Ao Wang Hui Chen∗ Lihao Liu Kai Chen Zijia Lin
Jungong Han Guiguang Ding
Tsinghua University
Corresponding Author.
文献来源:中英文对照阅读
摘要
在过去的几年里,YOLO 因其在计算成本和检测性能之间的有效平衡而成为实时目标检测领域的主要范例。 研究人员对 YOLO 的架构设计、优化目标、数据增强策略等进行了探索,取得了显着进展。 然而,后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。 此外,YOLO中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。 它提供了次优的效率,以及相当大的性能改进潜力。 在这项工作中,我们的目标是从后处理和模型架构方面进一步提升 YOLO 的性能效率边界。 为此,我们首先提出了 YOLO 的无 NMS 训练的一致双重分配,它同时带来了有竞争力的性能和低推理延迟。 此外,我们还介绍了 YOLO 的整体效率-准确性驱动模型设计策略。 我们从效率和准确性两个角度全面优化YOLO的各个组件,大大降低了计算开销并增强了能力。 我们努力的成果是用于实时端到端目标检测的新一代 YOLO 系列,称为 YOLOv10。 大量实验表明,YOLOv10 在各种模型规模上都实现了最先进的性能和效率。 例如,我们的 YOLOv10-S 在 COCO 上类似 AP 下比 RT-DETR-R18 快 1.8×,同时参数数量和 FLOP 少 2.8×。 与 YOLOv9-C 相比,在相同性能下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。 代码:GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection。
1简介
实时目标检测一直是计算机视觉领域的研究重点,其目的是在低延迟下准确预测图像中目标的类别和位置。 它被广泛应用于各种实际应用中,包括自动驾驶[3]、机器人导航[11]和物体跟踪[66], 等等。 近年来,研究人员致力于设计基于 CNN 的目标检测器来实现实时检测[18,22,43,44,45,51,12]。 其中,YOLO 因其在性能和效率之间的巧妙平衡而越来越受欢迎[2,19,27,19,20,59,54,64,7,65,16,27]。 YOLO的检测流程由两部分组成:模型前处理和NMS后处理。 然而,它们仍然存在缺陷,导致精度-延迟边界不理想。
具体来说,YOLO 在训练过程中通常采用一对多的标签分配策略,其中一个真实对象对应多个正样本。 尽管产生了优越的性能,但这种方法需要 NMS 在推理过程中选择最佳的正预测。 这会降低推理速度,并使性能对 NMS 的超参数敏感,从而阻止 YOLO 实现最佳的端到端部署[71]。 解决这一问题的方法之一是采用最近推出的端到端 DETR 架构[4,74,67,28,34,40,61]。 例如,RT-DETR [71] 提出了一种高效的混合编码器和不确定性最小的查询选择,将 DETR 推向实时应用领域。 然而,部署 DETR 固有的复杂性阻碍了其在准确性和速度之间实现最佳平衡的能力。 另一条路线是探索基于 CNN 的检测器的端到端检测,通常利用一对一分配策略来抑制冗余预测[5,49,60,73,16] 。 然而,它们通常会引入额外的推理开销或实现次优的性能。
此外,模型架构设计仍然是 YOLO 的基本挑战,它对精度和速度有重要影响[45,16,65,7]。 为了实现更高效、更有效的模型架构,研究人员探索了不同的设计策略。 为骨干网提供了各种主要计算单元以增强特征提取能力,包括 DarkNet [43, 44, 45]、CSPNet [2]、EfficientRep [ 27] 和 ELAN [56, 58]、等。对于颈部,PAN [35]、BiC [27]、GD [54] 和 RepGFPN [65]、等.被探索以增强多尺度特征融合。 此外,还研究了模型缩放策略[56, 55]和重新参数化[10, 27]技术。 虽然这些努力取得了显着的进步,但仍然缺乏从效率和准确性角度对 YOLO 中各个组件进行全面检查。 因此,YOLO 中仍然存在相当大的计算冗余,导致参数利用率低下和效率次优。 此外,由此产生的模型能力受限也会导致性能较差,从而为精度改进留下了足够的空间。
