文章目录
- 分布式常见的问题
- 常见的分布式算法
- Raft算法
- 概念
- Raft的实现
- ZAB算法
- Paxos算法
分布式常见的问题
分布式场景下困扰我们的3个核心问题(CAP):一致性、可用性、分区容错性。
1、一致性(Consistency):无论服务如何拆分,所有实例节点同一时间看到是相同的数据
2、可用性(Availability):不管是否成功,确保每一个请求都能接收到响应
3、分区容错性(Partition Tolerance):系统任意分区后,在网络故障时,仍能操作
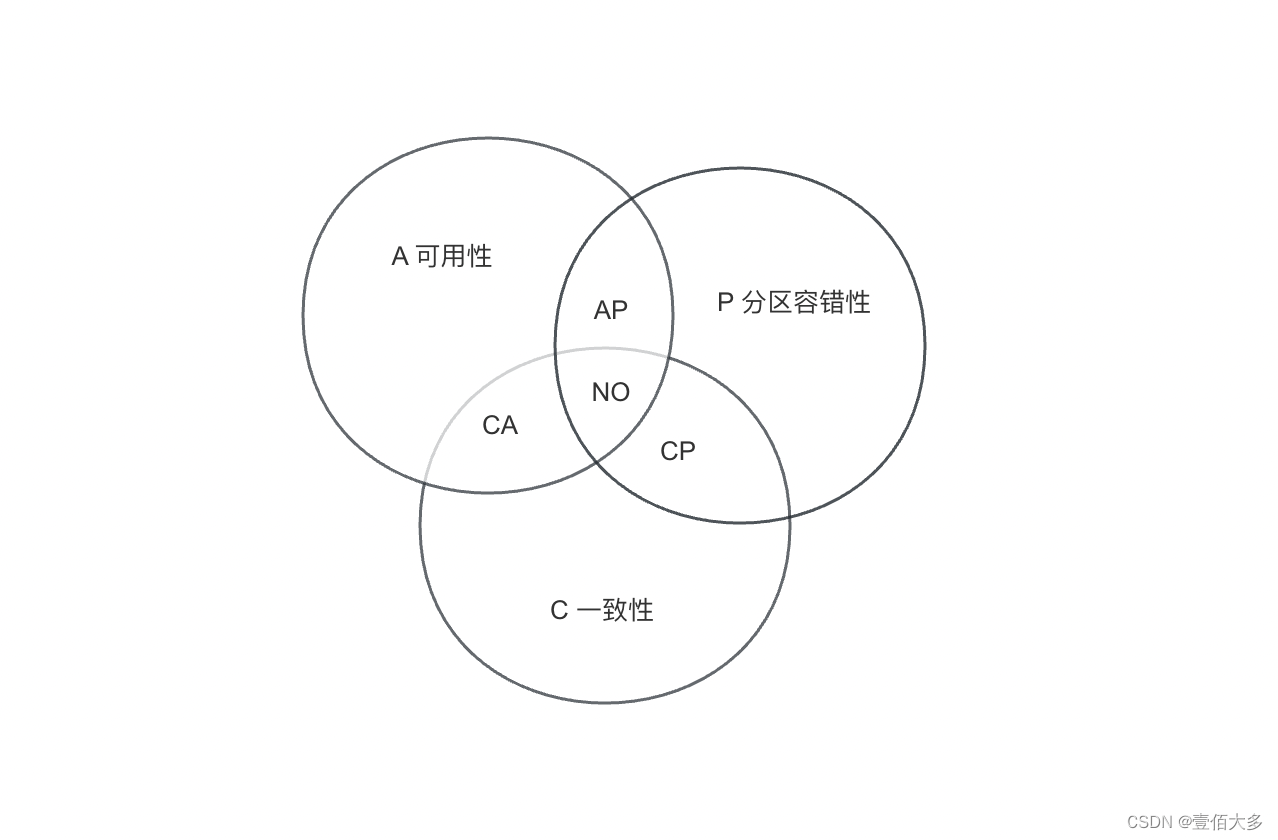
而我们的业务中,一般一致性、可用性、分区容错性,三个满足两个,一般算法就是以CA和AP两个选择性,进行选择。
常见的分布式算法
Raft算法
概念
RAFT(Replicated State Machine Approach)算法是一种一致性分布式复制协议,用于在分布式系统中维护一组服务节点的一致状态。它是一种领导者选举算法,适用于解决分布式系统中的数据复制和一致性问题。
1.领导者选举:RAFT将系统中的节点分为三种角色:领导者(leader)、跟随者(follower)和候选者(candidate)。在任何给定的时刻,系统中都只有一个领导者。节点之间通过选举机制选出领导者,领导者负责处理客户端请求,并在系统中推动状态变更。
跟随者(Follower)
Fllower是所有节点的初始状态,内部都会有一个随机超时时间。这个超时时间,规定了在倒计时结束后仍然收不到Leader的心跳,Follower就会转变为Candidate。
候选者(candidate)
Follower在转变为Candidate后,超时时间重置,倒计时结束时就会向其他节点提名自己的实,拉取选票。
如果能获得半数以上(1/2以上,包含自己投给自己的)的选票,则当选为Leader,这个过程就叫做Leader选举。
所以节点最好是单数,避免极端情况下出现一个集群选举出两个Leader的脑裂问题。
领导者(leader)
Raft集群通过Leader与客户端进行交互,Leader不断处理写请求与发送心跳给Follower,Follower在收到Leader的心跳后,其超时时间会重置,即重新开始倒计时。
正常工作期间只有 Leader 和 Follower,且Leader至多只能有一个。
2.任期(Term):系统中的时间被分为一个个任期。每个任期都有一个唯一的标识符,领导者选举是基于这个任期进行的。当一个候选者成为领导者时,它会增加当前任期的编号,并在该任期内保持领导者身份。
3.日志(Log):RAFT将系统状态的变化表示为一系列日志条目。每个日志条目包含一个命令和任期号。这些日志条目按顺序附加到每个节点的日志中,并通过领导者复制到其他节点。
4.选举过程:当没有领导者时,节点会进入选举过程。在选举过程中,节点变为候选者状态,并向其他节点发送选举请求。候选者获得多数票后成为领导者。为了避免竞争和分裂投票,选举中使用随机化的超时机制。
5.日志复制:领导者负责将新的日志条目复制到其他节点。一旦大多数节点确认了日志条目,领导者就可以提交日志,并通知其他节点将其应用到状态机中。
6.安全性和一致性:RAFT确保在系统中只有一个领导者,并且所有节点都按相同的顺序应用相同的日志条目,从而确保了系统的一致性和安全性。
Raft的实现
public class Node {
private int nodeId;
private RaftNode raftNode;
public Node(int nodeId, RaftNode raftNode) {
this.nodeId = nodeId;
this.raftNode = raftNode;
}
public int getNodeId() {
return nodeId;
}
public RaftNode getRaftNode() {
return raftNode;
}
}
import java.util.*;
import java.util.concurrent.*;
import java.util.concurrent.locks.*;
public class RaftNode implements Runnable {
private int nodeId;
private List<Node> cluster;
private String state;
private int currentTerm;
private Integer votedFor;
private List<String> log;
private int commitIndex;
private int lastApplied;
private Map<Integer, Integer> nextIndex;
private Map<Integer, Integer> matchIndex;
private Integer leaderId;
private final Lock lock;
