一、安装anaconda(阿里云镜像库)
pip config list -v#pip在哪里寻找pip.conf文件
阿里云镜像:
1、安装完成,命令行输入:conda config生成.condarc文件(运行期配置文件)
2、如果原本的源中的源地址是 https,可以直接改成http即可。这个方法可以特别注意,因为https有时候会出现连接错误的问题,改成http后不会再出现此类问题
参考链接:https://blog.csdn.net/weixin_51484460/article/details/122179000
3、conda包管理器
conda env list#查找包文件目录
conda install <package>#安装需要的包
conda -V#版本
conda create --name <new_env_environment> --clone <copied_env_environment>#复制环境并创建新的环境
二、anaconda的编辑和xlwings操作
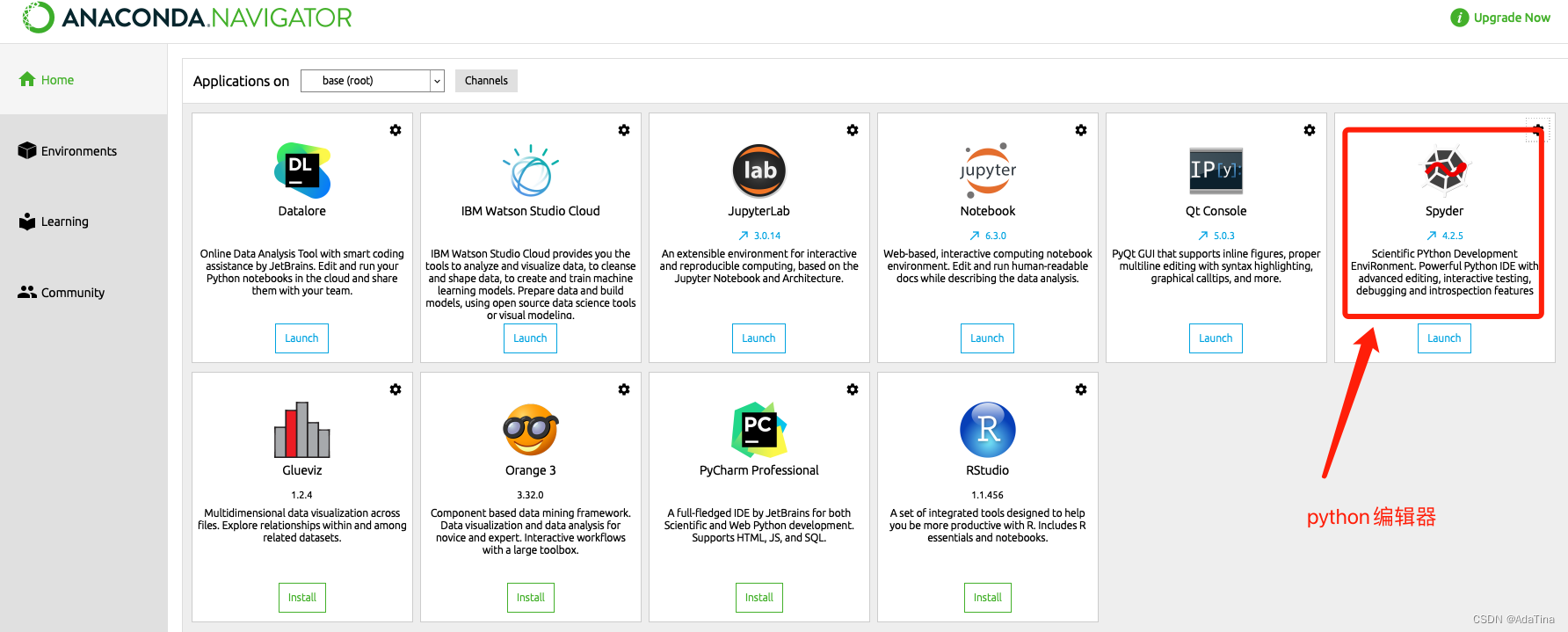 1、创建20个excel
1、创建20个excel
"""
编程os:mac
"""
import xlwings as xw
app=xw.App(visible=True,add_book=False)
for i in range(1,21):
workbook=app.books.add()
workbook.save(f'/Users/Tina/Desktop/20220607/分公司{i}.xlsx')
workbook.close()
app.quit()2、打开一个已存在的xlsx表,并在第一个单元格添加内容,并添加一个工作表
import xlwings as xw
app=xw.App(visible=True,add_book=False)
workbook=app.books.open('/Users/Tina/Desktop/20220607/分公司1.xlsx')
#指定的工作簿必须真实存在,并且不能处于已打开的状态
worksheet=workbook.sheets['Sheet1']
worksheet.range('A1').value="编号"
workbook.sheets.add('产品统计表')三、数组计算的数学模块——NumPy(前闭后开)
NumPy模块(Numerical Python缩写)一个运算速度非常快的数学模块
import numpy as np
a=[1,2,3,4]
b=np.array([1,2,3,4])
print(type(a),a)
print(type(b),b)
"""
运行结果:<class 'list'> [1, 2, 3, 4]
<class 'numpy.ndarray'> [1 2 3 4]
"""1、数组能够很好的支持一些数学运算
import numpy as np
a=[1,2,3,4]
b=np.array([1,2,3,4])
print(a*2)
print(b*2)
"""
运算结果:
[1, 2, 3, 4, 1, 2, 3, 4]
[2 4 6 8]
"""2、数组可以存储多维数据,而列表通常只能存储一维数据
import numpy as np
a=[[1,2],[3,4],[5,6]]
b=np.array([[1,2],[3,4],[5,6]])
print(a)
print(b)
"""
执行结果:
[[1, 2], [3, 4], [5, 6]]
[[1 2]
[3 4]
[5 6]]
"""3、创建一维数组
import numpy as np
#一位默认是终止值
a=np.arange(5)
#步长默认为1
b=np.arange(5,10)
#起点5,终点值10,步长2
c=np.arange(5,10,2)
print(a)
print(b)
print(c)
"""
输出结果:
[0 1 2 3 4]
[5 6 7 8 9]
[5 7 9]
"""4、创建一个一维数组,其中包含服从正态分布(均值为0、标准差为1的分布)的三个随机数
import numpy as np
a=np.random.randn(3)
print(a)
"""
执行结果:
[ 0.31614956 0.87779118 -0.78618781]
"""5、创建二维数组
import numpy as np
#创建一个一维数组,然后转化成3行4列的二位数组
a=np.arange(12).reshape(3,4)
print(a)
"""
运行结果:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
"""
####创建随机二维数组####
import numpy as np
#第一个起始值,第二个终止值,4行,4列