在这项工作中,我们的目标是解决这些问题并进一步提高 YOLO 的准确性-速度边界。 我们的目标是整个检测流程中的后处理和模型架构。 为此,我们首先通过使用双标签分配和一致的匹配度量为无 NMS YOLO 提出一致的双分配策略来解决后处理中的冗余预测问题。 它使模型在训练过程中享受丰富而和谐的监督,同时在推理过程中无需使用 NMS,从而获得高效率的竞争性能。 其次,我们通过对 YOLO 中的各个组件进行全面检查,提出了模型架构的整体效率-准确性驱动的模型设计策略。 为了提高效率,我们提出了轻量级分类头、空间通道解耦下采样和排序引导块设计,以减少明显的计算冗余并实现更高效的架构。 为了提高准确性,我们探索了大核卷积并提出了有效的部分自注意力模块来增强模型能力,在低成本下挖掘性能改进的潜力。
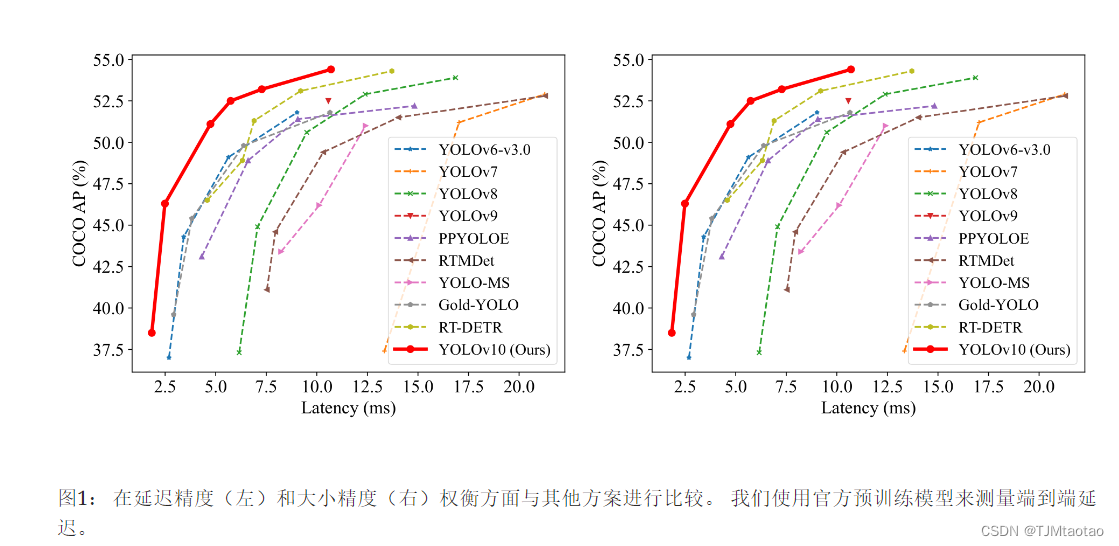
基于这些方法,我们成功实现了一系列具有不同模型尺度的实时端到端检测器,即。,YOLOv10-N / S /中/B/L/X。 对目标检测标准基准即.、COCO [33]进行的大量实验表明,我们的 YOLOv10 可以显着优于之前的状态在不同模型规模的计算精度权衡方面的最先进模型。 如图图 1所示,我们的YOLOv10-S / X为1.8× / 1.3× 在相似性能下分别比 RT-DETR-R18 / R101 更快。 与YOLOv9-C相比,YOLOv10-B在相同性能的情况下实现了46%的延迟降低。 此外,YOLOv10 表现出高效的参数利用。 我们的 YOLOv10-L / X 比 YOLOv8-L / X 的性能提高了 0.3 AP 和 0.5 AP,参数数量分别减少了 1.8× 和 2.3× 。 与 YOLOv9-M / YOLO-MS 相比,YOLOv10-M 实现了类似的 AP,参数分别减少了 23% / 31%。 我们希望我们的工作能够激发该领域的进一步研究和进步。
2相关工作
实时物体探测器。 实时对象检测旨在低延迟下对对象进行分类和定位,这对于实际应用至关重要。 在过去的几年里,人们付出了大量的努力来开发高效的探测器[18,51,43,32,72,69,30,29,39]。 特别是YOLO系列[43,44,45,2,19,27,56,20,59]脱颖而出,成为主流。 YOLOv1、YOLOv2 和 YOLOv3 确定了由三部分组成的典型检测架构,即.、骨干、颈部和头部[43,44,45]. YOLOv4 [2] 和 YOLOv5 [19] 引入了 CSPNet [57] 设计来替代 DarkNet [42] ,再加上数据增强策略、增强的 PAN 和更多种类的模型规模,等。 YOLOv6 [27] 分别针对颈部和脊柱提出了 BiC 和 SimCSPPPF,具有锚辅助训练和自蒸馏策略。 YOLOv7 [56] 引入了 E-ELAN 来实现丰富的梯度流路径,并探索了几种可训练的 bag-of-freebies 方法。 YOLOv8 [20] 提出了用于有效特征提取和融合的 C2f 构建块。 Gold-YOLO[54]提供了先进的GD机制来增强多尺度特征融合能力。 YOLOv9 [59] 提出 GELAN 来改进架构,并提出 PGI 来增强训练过程。
端到端对象检测器。 端到端对象检测已成为传统管道的范式转变,提供简化的架构[48]。 DETR[4]引入了Transformer架构,采用匈牙利损失实现一对一匹配预测,从而消除了手工制作的组件和后处理。 从那时起,人们提出了各种 DETR 变体来增强其性能和效率[40,61,50,28,34]。 Deformable-DETR [74]利用多尺度可变形注意力模块来加速收敛速度。 DINO [67]将对比去噪、混合查询选择和前瞻两次方案集成到DETR中。 RT-DETR[71]进一步设计了高效的混合编码器,并提出了不确定性最小的查询选择,以提高准确性和延迟。 实现端到端目标检测的另一条路线是基于 CNN 检测器。 可学习的 NMS [23] 和关系网络 [25] 提供了另一个网络来删除检测器的重复预测。 OneNet [49] 和 DeFCN [60] 提出一对一匹配策略,以通过全卷积网络实现端到端对象检测。 FCOSpss [73]引入正样本选择器来选择最佳样本进行预测。
3方法论
3.1无 NMS 训练的一致双重分配
