确认,这会导致消息数量增多,确认消息的数量也随之增加,从而可能导致网络延迟和吞吐量下降。
换句话说,nagle 算法节省了网络带宽,但是增加了网络延迟,目的和 tcp 捎带应答的目的是相同的。

拓扑结构
主从模式的拓扑结构主要分为三种:
一个主节点只有一个从节点:
一个主节点有多个从节点:

对于上面这样的结构,只有一个主节点的情况,这种情况下,如果写操作太多的话,是会对主节点造成压力的,但是也可以通过关闭主节点的 AOF 机制,只在从节点上开启 AOF 机制来减少主节点的写操作压力。但是这样又会出现问题,就是如果主节点挂掉之后,因为没有开启持久化操作,所以重新启动主节点服务的时候,主节点中的数据就是空数据,而从节点又会同步主节点的数据,所以也就导致所有节点上的数据都丢失了,所以需要避免主节点挂掉之后自动重启的发生,而是将主节点上的数据从从节点上恢复了之后再手动重启。
对于一个主节点多个从节点的结构来说,虽然降低了每个节点读数据的压力,但是对于主节点来说,每次修改数据都需要将改变的数据同步给多个从节点。
从节点也可以是主节点:
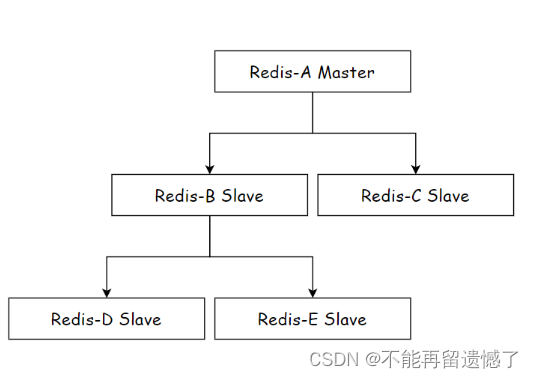
对于这种结构,偏下面的节点要想同步数据的话,中间就需要经过多个节点,也就意味了整个节点的同步差异会变大。
主从模式实现的过程

当在从节点的配置文件中配置主节点的信息或者使用命令指定主从关系之后,在从节点中首先会保存主节点的 ip 和 port 信息,然后根据这个信息与主节点之间建立 tcp 连接(三次握手),通过三次握手来验证双方之间是否能够正常的读写数据,然后从节点会向主节点发送 ping 命令用于确定主节点是否能够正常工作,再然后就是需要权限验证,当然这个步骤是针对 redis 服务器设置了密码的情况,我既然需要访问你内存中的数据,肯定是需要知道你的密码的,如果主节点设置了密码,需要在从节点的配置文件中配置 masterauth <master-password>,当完成上面的操作之后,从节点就会首先将主节点中的全部数据都进行同步,也就相当于初始化,当进行完初始化之后,后面主节点中的数据再发生变化,也就会将变化的数据同步到从节点中。
psync
reddis 提供了 psync 命令用来完成主从节点之间的数据同步,当我们在从节点上使用 psync 命令之后,从节点就会开始从主节点中同步数据,但是这个命令是不需要我们手动执行的,redis 在建立好主从同步关系之后,自动执行 psync 命令。

replicationid 是主节点生成的,从节点晋升为主节点也会生成一个 replicationid,每次主节点启动的时候都会生成一个 replicationid,这样就会导致同一个主节点启动之后生成的 replicationid 都是不同的。当从节点和主节点之间建立了主从关系之后,从节点中就会保存主节点生成的 replicationid 信息。
master_replid:89b3e379796165cc3064cfa0d6057200a8f2da06
master_replid2:0000000000000000000000000000000000000000
这个 replicationid 往往会保存两个,但是 replid2 通常用不到,只有当从节点和主节点之间的网络传输存在抖动的时候,从节点会认为主节点已经挂了,那么这个从节点就会晋升为主节点并且生成一个 replicationid,保存在 master_replid 中,但是之前保存的主节点生成的 replication 不会丢弃,而是会保存在 replid2 中用于后面主节点稳定了之后,从节点再次和主节点建立主从关系。
offset 是指数据的偏移量,在主节点和从节点中都会维护这个偏移量。
在主节点中,主节点会收到很多的修改操作的命令,每个命令会占用几个字节,主节点会将这些命令按照字节的个数进行累加,然后通过这个偏移量来快速定位到指定命令。而从节点中的偏移量则用来表明我这个从节点同步数据到哪了。
通过 replicationid 和 offset 就共同描述了一个数据集合,如果两个机器上的 replicationid 和 offset 是相同的,那么就可以认为这两个机器上面的数据也是一致的。
使用 psync 可以获取全量数据也可以获取部分数据。当 offset 为 -1 的时候就表示获取全量数据,而 offset 为正整数的时候,就表示获取从 offset 开始的部分数据。

