背景
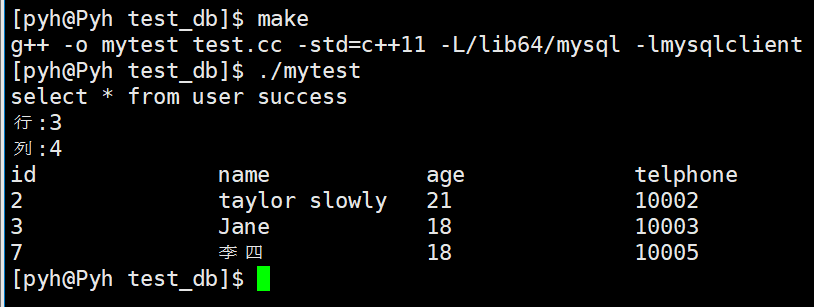
- 使用流批量处理数据的时候,我们最关注的肯定是效率问题
- 数据批量处理分为4类
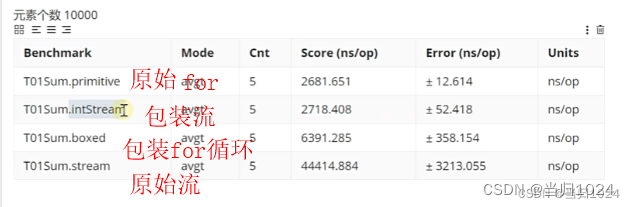
- 原始的for循环处理基本类型
- 基本类型包装流
- 原始的for循环处理包装类型
- 原始的依稀那个流Stream.of(1,2,3,4)
对比(单线程)
- 任何是时候,
原始的for循环处理基本类型都是最快的,普通的Stream永远都是最慢的数据量越大,基本类型包装流 的 速度就越接近原始的for循环处理基本类型- 如果数据量大,可以考虑使用流代替for循环,因为写法更加简洁,但是任何时候都要避免使用普通的stream进行计算
对比(多线程和单线程)
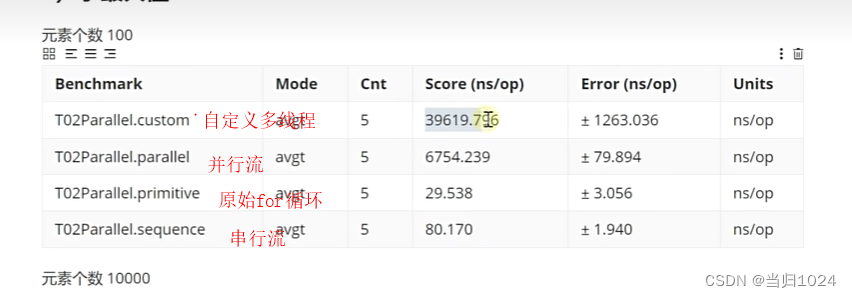
- 自定义的多线程
- 并行流
- 串行流
- 原始for循环
数据量小
- 数据量小的时候
- 串行比并行速度快,因为并行开启线程消耗大量时间
- 最快的还是for训话
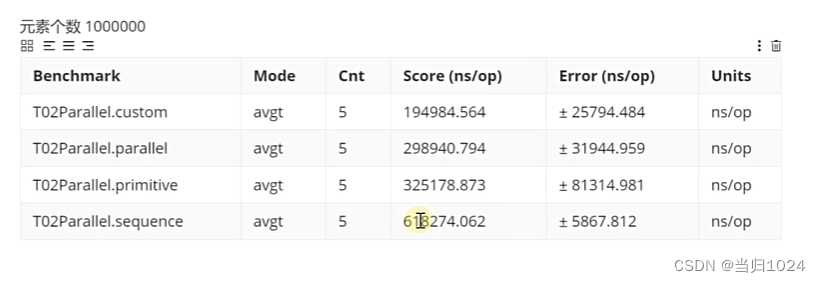
数据量大
数据量大的时候,串行流最慢,自定义的多线程最快- 速度:自定义多线程 >并行流>for循环>串行流
总结
数据量大的时候,多线程的优势逐渐体现数据量小的时候,开启多线程反而更加耗费时间和资源- 并行流比自己写多线程要简洁很多