在训练过程中,YOLO [20, 59, 27, 64] 通常利用 TAL [14] 为每个实例分配多个正样本。 采用一对多分配方式,产生丰富的监控信号,有利于优化,实现卓越的性能。 然而,它需要 YOLO 依赖于 NMS 后处理,这会导致部署的推理效率不理想。 虽然之前的工作[49,60,73,5]探索一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。 在这项工作中,我们提出了一种针对 YOLO 的无 NMS 训练策略,具有双标签分配和一致的匹配指标,实现了高效率和有竞争力的性能。
双标签分配。 与一对多分配不同,一对一匹配仅向每个基本事实分配一个预测,从而避免了 NMS 后处理。 然而,它导致监督较弱,从而导致精度和收敛速度不理想[75]。 幸运的是,这一缺陷可以通过一对多赋值[5]来弥补。 为了实现这一目标,我们为 YOLO 引入了双标签分配,以结合两种策略的优点。 具体如图图2所示。(a),我们为 YOLO 加入了另一个一对一的头。 它保留了与原始一对多分支相同的结构并采用相同的优化目标,但利用一对一匹配来获取标签分配。 在训练过程中,两个头部与模型共同优化,让脊柱和颈部享受一对多任务提供的丰富监督。 在推理过程中,我们丢弃一对多头并利用一对一头进行预测。 这使得 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。 此外,在一对一匹配中,我们采用了top one的选择,它达到了与匈牙利匹配[4]相同的性能,但额外的训练时间更少。
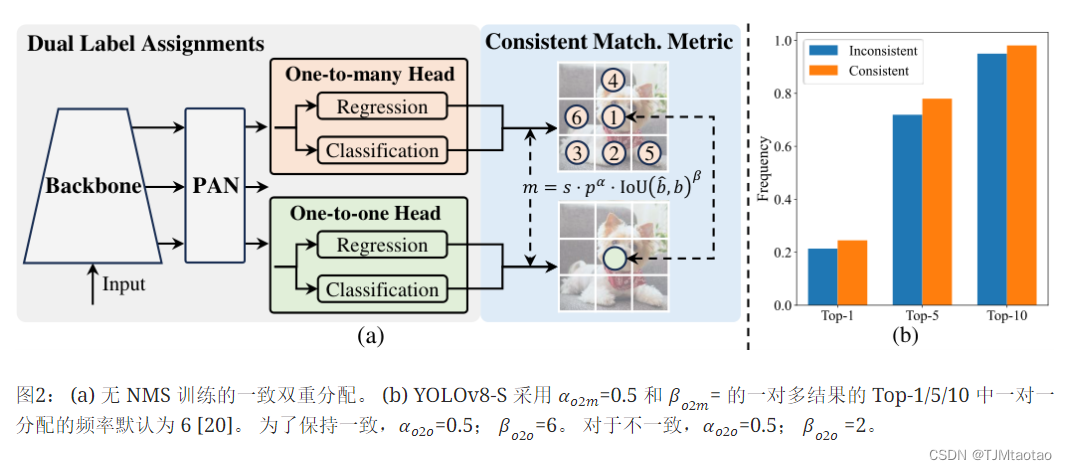
一致的匹配指标。 在分配过程中,一对一和一对多方法都利用指标来定量评估预测和实例之间的一致性程度。 为了实现两个分支的预测感知匹配,我们采用统一的匹配度量,即。,

其中p是分类分数,![]() 分别表示预测和实例的边界框。s表示空间先验,指示预测的锚点是否在实例 [20, 59, 27, 64] 内。
分别表示预测和实例的边界框。s表示空间先验,指示预测的锚点是否在实例 [20, 59, 27, 64] 内。![]() 是两个重要的超参数,它们平衡语义预测任务和位置回归任务的影响。 我们将一对多和一对一指标分别表示为
是两个重要的超参数,它们平衡语义预测任务和位置回归任务的影响。 我们将一对多和一对一指标分别表示为![]() 。 这些指标影响两个头的标签分配和监督信息。
。 这些指标影响两个头的标签分配和监督信息。


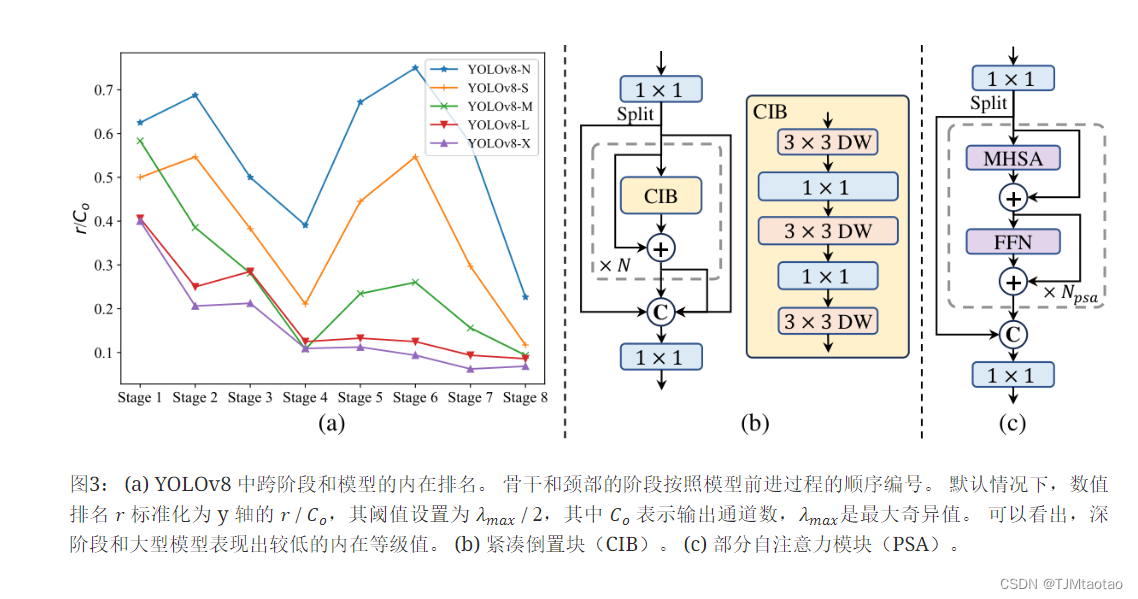


精度驱动的模型设计。 我们进一步探索了用于精度驱动设计的大核卷积和自注意力,旨在以最小的成本提高性能。
(1)大核卷积。 采用大核深度卷积是扩大感受野、增强模型能力的有效方法[9,38,37]。 然而,在所有阶段简单地利用它们可能会导致用于检测小物体的浅层特征受到污染,同时还会在高分辨率阶段引入显着的I/O开销和延迟[7]. 因此,我们建议在深度阶段利用 CIB 中的大内核深度卷积。 具体来说,我们将 CIB 中第二个 3×3 深度卷积的内核大小增加到 7×7,紧接着 [37]。 此外,我们采用结构重新参数化技术 [10, 9, 53] 引入另一个 3×3 个深度卷积分支来减轻优化问题,而无需推理开销。 此外,随着模型尺寸的增加,其感受野自然扩大,而使用大核卷积的好处逐渐减少。 因此,我们只对小模型规模采用大核卷积。
(2)部分自注意力(PSA)。 自注意力[52]由于其卓越的全局建模能力[36,13,70]而被广泛应用于各种视觉任务中。 然而,它表现出较高的计算复杂度和内存占用。 为了解决这个问题,鉴于普遍存在的注意力头冗余[63],我们提出了一种高效的部分自注意力(PSA)模块设计,如图图所示。 t2> 3.(c)。 具体来说,我们在 1×1 次卷积之后将跨通道的特征均匀地划分为两部分。 我们只将一部分馈送到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的�PSA块中。 然后两个部分通过 1×1 卷积连接并融合。 此外,我们按照[21]将查询和键的维度分配为MHSA中值的一半,并替换LayerNorm [1] 与 BatchNorm [26] 用于快速推理。 此外,PSA 仅放置在分辨率最低的第 4 阶段之后,避免了自注意力的二次计算复杂性带来的过多开销。 这样,可以将全局表示学习能力以较低的计算成本融入到YOLO中,从而很好地增强了模型的能力并提高了性能。