public RaftNode(int nodeId, List<Node> cluster) {
this.nodeId = nodeId;
this.cluster = cluster;
this.state = "Follower";
this.currentTerm = 0;
this.votedFor = null;
this.log = new ArrayList<>();
this.commitIndex = 0;
this.lastApplied = 0;
this.nextIndex = new ConcurrentHashMap<>();
this.matchIndex = new ConcurrentHashMap<>();
this.leaderId = null;
this.lock = new ReentrantLock();
}
public void start() {
new Thread(this).start();
}
@Override
public void run() {
while (true) {
switch (state) {
case "Follower":
runFollower();
break;
case "Candidate":
runCandidate();
break;
case "Leader":
runLeader();
break;
}
}
}
private void runFollower() {
long timeout = (long) (150 + Math.random() * 150);
long lastHeartbeat = System.currentTimeMillis();
while ("Follower".equals(state)) {
if (System.currentTimeMillis() - lastHeartbeat >= timeout) {
state = "Candidate";
return;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private void runCandidate() {
currentTerm++;
votedFor = nodeId;
int votesReceived = 1;
for (Node peer : cluster) {
if (peer.getNodeId() != nodeId && sendRequestVote(peer.getRaftNode())) {
votesReceived++;
}
}
if (votesReceived > cluster.size() / 2) {
state = "Leader";
leaderId = nodeId;
for (Node peer : cluster) {
if (peer.getNodeId() != nodeId) {
nextIndex.put(peer.getNodeId(), log.size());
matchIndex.put(peer.getNodeId(), 0);
}
}
} else {
state = "Follower";
}
}
private void runLeader() {
while ("Leader".equals(state)) {
sendHeartbeats();
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private boolean sendRequestVote(RaftNode peer) {
peer.lock.lock();
try {
if (peer.currentTerm <= currentTerm && (peer.votedFor == null || peer.votedFor == nodeId)) {
peer.votedFor = nodeId;
return true;
}
} finally {
peer.lock.unlock();
}
return false;
}
private void sendHeartbeats() {
for (Node peer : cluster) {
if (peer.getNodeId() != nodeId) {
sendAppendEntries(peer.getRaftNode());
}
}
}
private void sendAppendEntries(RaftNode peer) {
peer.lock.lock();
try {
if (peer.currentTerm > currentTerm) {
state = "Follower";
}
} finally {
peer.lock.unlock();
}
}
}
import java.util.*;
public class RaftCluster {
public static void main(String[] args) {