FULLRESYNC 表示全量数据同步,CONTINFU 表示增量数据同步,ERR 表示当前版本不支持 SYNC 操作。
当从节点首次和主节点进行数据同步的时候以及主节点不方便进行部分同步的时候会进行全量复制,首次数据同步很好理解,不方便部分同步是怎么回事呢?后面为大家介绍。
获取全量数据我们可以理解,但是获取部分数据是怎么回事呢?什么情况下会使用到同步部分数据呢?
当从节点已经从主节点上同步了一些数据,但是因为网络抖动获取其他问题发生了重启时,从节点就需要重新从主节点上同步数据,但是由于从节点已经存在的数据和主节点前部分的数据是高度一样的,所以就没必要将前面重复的数据再同步一遍,而是从后面那部分同步。
全量复制的过程:

1)从节点发送psync命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的运行 ID 和复制偏移量,所以发送psync?-1。
2)主节点根据命令,解析出要进行全量复制,回复+FULLRESYNC响应.
3)从节点接收主节点的运行信息进行保存。
4)主节点执行 bgsave 进行 RDB 文件的持久化。
5)主节点发送 RDB 文件给从节点,从节点保存 RDB 数据到本地硬盘
6)主节点将从生成 RDB 到接收完成期间执行的写命令,写入缓冲区中,等从节点保存完 RDB 文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然技照 rdb 的二进制格式追加写入到收到的 rdb 文件中、保持主从一致性。
7)从节点清空自身原有旧数据。
8)从节点加载RDB文件得到与主节点一致的数据。
9)如果从节点加载RDB完成之后,并且开启了 AOF 持久化功能,它会进行 bgrewrite 操作,得到最近的 AOF 文件。
当进行全量复制的时候,主节点会将内存中的数据通过 RDB 持久化操作生成一个 RDB 文件,如果需要多次全量复制的话,就需要多次 I/O 操作,这样速度就会很慢了,为了解决这个问题,出现了 “无硬盘模式”,主节点同步出来的数据不会存储在硬盘上,而是会先将数据存储在内存中,然后打包直接通过网络传输给从节点,这样就减少了硬盘的 I/O 操作。虽然这样,但是网络传输才是最花费时间的,所以提升并不大。
这里运行时 ID (runId)和 replicationId 不要混了,replicationId 是主节点在每次启动的时候都会生成的用于唯一标识主节点的标志,而 runId 则是每个节点启动时都会生成的唯一标识,每一个节点的 runId 都不相同。
部分复制的过程:

1)当主从节点之间出现网络中断时,如果超过 repltimeout 时间,主节点会认为从节点故障井终端复制连接。
2)主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中。
3)当主从节点网络恢复后,从节点再次连上主节点。
4)从节点将之前保存的 replcationld 和复制偏移量作为 psync 的参数发送给主节点,请求进行部分复制。
5)主节点接到 psync 请求后,进行必要的验证。随后根据 offset 去复制积压缓冲区查找合适的数据,并响应+CONTINUE给从节点
6)主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
当从节点重连之后,主节点如何判断这个从节点它之前连接的从节点呢?其实就是靠的从节点中存储的主节点的 replicationId,如果从节点重连之后传递过来的 replicationId 和主节点的 replicationId 相同的话,就可以根据从节点的复制偏移量来决定是否进行部分复制,而如果 replicationId 不同的话,就直接进行全量复制。
如果重连之后,从节点保存的复制偏移量 offset 超出了主节点复制挤压缓冲区当中的数据的范围的时候,就只能进行全量复制了,这也是上面全量复制的情况发生的原因。
实时复制
当从节点和主节点之间完成全量复制之后,也就是建立好连接并且从节点同步了主节点的数据之后,主节点还是会接收客户端发送的修改数据的请求,那么这时候主节点需要将修改之后的数据也同步给从节点,这个过程就叫做实时复制。
这个实时复制依靠的就是前面从节点和主节点建立的 tcp 长连接,而这个 tcp 长连接是否正常,则需要依靠心跳包机制。
主节点默认每隔 10s 给从节点发送一个 ping 命令,从节点如果正常存在则会返回 pong,而从节点则是每隔 1s 就会给主节点发送一个特定的请求,也就是上报当前从节点复制数据的进度,如果从节点的复制数据的进度相同的话,也就代表着主节点没有修改操作,也就不需要增量复制,如果从节点发送的复制数据的进度和主节点不同的话,就需要进行增量复制,所以从节点每隔一段时间发送的特殊的数据有很多的用处。
但是主从模式的话,如果进行写操作的主节点挂掉了之后还是会有很大的问题的,所以后面会再为大家介绍其他的模式。