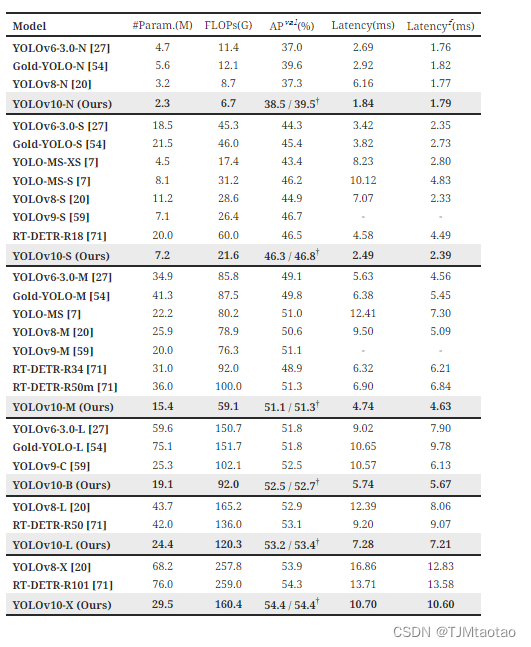
表格1:与最先进的技术的比较。 延迟是使用官方预训练模型来测量的。 Latencyf表示模型在没有进行后处理的情况下前向过程中的延迟。 †表示YOLOv10使用NMS与原始一对多的训练结果。 为了公平比较,以下所有结果均未使用知识蒸馏或 PGI 等额外的高级训练技术。
4.1实现细节
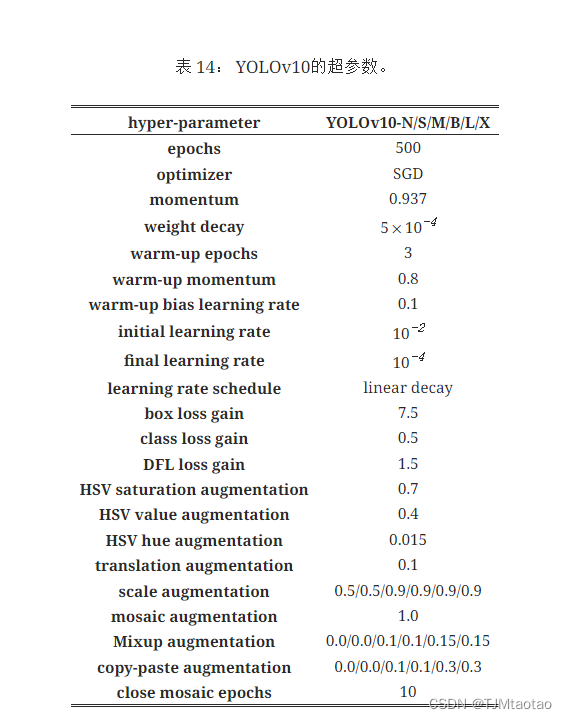
我们选择 YOLOv8 [20] 作为我们的基准模型,因为它具有值得称赞的延迟精度平衡及其在各种模型大小中的可用性。 我们采用一致的双重分配进行无 NMS 训练,并基于它进行整体效率-准确性驱动的模型设计,这带来了我们的 YOLOv10 模型。 YOLOv10 与 YOLOv8 具有相同的变体,即.、N / S / M / L / X。 此外,我们通过简单地增加 YOLOv10-M 的宽度比例因子,得到了一个新的变体 YOLOv10-B。我们在相同的从头开始训练设置 [20, 59, 56] 下在 COCO [33] 上验证了所提出的检测器。 此外,所有模型的延迟均在 T4 GPU 上使用 TensorRT FP16 进行测试,如下[71]。
4.2与最先进技术的比较
如图所示 选项卡。 1,我们的 YOLOv10 在各种模型规模上实现了最先进的性能和端到端延迟。 我们首先将 YOLOv10 与我们的基线模型进行比较,即.、YOLOv8。 在 N / S / M / L / X 五个变体上,我们的 YOLOv10 实现了 1.2% / 1.4% / 0.5% / 0.3% / 0.5% AP 改进,参数减少了 28% / 36% / 41% / 44% / 57% ,计算量减少 23% / 24% / 25% / 27% / 38%,延迟降低 70% / 65% / 50% / 41% / 37%。 与其他 YOLO 相比,YOLOv10 在准确性和计算成本之间也表现出卓越的权衡。 具体来说,对于轻量级和小型模型,YOLOv10-N / S 的性能比 YOLOv6-3.0-N / S 提高了 1.5 AP 和 2.0 AP,参数分别减少了 51% / 61%,计算量减少了 41% / 52%。 对于中型模型,与YOLOv9-C / YOLO-MS相比,YOLOv10-B / M在相同或更好的性能下分别享有46% / 62%的延迟降低。 对于大型模型,与 Gold-YOLO-L 相比,我们的 YOLOv10-L 的参数减少了 68%,延迟降低了 32%,AP 显着提高了 1.4%。 此外,与 RT-DETR 相比,YOLOv10 获得了显着的性能和延迟改进。 值得注意的是,在相似的性能下,YOLOv10-S / X 的推理速度分别比 RT-DETR-R18 / R101 快 1.8× 和 1.3× 。 这些结果很好地证明了YOLOv10作为实时端到端检测器的优越性。
我们还使用原始的一对多训练方法将 YOLOv10 与其他 YOLO 进行比较。 我们按照[56,20,54]考虑这种情况下模型转发过程的性能和延迟(Latencyf)。 如图所示 选项卡。 1,YOLOv10还展示了跨不同模型规模的最先进的性能和效率,表明了我们架构设计的有效性。
4.3模型分析
消融研究。 我们在 YOLOv10-S 和 YOLOv10-M 中展示了基于 YOLOv10-S 和 YOLOv10-M 的消融结果 选项卡。 2. 可以看出,我们的无 NMS 训练和一致的双重分配显着降低了 YOLOv10-S 的端到端延迟 4.63ms,同时保持了 44.3% AP 的竞争性能。 此外,我们的效率驱动模型设计减少了 11.8 M 个参数和 20.8 个 GFlOP,YOLOv10-M 的延迟显着减少了 0.65ms,充分展示了其有效性。 此外,我们的精度驱动模型设计使 YOLOv10-S 和 YOLOv10-M 实现了 1.8 AP 和 0.7 AP 的显着改进,并且延迟开销分别仅为 0.18ms 和 0.17ms,这很好地证明了其优越性。
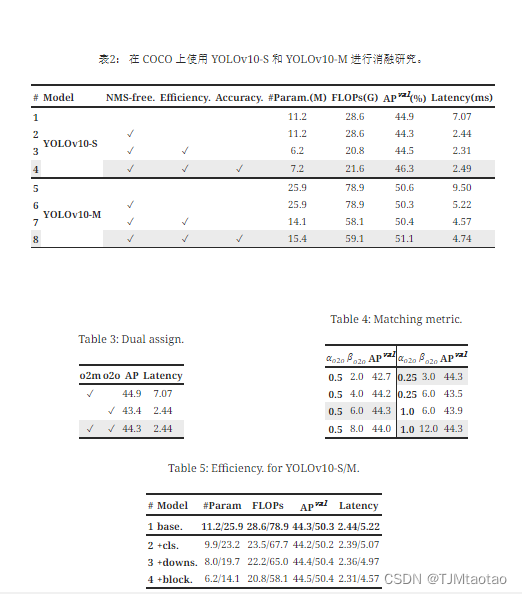

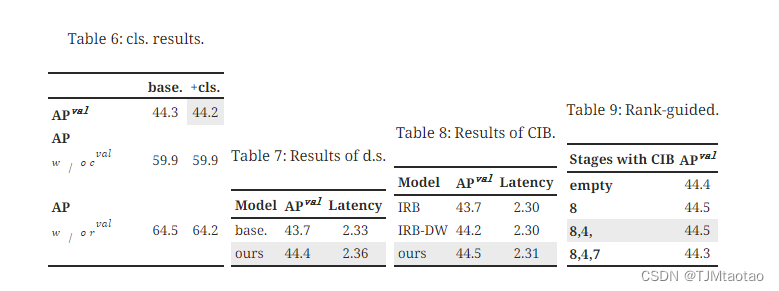
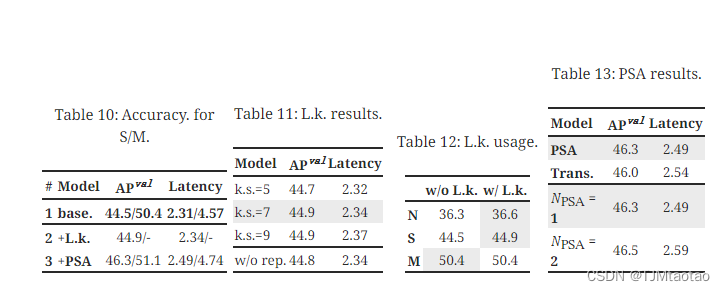

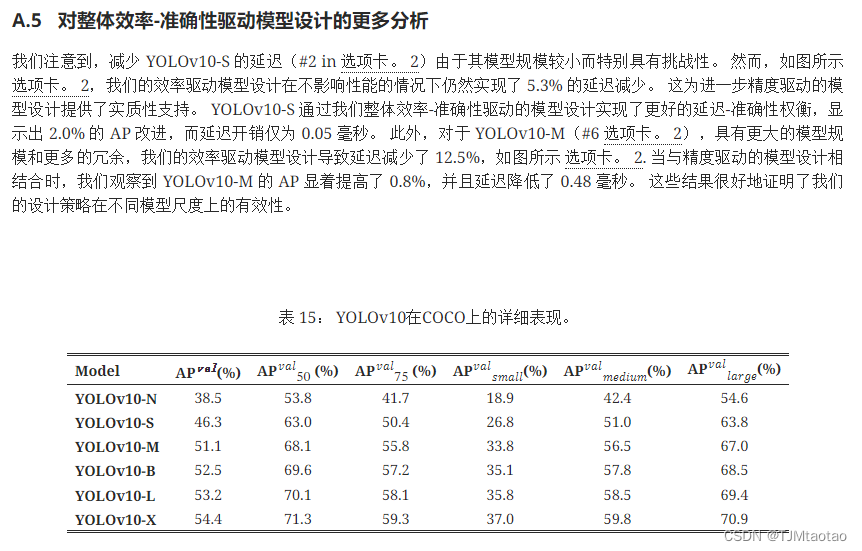