List<Node> cluster = new ArrayList<>();
for (int i = 0; i < 5; i++) {
RaftNode raftNode = new RaftNode(i, cluster);
Node node = new Node(i, raftNode);
cluster.add(node);
raftNode.start();
}
}
}
ZAB算法
ZAB(ZooKeeper Atomic Broadcast)算法是分布式系统中用来实现一致性的重要协议。它是Apache ZooKeeper分布式协调服务的核心组件,确保集群中的所有节点在数据上的一致性。以下是对ZAB算法的详细解释。
- 目标
ZAB的主要目标:
顺序一致性:确保所有事务在所有ZooKeeper服务器上以相同的顺序被应用。
原子广播:确保每个事务被可靠地传递到集群中的所有节点。
容错性:在部分节点故障的情况下,仍能保证系统的正确性和可用性。 - 工作模式
ZAB算法有两种主要的工作模式:
广播模式(Broadcast mode):用于正常操作期间处理客户端请求。
恢复模式(Recovery mode):用于集群启动或领导者故障后,选举新领导者并同步状态。 - 广播模式
在广播模式下,ZAB的工作流程如下:
领导者选举:集群启动或领导者故障后,会进行领导者选举。新领导者负责处理客户端请求并广播事务。
事务处理:
客户端请求被发送到领导者。
领导者生成提案(Proposal),将提案广播给所有追随者(Follower)。
追随者接收提案并将其写入事务日志,然后发送确认(ACK)给领导者。
当领导者收到大多数追随者的确认后,认为提案已提交(Commit),并将提交信息广播给所有追随者。
每个节点应用提交的事务到其状态机。 - 恢复模式
在恢复模式下,ZAB的工作流程如下:
数据同步:确保新领导者和追随者之间的数据一致性。追随者将与领导者进行数据同步,获取最新的事务日志。
领导者选举:如果没有现任领导者,集群会通过投票机制选举出新的领导者。
状态同步:新领导者与追随者同步状态,以便进入广播模式继续处理客户端请求。 - 容错处理
ZAB通过以下机制实现容错:
复制日志:每个事务都被写入多个节点的事务日志,确保在部分节点故障时仍然可以恢复数据。
多数派确认:事务在大多数节点确认后才被提交,保证系统在多数节点可用的情况下仍然一致。
持久化存储:事务日志被持久化存储在磁盘上,防止数据因节点重启或崩溃而丢失。
Paxos算法
Paxos是一种广泛使用的分布式一致性算法,由计算机科学家Leslie Lamport提出。它用于在分布式系统中达成一致性,即使某些节点发生故障也能保证系统的一致性。Paxos算法的核心思想是在分布式环境中,通过一系列的消息传递和投票机制,确保多个节点对某个值达成共识。
Paxos算法的基本概念
Paxos算法涉及三个主要角色:
提议者(Proposer):提出提案并争取达成共识。
接受者(Acceptor):对提议者提出的提案进行投票。
学习者(Learner):一旦共识达成,学习最终达成的值。
Paxos算法的基本过程
Paxos算法通常分为两个主要阶段:准备阶段(Prepare Phase)和接受阶段(Accept Phase)。
- 准备阶段(Prepare Phase)
提议者选择一个提案编号n并向大多数接受者发送Prepare(n)请求。
接受者收到Prepare(n)请求后,如果n大于它已经响应过的所有Prepare请求的编号,则接受该请求,并承诺不再接受编号小于n的提案。同时,接受者会向提议者回复它已经接受的提案中编号最大的提案。 - 接受阶段(Accept Phase)
提议者在收到大多数接受者对Prepare(n)请求的响应后,可以确定一个提案值。如果接受者返回了已经接受的提案,提议者会选取编号最大的那个提案值;否则,可以选择任意值。
提议者将提案(n, value)发送给大多数接受者,请求他们接受该提案。
接受者收到提案后,如果提案编号n不小于它已经响应过的所有Prepare请求的编号,则接受该提案,并向提议者回复确认消息。
达成共识
当提议者收到大多数接受者对Accept(n, value)请求的确认时,认为提案已经被接受,达成共识。
学习者通过接受者的消息获知已经达成共识的值。
Paxos算法的特点
容错性:Paxos算法能够容忍少量的节点故障,只要大多数节点正常工作,系统就能达成一致性。
一致性:Paxos算法保证所有参与节点最终会达成一致的决策。
复杂性:Paxos算法的实现和理解相对复杂,特别是在处理边界情况和优化性能时。
Paxos的变种
Paxos算法有许多变种,用于在不同的应用场景中优化性能和简化实现,例如:
Multi-Paxos:扩展Paxos算法以支持多个提案的连续达成共识,常用于实现分布式日志。
Fast Paxos:通过减少消息传递的轮数来加速达成共识。
Cheap Paxos:优化资源使用,降低实现成本。
应用场景
Paxos算法广泛应用于需要分布式一致性的系统中,例如分布式数据库、分布式文件系统和分布式协调服务等。