a=np.random.randint(0,10,(4,4))
print(a)
"""
运行结果:
[[1 1 3 4]
[5 7 6 3]
[0 1 9 8]
[2 4 7 7]]
"""四、数据导入和整理模块——pandas
1、pandas数据
import pandas as pd
a=pd.Series(['张三','李四','王五'])
print(a)
"""
运行结果:
0 张三
1 李四
2 王五
dtype: object
"""2、二维数据表格DataFrame
#####################列表创建DataFrame###################
import pandas as pd
a=pd.DataFrame([[1,2],[3,4],[5,6]])
print(a)
"""
运行结果:
0 1
0 1 2
1 3 4
2 5 6
结论:该数据结构存在行和列索引
"""
###############创建类似excel的行列结构#######################
import pandas as pd
a=pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
print(a)
"""
运行结果:
date score
A 1 2
B 3 4
C 5 6
"""
#######################另一种创建方式#########################
import pandas as pd
a=pd.DataFrame()
date=[1,3,5]
score=[2,4,6]
a['date']=date
a['score']=score
print(a)
"""
运行结果:
date score
0 1 2
1 3 4
2 5 6
"""
######################通过字典创建DataFrame###################
import pandas as pd
a=pd.DataFrame({'a':[1,3,5],'b':[2,4,6]},index=['x','y','z'])
print(a)
"""
打印结果:
a b
x 1 2
y 3 4
z 5 6
"""
###############以字典的键名作为行索引#####################
import pandas as pd
a=pd.DataFrame.from_dict({'a':[1,3,5],'b':[2,4,6]},orient='index')
print(a)
"""
打印结果:
0 1 2
a 1 3 5
b 2 4 6
"""
################通过二维数组创建DateFrame########################
import pandas as pd
import numpy as np
a=np.arange(12).reshape(3,4)
b=pd.DataFrame(a,index=[1,2,3],columns=['A','B','C','D'])
print(b)
"""
打印结果:
A B C D
1 0 1 2 3
2 4 5 6 7
3 8 9 10 11
"""3、修改索引
import pandas as pd
a=pd.DataFrame([[1,2],[3,4],[5,6]],index=['A','B','C'],columns=['date','score'])
a.index.name='公司'
print(a)
"""
打印结果:
date score
公司
A 1 2
B 3 4
C 5 6
"""
###################################################################
import pandas as pd
a=pd.DataFrame([[1,2],[3,4],[5,6]],index=['A','B','C'],columns=['date','score'])
a.rename(index={'A':'万科','B':'阿里','C':'百度'},columns={'date':'日期','score':'分数'},inplace=True)
print(a)
"""
执行结果:
日期 分数
万科 1 2
阿里 3 4
百度 5 6
"""
#####################将行索引转换为常规列###################
a.index.name='公司'
a=a.reset_index()
"""
公司 日期 分数
0 万科 1 2
1 阿里 3 4
2 百度 5 6
"""
####################把常规列转换为行索引####################
a=a.set_index('日期')
"""
公司 分数
日期
1 万科 2