分析准确性驱动的模型设计。 我们展示了基于 YOLOv10-S/M 逐步集成精度驱动设计元素的结果。 我们的基线是结合效率驱动设计后的 YOLOv10-S/M 模型,即。,#3/#7 选项卡。 2. 如图所示 选项卡。 13,大核卷积和PSA模块的采用使得YOLOv10-S在最小延迟增加0.03ms和0.15ms的情况下分别获得了0.4% AP和1.4% AP的可观性能提升。 请注意,YOLOv10-M 未采用大核卷积(请参阅 选项卡。 13)。
限制。 由于计算资源有限,我们没有研究 YOLOv10 在大规模数据集上的预训练,例如.、Objects365 [47] 。 此外,虽然我们可以在无 NMS 的情况下使用一对一头实现有竞争力的端到端训练训练性能,但与使用 NMS 的原始一对多头相比仍然存在性能差距,特别是在小数据中尤为明显。楷模。 例如,在 YOLOv10-N 和 YOLOv10-S 中,使用 NMS 的一对多训练的性能分别比不使用 NMS 的性能高出 1.0% AP 和 0.5% AP。 我们将在未来的工作中探索如何进一步缩小YOLOv10的差距并实现更高的性能。
更广泛的影响。 YOLO 可广泛应用于各种实际应用,包括医学图像分析和自动驾驶等等。我们希望我们的YOLOv10能够在这些领域有所帮助,提高效率。 然而,我们承认我们的模型存在被恶意使用的可能性。 我们将尽一切努力防止这种情况发生。
- •
大核卷积。 我们首先基于 #2 中的 YOLOv10-S 研究不同内核大小的影响 选项卡。 13. 如图所示 选项卡。 13,性能随着内核大小的增加而提高,并停滞在内核大小 7×7 附近,表明大感知场的好处。 此外,在训练过程中删除重参数化分支实现了 0.1% 的 AP 降级,显示了其优化的有效性。 此外,我们基于YOLOv10-N / S / M检查了跨模型尺度的大内核卷积的好处。如图所示 选项卡。 13,由于其固有的广泛感受野,它对大型模型即。、YOLOv10-M没有带来任何改进。 因此,我们只对小模型采用大核卷积,即即。,YOLOv10-N / S。
- •
部分自注意力(PSA)。 我们引入PSA,通过以最小的成本整合全局建模能力来提高性能。 我们首先基于#3中的YOLOv10-S验证其有效性 选项卡。 13. 具体来说,我们引入 Transformer 块,即.,MHSA 后跟 FFN,作为基线,表示为“Trans.”。 如图所示 选项卡。 13相比之下,PSA带来了0.3%的AP提升和0.05ms的延迟降低。 性能的增强可能归因于通过减少注意力头的冗余来缓解自注意力中的优化问题[62, 9]。 此外,我们还研究了不同�PSA的影响。 如图所示 选项卡。 13,将 �PSA 增加到 2 可以获得 0.2% 的 AP 改进,但会带来 0.1ms 的延迟开销。 因此,我们默认将�PSA设置为1,以在保持高效率的同时增强模型能力。
-
5结论
在本文中,我们针对 YOLO 整个检测流程中的后处理和模型架构。 对于后处理,我们提出了一致的无 NMS 训练的双重分配,实现了高效的端到端检测。 对于模型架构,我们引入了整体效率-准确性驱动的模型设计策略,改善了性能与效率的权衡。 这些带来了我们的 YOLOv10,一种新的实时端到端对象检测器。 大量实验表明,与其他先进检测器相比,YOLOv10 实现了最先进的性能和延迟,充分证明了其优越性。
-
参考
- [1]Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton.Layer normalization.arXiv preprint arXiv:1607.06450, 2016.
- [2]Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao.Yolov4: Optimal speed and accuracy of object detection, 2020.
- [3]Daniel Bogdoll, Maximilian Nitsche, and J Marius Zöllner.Anomaly detection in autonomous driving: A survey.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4488–4499, 2022.
- [4]Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko.End-to-end object detection with transformers.In European conference on computer vision, pages 213–229. Springer, 2020.
- [5]Yiqun Chen, Qiang Chen, Qinghao Hu, and Jian Cheng.Date: Dual assignment for end-to-end fully convolutional object detection.arXiv preprint arXiv:2211.13859, 2022.
- [6]Yiqun Chen, Qiang Chen, Peize Sun, Shoufa Chen, Jingdong Wang, and Jian Cheng.Enhancing your trained detrs with box refinement.arXiv preprint arXiv:2307.11828, 2023.
- [7]Yuming Chen, Xinbin Yuan, Ruiqi Wu, Jiabao Wang, Qibin Hou, and Ming-Ming Cheng.Yolo-ms: rethinking multi-scale representation learning for real-time object detection.arXiv preprint arXiv:2308.05480, 2023.
- [8]François Chollet.Xception: Deep learning with depthwise separable convolutions.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1251–1258, 2017.
- [9]Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding.Scaling up your kernels to 31x31: Revisiting large kernel design in cnns.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11963–11975, 2022.
- [10]Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun.Repvgg: Making vgg-style convnets great again.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13733–13742, 2021.
- [11]Douglas Henke Dos Reis, Daniel Welfer, Marco Antonio De Souza Leite Cuadros, and Daniel Fernando Tello Gamarra.Mobile robot navigation using an object recognition software with rgbd images and the yolo algorithm.Applied Artificial Intelligence, 33(14):1290–1305, 2019.
- [12]Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian.Centernet: Keypoint triplets for object detection.In Proceedings of the IEEE/CVF international conference on computer vision, pages 6569–6578, 2019.
- [13]Patrick Esser, Robin Rombach, and Bjorn Ommer.Taming transformers for high-resolution image synthesis.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021.