3 阿里 4
5 百度 6
"""4、文件的读取和写入
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
print(data)
"""
执行结果:
公司 哈哈
0 百度 卡看
1 分数 啦啦
"""
#也可读取CVS格式,pd.read_csv('data.csv')
###################################写入#########################################
import pandas as pd
data=pd.DataFrame([[1,2],[3,4],[5,6]],columns=['A列','B列'])
data.to_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')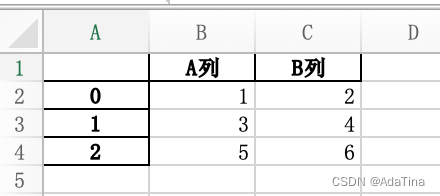
#把A列数据写入工作簿并忽略行索引信息
data.to_excel('data.xlsx', columns=['A列'],index=False)
#CSV同理
data.to_csv('data.csv')5、数据的选取、筛选、排序、运算与删除
1》数据的选取
1)按列选取数据
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
#选取列,返回一个一维的Series
a=data['A列']
#返回二维的表格数据
b=data[['A列']]
#多列表格数据
c=data[['A列','B列']]
print(a)
print(b)
print(c)
"""
打印结果:
0 1
1 3
2 5
Name: A列, dtype: int64
A列
0 1
1 3
2 5
A列 B列
0 1 2
1 3 4
2 5 6
"""
2)按行选取数据
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data[1:3]#按行选取数据,左闭右开
print(a)
"""
运行结果:
Unnamed: 0 A列 B列
1 1 3 4
2 2 5 6
"""
#####################以上方法可能引起错误######################
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data.iloc[1:3]#按行选取数据,左闭右开
#使用行的名称进行选取
b=data.loc[[1,2]]
#行比较多,可以进行head前几行的选取
c=data.head(2)
print(a)
print(b)
print(c)
"""
Unnamed: 0 A列 B列
1 1 3 4
2 2 5 6
Unnamed: 0 A列 B列
1 1 3 4
2 2 5 6
Unnamed: 0 A列 B列
0 0 1 2
1 1 3 4
"""3)按区块进行选取
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data[['A列','B列']][0:2]#按区块进行选取
#同上
b=data.iloc[0:2][['A列','B列']]
print(a)
print(b)
"""
运行结果:
A列 B列
0 1 2
1 3 4
A列 B列
0 1 2
1 3 4
"""
##########################选取单个单元格##############################
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data.iloc[0]['A列']#先选行,再选列,选取单个单元格
#选取多个单元格,i表示索引
b=data.iloc[0:2,[1,2]]
c=data.loc[[0,1],['A列','B列']]
print(a)
print(b)
print(c)
"""
运行结果:
1
A列 B列
0 1 2
1 3 4
A列 B列
0 1 2
1 3 4
"""
data.ix[[0:2,['A列','B列']]#索引不必须为字符串或数字2》数据的筛选
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data[data['A列']>1]
b=data[(data['A列']>1)&(data['B列']==4)]
print(a)
print(b)
"""
运算结果:
Unnamed: 0 A列 B列
1 1 3 4
2 2 5 6
Unnamed: 0 A列 B列
1 1 3 4
"""3》数据的排序
按A列进行降序排序
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