- [14]Chengjian Feng, Yujie Zhong, Yu Gao, Matthew R Scott, and Weilin Huang.Tood: Task-aligned one-stage object detection.In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3490–3499. IEEE Computer Society, 2021.
- [15]Ruili Feng, Kecheng Zheng, Yukun Huang, Deli Zhao, Michael Jordan, and Zheng-Jun Zha.Rank diminishing in deep neural networks.Advances in Neural Information Processing Systems, 35:33054–33065, 2022.
- [16]Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun.Yolox: Exceeding yolo series in 2021.arXiv preprint arXiv:2107.08430, 2021.
- [17]Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph.Simple copy-paste is a strong data augmentation method for instance segmentation.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2918–2928, 2021.
- [18]Ross Girshick.Fast r-cnn.In Proceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015.
- [19]Jocher Glenn.Yolov5 release v7.0.https://github.com/ultralytics/yolov5/tree/v7.0, 2022.
- [20]Jocher Glenn.Yolov8.https://github.com/ultralytics/ultralytics/tree/main, 2023.
- [21]Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze.Levit: a vision transformer in convnet’s clothing for faster inference.In Proceedings of the IEEE/CVF international conference on computer vision, pages 12259–12269, 2021.
- [22]Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick.Mask r-cnn.In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.
- [23]Jan Hosang, Rodrigo Benenson, and Bernt Schiele.Learning non-maximum suppression.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4507–4515, 2017.
- [24]Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam.Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861, 2017.
- [25]Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen Wei.Relation networks for object detection.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3588–3597, 2018.
- [26]Sergey Ioffe and Christian Szegedy.Batch normalization: Accelerating deep network training by reducing internal covariate shift.In International conference on machine learning, pages 448–456. pmlr, 2015.
- [27]Chuyi Li, Lulu Li, Yifei Geng, Hongliang Jiang, Meng Cheng, Bo Zhang, Zaidan Ke, Xiaoming Xu, and Xiangxiang Chu.Yolov6 v3.0: A full-scale reloading.arXiv preprint arXiv:2301.05586, 2023.
- [28]Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang.Dn-detr: Accelerate detr training by introducing query denoising.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13619–13627, 2022.
- [29]Xiang Li, Wenhai Wang, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang.Generalized focal loss v2: Learning reliable localization quality estimation for dense object detection.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11632–11641, 2021.
- [30]Xiang Li, Wenhai Wang, Lijun Wu, Shuo Chen, Xiaolin Hu, Jun Li, Jinhui Tang, and Jian Yang.Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection.Advances in Neural Information Processing Systems, 33:21002–21012, 2020.
- [31]Ming Lin, Hesen Chen, Xiuyu Sun, Qi Qian, Hao Li, and Rong Jin.Neural architecture design for gpu-efficient networks.arXiv preprint arXiv:2006.14090, 2020.
- [32]Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár.Focal loss for dense object detection.In Proceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017.
- [33]Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick.Microsoft coco: Common objects in context.In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [34]Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang.Dab-detr: Dynamic anchor boxes are better queries for detr.arXiv preprint arXiv:2201.12329, 2022.
- [35]Shu Liu, Lu Qi, Haifang Qin, Jianping Shi, and Jiaya Jia.Path aggregation network for instance segmentation.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8759–8768, 2018.
- [36]Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo.Swin transformer: Hierarchical vision transformer using shifted windows.In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- [37]Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie.A convnet for the 2020s.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11976–11986, 2022.
- [38]Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel.Understanding the effective receptive field in deep convolutional neural networks.Advances in neural information processing systems, 29, 2016.
- [39]Chengqi Lyu, Wenwei Zhang, Haian Huang, Yue Zhou, Yudong Wang, Yanyi Liu, Shilong Zhang, and Kai Chen.Rtmdet: An empirical study of designing real-time object detectors.arXiv preprint arXiv:2212.07784, 2022.
- [40]Depu Meng, Xiaokang Chen, Zejia Fan, Gang Zeng, Houqiang Li, Yuhui Yuan, Lei Sun, and Jingdong Wang.Conditional detr for fast training convergence.In Proceedings of the IEEE/CVF international conference on computer vision, pages 3651–3660, 2021.
- [41]Victor M Panaretos and Yoav Zemel.Statistical aspects of wasserstein distances.Annual review of statistics and its application, 6:405–431, 2019.
- [42]Joseph Redmon.Darknet: Open source neural networks in c.http://pjreddie.com/darknet/, 2013–2016.
- [43]Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi.You only look once: Unified, real-time object detection.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [44]Joseph Redmon and Ali Farhadi.Yolo9000: Better, faster, stronger.In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- [45]Joseph Redmon and Ali Farhadi.Yolov3: An incremental improvement, 2018.
- [46]Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen.Mobilenetv2: Inverted residuals and linear bottlenecks.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018.
- [47]Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun.Objects365: A large-scale, high-quality dataset for object detection.In Proceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019.
- [48]Russell Stewart, Mykhaylo Andriluka, and Andrew Y Ng.End-to-end people detection in crowded scenes.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2325–2333, 2016.
- [49]Peize Sun, Yi Jiang, Enze Xie, Wenqi Shao, Zehuan Yuan, Changhu Wang, and Ping Luo.What makes for end-to-end object detection?In International Conference on Machine Learning, pages 9934–9944. PMLR, 2021.
- [50]Peize Sun, Rufeng Zhang, Yi Jiang, Tao Kong, Chenfeng Xu, Wei Zhan, Masayoshi Tomizuka, Lei Li, Zehuan Yuan, Changhu Wang, et al.Sparse r-cnn: End-to-end object detection with learnable proposals.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14454–14463, 2021.
- [51]Zhi Tian, Chunhua Shen, Hao Chen, and Tong He.Fcos: A simple and strong anchor-free object detector.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(4):1922–1933, 2020.
- [52]Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin.Attention is all you need.Advances in neural information processing systems, 30, 2017.
- [53]Ao Wang, Hui Chen, Zijia Lin, Hengjun Pu, and Guiguang Ding.Repvit: Revisiting mobile cnn from vit perspective.arXiv preprint arXiv:2307.09283, 2023.
- [54]Chengcheng Wang, Wei He, Ying Nie, Jianyuan Guo, Chuanjian Liu, Yunhe Wang, and Kai Han.Gold-yolo: Efficient object detector via gather-and-distribute mechanism.Advances in Neural Information Processing Systems, 36, 2024.
- [55]Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao.Scaled-yolov4: Scaling cross stage partial network.In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 13029–13038, 2021.
- [56]Chien-Yao Wang, Alexey Bochkovskiy, and Hong-Yuan Mark Liao.Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7464–7475, 2023.
- [57]Chien-Yao Wang, Hong-Yuan Mark Liao, Yueh-Hua Wu, Ping-Yang Chen, Jun-Wei Hsieh, and I-Hau Yeh.Cspnet: A new backbone that can enhance learning capability of cnn.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 390–391, 2020.
- [58]Chien-Yao Wang, Hong-Yuan Mark Liao, and I-Hau Yeh.Designing network design strategies through gradient path analysis.arXiv preprint arXiv:2211.04800, 2022.
- [59]Chien-Yao Wang, I-Hau Yeh, and Hong-Yuan Mark Liao.Yolov9: Learning what you want to learn using programmable gradient information.arXiv preprint arXiv:2402.13616, 2024.
- [60]Jianfeng Wang, Lin Song, Zeming Li, Hongbin Sun, Jian Sun, and Nanning Zheng.End-to-end object detection with fully convolutional network.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15849–15858, 2021.
- [61]Yingming Wang, Xiangyu Zhang, Tong Yang, and Jian Sun.Anchor detr: Query design for transformer-based detector.In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 2567–2575, 2022.
- [62]Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, and Lei Zhang.Cvt: Introducing convolutions to vision transformers.In Proceedings of the IEEE/CVF international conference on computer vision, pages 22–31, 2021.
- [63]Haiyang Xu, Zhichao Zhou, Dongliang He, Fu Li, and Jingdong Wang.Vision transformer with attention map hallucination and ffn compaction.arXiv preprint arXiv:2306.10875, 2023.
- [64]Shangliang Xu, Xinxin Wang, Wenyu Lv, Qinyao Chang, Cheng Cui, Kaipeng Deng, Guanzhong Wang, Qingqing Dang, Shengyu Wei, Yuning Du, et al.Pp-yoloe: An evolved version of yolo.arXiv preprint arXiv:2203.16250, 2022.
- [65]Xianzhe Xu, Yiqi Jiang, Weihua Chen, Yilun Huang, Yuan Zhang, and Xiuyu Sun.Damo-yolo: A report on real-time object detection design.arXiv preprint arXiv:2211.15444, 2022.
- [66]Fangao Zeng, Bin Dong, Yuang Zhang, Tiancai Wang, Xiangyu Zhang, and Yichen Wei.Motr: End-to-end multiple-object tracking with transformer.In European Conference on Computer Vision, pages 659–675. Springer, 2022.
- [67]Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum.Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022.
- [68]Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz.mixup: Beyond empirical risk minimization.arXiv preprint arXiv:1710.09412, 2017.
- [69]Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z Li.Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection.In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9759–9768, 2020.
- [70]Wenqiang Zhang, Zilong Huang, Guozhong Luo, Tao Chen, Xinggang Wang, Wenyu Liu, Gang Yu, and Chunhua Shen.Topformer: Token pyramid transformer for mobile semantic segmentation.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12083–12093, 2022.
- [71]Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen.Detrs beat yolos on real-time object detection.arXiv preprint arXiv:2304.08069, 2023.
- [72]Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren.Distance-iou loss: Faster and better learning for bounding box regression.In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 12993–13000, 2020.
- [73]Qiang Zhou and Chaohui Yu.Object detection made simpler by eliminating heuristic nms.IEEE Transactions on Multimedia, 2023.
- [74]Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai.Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020.
- [75]Zhuofan Zong, Guanglu Song, and Yu Liu.Detrs with collaborative hybrid assignments training.In Proceedings of the IEEE/CVF international conference on computer vision, pages 6748–6758, 2023.





-
A.6可视化结果
图 4展示了我们的YOLOv10在复杂且具有挑战性的场景中的可视化结果。 可以观察到YOLOv10可以在弱光、旋转、等等各种困难条件下实现精确检测。 它还表现出强大的检测多样化和密集物体的能力,例如瓶子、杯子和人。 这些结果表明其优越的性能。
A.7贡献、限制和更广泛的影响
贡献。 总的来说,我们的贡献有以下三个方面:
- 1.
我们为无 NMS YOLO 提出了一种新颖的一致双重分配策略。 双标签分配方式旨在在训练过程中通过一对多分支提供丰富的监督,并在推理过程中通过一对一分支提供高效率。 此外,为了确保两个分支之间的和谐监督,我们创新性地提出了一致性匹配度量,可以很好地缩小理论监督差距并提高绩效。
- 2.
我们为 YOLO 的模型架构提出了一种整体效率-准确性驱动的模型设计策略。 我们提出了新颖的轻量级分类头、空间通道解耦下采样和排序引导块设计,大大减少了计算冗余并实现了高效率。 我们进一步引入了大核卷积和创新的部分自注意力模块,在低成本下有效提升了性能。
- 3.
基于上述方法,我们引入了YOLOv10,一种新的实时端到端目标检测器。 大量实验表明,与其他先进检测器相比,我们的 YOLOv10 实现了最先进的性能和效率权衡。




![【Real】[Flask]SSTI](https://img-blog.csdnimg.cn/direct/a9a9d933f435421f88dee19186b79df5.png)