a=data.sort_values(by='A列',ascending=False)
print(a)
"""
运行结果:
Unnamed: 0 A列 B列
2 2 5 6
1 1 3 4
0 0 1 2
"""
###################按照行索引进行升序###################
b=data.sort_index(ascending=True)#按照行索引进行排序
print(b)
"""
运行结果:
Unnamed: 0 A列 B列
0 0 1 2
1 1 3 4
2 2 5 6
"""4》数据的运算
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
data['C列']=data['B列']-data['A列']
print(data)
"""
运算结果:
Unnamed: 0 A列 B列 C列
0 0 1 2 1
1 1 3 4 1
2 2 5 6 1
"""5》数据的删除
import pandas as pd
data=pd.read_excel('/Users/Tina/Desktop/20220607/分公司1.xlsx')
data.drop(columns='A列')#单列删除
data.drop(columns=['A列','B列'])#进行列数据删除
data.drop(index=[1,2],inplace=True)#进行行数据删除;inplace=True会改变DataFrame的结构
print(data)
"""
运行结果:
Unnamed: 0 A列 B列
0 0 1 2
"""6、数据表的拼接
1)合并merge
import pandas as pd
df1=pd.DataFrame({'公司':['百度','腾讯','静思'],'分数':[90,98,65]})
df2=pd.DataFrame({'公司':['百度','腾讯','静思2'],'股价':[33,49,10]})
print(df1)
print(df2)
"""
执行结果:
公司 分数
0 百度 90
1 腾讯 98
2 静思 65
公司 股价
0 百度 33
1 腾讯 49
2 静思2 10
"""
###############merge()默认选取两个列共有的内容,根据相同的列名进行合并#########
df3=pd.merge(df1,df2)
print(df3)
"""
运行结果:
公司 分数 股价
0 百度 90 33
1 腾讯 98 49
"""
############如果同名的列不止一个,on指定按照哪一列进行合并######################
df3=pd.merge(df1,df2,on='公司')
####################默认合并方式取交集,并集outer########################
df3=pd.merge(df1,df2,how='outer')
"""
运行结果:
公司 分数 股价
0 百度 90.0 33.0
1 腾讯 98.0 49.0
2 静思 65.0 NaN
3 静思2 NaN 10.0
"""
############保留左表全部内容,右表不太在意#####################
df3=pd.merge(df1,df2,how='left')#右表同理
"""
运行结果:
公司 分数 股价
0 百度 90 33.0
1 腾讯 98 49.0
2 静思 65 NaN
"""
############按照行索引进行合并##############
df3=pd.merge(df1,df2,left_index=True,right_index=True)
"""
公司_x 分数 公司_y 股价
0 百度 90 百度 33
1 腾讯 98 腾讯 49
2 静思 65 静思2 10
"""2)连接concat
df3=pd.concat([df1,df2],ignore_index=True)
"""
运行结果:
公司 分数 股价
0 百度 90.0 NaN
1 腾讯 98.0 NaN
2 静思 65.0 NaN
3 百度 NaN 33.0
4 腾讯 NaN 49.0
5 静思2 NaN 10.0
"""
#############横向拼接##############
df3=pd.concat([df1,df2],axis=1)#横向拼接
"""
公司 分数 公司 股价
0 百度 90 百度 33
1 腾讯 98 腾讯 49
2 静思 65 静思2 10
"""
##############append简化版concat#########
df3=df1.append({'公司':'腾飞','分数':'90'},ignore_index=True)
"""
运行结果:
公司 分数
0 百度 90
1 腾讯 98
2 静思 65
3 腾飞 90
"""
五、数据可视化模块——Matplotlib